计算机网络大规模高维数据流异常数据挖掘
2023-09-18郑湘辉张雪冰
郑湘辉,张雪冰
(合肥财经职业学院 人工智能学院,安徽 合肥 230601)
互联网以及计算机技术的迅猛发展,使得计算机与互联网被广泛应用于人们的生活以及工作中,这不仅使计算机网络中存在的计算机网络数据流数据不断增加,也使计算机网络数据流数据呈现出多样化的特征,逐步形成计算机网络大规模高维数据流[1-3]。与此同时,计算机网络环境的日益复杂化无疑给各种网络攻击行为提供了可乘之机,各种攻击类异常数据的存在,严重危害计算机网络安全,若不及时对其实施有效挖掘,有效防范其可能带来的计算机网络安全风险,长此以往,势必会对人们的生活以及工作带来非常不利的影响[4-5]。
针对上述问题,康耀龙等人研究基于朴素贝叶斯的计算机网络大规模高维数据流异常数据挖掘方法[6]、仇媛等人研究的基于长短期记忆网络和滑动窗口的计算机网络大规模高维数据流异常数据挖掘方法[7]。前者通过重构假象空间,计算网络数据流数据向量之间的欧式距离,有效获取度量策略;通过网络数据流数据偏差比计算以及网络数据流数据节点概率化瞬态计算等操作实现计算机网络数据流异常数据挖掘;后者使用LSTM网络对计算机网络数据流数据实施有效预测,并合理求解其与实际计算机网络数据流数据之间存在的差值,之后为各计算机网络数据流数据挑选恰当的滑动窗口,对存在于滑动窗口某一区间内的全部差值执行有效分布建模操作,再依据各差值的概率分布密度,判别数据异常状况。二者均可实现计算机网络数据流异常数据挖掘,但是当待挖掘的计算机网络数据流数据规模庞大时,异常数据挖掘效果并不理想。
加权离群分数算法在计算机网络大规模高维数据流异常数据挖掘工作中优势显著,可较为理想地从计算机网络大规模高维度数据流数据中分离出计算机网络数据流异常数据。为此,本文提出基于加权离群分数的计算机网络大规模高维数据流异常数据挖掘方法,更好满足实际工作需要。
