基于PSO优化SVM算法的癌症诊断方法研究
2023-09-20孟霖宜刘屿鸿
孟霖宜,刘屿鸿
(1. 四川大学生命科学学院,四川 成都 610065;2. 四川大学网络空间安全学院,四川 成都 610065)
1 引言
癌症已成为威胁人类生命健康最严重的疾病之一,具有发展速度快、死亡率高、术后可能复发的特点。传统的癌症诊断大多采用病理切片、活检等方式进行诊断,对医生的水平要求高,且易受医生主观经验影响,难以满足早诊断、早治疗的要求。支持向量机(Support Vector Machine,SVM)作为一种优异的模式识别方法,可以充分利用大量历史癌症数据,结合患者的数据特征进行识别判断,在肺癌、乳腺癌、宫颈癌等医学研究等领域得到广泛的应用,是近几年用于癌症辅助诊断领域最多的智能方法之一。文献[1]提出了SVM-PCA和SVM-RFE的方法,并用于宫颈癌的诊断;文献[2]提出了一种基于主成分分析和支持向量机的卵巢癌预测方法;文献[3]采用支持向量机的方法开展了癌细胞识别的应用研究;文献[4]开展了支持向量机的癌症辅助诊断方法研究;文献[5]开展了改进SVM的癌症诊断应用研究。
本文采用径向基函数作为核函数的 SVM分类器,构建了癌症辅助诊断流程,探讨其在癌症诊断中的应用,针对SVM分类器中对诊断准确度影响较大的惩罚函数C和核函数参数γ,设计了基于粒子群(particle swarm optimization,PSO)的参数优化流程,构建了合理的适应度函数,利用粒子群算法进行了参数C和γ的寻优,建立了基于PSO-SVM融合算法的癌症诊断流程。采用威斯康星(Wisconsin)大学乳腺癌数据,通过仿真验证了所提方法的有效性。
2 支持向量机的诊断方法
2.1 支持向量机算法
支持向量机本质上是一种二分类模型,通过寻找一个能满足分类要求的超平面,使训练样本集内的所有点尽可能地距该超平面最远,用样本特征空间中的间隔最大来定义,达到分类的目的。 其思想是对于线性可分的样本集,支持向量机通过间隔最大化,得到一个线性分类模型;而对于非线性的样本集,支持向量机引入了核函数,将输入数据映射到新的高维特征空间,在新空间中将非线性分类问题转化为线性分类问题,再采用线性支持向量机的方法来实现非线性问题的分类[6,7]。
设给定样本集{(x1,y1),(x2,y2),…,(xn,yn)},xi∈Rn,yi∈{-1,1},i=1,2,…N。(xi,yi)为数据的样本点,xi为样本特征向量,而yi为xi对应的类别标签,N为训练样本总数,n为样本空间的维数。SVM需要构建一个超平面,使得各个样本点距离该超平面的距离尽可能地远,达到精确分类的目的。最优分类超平面函数如下

(1)

(2)
0≤αi≤C,i=1,2,…N
(3)
其中C为惩罚参数,表示对于分类错误的惩罚程度,代表能够接受的分类错误率的值,C值越大惩罚越大。在实际应用中,需要根据具体情况预先设定。
对于非线性问题,引入能够实现非线性映射的核函数,将样本映射到更高维的特征空间,再利用线性分类方法在高维的特征空间进行分类。
定义一个核函数K(x,y)=φ(x)·φ(y),φ是样本空间到特征空间的映射,式(1)变换为

(4)
核函数对于非线性支持向量机的学习具有非常重要的影响,常用的核函数有:线性核函数、多项式核函数、径向基核函数和Sigmoid核函数。在实际应用中,需要根据具体情况参考经验预先设定:一般样本的特征维数多、样本量相对较少时常选用线性核函数;特征维数少、样本量相对较大时常选用径向基核函数。
本文的实验数据样本数量远大于样本维数,故采用径向基核函数作为SVM的核函数,如式(5)

(5)
式中:γ为核函数参数,γ>0。γ的改变会影响SVM的分类准确度,γ减小会提高准确度,但会影响分类的推广度。
2.2 支持向量机的诊断与分析
采用支持向量机进行癌症辅助诊断时,其流程如图1所示。

