基于孪生网络的目标跟踪算法综述
2023-09-18马玉民钱育蓉周伟航公维军帕力旦吐尔逊
马玉民,钱育蓉,周伟航,公维军,帕力旦·吐尔逊
(1.新疆大学软件学院,新疆 乌鲁木齐830000;2.新疆维吾尔自治区信号检测处理重点实验室,新疆 乌鲁木齐 830046;3.新疆大学软件工程重点实验室,新疆 乌鲁木齐 830000;4.新疆师范大学,新疆 乌鲁木齐 830000)
1 引言
近年来,随着人工智能[1]的热潮以及计算机视觉领域的不断进步,目标跟踪相关研究也得到了充分的发展。截至目前,基于视觉的目标跟踪已广泛应用于视频监控、城市交通以及军事等领域[2,3]。例如,视频监控通过使用电子输入设备捕获大量视频数据并通过目标跟踪算法监控目标数据,从而完成对目标的跟踪定位,提前预知目标大体走向,避免危险的发生。在城市交通领域,通过对车辆等运动目标的实时跟踪,再对获取的数据进行分析验证,从而判断是否有异常行为,为监管提供了更为有效的手段。在军事领域,通过无人机等侦察手段,进行航拍目标跟踪,获取目标运动状态,并根据该状态做出相应战略措施,其中目标跟踪起到了至关重要的作用。
虽然目标跟踪算法已经得到较为广泛的应用,但由于跟踪场景种类繁多,环境复杂多变,导致目前仍没有一个合适的算法可以应对现有的所有情况,目标跟踪仍是一个具有挑战的任务。如图1所示,目标跟踪一般由5个部分组成,分别是生成运动模型、特征提取、观测模型评分、模型更新以及预测集成[4,5]。
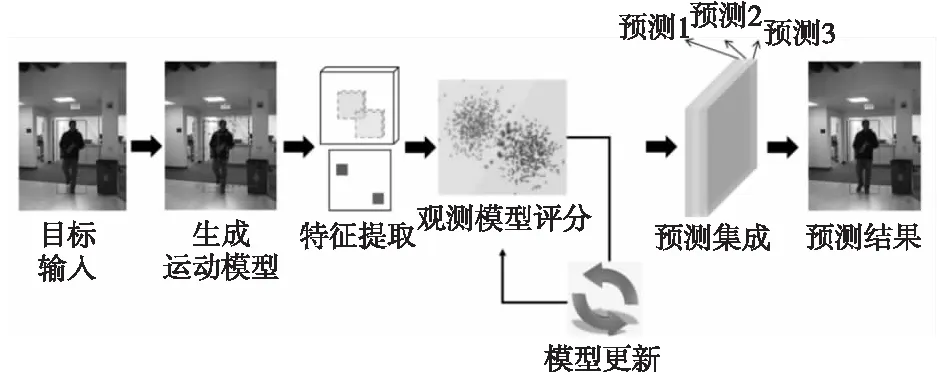
Figure 1 Main components of target tracking
在给定目标输入以及对应边界框的情况下,目标跟踪算法仍要克服包括光照变化、尺度变化、形变、运动模糊、快速运动、平面内旋转、平面外旋转、出视野、背景干扰以及低像素等[6]挑战。这些挑战共同决定了目标跟踪是一项极为复杂的任务,目标跟踪算法不仅要尽可能解决上述挑战带来的困难,也要同时兼顾准确率和实时性。
2 传统的目标跟踪算法
传统的目标跟踪算法通常被分为生成式模型方法和判别式模型方法[7],其划分准则和依据为初始目标模型采取的建模方式[8]。
2.1 生成式模型方法
生成式模型的初始目标模型是在当前帧对目标区域建模,下一帧以相似度的度量为准则,选择与目标模型最相近的区域作为预测位置,并更新为新的目标模型。
Comaniciu等人[9]构建目标模型的均值漂移(Mean Shift) 向量,该向量始终指向样本点最密集的区域并快速收敛,从而实现目标跟踪。MeanShift算法因计算简单、实时性好,同时又能较好地应对遮挡与形变等状况而得到了广泛的应用和研究。后来Vojir等人[10]使用经典颜色直方图特征在原有的均值漂移算法上增加了尺度估计,提出了ASMS(Adaptive Scale Mean Shift)算法。ASMS解决了由背景混乱导致的尺度扩张和相似物体的尺度内爆问题,进一步提高了算法的适用度。
与均值漂移这一类内核方法[11]不同,Nummiaro等人[12]基于贝叶斯估计理论,提出了粒子滤波算法,该算法对于非线性系统有着较好的建模能力,从而取得了较好的效果。Zhang等人[13]基于奇异值分解的新型卡尔曼粒子滤波器,使用卡尔曼滤波器来生成复杂的粒子预测分布,改善了原有的滤波效果。次年,他们又通过添加层次采样,并使用粒子配置中提取的群体智能作指导,克服原有的样本贫化问题,提出了一种基于粒子群智能的粒子滤波算法[14]。
2.2 判别式模型方法
判别式模型方法将当前帧分为目标区域和背景区域2个部分,运用机器学习的方法训练出一个最优判别函数,从而在后续帧中找到符合判别函数的最优解区域作为目标区域。
基于相关滤波思想的跟踪算法是典型的判别式模型方法[15]。Bolme等人[16]通过高斯函数标识样本标签,将建模问题转化为频域求解,提出了MOSSE(Minimum Output Sum Square Error)算法,极大地提高了跟踪算法的速度。Henriques等人[17]在相关滤波的基础上对正样本增加了循环移位,从而产生了一个新的样本集合,利用循环矩阵的性质,降低模型复杂度,提出了CSK(Circulant Structure with Kernels)算法,并在后来使用方向梯度直方图特征以及高斯核函数代替灰度特征,提出了KCF(Kernel Correlation Filter)[18]算法。在此基础上,研究人员又融合了多种特征并兼顾尺度变化,提出了SAMF(Scale Adaptive Multiple Feature)[19]和KCFDP(Kernel Correlation Filter with Detection Proposals)[20]等算法继续改进KCF,并取得了一定成效。