1 计算机网络大规模高维数据流异常数据挖掘方法
1.1 Python网络爬虫计算机网络数据流数据采集
能够从计算机网络中采集到有效的计算机网络数据流数据是能够完成计算机网络数据流异常数据挖掘工作的关键[8-9]。鉴于爬虫技术在计算机网络数据采集工作方面的优势,本文使用基于Python网络爬虫的数据采集技术采集计算机网络数据流数据,具体的采集技术架构如图1所示。
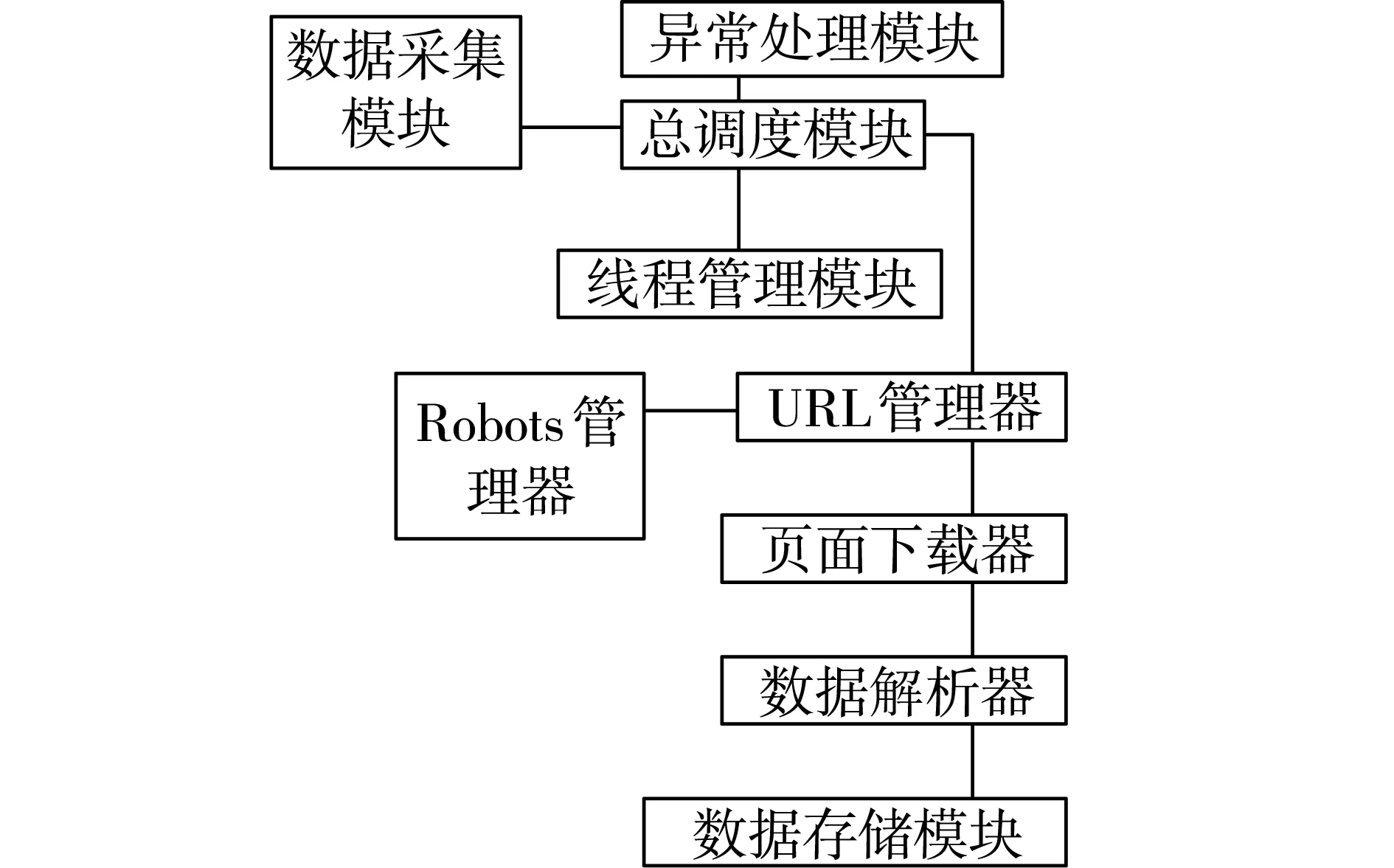
图1 采集技术架构
在该采集技术架构中,总调度模块相当于整个数据采集工作的总指挥,它作为爬虫程序的有效总入口,其主要职责是对各个模块实施合理调度;URL管理器承担的主要职责是负责管理全部的URL;页面下载器的主要职责是在URL管理器中获得相应的URL以后,利用其所拥有的优越下载性能获取不同格式的URL页面数据;页面解析器承担的主要职责是对从页面下载器取获的网络数据执行有效的数据处理操作,去除其中的噪声元素,获得较为理想的目标网络数据;数据存储模块的主要职责是对在接收到由页面解析器发送过来的相关网络数据后,对所获数据实施分类存储,将结构化以及非结构化数据分别发送给相应的数据库以及本地硬盘存储,并实施合理的索引构建操作;线程管理模块的应用,主要是能够使客户按实际需求设置爬取作业需要的线程数量,从而显著提升数据采集工作的效率;robots管理器承担的主要职责是对爬取网站当中应用的robots协议执行有效的下载与更新操作,并按robots协议相关描述对爬取地址目录执行合理调用操作;异常处理模块是技术架构中所有模块均接入的模块,一旦数据采集过程发生异常,便可触发异常处理模块实施相应处理,并将其记录到相应的日志信息库中,供实际工作参考。