图1 基于支持向量机的癌症辅助诊断
基于支持向量机的癌症辅助诊断流程包括历史病例诊断数据处理、支持向量机参数设置、支持向量机训练、待诊断病人信息分类诊断等步骤。
支持向量机用于诊断分类时,其诊断分类的效果主要受惩罚参数 C 和核函数参数γ的影响。实际使用中往往结合经验选取C 和γ的值,选取不当可导致过学习、欠学习的情况,致使诊断分类效果不理想。要想获得性能更为优越的SVM,必须在训练开始之前对C 和γ两个参数在一定范围内寻优。
粒子群算法是一种启发式优化算法,能较好地解决最优化问题,可用于惩罚参数 C 和核函数参数γ的优化。
3 基于PSO优化SVM算法的癌症诊断
3.1 粒子群算法原理
粒子群算法(Particle Swarm Optimization,PSO)是一种基于种群中的个体行为及数学抽象而提出的启发式优化算法,具有实现方便、可调参数少和收敛速度快的优点,在解决优化问题方面得到广泛应用。
该算法采用“位置-速度”模型,每个粒子的迭代过程由速度和位置决定,速度代表粒子搜索的方向和距离,单个粒子在多次迭代中适应度最好的位置为个体极值,整个群体在多次迭代中所有粒子适应度最好的位置为群体极值;各个粒子的适应度由粒子群的适应度函数决定。
在D维搜索空间中,粒子群由n个粒子组成X=(X1,X2,…,Xn),Xi表示第i个粒子在空间的位置Xi=(xi1,xi2,…,xiD),每个Xi都有可能是最优解;第i个粒子的速度为Vi=(vi1,vi2,…,viD),个体极值为pi=(pi1,pi2,…,piD);群体极值为pg=(pg1,pg2,…,pgD)。每次迭代的速度和位置分别为[8,9]
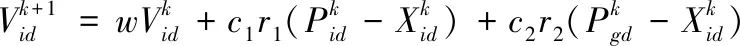
(6)

(7)

3.2 PSO优化SVM的适应度函数选择与参数寻优
采用径向基函数作为核函数的支持向量机用于诊断分类时,其分类的准确度和推广能力主要受惩罚参数 C 和核函数参数γ影响。
本文为了提高癌症诊断准确率,以C 和γ作为优化目标,利用粒子群算法对其优化。使用PSO进行SVM参数的优化,其优化过程如图2所示。

