基于改进YOLOv5 的遥感小目标检测网络
2023-09-18李嘉新盛博莹周宇航
李嘉新,侯 进,盛博莹,周宇航
(1.西南交通大学 计算机与人工智能学院,成都 611756;2.西南交通大学 信息科学与技术学院智能感知智慧运维实验室,成都 611756;3.西南交通大学 综合交通大数据应用技术国家工程实验室,成都 611756)
0 概述
近年来,遥感图像目标检测在无人机巡检[1]、农业监测[2]、城市规划[3]、生态保护[4]等领域得到了广泛应用,因此,对遥感图像检测的进一步优化具有重要意义。遥感图像采用空中设备对地采集信息,可以解决地面采集覆盖范围有限、减少目标被遮挡等问题。但是,从远距离和俯瞰视角拍摄的目标在高分辨率下呈现多邻域聚集、小目标占比高等特性,导致检测精度大幅下降,给航拍遥感场景下小目标检测带来巨大挑战。根据国际光学工程学会定义,尺寸小于原图的0.12%可认为是小目标[5]。
现阶段遥感领域的小目标检测性能的提升主要从多尺度融合和感受野角度出发。文献[6]对特征金字塔模块进行重构,添加跨层级横向连接以融合更多的通道特征,并在检测头前引入位置注意力(Coordinate Attention,CA)机制[7]以确保遥感小目标精确定位,虽然其对小目标具有较优的检测性能,但是采用直接去除顶层特征提取层的方式会对语义信息造成一定程度的损失,不利于应对复杂场景下的检测任务。文献[8]提出用于特征增强的特征图融合机制,利用卷积操作对不同深度、不同尺度的特征图深度以及尺度进行统一,融合得到检测能力更强的特征图,从而构建特征金字塔(Feature Pyramid Network,FPN)以增强小目标特征。尽管在遥感飞机和不同空中飞机数据集上的检测精度均有所提升,但是其检测速度无法满足实时性需求。文献[9]基 于Faster R-CNN[10]上的特 征金字塔[11]结构设计了特征门控模块和动态融合模块,依据不同尺度分配不同权重来区分目标尺度对特征融合的影响,解决在特征融合中共享同一权重的问题。但是,基于双阶段的目标检测算法本身在速度方面存在一定的局限性。
此外,研究人员从感受野角度来提升小目标检测性能。文献[12]在8 倍下采样后的特征映射中添加可变形卷积,对卷积中采样点的位置增加1 个偏移,扩张实际感受野进而提升对小目标的识别精度,但是当目标存在背景遮挡时虚警率和漏检率较高。文献[13]参考RFB(Receptive Field Block)[14]结构,采用多分支处理和空洞卷积设计特征增强模块以加强特征语义信息,减少小目标的检测精度损失,但是在遥感图像检测精度上仍有进一步提升的空间。文献[15]利用混合空洞卷积的方式提取特征,有效增大感受野,并直接引入空洞空间金字塔池化(ASPP)[16]进行多尺度特征融合,以捕获更完整的卫星道路图像信息。但是以上方法使用场景单一,不能很好地应用在多场景任务中。因此,现有算法在小目标检测任务上取得了一定成效,但是无法有效权衡检测精度和速度,且未考虑卷积特征提取和下采样操作过程中的小目标信息传递丢失问题。
本文提出基于YOLOv5 的遥感小目标检测算法YOLOv5-RS。通过构建轻量的并行混合注意力模块抑制图像中复杂背景和负样本的干扰,同时通过调整下采样倍数,保证传递更多的细节信息,并进一步设计卷积神经网络(Convolutional Neural Network,CNN)与Transformer[17]相结合 的特征 提取模 块C3BT,将从特征图中获取到的局部与全局信息输出作为融合的底层特征。将原网络中的CIoU[18]损失函数替换为EIoU[19]损失函数,有效减少目标检测框的重叠,精准定位小目标的位置,从而提升模型对遥感小目标的检测性能。