在实际的计算机网络数据流数据采集工作中,采集架构中的各模块由总调度模块采用合理的总调度程序,实施合理调度完成相应数据采集工作[10-11],用户在确定好将要爬取的计算机网络数据主题后,构建相应的数据库,在完成总调度模块参数初始化设置工作后,总调度模块会在URL管理器中调用出一个URL,并启动robots管理器,合理检验URL目录结构是否符合相关规定,若不符合,需要重新在URL管理器中调用出一个URL,若符合,启动页面下载器,并执行数据下载工作。若下载过程中出现异常,触动异常处理模块实施相应处理,若未出现异常,下载工作完毕后,启动页面解析器实施有效的数据解析操作,辨别所获数据为URL数据还是目标主题网络数据,若为URL数据将其发送至URL数据库实施存储,若是目标主题网络数据,启动数据存储模块向相应的数据库发送数据,存储完毕后,继续执行数据爬取操作,若处理过程出现异常,同样触动异常处理模块实施相应处理。
1.2 计算机网络大规模高维数据流数据清洗
通常采集到的计算机网络数据流数据的规模会比较庞大,数据的维度也会比较高[12-13],加之受采集环境以及各种其他因素影响,获取到的计算机网络数据流数据中,可能会包含一些不相关的,缺失以及错误的数据,这无疑会影响计算机网络数据流异常数据挖掘工作的准确性以及效率。在本文中为收获较为理想的计算机网络数据流异常数据挖掘效果,在采集完计算机网络数据流数据后,使用基于软件总线模型的数据清洗技术对其执行必要的数据清洗操作,具体的数据清洗技术架构如图2所示。
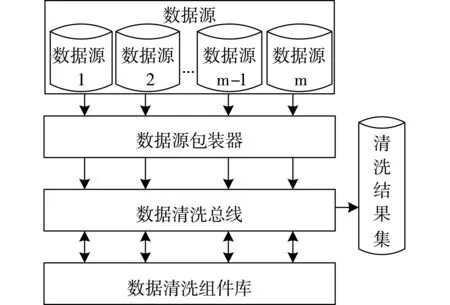
图2 数据清洗技术架构
使用数据源包装器对来自各计算机网络数据源的计算机网路数据流数据执行有效的数据封装操作,将其转换成符合数据清洗总线要求格式的有效数据,并发送给数据清洗总线,数据清洗总线按计算机网络数据中包含的信息调用数据清洗组件库中的相应组件,对计算机网络数据流数据实施合理清洗[14-15],清洗完毕后将其重新发送给数据清洗总线,并将其放入清洗结果集,等待相关专家明确数据无误后,再放入到相应的计算机网络数据库中实施相应存储。