基于深度学习[21]的目标跟踪算法是判别式模型方法的另一主流方法。Wang等人[22]最早将深度学习应用于目标跟踪领域,但其算法的性能不如当时其他算法的。Nam等人[23]提出了一种基于卷积神经网络[24]的多域学习算法MDNet(Multi-Domain Convolutional Neural Network),该算法将图像分类任务中的预训练模型VGG-M(Visual Geometry Group-M)[25]作为网络的初始化模型,利用不同的视频序列进行离线训练,在精度上取得了重大的突破。
将目标跟踪转化为二分类问题可以更好地关注视频中目标和背景的区分,所以判别式模型方法普遍优于生成式模型方法。但是,即使深度学习方法进一步提高了判别式模型方法的精度,但其引入了大量的卷积计算,导致算法的跟踪速度变慢,很难达到实时跟踪的目的,这使得判别式模型方法很难兼顾精度与速度。
3 基于孪生网络的目标跟踪算法
基于孪生网络的目标跟踪算法将跟踪问题转化为相似度度量问题,并在发展过程中逐渐从简单的相似度匹配问题延伸到分类与回归的综合问题。与传统方法相比,孪生网络特殊的网络结构提高了样本的利用率,在有限样本中提取出了更多特征,同时其结果在一定程度上保证了精度和速度的平衡,并提高了算法的鲁棒性。
3.1 孪生网络本质和发展
孪生网络结构的根本在于孪生——即基于2个或多个人工神经网络建立的耦合框架。一般同时接收2幅图像作为网络的输入,输出一个相似度数值,如图2所示。狭义的孪生网络结构是由2个结构相同、权值共享的人工神经网络组成。广义的孪生神经网络可由任意的2个人工神经网络拼接而成。本文主要介绍狭义的孪生网络。

Figure 2 Structure of Siamese network in narrow sense
孪生网络的原始过程是将输入映射为一个或多个特征向量,使用2个向量之间的“距离”来表示输入之间的差异,也就是相似度数值。这个数值在2个或多个输入相似或属于同一类别时较小,输入不相似或不属于同一类别时较大。这里相同结构仅代表有相同的参数和权重,可以在2个子网上同时进行更新。
Bromley等人[26]在首次提出孪生网络这个概念时,将其用于签名验证,并取得了相对不错的结果。
Zagoruyko等人[27]研究了如何从图像数据中直接学习到一个普适性的相似度函数用于图像匹配,结果表明孪生网络在图像匹配领域具有较大的优势。
Melekhov等人[28]提出了一种基于孪生网络的全图像相似度预测方法,结果表明孪生网络在图像比对任务中具有较好的可行性和竞争力。
Tao 等人[29]通过使用孪生网络学习一个匹配函数,以第1帧做模板,其他帧与第1帧进行匹配计算,选最高分帧作为目标,提出的SINT(Siamese Instance Search for Tracker)算法首次使用孪生网络完成了目标跟踪任务。
SINT的成果虽然证明了孪生网络可以用于目标跟踪领域,但其效果一般而未引起广泛注意。同年Bertinetto等人[30]提出的SiamFC(Fully-Convolutional Siamese Network)方法,让研究人员看到了孪生网络的潜力与前景。该方法设计了一个端到端的全卷积孪生跟踪网络,输出是标量值的得分图,尺寸取决于候选图像的大小。其网络结构如图3所示,在跟踪过程中,以Z作为输入的模板图像,X作为输入的搜索图像,接着对2个输入分别进行φ变换进行特征提取。生成的特征图进行互相关操作,即卷积操作,生成响应图。最后将响应图进行双三次插值生成图像确定目标位置。
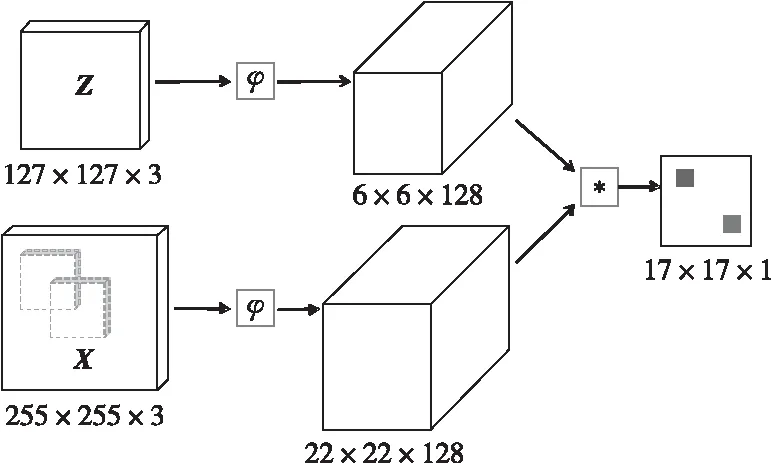
Figure 3 Structure of SiamFC
3.2 基于孪生网络方法的改进
SiamFC在取得具有竞争力的结果的同时,其在鲁棒性和准确率方面的表现仍有所欠缺,但却让研究人员看到了孪生网络更多的可能性。截至目前,研究人员改进的基于孪生网络的目标跟踪算法在准确率和实时性上都已经赶超了传统跟踪算法和其他基于深度学习的算法,本节将介绍对应的改进的孪生网络目标跟踪算法。
