基于GAN的小样本数据增强在身份识别中的应用
2023-09-20李瀚铭苏金善
李瀚铭,苏金善
(伊犁师范大学电子信息工程学院,新疆 伊犁 835000)
1 引言
人脸识别技术通过数十年的发展,已经到了相当成熟的阶段[1]。但在实际应用中,由于人脸受到表情、饰品、光线、角度等复杂因素的影响,导致识别率急剧下降[2]。因此,人脸识别技术的研究热点已经转变为如何实现在各种复杂条件下的身份识别[1]。如文献[3]提出了利用PDSN算法实现轻微遮挡条件下的人脸识别;文献[4]提出了利用小波变换+LBP算法实现复杂光照下的人脸识别,文献[5]提出了利用CLAHE算法增强对比度的方式实现在低亮度条件下的人脸识别;文献[6]提出了利用了CVBJ算法实现各种表情下的人脸识别。这些方法虽然在对应条件中取得了较高的准确率,但是这些针对性算法往往只能解决一种复杂条件下的识别问题。
同时,由于样本数据获取困难,亟待需要实现基于小样本的复杂人脸的身份识别。文献[7]详细分析了如今主流的各种人脸识别算法,认为数据集中的图像数量越多、图像分布越广则训练效果越好,并且论证了诸多数据增强方法对人脸识别系统的影响;文献[8]提出了一种叫做SSPP-DAN的想法,通过一个3D人脸模型生成不同姿态的人脸虚拟样本从而实现小样本人脸识别。文献[9]是通过引入一个人脸特征提取器,并改进Loss计算方法从而实现小样本的身份识别。文献[10]将数据不确定性估计理论应用于人脸识别领域,提出DUL算法,并通过实验证明该算法可以使低质量图像在1v1情况下的一些指标得到极大的提高。这些方法虽然可以大幅降低数据需求量,但是与算法优化一样,只能进行一些特定复杂条件下的身份识别。文献[11]提出了基于GAN的小样本数据增强的方法,由于GAN具有风格迁移功能,使其生成的虚拟样本与真实图像样本在识别训练中没有实质的区别。针对上述问题,本文主要提出了一种利用GAN进行小样本数据增强的方法,进而实现小样本复杂人脸的身份识别,主要工作内容如下:
a)利用现有公共人脸数据集对GAN模型在指定域进行预训练,得到一个虚拟样本生成模型。
b)通过虚拟样本生成模型对小样本中的真实人脸图像生成大批量各种复杂条件下的人脸虚拟样本,得到一个分布广泛、类型全面的复杂人脸数据集,作为本文复杂人脸身份识别模块的训练集。
c)通过与不同算法进行对比实验,验证本文方法的可行性,并且性能得到一定提升。
2 方法介绍
为了解决小样本在复杂条件下的身份识别的问题,本文通过使用GAN对小样本中少量正常条件下的真实图像生成大量基于光线、表情、角度、姿态等数据变换的复杂条件下的虚拟样本,从而创建出一个样本数量充足、分布广泛的人脸数据集进行训练。为了实现上述目标,本文分为两大模块:人脸数据生成模块和身份识别模块。
2.1 使用GAN进行小样本数据增强的可行性
文献[11]分析了对小样本进行数据增强的方法与可行性,认为利用GAN进行数据增强时存在的最大问题在于GAN需要大量数据进行训练才能达到较好的生成效果;同时文献[12]指出,因为在训练GAN模型时,需要大量的数据进行迭代,而小样本问题正是在解决数据分布范围不广或数据量不足的问题,因此该方法局限性较大。但是针对复杂人脸的身份识别问题,目前有大量的开放公共人脸数据集可以用于对GAN模型进行训练,因此该问题可以通过使用开放公共数据集进行训练GAN模型的方法解决。其次文献[12]还指出,在训练GAN网络时想要生成较高分辨率的图像容易引起网络的不稳定和不收敛,但是通过实验发现,生成可以满足人脸识别所需分辨率的虚拟样本并不会发生上述问题。而文献[13]的研究表明,GAN对真实数据进行采样后所生成的虚拟样本可以用来进行训练分类器,其训练精度和准确率在某些情况下甚至高于使用原始数据集进行训练的结果。因此可以使用通过公开数据集训练好的GAN模型对小样本进行数据增强,生成各种复杂条件下的虚拟样本进行身份识别网络的训练。
2.2 人脸数据生成模块
因为目前公开数据集的属性分布问题以及网络生成方式的不同,一种GAN只能在部分领域做到较好的生成效果。通过分析实际生成效果,决定采用基于域转换的StarGAN[14]生成遮挡条件下的虚拟样本,采用基于样式混合的StyleGAN[15]生成光线、表情、角度等细节变换条件下的虚拟样本。
2.2.1 StarGAN方法
StarGAN是通过域转换的方式进行虚拟样本的生成,它可以同时训练多个领域,即在同一种模型下,可以做多个图像翻译任务,例如更换头发颜色、添加遮挡等。在网络结构设计上,鉴别器不仅仅需要学习鉴别样本是否真实,还需要对真实图像判断来自哪个域。即对于给定的输入图像x和目标域标签c,网络的目标是将x转换成输出图像y,输出图像y能够被归类成目标域c。为了实现这一点就需要鉴别器有判别域的功能。所以需要在D的顶端加一个额外的域分类器,域分类器loss在优化D和G时都会用到,因此将这一损失分为两个方向,分别用来优化G和D。
真实图像的域分类的损失函数定义如下式
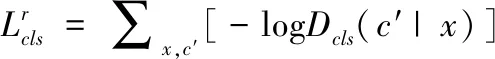
(1)
生成图像的域分类的损失函数如下式