1.3 基于加权离群分数的异常数据挖掘
以往在利用传统加权离群分数算法进行计算机网络大规模数据流异常数据挖掘时,若待挖掘的计算机网络数据流数据存在明显的枢纽现象时,很难以较快的速度准确实现计算机网络数据流异常数据挖掘,针对上述问题,本文使用基于枢纽现象与加权离群分数的离群数据挖掘算法完成计算机网络数据流异常数据挖掘工作。具体的异常数据挖掘流程如下:
(1)对计算机网络数据流数据集中的各个计算机网络数据流数据对象执行K近邻查询操作,获取各计算机网络数据流数据对象i在其他计算机网络数据流数据对象K近邻列表内出现的准确次数,将该次数标记为Gk(i),并通过对Gk(i)执行合理的归一化操作,求解各计算机网络数据流数据对象i的离群分数。具体的求解过程用公式(1)可描述。
ai=1÷(1+Gk(i))
(1)
式(1)中,计算机网络数据流数据对象i的离群分数用ai标记。即使是在计算机网络数据流数据对象i在其余计算机网络数据流数据对象K近邻列表内出现的准确次数为0条件下,式(1)也依然成立。
(2)求解计算机网络数据流数据对象i的K近邻数据对象离群分数和。具体的求解过程可用公式(2)描述。
aggi=∑j∈GG(k,i)aj
(2)
式(2)中,计算机网络数据流数据对象i的K近邻网络数据流数据对象离群分数和用aggi标记;j标记的是计算机网络数据流数据对象i的K近邻;GG(k,i)标记的是i的K近邻列表。
(3)对aggi执行有效的加权操作,获得加权后的aggi。通常拥有较大ai的计算机网络数据流数据对象,会拥有较小的Gk(i)值,也就是说此时计算机网络数据流数据对象i出现在其K近邻数据列表中的概率为0或者极低。因ai从本质上具有一定的离散性能,故对离群的计算机网络数据流数据以及正常的计算机网络数据流数据区分性能并不佳,为显著提升离群的计算机网络数据流数据以及正常计算机网络数据流数据之间的区分度,引入K近邻权值,对aggi执行有效的加权操作,引入的K近邻权值实质上是一种距离信息,该权值实际上标记的是给定计算机网络数据流数据对象所具有的K近邻距离与计算机网络数据流数据集具有的K近邻距离平均值之间相除,获得的有效比值,在本文中用ωi标记,其求解过程用公式(3)描述。