3.2.1 额外的分支
He等人[31]观察到图像分类任务中的语义特征和相似性匹配任务中的外观特征互补,在原有的SiamFC的基础上,增加了语义分支,并在该分支上加上通道注意力模型,该模型将网络输入的特征分为3*3的块,然后对每块进行最大池化处理,再通过多层感知机,得到最后每个通道的权重值,选择对特定跟踪目标影响最大的通道。SASiam(Semantic and Appearance Siamese Network)的2个分支是分开训练的,只在测试阶段进行加权求和。
如图4所示,z表示目标图像,X表示搜索区域图像。hs(zS,X)与ha(z,X)分别表示双分支卷积得到的映射结果,通过加权求和,得到最终相似度结果h(zS,X)。SASiam的额外的分支为孪生网络目标跟踪算法从传统的统一计算处理到之后的分别处理,综合计算损失奠定了基础,扩宽了研究人员的视野。
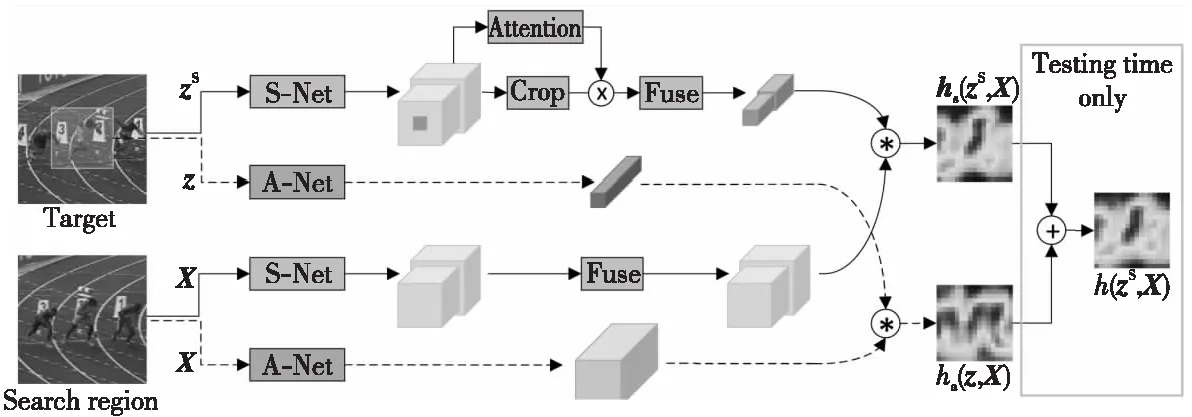
Figure 4 Structure of SASiam
3.2.2 锚设计
SASiam虽然将分类和相似性检测相结合,但并没有对边界框进行回归,浪费了时间和空间,但同年的Li 等人[32]受到Faster R-CNN(Faster Regions with Convolutional Neural Network features)[33]的启发,在提出的SiamRPN(Siamese Region Proposal Network)中引入了RPN模块来产生候选区域。如图5所示,RPN候选区域由2个分支组成,一个是用来区分目标和背景的分类分支,另一个是微调候选区域的回归分支。其中,x,y,w,h分别表示回归得到矩形框的中心坐标和矩形的长与宽;n表示锚框的数量;k表示帧数。RPN通过对多个锚框上产生的多种矩形进行分类和回归,得到感兴趣的区域。

Figure 5 Structure of SiamRPN
在分类分支上,模板图像和检测图像特征先经过卷积处理,其中,模板分支的通道数会增加到对应锚框数量的2倍,对应前景和背景信息,并在后续操作中作为检测图像特征的卷积核,最终返回相应锚框数量的维度为2的分数图,也就是对应的分类分数。在回归分支上,类似地,模板分支的通道数会增加到4n倍,与分类分支不同,这些通道最终直接返回每个样本的位置回归值。
SiamRPN锚设计使得其在回归方面表现优异。但Zhu等人[34]后续发现,该算法在面对目标短时间内消失(超出视线、全遮挡、翻面等)情况时,即使跟踪失败,分类的相似度量依旧可保持较高的分数。因此,在不修改SiamRPN的原有骨干网络的情况下,Zhu等人[34]提出了DaSiamRPN(Distractor- aware Siamese Region Proposal Network)。如图6所示,该算法引入ImageNet Detection[35]和COCO(Microsoft Common Objects inCOntext)[36]数据集,并使用数据增强技术增加了3类样本对:正样本对、相同类别和负样本对不同类别的负样本对。

Figure 6 New sample pairs in DaSiamRPN
根据新增的负样本对,DaSiamRPN在原有的相似度量函数基础上,添加了负样本的影响学习。如图7所示,新的相似度量函数得到的相似度评分可以正确反映目标丢失现象(评分降低)。这种正确度量使DaSiamRPN可以较为精确地评估目标丢失,在目标丢失后,使用由局部到整体的策略逐步扩大搜索区域,从而在目标重现时可以快速且准确地重新跟踪到它。
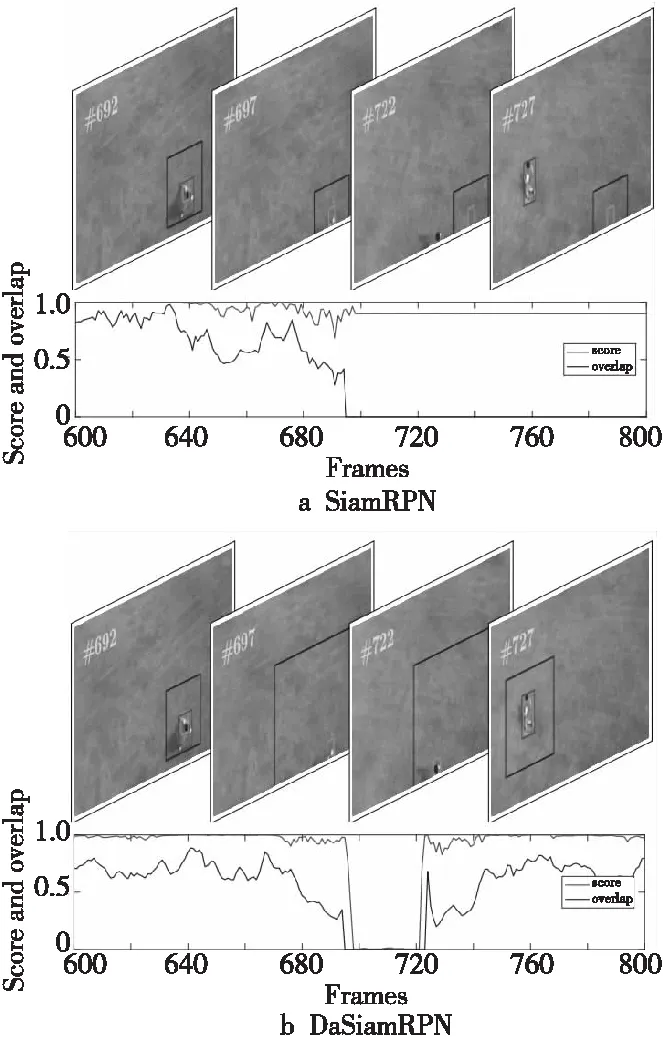
Figure 7 Detection scores and according overlaps of SiamRPN and DaSiamRPN
3.2.3 骨干网络优化
浅层的AlexNet[37]骨干网络难以从现有的数据集中挖掘出更多的知识,研究人员也尝试使用深度神经网络替换掉孪生网络中的浅层骨干网络,但大都收效甚微。Zhang 等人[38]通过实验分析认为深层网络不会带来改进的主要原因是:神经元感受野的大幅度增加导致特征识别和定位精度降低;卷积的网络填充导致了学习时的位置偏差。并通过定量分析找到了影响深层神经网络的多个因素,包括网络的深度和宽度、步长、填充、感受野和输出特征大小。再通过定性分析,认为网络在填充之后,特征提取时会提取到填充的特征;当目标移动至图像边界时,不能精确地指示出目标的位置。