(2)
通过最小化对抗损失与分类损失,G努力尝试做到生成目标域中的真实图像。但是这无法保证学习到的转换只会改变输入图像的域相关的信息而不改变图像内容。所以需要加上周期一致性损失如下式
Lrec=∑x,c,c′[||x-G(G(x,c),c′)||1]
(3)
汇总后的总体损失如下式

(4)

(5)
其中Ladv为GAN的通用函数,用来判断输出图像是否真实。
2.2.2 StyleGAN方法
StyleGAN则可以通过样式混合的方式进行虚拟样本的生成,文献[15]利用了一种混合正则化的方法,在训练过程中使用两个Latent Z,通过映射网络运行Z1、Z2,并让对应的W1、W2控制样式,从而以样式混合的方式生成图像,这种方法虽然不会提高模型性能,但是它可以从一张生成图像中提取低级别的特征并从另一张生成图像中提取其余特征混合出一张新的图像,从而实现了对生成虚拟样本的光线、表情、角度等细节方面的控制。
它是在ProGAN的基础上发展改进而来的,这种网络首先通过学习在低分辨率图像中也可以显示出来的基本特征来构建图像的基本轮廓,然后随着分辨率的提高来学习更多细节。但ProGAN控制生成图像的特定特征能力非常有限,为了解决该问题,文献[15]提出了一个新的生成器结构,如下图1,图中左侧为传统GAN所用结构,右侧为StyleGAN所提出的新结构。

图1 传统GAN与StyleGAN的生成器结构
这种结构放弃了传统的输入层,并添加了一个非线性映射网络,将输入Z用8层全连接层进行非线性变化得到W,然后再利用下式进行仿射变化得到归一化所需的scale和shift

(6)
接下来在AdaIN模块之前引入噪声为生成器生成随机细节,从而使图像更加真实的同时也增加了输出图像的多样性。
2.3 身份识别模块
本文旨在解决复杂条件下的身份识别,为了实现在各种复杂条件下准确提取到人脸面部特征,需要建立一个很深的网络层次,理想情况下,神经网络的层数越多,模型的效果会越好。主要体现在特征的“等级”随着网络层数的增加而变高,深度越深的网络拥有越强大的表达能力。但是在实际的训练过程中更深的网络更难训练,主要存在两个问题:其一是梯度消失。基于反向传播通过链式法则进行一系列连乘计算隐藏层梯度的网络模型,导致浅隐藏层的梯度急剧衰减,这是梯度消失问题的根源。其二是退化问题。对于较深的模型会比较浅的模型有更高的训练误差,主要原因在于:当模型变得复杂时,算法的优化会变得更加困难,这会导致模型的学习效果变得较差。ResNet网络则较好的解决了上述问题,其可以实现一个很深的网络层数,因此有很强的特征提取能力,基本可以满足从大量复杂条件下的人脸图像中提取出面部特征的需求。
文献[16]提出了残差块(Residual Block)的想法,并由此避免了梯度消失和性能退化的问题,从而实现了一个很深的网络。残差块一般可以分为直接映射部分和残差部分。残差网络与普通的网络不同之处在于增加了Shortcut Connection,如下图2,图中右侧曲线即是直接映射部分,这可以使上一个残差块的信息没有阻碍的流入到下一个残差块,提高了信息流通,并且也避免了由于网络过深所引起的退化问题。