1 YOLOv5-RS 方法
近年来,目标检测领域越来越注重算法的工程化应用,对实时性要求大幅提高。考虑到一阶段网络YOLOv5s[20]能兼顾检测精度与速度的特性,本文将其作为基础框架,从注意力模块、特征金字塔融合、损失函数3 个角度进行优化。在特征提取阶段,为减少小目标信息的丢失,本文使用16 倍下采样操作代替32 倍下采样,并添加浅层分支。上述操作虽然能够传递更多的浅层信息,但是缩小了感受野。基于此,本文构建具有更大感受野和更强表征能力的C3BT 模块替换SPPF 模块前的原C3 特征提取模块,C3BT 由CNN 和多头自注意力(Multi-Head Self-Attention,MHSA)组合而成,同时,将并行混合注意力模块CBAM-P 嵌入到FPN 结构中进行Concat 融合浅层特征之前。从模型预测中发现,在小目标的定位任务中会存在大量重复的检测框,采用EIoU 损失函数具化预测框与真实框之间的长宽关系。YOLOv5-RS 网络整体结构如图1 所示。

图1 YOLOv5-RS 网络整体架构Fig.1 Overall architecture of YOLOv5-RS network
1.1 并行混合注意力模块
注意力机制的本质是仿照人类视觉处理图像的过程,对特征图的不同位置予以各自的权重来表示不同的关注度。遥感图像往往包含复杂的背景,经过卷积层特征提取后存在待检测小目标信息占比少、背景以及背景中非检测物体信息占比多的情况,这些非感兴趣区域信息会对小目标检测产生干扰。
为关注图像中待检测的小目标以及忽略无关的物体信息,本文借鉴了CBAM(Convolutional Block Attention Module)[21]的通道 注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM)结构,提出通道注意力模块CAM-P 和空间注意力模块SAM-P,最终通过并行连接构成CBAM-P 模块,使其分别沿通道和空间维度对特征图信息进行编码。与CBAM 模块相比,CBAM-P 在减少计算量的同时提高检测精度。CBAM-P 模块结构如图2 所示。

图2 CBAM-P 模块结构Fig.2 Structure of CBAM-P module
首先对通道注意力模块进行改进,CAM-P 是基于SENet[22]模块进行改进,将SENet 模块中全局平均池化(Global Average Pooling,GAP)后的全连接层替换为3×3 卷积层,并获取局部信息。因为小目标本身的感受野较小,所以全连接层对整张图片进行降维,导致待检测的小目标被淹没在与其他背景的平均特征之中。CAM-P 特征图计算过程如式(1)所示:
其中:σ表示Sigmoid 激活函数;f1×1表示大小为1×1的卷积;f3×3表示大小为3×3 的卷积。输入特征X∈ℝH×W×C通过GAP 后输出1×1×C的一维通道注意力图,再通过激活函数重建得到权重特征图WC。
然后对空间注意力模块进行改进,SAM-P 在原SAM 模块的基础上移除所有池化层,仅由1×1 卷积层生成。该操作是考虑到池化会丢失小目标的关键特征而不利于检测。SAM-P 特征图的计算过程是将输入特征X经1×1×1 卷积的结果输入Sigmoid 激活函数,得到空间注意力特征图WS,如式(2)所示:
最终,将通道特征图WC与空间特征图WS分别与输入特征X逐元素相乘,采用逐元素相加方式将相乘后所得的特征图并行连接,输出特征XCS。上述过程的计算式如式(3)所示:
其中:⊗表示逐元素相乘;⊕表示逐元素相加。
1.2 特征金字塔改进
特征金字塔网络结构如图3 所示。YOLOv5 特征图的融合部分采用路径聚合网络(Path Aggregation Network,PANet)[23],其结构如图3(a)所示。将主干网络经8 倍、16 倍、32 倍下采样后输出{P3,P4,P5}特征,分别与FPN 自底向上的特征图进行融合。这种将浅层丰富细节信息和深层高语义信息融合的操作有利于多尺度目标检测,但是对于小目标,经过多次下采样后特征图所含小目标的有效特征信息较少,导致小目标检测精度降低。因此,本文对特征金字塔进行改进,保证传递更多的小目标细节信息并输出对小目标表征能力更强的特征图。改进后的特征金字塔PANet_RS 结构如图3(b)所示。

图3 特征金字塔网络结构Fig.3 Structure of feature pyramid network
原始输入图像在经卷积下采样逐步映射为不同尺度特征图的过程中,所包含的有效像素信息逐渐减少。表1所示为将原始图像映射到不同特征层后所占像素的情况,P2、P3、P4、P5 分别进行4、8、16、32 倍下采样。结合实际数据目标尺度分布情况,将小目标进一步划分为检测尺度小于16×16像素的微小目标。
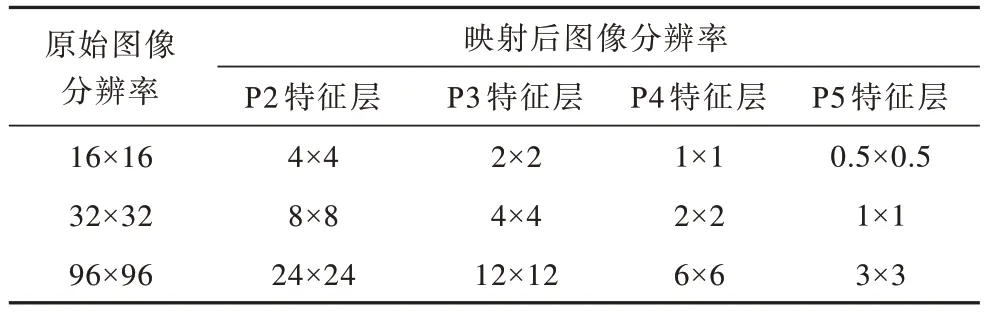
表1 原始图像映射到不同特征层后的分辨率 Table 1 Resolution of original image mapping to different feature layers 单位:像素
从表1 可以看出,小目标特征映射到P5 特征层后所包含的小目标分辨率为1×1 像素,微小目标的分辨率甚至不到1×1 像素,对遥感小目标的检测效果甚微。考虑到直接裁剪P5 检测层和其对应的分支,会造成深层网络间的语义信息缺失、感受野减小,进而影响分类任务的准确率。为缓解语义信息与位置信息之间的矛盾,本文在主干网络中去除32 倍的下采样层,使用16 倍的卷积层进行替换,有效缓解连续下采样存在信息损失的问题。
与{P3,P4,P5}相比,在P2 大尺寸检测层中含有丰富的纹理和轮廓信息,有利于图像中小目标的检测,因此添加P2 检测头并使用CBAM-P 注意力模块来抑制P2 特征层的噪声信息。为进一步平衡速度与精度,本文仍然保持3 个尺度的检测头预测结构,但调整检测头为{P2,P3,P4}所对应的检测分支。
虽然上述通过1×1 卷积替代用于下采样的3×3 卷积操作可以保证传递更多信息,但是1×1 卷积操作与YOLOv5 网络相比感受野减少,导致图像中大尺寸目标的检测精度下降,整体精度提高不明显。基于此,本文构建基于CNN 与Transformer 相结合的模块C3BT,提取表征能力更强的特征图作为FPN 的底层特征。具体操作是将YOLOv5 特征提取基础单元Bottleneck中的3×3 卷积替换为BottleTransformer[24]中的MHSA。BottleTransformer结构如图4所示。

图4 BottleTransformer 模块结构Fig.4 Structure of BottleTransformer module