Zhang等人[38]认为适用于孪生网络的深层骨干网络步长不应该相应增加,而是保持在4或8即可,感受野的大小应为模板图像的60%~80%。对于完全卷积的孪生网络,处理2个网络之间的感知不一致问题是至关重要的。Zhang等人给出了2种可行的解决方案:一种是删除网络中的多余的填充工作,另一种则直接裁剪受填充影响的特征并最终提出了SiamDW(Deep and Wider Siamese Network)。经过裁剪修改的神经网络有更高的准确率。
如图8所示,SiamDW破除了孪生网络无法使用深层神经网络的枷锁,使孪生网络目标跟踪算法可以从原有的图像中获取更多的特征信息,也在一定程度上缓解了目标跟踪任务数据集较少而无法得到有效训练的问题。深层知识为回归任务提供了更多有效信息,使算法的性能得到了较大提升。

Figure 8 Accuracy comparison of SiamDW backbone networks
同年,Li等人[39]提出的SiamRPN++中使用了修改后的残差网络[40],与SiamDW类似,为了定位的准确率,将最后2个残差模块的步长减少到8,并使用了空洞卷积[41]技术。这样既增大了感受野,也利用了预训练参数。这种修改使最后3个残差模块的分辨率始终一致,所以作者又使用了多层融合技术。此外,作者还修改了互相关操作,并将新的互相关操作命名为深度互相关,如图9所示,这种改进使参数量大幅下降,同时也使整体训练变得更为稳定,加强了网络的整体性。类似地,SiamRPN++的作者也用MoblieNet[42]等网络进行了相同的改动和实验。
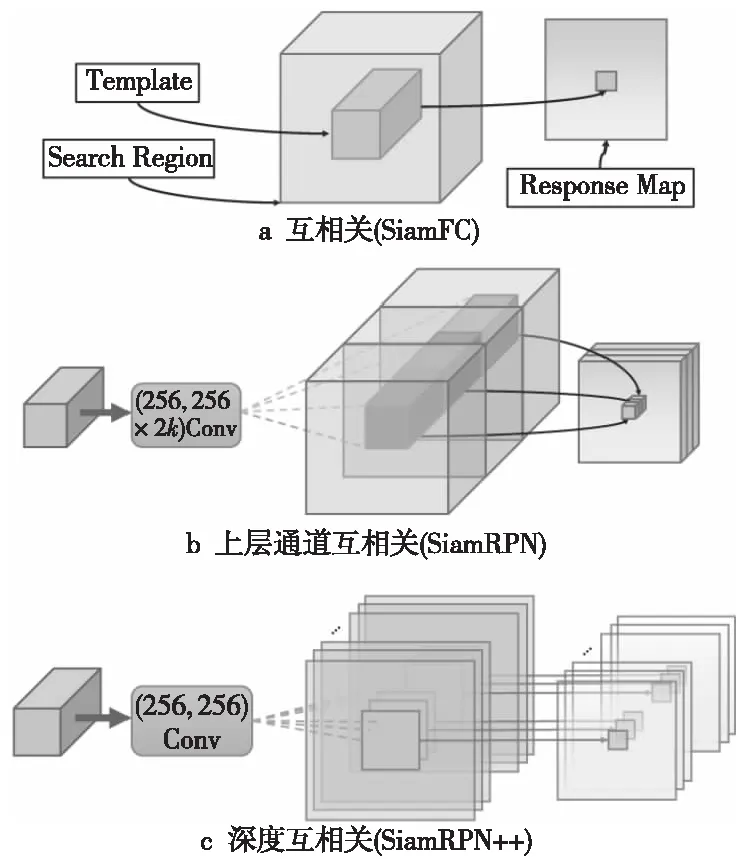
Figure 9 Differences between deep-wise cross-correlation method and traditional cross-correlation method
3.2.4 无锚设计
Li等人[43]认为,以SiamRPN为首的RPN头需要对锚框选择做出仔细调整,这个工作费时费力,于是提出了一种利用无锚的级联KPN(Keypoint Prediction Network)特征融合头实现的算法,并命名为SiamKPN。如图10所示,SiamKPN使用的KPN模块包括3个3×3的卷积和1个5×5的深度互相关模块,并将返回的结果经过2次卷积得到热图,该热图有5个通道,其中1个通道用于估计目标的中心点,2个用于解决步长导致的离散误差,另外2个则用于估算目标大小。SiamKPN在使用3层级联的同时,缩小了标签热图的方差,沿着级联方向逐渐细化,加强了特征信号的监督强度。这种修改使得目标中线点周围的区域特征更加突出,前后景差异更加明显,从而更容易区分目标与类似的干扰项。

Figure 10 Structure of SiamKPN
类似地,Chen等人[44]认为使用锚框的多尺度设计来估计目标大小,虽然使精确度有显著提高,但这种启发式设计也引入了大量的参数,增加了计算复杂度。于是在之后设计了无锚跟踪器SiamBAN(Siamese Box Adaptive Network),它直接预测了相关特征映射上每个空间位置的前景与背景类别评分和一个4D向量。与传统的回归方法不同,该4D向量描述了从边框的4个侧面到搜索区域对应的特征位置中心点的相对偏移。如图11所示,一个骨干网络中有多个特征融合头处理单元用于进行自适应边框预测。与SiamRPN++类似,这些处理单元也使用模板分支的卷积结果,与检测分支深度互相关得到对应层的互相关特征图。最后将各个卷积层的特征图进行融合,得到最后的互相关结果。SiamBAN的无锚框设计在不损失精度的情况下,将输出所需要的变量数减少到有锚框设计的1/5,极大地提高了训练与跟踪的速度。
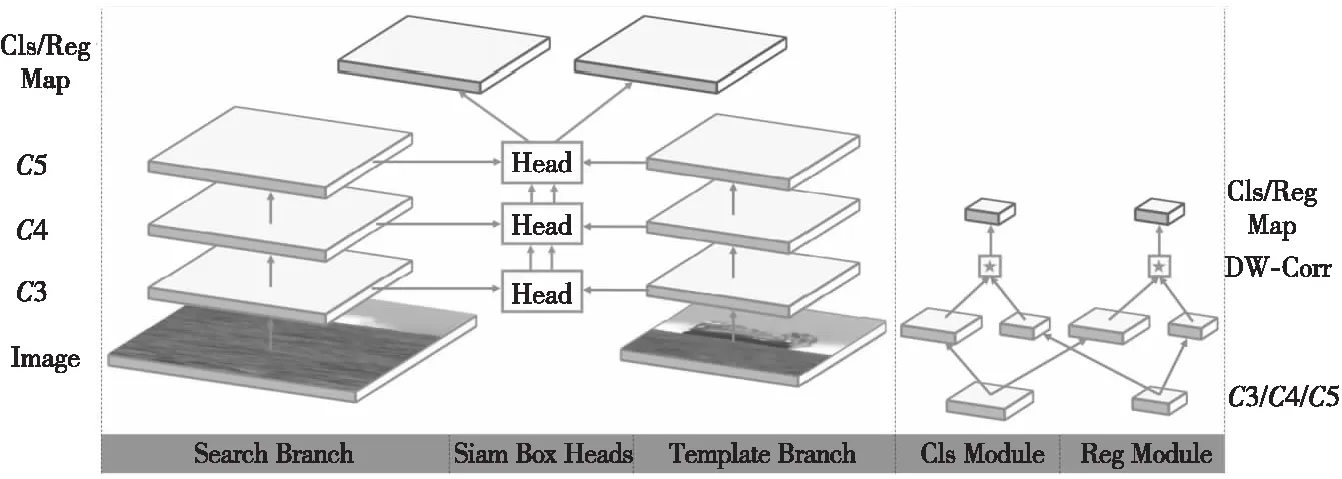
Figure 11 Structure of SiamBAN
Xu等人[45]受到质量评估[46,47]的启发,在卷积模块后的分类分支中增加了质量评估分支,提出了SiamFC++。质量评估分支对远离中心点的位置进行约束,使距离中心点近的像素点评分高,远离中心点的像素点评分低,如图12所示,质量评估分支最终与原分类分支结果点乘,得到分类分支结果。最后与回归分支使用argmax函数结合。