图2 残差块示意图[16]
在一个残差块中,如果其可以拟合的函数为F(x),期望的潜在映射为H(x),则F(x)并不直接学习潜在的映射,而去学习残差,如下式
F(X)=H(X)-X
(7)
原本的前向路径上就变成为下式
F′(X)=F(X)+X
(8)
然后用F′(x)拟合H(x),对于冗余的残差块,只需F(x)→0就可以得到恒等映射。如果神经网络已经训练到较饱和的准确率,那么后续的训练就转变为恒等映射的训练。这样就可以在不损失性能的条件下加深网络,提升网络效果。
该模块的LOSS使用keras框架中的分类交叉熵损失函数进行计算,这种函数可以计算出实际输出与期望输出之间的距离,函数如下式。

(9)
3 仿真研究
3.1 仿真数据集
3.1.1 人脸数据生成模块数据集
StarGAN方法采用已经经过对其处理的CelebA数据集进行训练。StyleGAN方法采用公开预训练模型生成目标对象的虚拟样本。
3.1.2 身份识别模块数据集
为了利用模型生成虚拟样本以及进行识别效果的检验,搜集了3000名对象每人20张真实图像,其中8张为在正常条件下正对摄像头所拍摄;剩余12张分别为轻微遮挡、复杂光线、表情变化以及45°侧脸的复杂条件下所拍摄,每种条件下各3张,并以此作为原始数据集。
关于身份识别模块训练集的构成,首先从真实图像中每人抽取4张正常条件下的真实图像作为生成模块的输入,利用StarGAN模型生成每人25张在各种轻微遮挡下的虚拟样本,再利用StyleGAN模型生成每人25张的各种细节变换下的虚拟样本,组成每人50张,共计150000张的复杂条件下的虚拟样本用于训练。
关于身份识别模块测试集的构成,根据测试目标的不同,将原始数据集划分为五个测试集。测试集1包含每名对象未参与生成的4张真实图片,共计12000张;测试集2到测试集5分别包含每名对象在遮挡、复杂光线、不同表情以及45°侧脸的条件下的3张真实图像,每个测试集均有9000张真实图像。
3.2 实验模型准备
关于StarGAN的训练,以8种属性标签为一组,将CelebA数据集所提供的40种属性标签分为5组均进行了相同的训练,详细训练参数如表1所示。
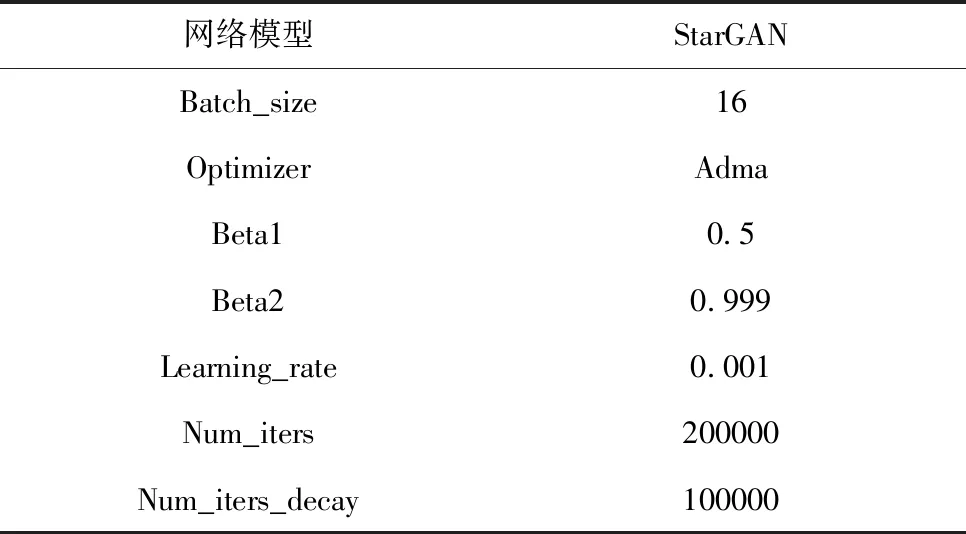
表1 人脸数据生成模块预训练参数
StarGAN与StyleGAN迭代完成后的生成效果如图3图4所示。