MHSA 层由多个Self-Attention 模块组成,每个Self-Attention 模块在不同空间中捕获全局特征信息,最终将每个Self-Attention 模块输出的信息进行拼接形成带注意力权重的新特征图Z。每个Self-Attention 模块的具体操作过程如式(4)所示,q(query)、k(key)、v(value)如式(5)所示:
1.3 EIoU 损失函数
原始YOLOv5 采用CIoU 计算定位损失,其在IoU(Intersection over Union)损失的基础上,添加边界框回归的重叠面积、中心点距离及边长纵横比作为惩罚项因子。CIoU 及其惩罚项计算式如式(6)和式(7)所示:
其中:b、bgt分别表示预测框和真实框的中心点;ρ表示2 个中心点间的欧氏距离;c表示包含预测框和真实框的最小闭包区域形成的对角线距离;v用来测量宽高比差异。
本文采用EIoU 损失函数计算定位损失,将宽高纵横比的损失项拆分,分别计算宽和高的差异值,计算式如下:
其中:w、wgt、h、hgt分别表示预测框和真实框的宽度及高度。
在同一目标区域内采用CIoU 和EIoU 损失函数的预测结果如图5 所示。CIoU 损失增加了宽高比的一致性,使得检测框回归过程更加稳定,收敛的精度更高。但是参数v只反映了宽高比间的相对差异,而不 是w与wgt、h与hgt之间的真实关系。CIoU定位损失如图5(a)所示。CIoU 损失函数生成的预测框与真实框相比,其宽边差异很大且无法精确定位。利用预测框与标注框宽高之间的真实差监督反向传播过程,得到损失函数最优解。该过程提高回归精度进而提升小目标检测性能。EIoU 定位损失如图5(b)所示,EIoU 定位损失函数生成的预测框高度和宽度与真实框相似。

图5 同一目标区域预测结果Fig.5 Prediction results for the same target area
2 实验结果与分析
2.1 实验配置
实验环境:Ubuntu20.04 操作系统,显卡GeForce RTX 3090,训练平台Python3.8,深度学习框架PyTorch。模型训练参数设置:迭代次数为200,批大小batch_size 为16,其余参数均为默认值。
2.2 数据预处理
本文采用武汉大学发布的航空遥感影像DOTAv1.5 数据集[25]对所提小目标检测算法进行评估,选取小型车辆(Small Vehicle,SV)、大型车辆(Large Vehicle,LV)和轮船(SH)3 种小目标数据集作为原始图像,图像大小一般为800~3 000 像素不等。若将小目标数据集图像直接送入检测网络训练,其分辨率过大,易造成显存溢出。若等比例缩放会直接导致图像过度压缩而丢失大量小目标细节信息。因此,本文使用图像裁剪方式对数据集进行预处理,将样本统一裁剪为1 024×1 024 像素的图片,在切割图像时保留一定重叠区域(gap)来防止切割边缘目标信息丢失,本文将gap 设置为200。
将处理后得到的9 240 张图像构成DOTA-v 数据集,共计标注457 528 个实例,平均单幅图像包含49.5 个待测实例,按照6∶2∶2 比例划分为训练集、验证集和测试集。图6 所示为3 类目标的标注框占原图像尺寸的比例分布。从分布情况可以看出,SV类目标几乎全部为占比小于0.1 的小目标,LV 和SH类目标也大多集中在0.1 范围内。在COCO 数据集[26]中大、中、小目标占比约为4∶3∶2,而DOTA-v数据集为7∶2∶1,显然DOTA-v 数据集的小目标占比更高,可用于验证本文算法的合理性。