图2 PSO优化SVM参数的寻优过程
基于PSO的SVM参数优化过程,包括粒子群初始化、粒子群适应度计算、个体极值和群体极值寻找、种群更新等步骤:
1)粒子群初始化,以待优化参数(C,γ)为粒子个体,在其潜在求解范围内,随机生成一定数量的粒子,获得初始化种群。种群中每个个体(C,γ)即为一个潜在解;
2)粒子群适应度计算,对种群中每个个体,基于适应度函数进行其适应度计算。适应度函数是粒子群求解过程中的关键,决定了求解方向和求解质量。本文将支持向量机与粒子群融合的算法用于癌症的辅助诊断,目的是用人工智能的方法辅助医生提高癌症的诊断的准确性。为准确评估粒子个体适应度,将粒子(C,γ)设置下的SVM分类器的诊断准确度(Accuracy),作为粒子群优化过程中的适应度函数。
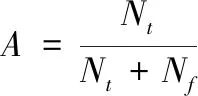
(8)
式中:Nt为验证样本中输出值与期望值一致,输出正确的数量;Nf为验证样本中输出值与期望值不一致,输出错误的数量。
粒子群适应度计算过程中,对于种群中的每个粒子,进行SVM分类器的设置、训练、测试,获得该粒子对应SVM分类器的诊断准确度,进而得到粒子适应度。
3)个体极值和群体极值寻找,在粒子群适应度计算基础上,根据每个个体适应度大小,获得种群最优个体及单个粒子历史更新过程中的最优值。
4)种群更新,根据种群最优值、个体最优值,根据式(6)、式(7)进行每个粒子的更新,实现粒子种群的更新。
3.3 基于PSO优化SVM算法的癌症诊断流程
基于PSO优化SVM算法的癌症诊断流程如图3所示。主要步骤如下所示。
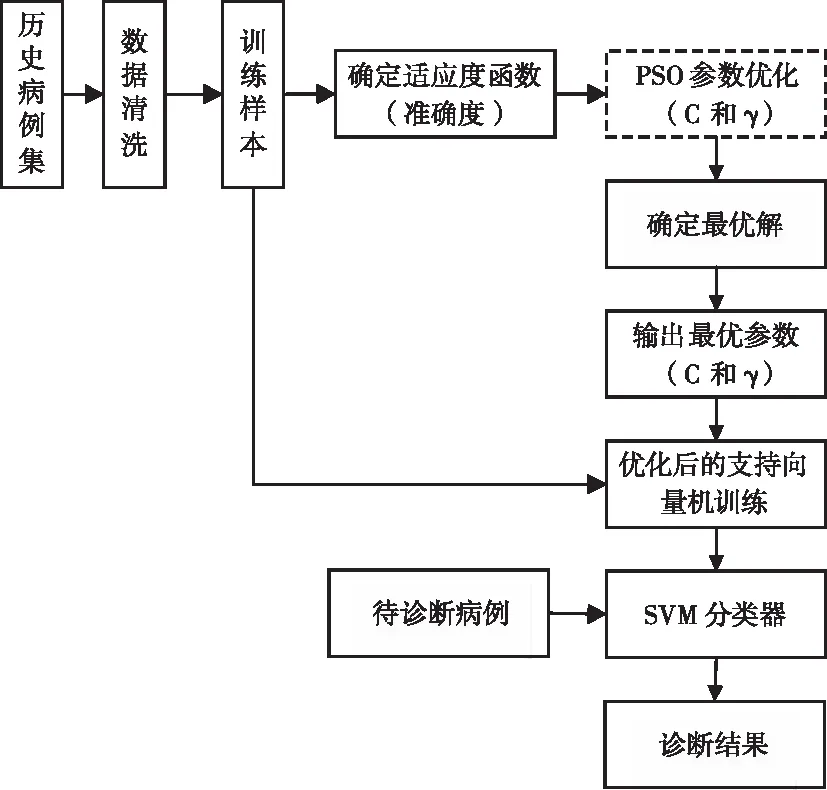
图3 基于PSO优化SVM算法的癌症诊断
1)首先对历史病例集并进行数据清洗,剔除特征要素不完整的数据和明显输入错误的数据;
2)将符合要求的历史病例数据按照交叉实验的方法进行训练;
3)将诊断的准确度按照式(8)作为粒子群优化过程的适应度函数;利用训练样本,采用粒子群算法对支持向量机的惩罚参数 C 和核函数参数γ优化;
4)采用优化后的惩罚参数 C和核函数参数γ进行支持向量机设置,并利用历史癌症病例数据进行支持向量机的训练,获得支持向量机分类器;
5)对于待诊断病人,采集病人特征数据,并使用支持向量机分类器进行计算,确定病人类别,完成病人的诊断。
仿真关键伪代码如下所示。
X = initialParticle(iniNum, range);
pb_fitValue = fitness_PSO(X, trainX, trainY, testX, testY);
…
for epoch=1:MAXDT
V = w*V+c1*R1*(pb-X)+c2*R2*(gb-X);
X = X+V;
cur_fitValue = fitness_PSO(X, trainX, trainY, testX, testY);
[pb, gb, pb_fitValue, gb_fitValue] = update(pb, gb, max_pb_fitValue, gb_fitValue, cur_fitValue, X);
if(gb_fitValue >limit) break; end
end
…
gam = gb(1);
sig2 = gb(2);
trainlssvm(trainX, trainY, gam, sig2,);
SVM_Y = simlssvm(trainX, trainY, gam, sig2, testX);
其中:initialParticle()为粒子群初始化函数;fitness_PSO()为粒子群适应度计算函数;update()为粒子群更新函数;trainlssvm()为SVM分类器训练函数;simlssvm()为SVM分类器测试、应用函数。
4 仿真验证
4.1 实验数据集
本文的实验数据采用威斯康星(Wisconsin)大学乳腺癌数据样本集[12](http:∥archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Prognostic%29),该数据集共有198个癌症病例术后是否复发的数据,其中有151个没有复发的病例和47复发病例,每条数据记录包括33个特征(属性3~35),如表1所示。

表1 数据样本集描述
表中各属性含义:1是编号;2是结果(R代表复发,N代表没有复发);3是复发时间;4~33分别是是(半径、纹理、周长、面积、平滑度、紧密度、凹陷度、凹点、对称性、分形维数等10个特征的均值、标准差和最坏值);34是肿瘤大小;35是淋巴结状态。
5.2 仿真验证与结果分析
本文应用支持向量机对训练样本集建立分类模型进行训练,在198个样本中有4个样本缺少淋巴结状态数据,不作为实验样本。故以有效实验样本中的154个样本为训练样本进行支持向量机的训练,以40个样本为测试样本,进行支持向量机性能的测试。
采用式(5)径向基函数作为核函数,惩罚参数 C 和核函数参数γ通过PSO进行寻优后,采用优化后的C 和γ对测试样本集进行分类,得到分类结果。
设定C 的取值范围为10-1~102,γ的取值范围为10-1~102;粒子群算法初始化粒子个数为20,迭代次数 50,惯性权重w为 0.7,加速因子c1为 1.2、c2为 1.5。采用图2所示基于PSO的SVM参数优化流程,进行惩罚参数C和核函数参数γ的优化,优化过程中最优个体适应度如图4所示。
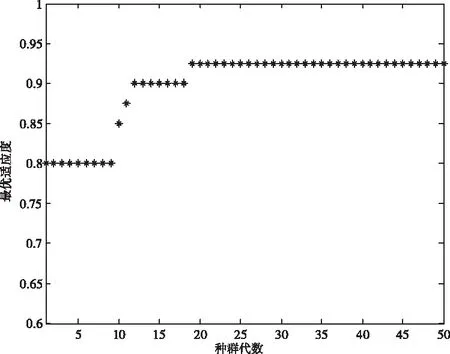
图4 适应度优化过程
由图4所示参数优化过程可以看出,通过PSO的优化,种群最优适应度不断提升,从0.8逐步提升至0.85、0.875、0.9、0.925,通过50代种群的优化,最优个体的适应度达到0.925,此时最优个体为(7.2377, 4.7909),即惩罚参数C=7.2377、核函数参数γ=4.7909。
根据优化结果进行支持向量机参数的设置,使用154个训练样本进行支持向量机的训练,设置复发病例的类别标志为+1,设置未复发病例的类别标志为-1。训练完成后,使用40个病例进行支持向量机诊断性能的测试。经测试,40个病例中37个病例诊断结果正确、3个病例诊断结果错误,结果如图5所示,即所提方法诊断正确率为92.5%。