图3 StarGAN生成效果

图4 StyleGAN生成效果
关于身份识别网络的训练,采用ResNet50结构为主体架构;采用动量梯度下降法进行优化;使用虚拟样本训练集进行训练。详细训练参数如表2所示。

表2 身份识别模块参数
身份识别网络的训练结果如图5所示。
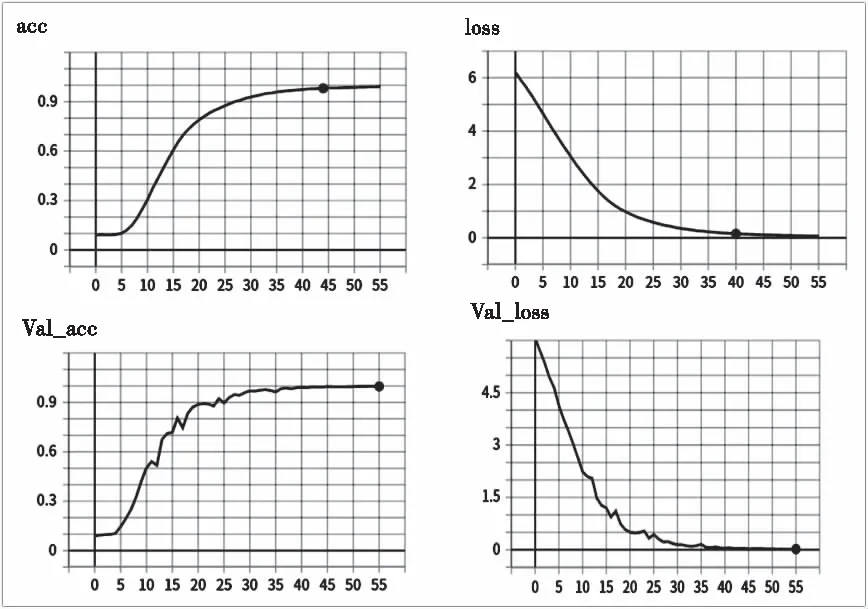
图5 身份识别网络训练效果
3.3 实验分析与结果对比
首先,为了验证对小样本利用GAN生成的虚拟样本用于身份识别训练的效果,测试样本使用由正常条件下的真实图像组成的测试集1并调用训练好的身份识别模型进行性能测试。选择从训练达到理想效果时单个样本所需的图片数量和识别准确率两个方向与现有的一些方法进行对比,对比结果如表3所示。
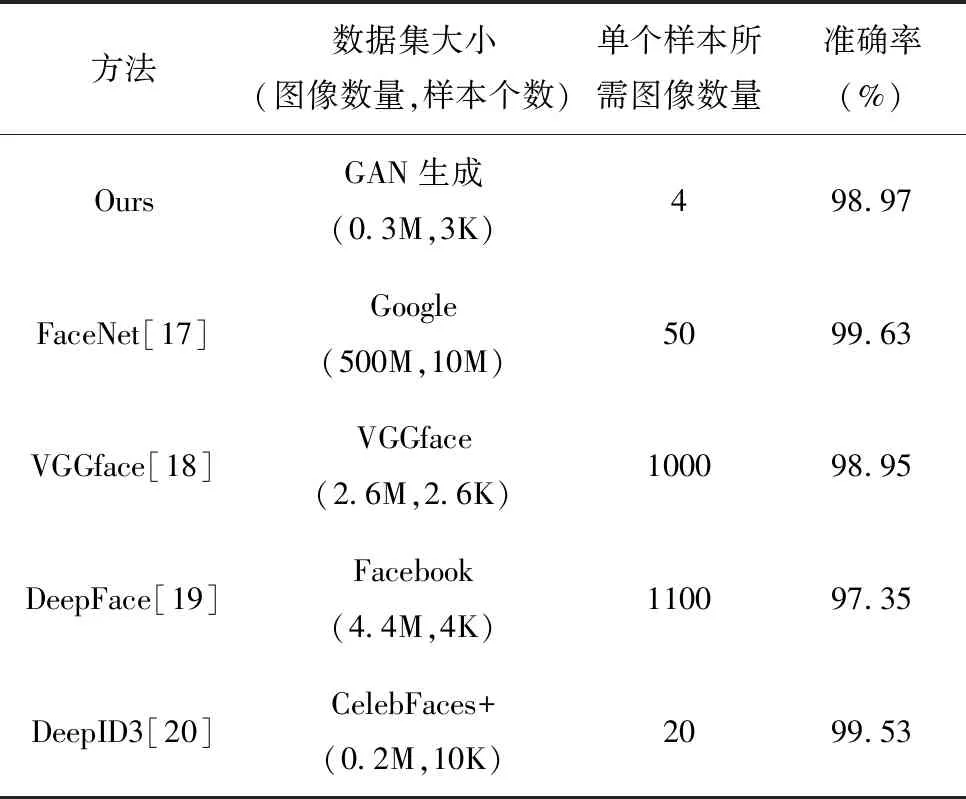
表3 与经典方法的对比
对比结果表明,利用小样本使用GAN生成的虚拟样本进行网络训练的效果可以达到使用真实图像进行训练的效果,证明了利用GAN进行小样本数据增强的可行性。
在上述结果的基础上,为了验证对小样本利用GAN生成的复杂条件下的虚拟样本进行身份识别训练的效果,测试样本使用由各种复杂条件下的真实图像组成的测试集1到测试集4并调用训练好的身份识别模型分别进行性能测试。选择从各种复杂条件下的识别率与现有的较新算法进行了对比,对比结果如表4所示。