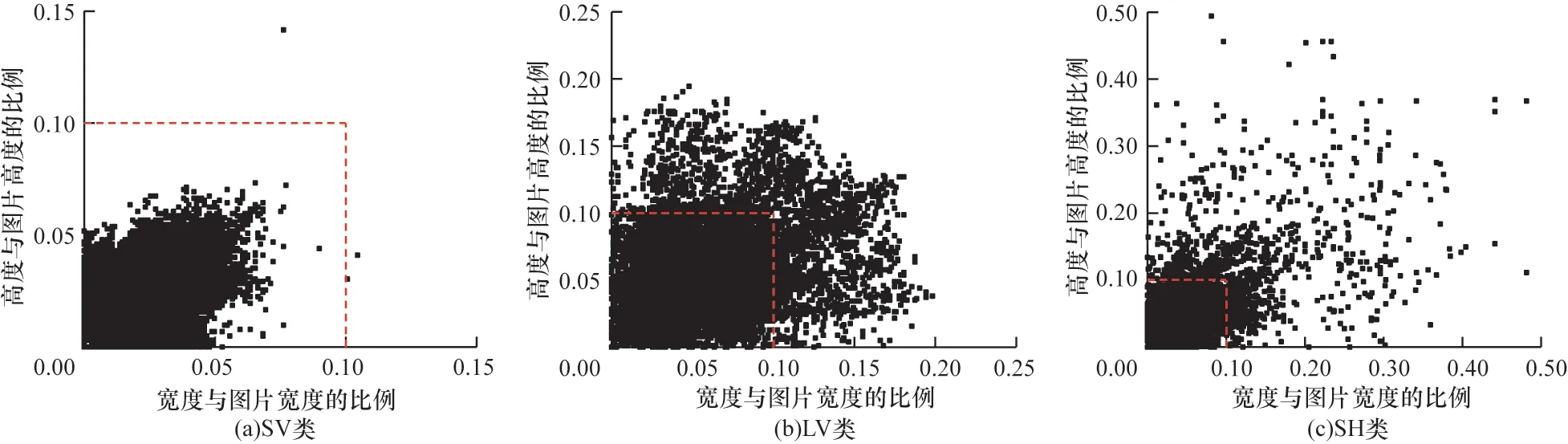
图6 在DOTA-v 数据集中各类目标尺寸分布情况Fig.6 Distribution of various objects size on DOTA-v dataset
2.3 评价指标
本文选取目标检测领域3 种常用的评价指标对算法进行定量评价。
1)精确度(P)和召回率(R)的计算式如式(9)和式(10)所示[27]:
其中:TTP(True Positive)表示图像中待检测目标被正确识别且IoU 大于阈值;FFP(False Positive)表示检测目标未被正确识别且IoU 小于阈值;FFN(False Negative)表示没有被检测到的目标。
2)平均精度(mAP)计算式如式(11)所示:
其中:N代表数据集中检测目标的类别个数;Pn表示某一类别的AP 值。mAP@0.5 和mAP@0.5∶0.95 常用来评估模型性能,mAP@0.5 关注模型精确率随召回率变化趋势,mAP@0.5∶0.95 更关注模型在不同IoU 阈值下的综合表现,反映检测框与真实框的拟合程度。本文若无特殊说明,mAP 默认为mAP@0.5。
3)帧速(Frames Per Second,FPS)[28]表示模型每秒能处理图片的数量,单位为帧/s,通常用于衡量模型的实时性,辅以参数量和计算量(GFLOPs)综合判别模型性能。
2.4 结果分析
2.4.1 注意力机制改进实验
为验证本文所提CBAM-P 模块的有效性,本文进行注意力机制对比实验,比较参数量和mAP 这2 个指标,其中,CBAM-S表示CAM-P 与SAM-P 的串行模块,CBAM-P 表示CAM-P 与SAM-P 的并行模块。CBAM-P 模块对模型性能影响如表2 所示。
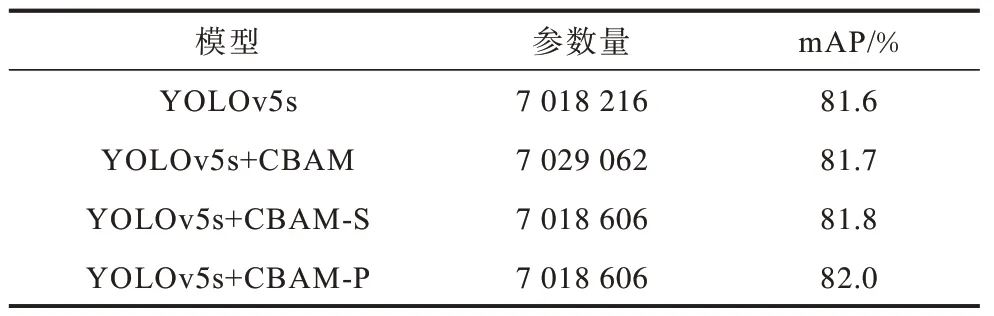
表2 CBAM-P 模块对模型性能影响 Table 2 Influence of CBAM-P module on model performance
CBAM 首先使用CAM 给不同通道分配不同的权重,然后使用SAM 进行空间信息校准。从表2 可以看出,在YOLOv5s 中直接嵌入CBAM 模块后相比YOLOv5s mAP 指标仅提升0.1 个百分点,然而在YOLOv5s 中直接嵌入CBAM-P 模块后与YOLOv5s+CBAM 相比不仅参数量减少,而且mAP 提高了0.3 个百分点。分析认为有2 个方面的原因:1)在小目标信息本身不足的情况下,池化操作和全连接操作带来的负面影响大于正面影响,替换全连接层和移除池化层后的模块后所得的特征图更有利于小目标检测;2)得益于并行的连接结构,在串行结构中,空间注意力机制的输入是经过通道注意力模块后所得,使得目标浅层信息再次减少,即使具有更多的语义信息也无法对小目标进行定位,相反可能导致目标错检。
为进一步直观对比CBAM 模块与CBAM-P 模块的效果,本文采用Grad-CAM(Gradient-weighted Class Activation Map)[29]热力图进行可视化,可视化结果如图7 所示(彩色效果见《计算机工程》官网HTML 版)。图7(a)中标注框表示将地面停车线误判为感兴趣目标,从图7(b)可以看出,采用CBAM-P结构后的热力图没有出现误判现象。该实验结果进一步说明注意力机制的减法操作和并行结构能够有效提高空间维度特征的提取能力,更好地区分前景和背景信息,使得关注区域与检测目标区间更紧凑,证明CBAM-P 模块对小目标检测是有效的。