Figure 12 Processing of SiamFC++ convolution results
综合SiamBAN和SiamFC++的优势,Guo等人[48]提出了SiamCAR(Siamese fully Convolutional classification And Regression),为了抑制过大的位移导致的精确度下降,在SiamBAN的基础上增加了类似SiamFC++的质量评估分支,从而使网络在跟踪时更精确地获取到目标的中心点。并且,SiamCAR修改了SiamBAN互相关特征图的融合方式,将原来的相加取平均值修改为拼接后降维的方法,通过训练修改权重,找到最佳的融合方法。
3.2.5 Transformer方法
相关性在孪生网络跟踪领域起着关键作用,但该操作实际上是一个局部线性匹配的过程,易丢失语义信息,继而陷入局部最优。Chen等人[49]受Transformer[50]启发,提出了基于注意力的特征融合网络TransT(Transformer Tracking)。TransT设计了一种独特的特征融合层,先使用自注意力ECA(Efficient Channel Attention)模块分别增强来自模板分支和搜索分支的特征信息,再使用交叉注意力CFA(Cross Feature Augment)模块同时接收各分支自身和另一个分支的特征,并通过多头交叉注意力进行特征融合。如图13所示,TransT将孪生网络提取的特征经过降维后,输入由4个独特的特征融合层叠加的融合层,再使用一个额外的交叉注意力融合2个分支的特征。在预测结果时,使用无锚方法直接预测标准化坐标,从而使整体的跟踪框架更加简洁。
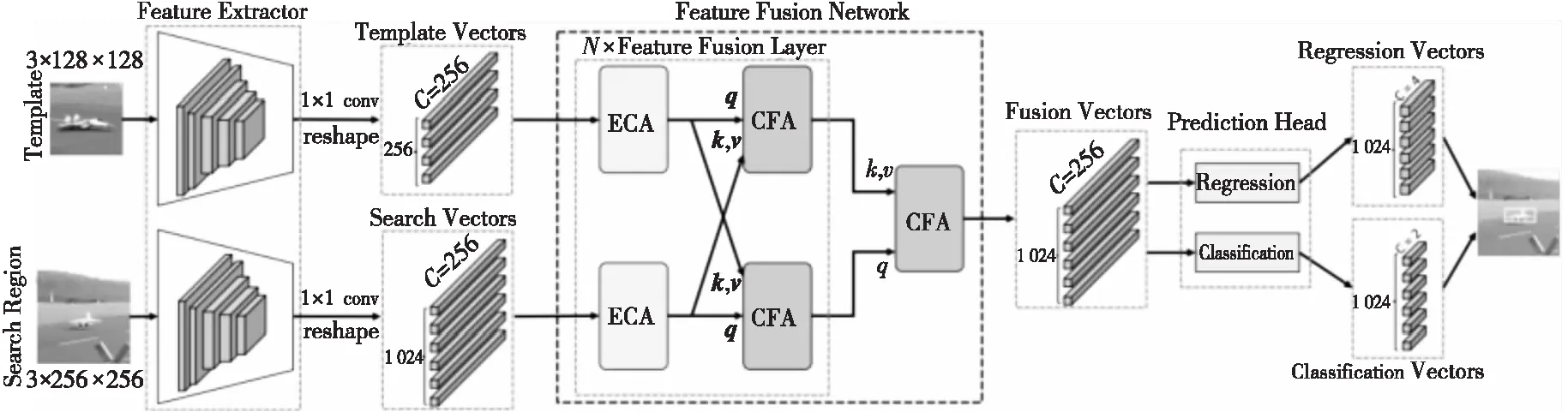
Figure 13 Structure of TransT
与TransT多个特征融合层叠加不同,Zhao等人[51]提出了TrTr(visual Tracking with Transformer)算法。如图14所示,该算法设计的特征融合网络中,先分别使用自注意力模块增强模板分支和搜索分支的特征信息,之后,模板分支经过一个额外的前馈网络FPN(Feature Pyramid Network)后,直接与搜索分支的特征使用交叉注意力进行特征融合。
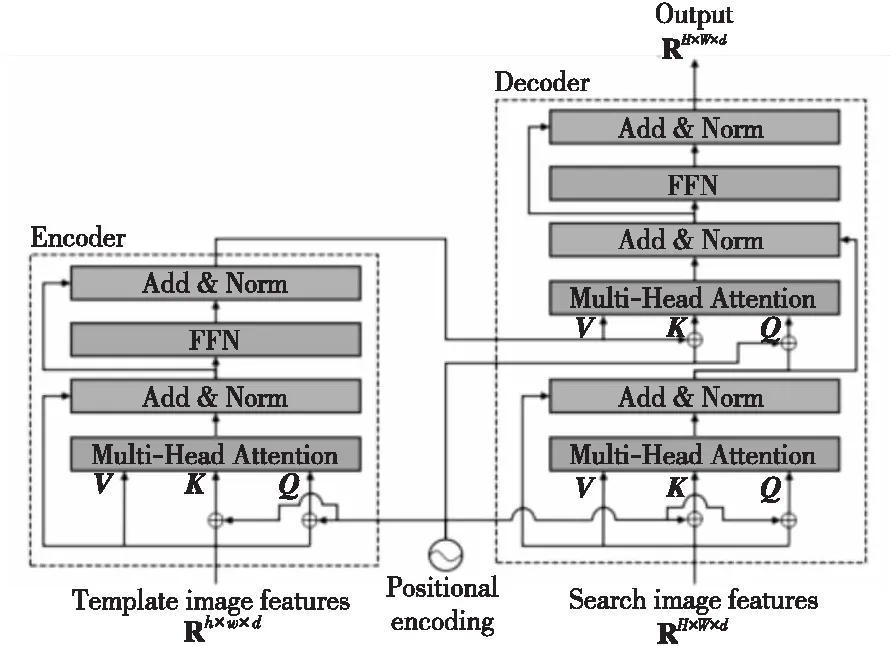
Figure 14 Transformer structure of TrTr
TrTr的特征融合网络的设计更接近传统的Transformer,对注意力使用和特征图处理的探讨相较TransT略有不足,但其使用了额外的在线学习方法,提高了跟踪的准确率。
受到DETR(DEtection TRansformer)[52]启发,Yan等人[53]提出了STARK算法,不仅将原Transformer的编码器层和解码器层分别叠加6次,还使用角点概率分布设计了独特的预测头。如图15所示,该预测头首先从编码器中获取搜索分支的特征,计算与解码器的输出嵌入之间的相似程度;再使用该相似度的得分与搜索分支的特征相乘以突出重要特征;最后使用一个简单的全卷积网络完成对角点的预测。不仅如此,STARK考虑到目标物体的外观可能会随时间发生显著变化,对算法进行进一步优化,如图16所示。首先,在输入端引入中间帧采样,以提供额外的其他时间信息。其次,添加了一个额外的得分预测头过滤掉目标完全遮挡或移除视线等不可靠帧覆盖动态模板。最后,将训练过程分为2个阶段,分别关注定位和分类任务,防止联合学习导致2个任务的解决方案都不理想。
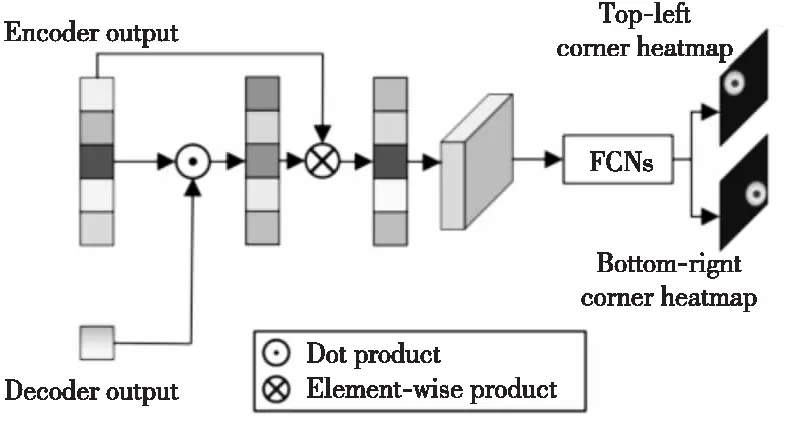
Figure 15 Structure of STARK’s box prediction head
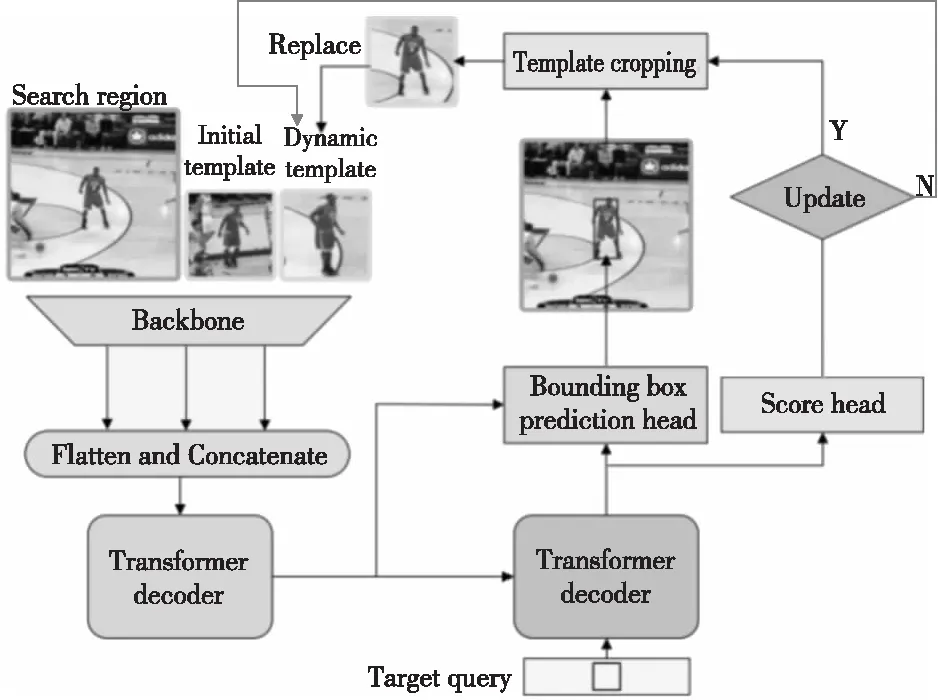
Figure 16 Framework of spatio-temporal tracking
