基于UVM的可重用硬件加速器验证平台
2023-09-20隋金雪郁添林沈姒清
隋金雪,郁添林,3,沈姒清,3,张 霞
(1. 山东工商学院电子与信息工程学院,山东 烟台 264003;2. 北京大学信息技术高等研究院,浙江 杭州 311215;3. 中科网络技术研究所(中科院计算机所烟台分所),山东 烟台 264026)
1 引言
CNN在现代人工智能系统中得到了广泛应用,同时也给底层硬件带来了数据吞吐量和能效的挑战,通过优化整个系统,包括片内外数据流处理以及可重配置各种CNN架构等提高效率。目前主流的卷积神经网络硬件设计方式有FPGA、GPU和ASIC;FPGA虽然编程更灵活,开发周期短,但用高级语言生成的RTL代码可读性差,后期维护成本高,布线资源也存在一定的限制;GPU的峰值性能极好,但功耗过高,不适用于低功耗的场景[1]。ASIC为实现特定要求而定制的芯片,在功耗、可靠性、体积等方面具有优势,通用性强、适配各种算法模型的硬件加速器可用于更多的物联网终端设备。因此,可扩展的专用定制芯片需要充分的功能型验证。
传统架构的通用型处理器不能更好的支持机器学习的各种模型,不同算法带来的高计算密度和大存储带宽,需要灵活的专用集成电路来解决这些问题。硬件加速器的框架中独立的memory和core分离的结构,过总线进行通信[2]。设计各种串并行、数据流以及通信计算方式的RTL代码方案,需要一个由SystemVerilog语言搭建的基于UVM可重用的层次化验证平台。
2 基于UVM的硬件加速验证IP
本文搭建一个可重用的自动化验证平台,对卷积神经网络的前向传播进行验证,即卷积层、激活层、池化层和全连接层的功能型验证,以及对一些关键测试点的验证。
2.1 验证IP结构
硬件加速器验证IP的结构如图1所示。顶层是environment,包括memory_master_agent、memory_slave_agent、control_status_agent、kernel_agent、register_port_agent、reference_model、convolution_scoreboard等组件。其中多图层时需要例化对应的数据输入输出以及卷积核的通道数量[3]。各自的agent中都包含了driver、monitor和sequencer,sequence虽不属于验证平台的基本组件,但验证所需的激励由transaction组成,由sequence产生。
验证平台与DUT需要interface指明连接信号,在顶层用uvm_config_db配置变量,将virtualinterface传递到相应的组件。testbench和DUT之间存在时序和同步建模的问题,为了避免对输入的激励驱动与输出的采样产生竞争冒险[4],用clockingblocks构造理想的验证环境。modport作用如图2所示,明确了站在不同的角度对应信号的输入输出方向,通过虚拟接口的定义将以上内容封装起来。virtualinterface在测试平台的不同位置操纵一组虚拟信号,而不是直接操纵实际的信号[5,6]。