图7 注意力机制可视化结果Fig.7 Visualization results of attention mechanism
2.4.2 特征融合层改进实验
检测头分支数量与性能关系如表3 所示。本文综合考虑参数量与检测精度,选取{P2,P3,P4}对应的预测分支输出检测头。
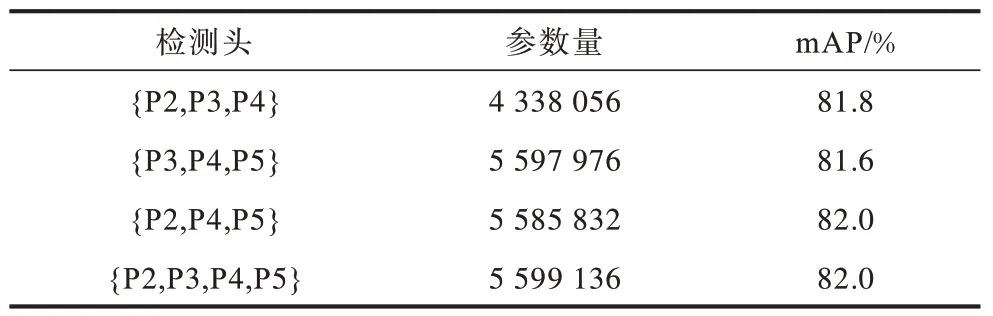
表3 检测头分支数量与模型性能关系 Table 3 Number of detection head branches in relation to model performance
从表3 可以看出,采用减少下采样倍数并添加P2 检测头模块后的结构{P2,P3,P4,P5},与{P2,P3,P4}检测头相比mAP 提高约0.2 个百分点,证明该结构能够传递更多的小目标信息。但受限于降采样操作所造成感受野缩小和浅层特征P2 中的噪声干扰,mAP 提升不是很明显。基于此,本文进一步验证C3BT 模块的有效性,选取{P2,P3,P4}检测头进行对照实验,并增加各类目标mAP 指标以直观反映其对不同尺寸目标检测性能的影响,对比结果如表4所示,“√”表示在基准模型YOLOv5s 中添加该模块。

表4 C3BT 模块对模型性能影响 Table 4 Influence of C3BT module on model performance %
从表4 可以看出,为传递更多小目标而采用降采样操作,添加{P2,P3,P4}结构后,相比YOLOv5s 的SV 目标的mAP 提高1.2 个百分点,但LV 类目标mAP下 降0.4 个百分 点,SH 类目标mAP下降0.3 个百分点。感受野的缩小影响了LV 类和SH 类中大尺寸和中尺寸目标,无法捕捉到全部的特征。在添加了C3BT 模块后,与YOLOv5s相比,mAP 提升了0.8 个百分点,其中SV 类目标mAP 提升了2.2 个百分点,SH类目标mAP 提升0.1 个百分点,说明C3BT 模块能有效地提取更具判别能力的特征用于检测小目标,同时扩张了感受野保证大尺寸和中尺寸目标的精度。
2.4.3 模块消融实验
为验证各模块的有效性,本文在遥感数据集DOTA-v 上进行消融实验。本文在YOLOv5s 基础上依次添加CBAM-P、特征层改进模块(PANet_RS)以及EIoU 损失函数。消融实验结果如表5 所示。

表5 消融实验结果 Table 5 Ablation experiment results
从表 5 可以看出,本文所提 CBAM-P、PANet_RS、EIoU 损失函数对模型性能具有一定的有效性,YOLOv5s+CBAM-P+PANet_RS+EIoU 模型大小缩小为10.1 MB,整体mAP 与YOLOv5s 相比提高了1.5 个百分点。
2.5 对比实验
2.5.1 预测结果分析
从上述实验中可以发现,本文在DOTA-v 数据集上的整体预测效果优于YOLOv5s。为了进一步反映改进模型的性能,在所有预测类上的mAP 变化结果如表6 所示,并通过遥感图像进行主观视觉定量评价。
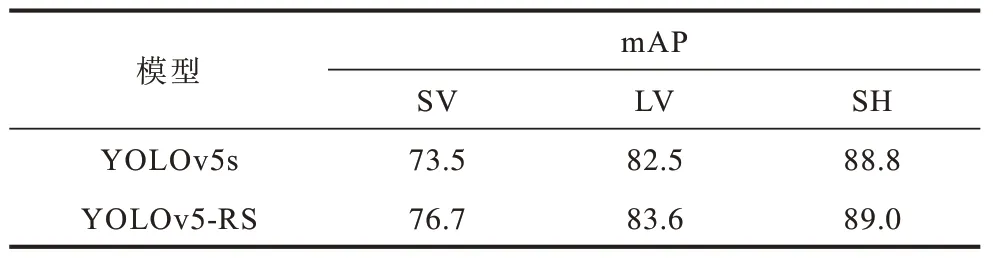