ωi=averDisk(i)÷averDisk
(3)
式(3)中,计算机网络数据流数据对象i的K近邻距离以及计算机网络数据流数据集的K近邻距离平均值分别用averDisk(i)、averDisk标记。
在通过式(3)获取到ωi后,可将具体的aggi加权过程用公式(4)描述。
Waggi=aggi×ωi
(4)
式(4)中,Wggi标记的是执行加权操作后的aggi;ωi标记的是K近邻权值。
(4)执行区分度阈值随机生成操作,并以所获阈值为可靠依据对区分度比例满意值实施有效判别,在本文中将区分度比例满意值标记为α′,以获取的α′为数据支撑,求解计算机网络数据流数据对象的离群度,各个计算机网络数据流数据离群度求解工作完成后,离群度最高的某些计算机网路数据流数据便为离群数据,即计算机网络数据流异常数据。在明确α′后,计算机网络数据流数据对象的离群度可通过式(5)实现求解。
cti=(-α′+1)×ai+α′×Waggi
(5)
式(5)中,计算机网络数据流数据对象i的离群度用cti标记。
1.4 计算机网络大规模高维数据流异常数据类型识别
根据上一小节所阐述的加权离群算法,能够有效判别输入的计算机网络数据流数据是正常数据还是异常数据,但是却无法识别出计算机网络数据流数据的异常数据类型,卷积神经网络虽具有良好的数据分类性能,但不适合大规模高维数据挖掘,但却可以在高维数据规模较小时,用于完成异常数据类型识别工作。为此,在本文中使用卷积神经网络对经加权离群算法挖掘出的计算机网络数据流异常数据实施异常数据类型识别,具体的识别过程如下。