图2 modport结构示意图
2.2 组件功能实现
agent作为标准验证环境的组件,按照is_active的缺省值,配置为主动模式,在build_pahse()、connect_phase等函数中对driver、monitor和sequencer进行有条件的例化和连接,提供激励与检测的场景。
Referencemodel将每个单独的功能层写成virtualtask,将参数的传递和获取分离,便于封装和复用。主要实现kernel与channel数据写入(单个像素点8/16bit随机)、满足kernel列数开始卷积计算、基地址与偏移地址、非线性激活、最大最小以及均值池化、全连接和bank切换等功能。卷积核与输出层数量保持一致,数据从driver中获取,用for循环嵌套存入二维数组[7]。依据寄存器的值,判断卷积核大小以及数据类型,做出相应的乘加运算,计算的数据结果截取位宽后做非线性映射以及选择池化模式,对图像压缩提取特征。对连续多幅图片计算时,配置乒乓缓存的寄存器节约读写时序。经过处理后的每笔数据按总线位宽传输至记分板。
Scoreboard用于比较referencemodel与DUT输出是否一致,实际仿真过程中验证部分的输出结果更快,先用一个队列暂存数据并打印到对比文件,等待DUT同样的操作。两个队列的数据比对后删除,仿真结束后,队列不为空会报错,也可以从打印文件中直观的看出实际结果的差异。
SystemRDL是Accellera发布的寄存器描述语言,由IC寄存器自动化定义工具ordt可以实现由单一输入源得到多种一致性的输出[8],包括UVM寄存器模型、RTL代码和文档等,旨在提高复杂数字系统的IC设计和验证的效率,质量及复用性。
寄存器模型流程如图3所示,在env实例化,建立数据通道bank0、bank1以及卷积核与非乒乓配置寄存器三个uvm_reg_block,以前门的方式产生事务并借助于agent来访问DUT中的存储器,消耗仿真时间。本文主要的测试内容围绕配置寄存器展开,会同时启动多个sequence从而产生存储着操作的地址和操作类型的变量,经过adapter转换后传给sequencer,最后交由driver以apb接口时序完成前门访问操作[9]。
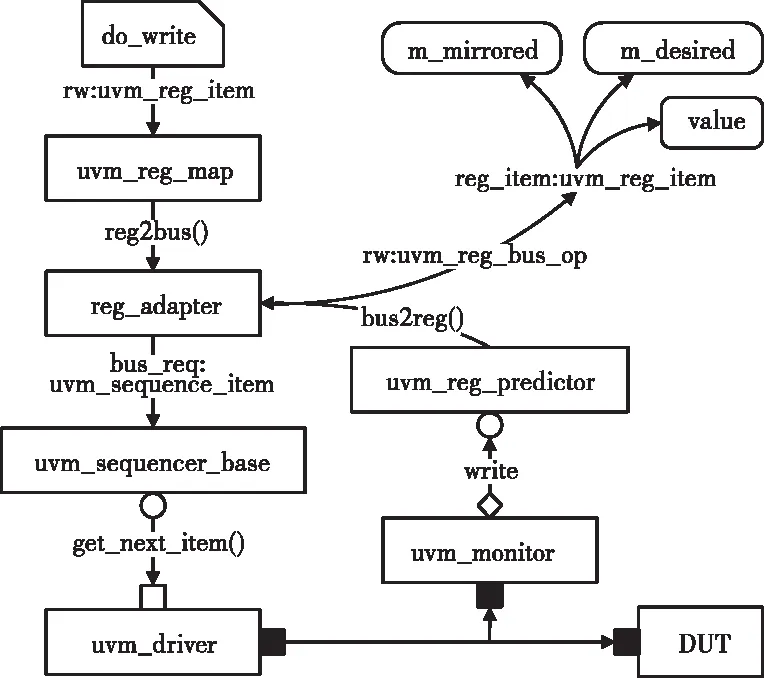
图3 寄存器模型示意图
2.3 仿真执行过程
整个验证平台执行tmake管理makefile,用python、shell和perl脚本混合编程,获取宏定义的参数,将配置信息传递至RTL、testbench和buildflow,进行文件预处理、编译以及仿真。
UVM验证平台启动流程是在top_tb导入uvm_pkg文件,创建例化对象,定义时钟频率,调用run_test();再从uvm_test依次执行各组件中的phase机制,在run_phase获取外部脚本处理后的测试用例名,object用factory机制创建实例,转换成UVM_TESTNAME类型后raise_objection,再通过start启动sequence,等待objection被撤销后停止仿真,结束run_phase(),达到并行仿真的效果。
每个测试用例运行都由DUT发出请求信号,再从master_driver中发出确认信号,并例化的每层read_channel_transaction产生不同的随机数,分别由读数据通道接口传递给DUT和reference_model用TLM通信中的uvm_blocking_get_port获取对应通道的数据。触发信号开始数据卷积、激活、池化等功能输出至scoreboard比对[10]。
仿真在reference_model中,存满卷积核大小的列数后就开始做乘加运算,比DUT数据预存更快。为保持sequence与driver通信,只要seq_item_port有数据包就会通过get_next_item(req)获取,并通过send(req)函数按照验证Spec时序驱动至DUT,并执行item_done作为当前transaction发送结束的标志。Sequence挂载于能发送tarnsaction的sequencer上。每个sequence继承于uvm_sequence,默认uvm_sequence_item类型,必须实现body函数,当sequence被调用后会自动执行body中的代码[11]。
在uvm_test阶段,自定义initialphase配置硬件加速器的默认值,构建初始化测试用例,可以用来对验证平台做冒烟测试。sequence中配置寄存器值时,保证随机化、参数化运行,降低错误概率。
3 测试用例设计
验证功能测试点根据硬件加速器实际应用场景和卷积计算等特性来制定各种测试用例。表1所列为IP的基本功能测试点,包括寄存器值可变范围和覆盖次数统计。