表6 YOLOv5s 与YOLOv5-RS 各类别mAP 对比 Table 6 Comparison between YOLOv5s and YOLOv5-RS by category mAP %
从 表 6 可以看 出,与 YOLOv5s相比,YOLOv5-RS 在SV、LV 和SH 3 个类别 目标的mAP均得到提高,尤其是SV 的检测精度提升了3.2 个百分点。SH 类小目标大多呈现密集分布,水平检测框之间的重合导致精度提升不明显。
YOLOv5-RS 与YOLOv5s 检测效果对比如图8所示(彩色效果见《计算机工程》官网HTML 版)。从图8 可以看出:第1 组YOLOv5-RS 算法对小目标定位更加准确,预测框能更好地定位到物体所在的位置,且减少了预测框重叠的现象;第2 组在遮挡场景下,YOLOv5-RS 算法可以更准确地检测被树遮挡的车辆;第3 组在密集场景下,YOLOv5-RS 算法可以检测出更多的船类目标,在目标识别与定位能力上均优于YOLOv5s 算法。

图8 YOLOv5-RS 与YOLOv5s 算法的检测效果对比Fig.8 Detection effects comparison between YOLOv5-RS and YOLOv5s algorithms
2.5.2 不同算法对比实验
本文以 一阶段EfficientDet[30]、YOLOx[31]、TPH-YOLOv5[32]、YOLOv7[33]以 及YOLOv5s 5种算法作为对照组进行实验,包括近年来在小目标检测领域的常用框架和最新的改进框架。EfficientDet 系列网络以权衡速度与精度为前提,实现对双向特征融合结构的动态调整。本文选取兼顾速度与精度的EfficientDet-d4 作为对照组。YOLOx 采用无锚框方式,并通过解耦YOLO Head 提升网络的性能。TPH-YOLOv5 是基于YOLOv5s 进行改进。由于TPH-YOLOv5集成CBAM、Transformer 等模块,因此在无人机小目标检测数据集上性能表现突出。YOLOv7 设计新的内部组件模块,结合新的标签分配策略使其架构在速度和精度上均取得较优的表现。不同算法的评价指标对比如表7 所示,加粗表示最优数据。与上述5 种算法相比,YOLOv5-RS 在mAP@0.5、mAP@0.5∶0.95 和模型大小3 种评价指标上取得最优结果,在精确率与召回率的平衡、检测框与预测框的拟合方面表现突出。YOLOv5-RS 检测速度为65.4 帧/s,其兼顾精度与实时性,对小目标检测性能更优。

表7 不同算法的评价指标对比 Table 7 Comparison of evaluation indicators for different algorithms
3 结束语
为解决现有算法的小目标检测精度远低于大、中目标的问题,本文提出一种基于并行注意力机制和融合更多低层级特征的检测算法YOLOv5-RS。在特征金字塔融合结构中添加1 个浅层特征分支以反馈更多的浅层特征,并利用所提的注意力模块抑制分支中的噪声干扰。通过调整下采样倍数,并融合全局和局部信息生成特征提取能力更强的特征提取模块。在预测阶段,采用EIoU 损失函数有效缩小真实框与预测框之间的差异。实验结果表明,相比现有一阶段算法,本文算法具有较优的小目标识别能力,在复杂场景下鲁棒性较优。下一步将在一阶段网络中引入旋转检测方法,解决目标方向不确定所存在边界框重叠问题。