(1)使用基于非负Tucker3分解的高维数据特征提取算法提取计算机网络大规模高维数据流异常数据特征,获取计算机网络大规模高维数据流异常特征数据。
(2)计算机网络大规模高维数据流异常特征数据归一化。对计算机网络大规模高维数据流异常特征数据实施归一化的实质就是将具有不同维度的计算机网络数据流异常特征值向同区间实施合理映射,使各计算机网络数据流异常特征数据拥有相同的数量级[16-17]。以往工作中,通常将计算机网络数据流异常特征数据映射到[-1,1]区间内,本文为方便后续计算,将其映射到区间[0,1],具体的归一化过程用公式(6)描述。
(6)
式(6)中,归一化前的计算机网络数据流异常特征数据值用φ标记;归一化后的计算机网络数据流异常特征数据值用φ‴标记;max、min标记的是φ的最高以及最低值。
(3)卷积神经网络计算机网络数据流异常数据类型识别模型构建。构建的计算机网络数据流异常数据类型识别模型如图3所示。
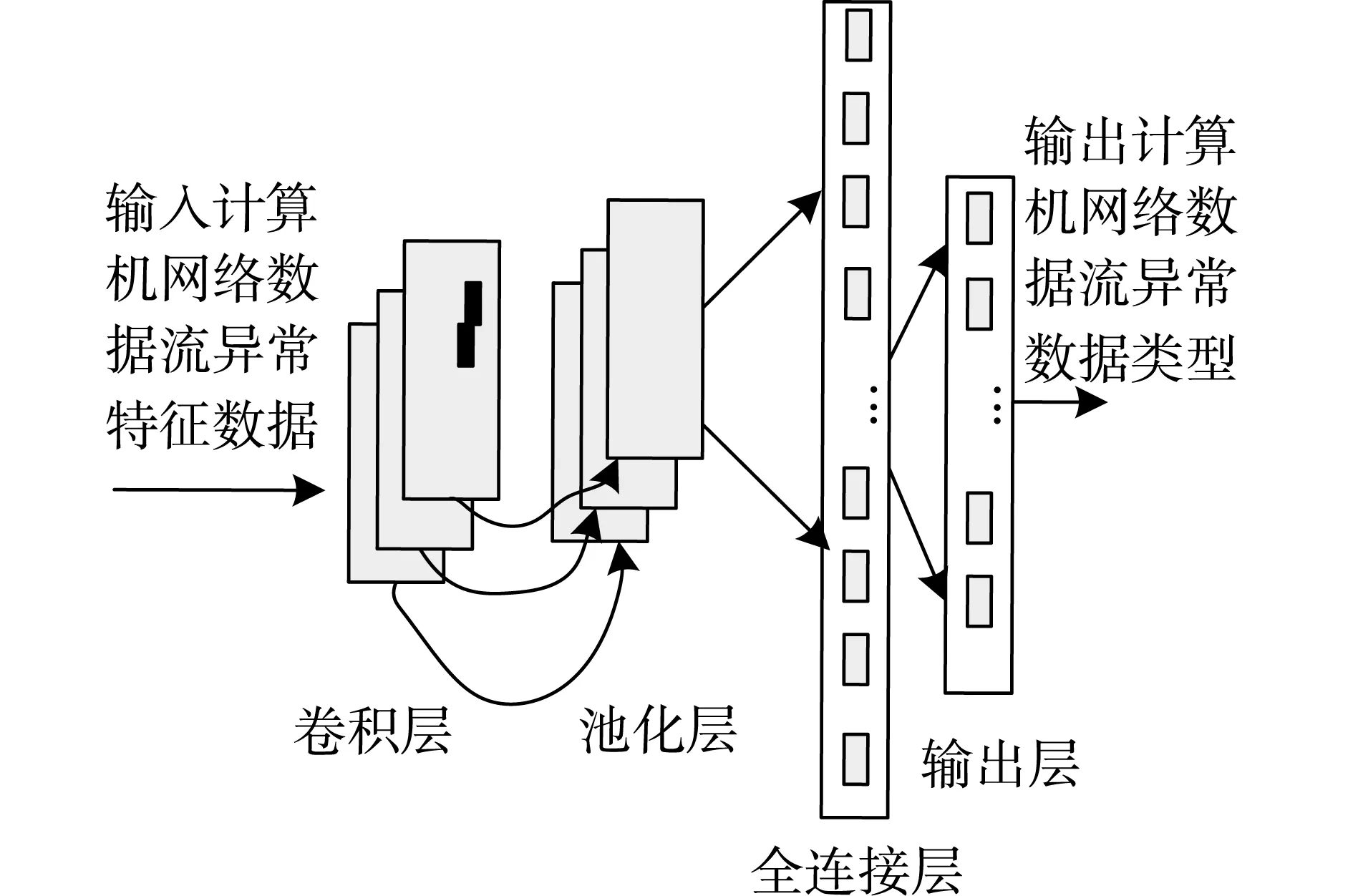
图3 计算机网络数据流异常数据类型识别模型
在将有效的计算机网络数据流异常特征数据输入到该模型后,经过有效的模型训练,便可输出较为理想的计算机网络数据流异常数据类型。
2 实验与分析
本文实验以地处我国H省B市某科技大学的校园计算机网络环境为实验对象。实验中所使用的计算机网络数据流数据主要来自该校用于向学生以及教职工提供各种服务的校园网络,具体包含V01、V03、V05、V07、V09以及V11六个服务网络,应用本文方法对该科技大学校园计算机网络中存在的计算机网络数据流数据实施有效采集,用于实验研究。选择该科技大学校园计算机网络环境为实验对象的原因是其网络环境相对比较简单、安全,很少发生网络攻击行为,网络中几乎无异常数据存在,即使有也是很难被检测出来的,完全可以忽略不计,因而在某一时段向其加入若干攻击数据后,应用本文方法对其实施合理挖掘,可很好验证本文方法有效性。