表1 IP功能测试点
按照数据位宽测试,用独热码以数据流推动,直观计数,无需占用大量资源。异常测试,在卷积核与图层计算过程中,再次使能卷积触发信号不受影响。Dist操作符允许不同值的概率选取不同,同时也保证了边界测试带有相应的权重。
通过随机化可以通过利用CPU的时间来换取人工检查的时间,提高效率,提供足够的激励。采用受约束的随机测试法(CRT)产生测试集:使用随机的数据流为DUT产生输入的测试代码。改变伪随机数发生器(PRNG)的种子(seed)。同时在测试设计时考虑设计规范的边界处,甚至测试设计规范之外的行为[12,13]。
4 代码及功能覆盖组模块
覆盖率是验证DUT的功能正确性与完整性的重要指标,分为代码覆盖率和功能覆盖率。如图4代码覆盖率是工具自动搜集编写好的RTL代码,包括行、条件、跳转、分支和状态机。功能覆盖率是对数据组合和行为序列的检查。在本文中功能覆盖率是通过编写覆盖组、覆盖点和交叉覆盖主要是获得对寄存器配值的数据覆盖率,同时也是硬件加速器各层功能的测试指标。

图4 覆盖率总结图
硬件加速器验证IP的功能覆盖组设计考虑了架构特性,包括旁路模式、乘加阵列、缓存切换、多图层并行,根据总线位宽还考虑了数据读写次数,图像大小边界测试以及计算触发方式等异常测试。
如图5所示是覆盖率的收敛过程,由于功能覆盖率是人为定义的,可能存在遗漏的功能场景,需要对测试用例不断的进行迭代[14,15]。
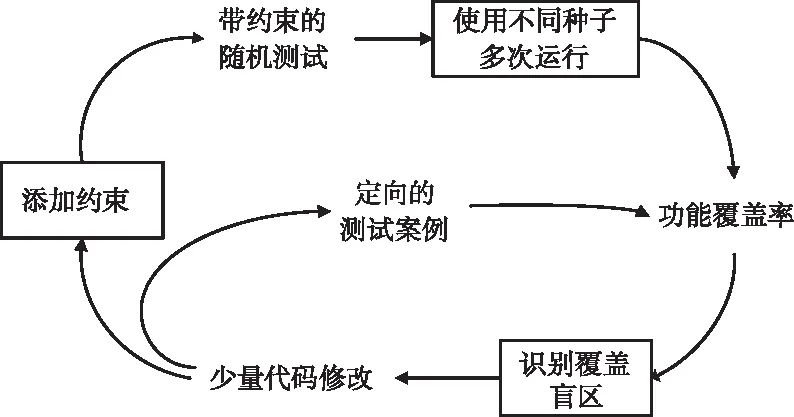
图5 覆盖率收敛流程
5 结果分析
该验证IP对不同总线位宽、数据与卷积核单个像素位宽、卷积核大小、步长及输入输出层数等需求,配置宏定义参数,连续多幅图片卷积的寄存器值切换,波形包含时钟沿触发跳变的脉冲信号,是逻辑正确运行的最直观体现。
由图6看出数据从读通道写入,预存一定量的数据到buffer,保证列数不小于卷积核尺寸,卷积核数据读入方式与其类似,由寄存器模型配值去触发卷积计算。

图6 数据预缓存波形图
由图7看出通过APB总线完成寄存器读写,时钟频率远低于模块时钟。先传输kernel寄存器值,等待kernel寄存器标志位有效;再配值数据寄存器,等待数据通道寄存器标志位有效,再将soft_trigger信号置1,等待卷积计算状态位拉低后,一幅图片处理完成。

图7 APB总线波形图
图8表示数据的输出,RTL发出请求信号,验证部分随即给出确认信号以及一笔总线位宽的数据。验证结果表明HWPE的功能已完全实现,测试激励覆盖了所有功能点。
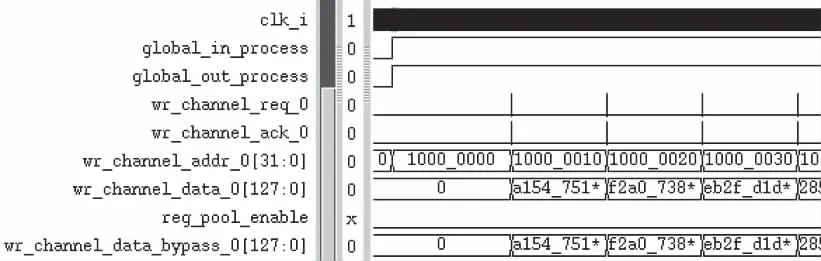
图8 数据输出波形图
6 结论
UVM作为IC最有效的验证方法学,前期搭建验证平台耗费一定的时间,但其重用性与可扩展性强,测试用例的验证效率高,极大的缩短了IC设计的研发周期。本文搭建了基于UVM的硬件加速器模块的可重用验证平台,充分验证了卷积神经网络的功能正确性,完成了芯片设计电路逻辑关系的分析。该验证架构按照网络模型需求,做少量的代码修改,即可投入其它的验证流程中。