与残差网络相比,Swin-Transformer[54]可以提供更紧凑的特征表示和更丰富的语义信息,Lin等人[55]以此为骨干网络,设计并提出了SwinTrack算法。如图17所示,得益于骨干网络的更换,SwinTrack可以接收多模态的数据作为输入,从而使用基于连接的融合方法代替基于交叉注意的融合方法,降低了运算的复杂度。不仅如此,在预测分类时引入目标候选包围框与真实目标标注的交并比得分,使分类分支的预测更加准确。
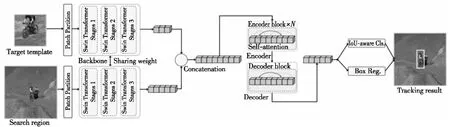
Figure 17 Structure of SwinTrack
3.2.6 其他改进方法
Voigtlaender等人[56]设计了一种将Faster R-CNN中的RCNN模块级联3次的重检测头,以得到更精确的特征图相似评分,并提出了SiamR-CNN。如图18所示,该算法先使用孪生网络进行特征提取后,将第1帧的特征中的目标区域特征与当前帧经RPN网络得到的候选区域特征结合,使用重检测头回归计算这些候选区域与目标区域的相似度的得分。再使用其中得分较高的结果,与上一帧以相似方法得到的区域特征排列组合,再使用重检测头回归计算。继而完成了当前帧与第1帧、当前帧与上一帧的关联,得到了更精确的回归边框。
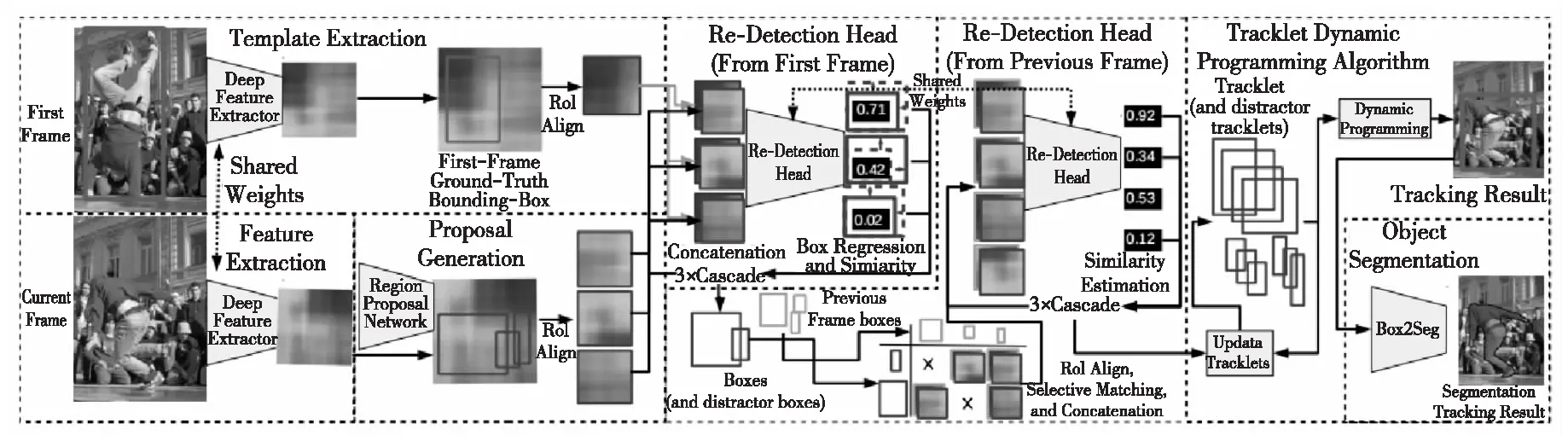
Figure 18 Structure of SiamR-CNN
在跟踪过程中,SiamR-CNN对所有可能的结果都进行检测,并随着新目标的出现产生新的跟踪轨迹,这些轨迹与真实的轨迹动态关联,得到正确的跟踪结果。这些方法的融合极大地提高了跟踪的精度,但复杂的计算导致网络的实时性有待提高。
SiamKPN等无锚框设计摆脱了复杂的超参数调整,但与SiamRPN等跟踪方法一样,仍将固定比例的裁剪区域作为模板特征,这种方法可能会引入很多的背景信息,或者丢失大量的前景信息,特别是当模板目标的宽高比发生了急剧的变化时尤为突出。
Guo等人[58]在设计SiamCAR后继续探索其他模块与孪生网络结合的可能性,利用注意力机制聚合相邻节点的特征,构建了适合孪生网络的图形注意力模块[57],如图19所示。作者根据该模块设计了SiamGAT(Siamese Graph Attention Tracking)算法[58]。

Figure 19 Graph attention module of SiamGAT
SiamGAT将模板帧中标记的边框投影到特征图上,从而得到一个感兴趣的区域,并仅使用这个区域的像素作为模板特征,这些像素作为模板子图的节点GT。而在搜索帧中,所有的像素都被当作搜索子图的节点GS。GT中的所有节点ht被aij赋予注意力后与GS中某个节点hs进行聚合表达,再将该聚合表达与原节点hs组合起来得到更强的特征表达。W为每次线性变换所使用的矩阵。这2幅子图作为图形注意力模块的输入,最终重构出每个搜索节点的表示。最后,SiamGAT使用SiamCAR中的分类与回归的特征融合头处理网络。2个分支共享图形注意力模块的输出结果,并最终得到跟踪结果。
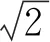

Figure 20 Special process of SE-SiamFC
4 实验对比
本文使用OTB2015[6]、VOT2018[60]与LaSOT(Large-scale Single Object Tracking)[61]作为上述所有基于孪生网络的目标跟踪算法的测试数据集,通过算法间的对比直观地展示它们的跟踪性能。
4.1 OTB2015
Wu等人[6]在前人研究的基础上提出了目标跟踪基准OTB2013,并在后续的研究中,将最初的50个视频序列拓展到100个,即如今的OTB2015测试数据集,也称OTB100。OTB2015包含灰度图像和彩色图像,数据集完全公开,而且涉及了目标跟踪领域大部分复杂情况的挑战,从而能更加准确地判断目标跟踪算法面对现实生活中各种情况的能力。基于该测试集主要通过2个指标评价目标跟踪算法:
(1)成功率Successrate。将每个视频跟踪算法估计的跟踪框内的像素点个数与人工标注的跟踪框内的像素点个数的交集与并集的比值定义为重合率得分。给定重叠率阈值,当某一帧算法得到的重叠率得分大于该阈值时,视该帧为成功帧。总成功帧数占所有帧数的比值即为当前阈值下的成功率。阈值由0到1,可拟合出成功率的曲线。
(2)准确率Precision。计算每个视频跟踪算法估计的跟踪框中心点与人工标注的跟踪框中心点的距离。给定距离阈值,准确率为2个中心点距离小于给定阈值帧数占总帧数的百分比。根据不同的距离阈值,可拟合出准确率的曲线。