表4 与现有算法的对比
实验结果表明,基于域转换或基于样式混合的GAN所生成的复杂条件下的人脸虚拟样本可以脱离真实数据集单独使用进行网络的训练。同时,通过与现有算法的对比,认为利用GAN对小样本进行数据增强,扩展小样本的数据分布是可行的。通过该方法可以解决小样本中样本数量不足,数据分布不均衡的问题;也可以解决传统方法中搜集大量数据集困难的问题;也可以对因为光线、表情、角度等条件的变换或者轻微遮挡所导致的识别率下降问题进行解决;同时对比使用先进算法进行训练的方法也可以在准确率几乎没有差距的情况下,解决这些算法只能针对一种复杂条件进行优化的问题,使得身份识别网络具有更好的鲁棒性。
4 总结
针对目前的复杂条件下的身份识别问题,在仅有小样本时系统性能不佳;利用算法优化又仅能在部分条件下提高性能,整体泛化能力较弱;通过增加数据量与数据分布改善系统性能又面临着数据搜集困难的问题。本文提出了一种对小样本使用GAN进行数据增强从而使得小样本扩充为数据分布广泛、样本数量充足的大数据集,从而进行训练得到高性能模型的方法。通过实验首先证明了对小样本利用GAN进行数据增强的可行性。其次,分别通过GAN对小样本生成的基于光线、表情、角度等条件的变换或者轻微遮挡等复杂条件下的虚拟样本,并进行训练,训练结束后对模型进行性能评价并与现有公开的识别方法进行对比。对比结果表明利用小样本进行数据增强所生成的虚拟样本进行训练可以达到较好的效果,模型在各种复杂条件下的识别率与现有公开算法几乎相同,解决传统算法只能针对一种复杂条件进行优化的弊端,大幅提高了模型的鲁棒性。最后,在本次设计中也存在较多的不足,比如在遮挡面积与时间复杂度等方面,这将在下一步研究中进行改进。