本文在V01、V03、V05、V07、V09以及V11六个校园服务网络的部分主机上执行攻击模拟操作,向各校园服务网络中加入不同攻击类型异常数据,计算机网络异常数据加入情况如表1所示。
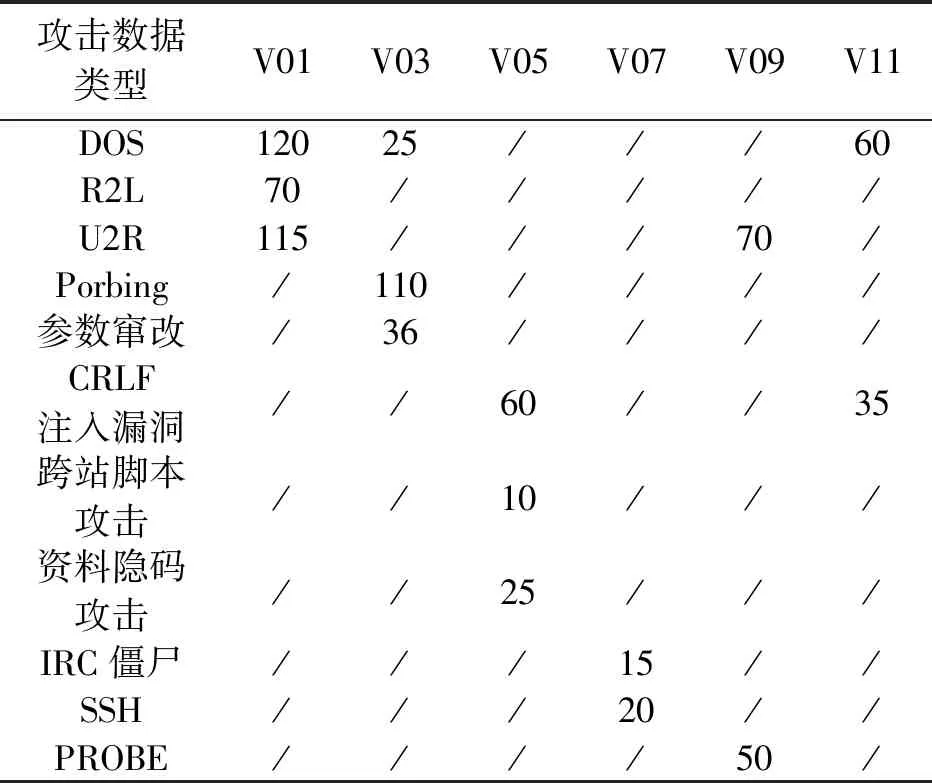
表1 计算机网络异常数据加入情况 单位:个
应用本文方法对加入不同类型攻击异常数据后的校园计算机网络,实施有效异常数据挖掘,获得计算机网络数据流异常数据挖掘结果如表2所示。
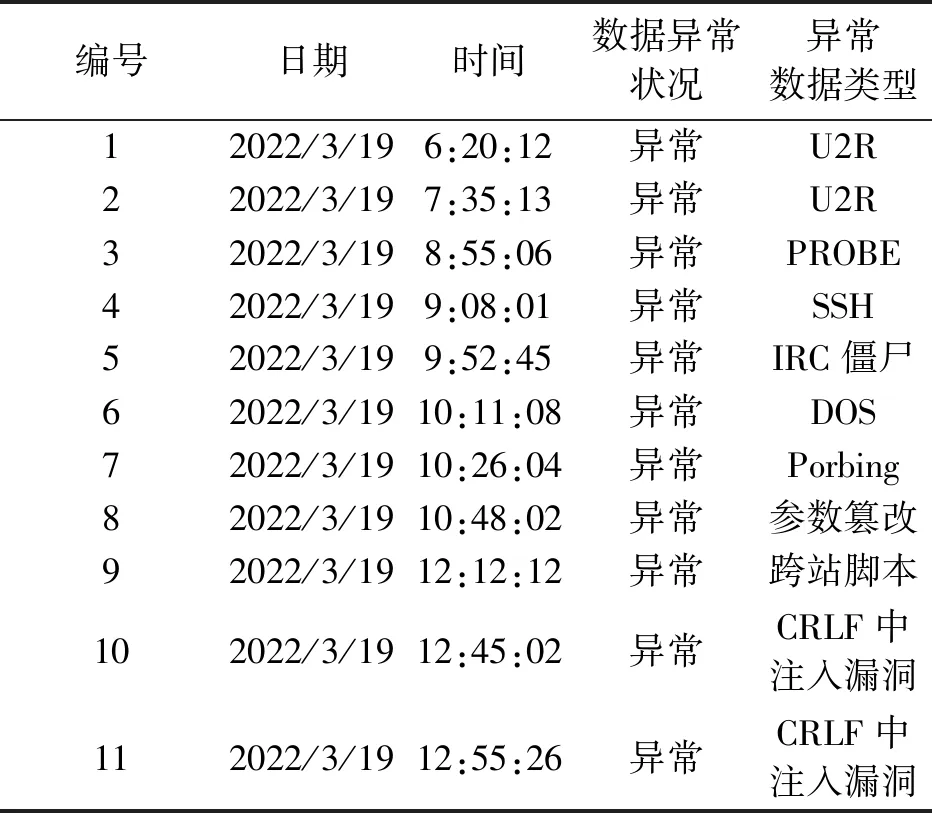
表2 计算机网络数据流异常数据挖掘结果
由表2可以看出,应用本文方法可以实现计算机网络大规模高维数据流异常数据挖掘,根据挖掘结果积极采取措施对计算机网络环境实施相关保护,可有效保障计算机网络安全稳定运行。
应用本文方法对该高校计算机网络实施计算机网络数据流数据异常挖掘,获得的计算机网络数据流数据异常状况挖掘效果如表3所示。在2022年3月29日6:00到12:00,应用本文方法对该高校计算机网络实施计算机网络数据流数据异常挖掘获得的异常数据类型挖掘效果如图4所示。
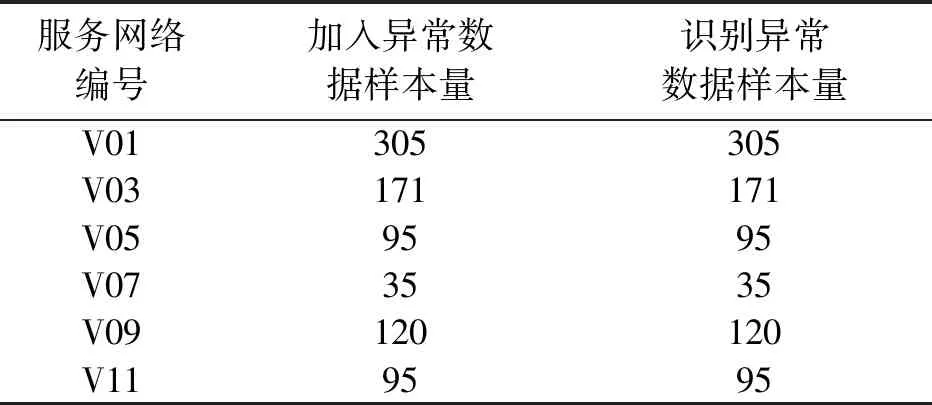
表3 计算机网络数据流数据异常状况挖掘效果 单位:个
由表3与图4可知,本文方法在计算机网络大规模高维数据流异常数据挖掘工作方面具有较高的挖掘准确性,将其应用于实际工作,能够更好保障计算机网络安全。
3 结论
应用本文方法可以实现计算机网络大规模高维数据流异常数据挖掘,并且数据挖掘效果较好。其在计算机网络大规模高维数据流异常数据挖掘工作方面的有效性主要体现在:应用本文方法可以实现计算机网络大规模高维数据流异常数据挖掘,并且可将计算机网络中存在的大规模高维数据流异常数据全部挖掘出来,挖掘出的计算机网络数据流异常数据类型与实际异常数据类型完全一致,将其应用于实际工作,可收获较为理想的工作效果。