各算法在OTB2015上的测试结果如图21所示。

Figure 21 Comparison of success rates and precision rate of each algorithm on OTB2015
4.2 VOT2018
VOT竞赛作为目标跟踪领域最具权威和影响力的测评平台,由伯明翰大学、卢布尔雅那大学、布拉格捷克技术大学和奥地利科技学院联合创办,旨在评测在复杂场景中单目标跟踪算法的性能。该竞赛使用的数据集由公开测试集与隐藏测试集组成,测试序列涵盖遮挡、光照变化、快速运动和尺度变化等影响因素。评测集逐年进行更新,不断加入更具挑战性的序列,因此被视为视觉目标跟踪领域最难的竞赛。其中,VOT2018由于其特有的反映算法实时性的评价指标而广泛用于测试算法的性能。
与OTB2015包含25%灰度序列不同,VOT2018是全彩色序列,且VOT序列的分辨率更高,评价指标更为完善。基于VOT2018的评价指标主要有以下3个:
(1)平均重叠期望EAO(Expected Average Overlap):是对每个跟踪器在一个短时图像序列上的非重置重叠的期望值,是VOT评估跟踪算法的最重要的指标。
(2)准确率(Accuracy):是指跟踪器在单个测试序列上的平均重叠率(2个矩形框的交集部分除以并集部分)。
(3)鲁棒性(Robustness):是指在单个测试序列上跟踪器跟踪失败次数所占比例,默认重叠率为0时跟踪失败。
各算法在VOT2018上的测试结果如表1所示。
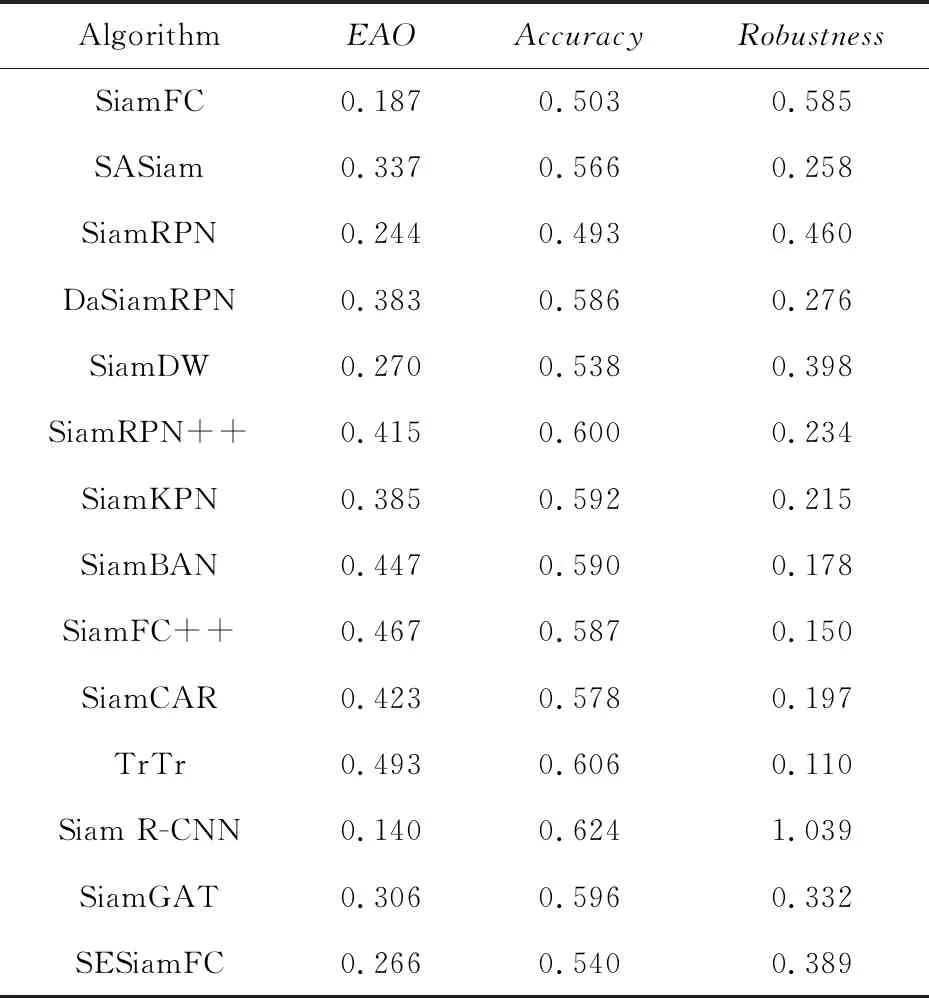
Table 1 Test results of each algorithm on VOT2018
4.3 LaSOT
为了给目标跟踪任务提供一个大规模的训练数据与专业且质量高的评估基准,Fan等人构建了LaSOT数据集。与其他数据集相比,LaSOT提供了70种目标类别,每一种又包含20个序列,即共有1 400个视频。这些视频平均每个长达2 512帧,最低不少于1 000帧。同时,LaSOT提供了丰富的可视化边框注释和自然语言规范,共计352万个高质量人工标注的包围框。各算法在LaSOT上的测试结果如表2所示。实际测试过程中,将每种类别的4个序列用于测试,即共280个序列,总计69万帧。与OTB2015相比,LaSOT不仅提供了评价指标成功率Successrate,还提供了标准化准确率NormalizedPrecision作为更准确体现精度的评价标准。标准化准确率在准确率中心点距离的基础上额外增加了目标大小考量,以降低因准确率对图像分辨率和目标大小过于敏感导致的效果不佳。

Table 2 Test results of each algorithm on LaSOT
5 问题与展望
从实验对比结果来看,SiamKPN、SwinTrack与SiamFC++等无锚设计的算法表现良好,能够在保持高准确率和高实时性的情况下应对光照变化、尺度变化和平面内变化等挑战。但是,在梳理这些算法的结果时,本文也发现了一些普遍问题。下面主要讨论目前孪生网络目标跟踪算法仍需突破的瓶颈,以及未来的研究趋势。
5.1 存在的问题
虽然在近几年基于孪生网络的目标跟踪算法得到了飞速发展,但目标跟踪任务本就复杂,本文对上述所有算法的结果进行对比评估,总结出以下孪生网络目标跟踪算法仍待解决的问题与瓶颈。
5.1.1 网络结构复杂
目前,孪生网络目标跟踪算法虽在一定程度上解决了传统跟踪算法数据量少、泛化能力较差的问题,但网络本身设计复杂,尤其是近几年深层神经网络的引入,这一问题愈加突出。随着时间推移,更多大规模目标跟踪数据集的提出可以为孪生网络目标跟踪算法提供更大帮助,但如何优化网络结构,使数据得到充分利用的同时仍能保证回归速度、训练速度与实时性是基于孪生网络的目标跟踪算法亟需解决的难题。
5.1.2 特殊遮挡
孪生网络目标跟踪算法在面对瞬时遮挡和部分遮挡等问题时,能够快速重新找回目标并继续跟踪。但是,面对如图22所示的长时间遮挡以及频繁遮挡等特殊的遮挡问题时,孪生网络目标跟踪算法准确率较低,甚至可能出现目标丢失的情况。未来目标跟踪任务会越来越复杂,上述的特殊遮挡情况更是屡见不鲜,能否准确找回复杂情况下被遮挡的目标是孪生网络目标跟踪算法的重要问题。