图5 分类结果
同时,针对相同的训练样本,采用Bayesian方法进行惩罚参数C、核函数参数γ的优化,优化获得惩罚参数C=94.9917、核函数参数γ=0.0183。采用该参数设置支持向量机,使用相同的病例进行支持向量机的训练、测试,经测试,40个病例中36个病例诊断结果正确、4个病例诊断结果错误,即经Bayesian优化的支持向量机其诊断正确率为90%。
与随机森林、神经网络、梯度提升树、LightGBM、Stacking-1、Stacking-2等现有诊断方法[4]相比较,各方法的诊断准确率如表2所示。
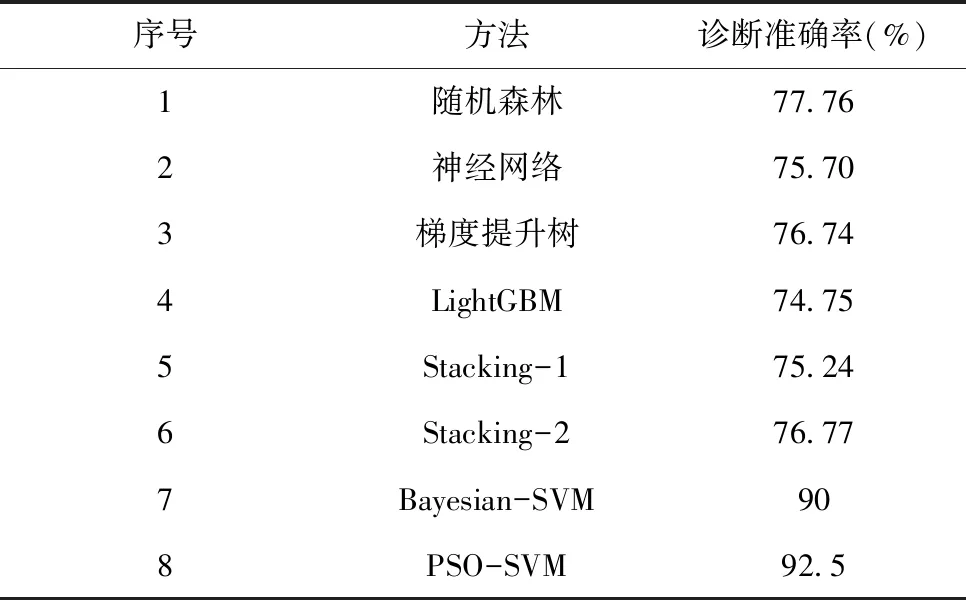
表2 不同方法的诊断准确率
由表2所示各诊断方法的诊断准确率可以看出,已有方法中,随机森林、神经网络、梯度提升树、LightGBM、Stacking-1、Stacking-2的诊断准确率分别为77.76%、75.70%、76.74%、74.75%、75.24%、76.77%;基于Bayesian参数优化的支持向量机(Bayesian-SVM)其诊断准确率为90%;本文所提支持向量机与粒子群相结合的诊断方法(PSO-SVM)其诊断准确率为92.5%,可以看出,本文所提方法通过粒子群参数优化、支持向量机训练分类,提高了癌症诊断准确率,为癌症的自动化、智能化诊断提供了一种新方法。
5 结论
本文针对传统的癌症诊断易受医生主观经验影响、支持向量机辅助诊断准确度不高、无法满足实际使用需求的问题,结合粒子群具有启发式优化的特点,构建合理的适应度函数,通过粒子群算法实现支持向量机中惩罚函数C和核函数参数γ的优化,进而构建了基于支持向量机与粒子群融合算法的癌症辅助诊断模型。仿真验证表明,该方法有效提高了诊断的准确度,可以作为医生的对癌症诊断的有效辅助手段。