Figure 22 Long time occlusion problem and frequent occlusion problem
5.1.3 回归困难
SiamRPN的提出让后续孪生网络目标跟踪算法将跟踪任务划分成分类与回归2个子任务。在实际训练过程中,算法已经可以准确区分目标的前景与背景。但是,孪生网络目标跟踪算法主流的回归指标IoU(Intersection over Union)[46],在面对完全不重合的目标与完全重合却比例变化的的目标情况时,无法正确表达损失下降的方向,导致回归损失无法继续降低,成为孪生网络目标跟踪算法参数更新时的瓶颈。
5.1.4 局限于平面特征
孪生网络的本质仍是2幅图像的特征匹配问题,当跟踪物体在平面内不发生剧烈变化时,孪生网络目标跟踪算法确实能够发挥较好的性能优势。但是,当物体发生快速翻转、翻折等立体维度的变化时,该类算法并没有高效的应对方法。如图23所示,现实生活中,目标跟踪任务并不只有平面内的简单跟踪,能否正确认识到自身以及周围环境的立体维度的信息,这也是孪生网络目标跟踪算法需要面对的一个难题。

Figure 23 Object flipping problem and folding problem
5.2 孪生网络目标跟踪的展望
上节总结了孪生网络目标跟踪算法面临的瓶颈,这些瓶颈带来难题的同时,也引导着研究人员研究的方向。下面讨论可能会成为今后研究热点的几个问题。
5.2.1 优化骨干网络
虽然SiamDW讨论了卷积神经网络深度对孪生网络目标跟踪算法的影响,但影响骨干网络性能的因素并不只有网络深度。网络的卷积方法(高波卷积[62]和动态卷积[63]等)、使用注意力机制(SE(Squeeze and Excitation networks)[64]、CBAM(Convolutional Block Attention Module)[65]和CA(Coordinate Attention)[66]等)以及引入其他额外模块,都已被证明可以提升视觉图像领域算法的性能。孪生网络目标跟踪算法由于其本质是2个或多个人工神经网络组合的耦合框架,优化骨干网络对于提升算法准确率与实时性事半功倍。
5.2.2 困难样本挖掘
DaSiamRPN证明了额外的训练样本有助于提升算法的整体性能,而针对特殊遮挡等复杂的目标跟踪任务,孪生网络目标跟踪算法需要对困难样本进行额外的训练来改善网络参数。类似目标检测领域中提出的OHEM(Online Hard Example Mining)[67]在线学习算法,训练时选择困难样本进行迭代,代替简单的采样,可以有效提高孪生网络目标跟踪算法在面对复杂挑战时的鲁棒性。
5.2.3 优化评价指标
近年来,GIoU(Generalized Intersection over Union)[68]、DIoU(Distance Intersection over Union)[69]以及CIoU(Complete Intersection over Union)[70]的相继提出,弥补了传统IoU算法在部分情况下参数更新困难的问题(如图24所示)。将更有助于梯度下降的指标引入到孪生网络目标跟踪算法中可以有效降低回归损失。同时,SESiamFC也证明了其他的相似度量函数也可以有效应用到孪生网络目标跟踪算法中,并提高算法的准确率。
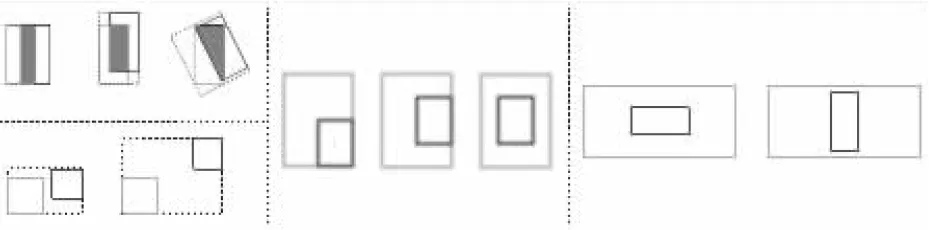
Figure 24 Regression problems that IoU method cannot solve
5.2.4 目标立体建模
3D立体建模已经广泛应用到目标检测[71]和目标识别[72]任务中。将孪生网络目标跟踪算法的平面特征输入修改为空间特征输入,从而使网络学习到目标和周围环境的立体空间知识,提高网络对发生剧烈形变和平面外翻转的目标前后景的识别能力,这种方法还有很大的拓展空间。
6 结束语
基于孪生网络的目标跟踪算法是目标跟踪领域的研究热点。随着目标跟踪算法的不断发展,该方向也逐渐受到研究人员更为广泛的关注。本文首先介绍了目标跟踪的现状以及孪生网络目标跟踪算法的本质与由来,并讨论了多种以孪生网络为基础的目标跟踪算法以及它们的特点与优势。通过使用近年主流且具有说服力目标跟踪数据集作为测试标准,对比了所有介绍的基于孪生网络目标跟踪算法的性能差异。根据实验结果,讨论了当前基于孪生网络的目标跟踪算法的瓶颈并分析了日后的发展趋势。
