KNN算法在网络安全入侵检测中的运用研究
2023-09-14谢海涛
谢海涛
宁海传媒集团,浙江宁波,315600
0 引言
得益于互联网技术的飞速发展,广播电视行业的信息化程度越来越高,广播电视行业从传统的电视播出等传媒方式逐步向互联网转型。广播电视行业的新闻、播发、业务、编辑系统高度依附于信息网络,使得互联网承载的信息价值愈发重要,网络规模和复杂度也大大提高。为使安全保障能力全面提升、监测监管体系进一步完善,有关部门出台了多个信息安全等级保护的标准文件,针对当前复杂化的网络信息安全体系下的多方位问题取得了一定进展,但与此同时,面对海量的数据,仍存在无法进行有效的处理分析、对于异常的流量和安全隐患无法定位和判别问题[1]。
1 当前广播电视行业在网络安全入侵检测中的现状分析
入侵检测作为网络安全系统的一种重要动态防护策略,能够辨别出计算机网络的非法或者恶意攻击行为,作为防火墙之后的第二道安全闸门。入侵检测是互联网网络安全检测中非常重要的核心技术之一,有效地扩展了系统管理员的安全管理能力及系统安全架构的完整性。但是当面对海量数据时,黑客攻击行为隐蔽手段层出不穷,混淆数据的方式使业务正常数据和恶意数据夹杂在一起,而入侵检测纯依赖于人工分拣时,会出现问题。传统广电工程技术人员到网络安全技术人员的转型较为困难,知识重构和经验积累难以快速完成。技术人员无法判断网络数据的好坏性,也无法对发现的恶意流量进行分类,从而无法采取正确的保障措施。若依据行业规定的规则库进行识别,人工分析判别的速度远低于智能化的分析判别[2-3]。
上述问题使运维人员无法进行业务最小单元切断原则,导致黑客潜伏周期不断扩张,数据窃取时间拉长,对公司的核心数据造成无法估量的损失,所以当下急需提出一种更为智能的数据分拣手段。
2 人工智能算法在网络安全中的作用
2.1 人工智能的优势
人工智能技术的出现给网络安全攻防技术和体系建设开拓了全新的篇章,利用大数据、人工智能等技术,建立协同一体的智能化管控中心平台,能够通过多源关联分析、异常行为分析、机器学习等技术实现威胁精准分析,通过威胁情报实现情报共享,安全预警和安全分析能力逐步增强。通过使用机器学习技术,可以建立模型来分析网络流量的特征,识别出恶意流量。例如,人工智能技术可以通过分析流量的特征,如源IP地址、目的IP地址、协议类型、数据包大小等,来识别DDoS攻击、恶意软件传播、网络钓鱼等恶意流量。此外,人工智能还可以通过学习历史数据,来预测未来的恶意流量,并及时采取防御措施。使用人工智能技术来检测恶意流量的优势在于,它可以快速处理大量的数据,并且能够自动学习和更新模型,从而提高检测的准确性[4-5]。因此,人工智能在恶意流量中的检测作用很大,可以为网络安全提供强有力的保护。
2.2 入侵检测算法
入侵检测算法是运用于入侵检测中最为核心的部分,算法的精准率和数据处理能力直接决定了整个入侵检测的高效率能力和平稳性。现有的多种检测算法,不管在检测能力还是效率上相较于宁海传媒集团的现场运行环境仍存在较大的差距,积极地改善算法和分类精度,降低系统的误报率和漏检率,对进一步提高智能算法的仿生性和学习能力有着极其重要的意义。
3 KNN算法
3.1 KNN算法简介
KNN是一种用于分类和回归的机器学习算法。它基于这样一种观点,即数据集中与给定样本最相似的样本是最有可能与给定样本属于同一类的样本。要使用KNN,首先需要为k选择一个值(要考虑的最近邻居的数量),然后算法查看数据集中与试图分类或预测的样本最接近的k个样本。然后,它将样本分配给这k个样本中的大多数所属的类别。在KNN中,作为邻居的参数k是需要仔细选择的参数。一个较小的k值可能导致过拟合,而k值过大则会导致欠拟合。最优的k值可以通过交叉验证或使用探索式的方法来确定[6-7]。
KNN有几个优点,包括它的简单性及其通过使用集成领域知识的能力距离度量。它还能够处理大的特征空间和同时使用连续和分类数据。然而,KNN也有一些缺点。它的一个主要缺点是计算成本高,特别是在处理大型数据集时。此外,高性能的KNN会受到噪声或不相关特征的影响。
3.2 KNN在入侵检测中的作用
KNN作为一种流行的算法,可以用于入侵检测算法中。KNN的分类原理为对训练集中待分类的对象分类,每个对象的分类由最近的K个数据投票确定,即对象被分配给最近的K个对象中最多的类,并由训练集中K个最近邻居的多数标签表示。在一个可用于基于正常或异常对网络流量进行样本分类的特征向量空间内,如果网络的流量特征包括流量走向的源IP地址和目的IP地址、端口号和数据包大小,则可以使用KNN算法将流量分类为正常或异常,分类的依据取决于其邻近点的多数类别。如果一个样本周围大多有正常的相邻点,那么它很可能被分类为正常流量;如果相邻样本多为异常点,则它很可能被归类为异常流量。
使用KNN的优点是可以通过使用欧式距离度量来合并样本。例如不同IP地址之间的重要性可以用来加权,从而分析出随机流量之间的关联性,协助运维人员判断出黑客恶意IP或者随机代理的走向行为。KNN的另一个优势是可以处理比较大的特征空间,可以连续不间断地做分类工作。
4 KNN在入侵检测中的实际运用
对公司对外开放的系统中将近几个月的网络日志进行汇总,筛选出将近1万条数据,其中有一半的正常流量数据和一半的异常流量数据。在入侵检测的运用中,模型不但需要检测网络流量的差异性,还需对非正常的流量进行分拣,从而协助技术人员采取相应的有效措施。
4.1 数据分类机制
4.1.1 正常数据特征
当用户正常浏览或者搜索引擎对页面进行抓取时,http请求头中的url并不会出现长度过长、存在特殊字符和系统路径等信息,根据这些特征可断定为用户正常访问的流量。
4.1.2 异常数据分类
在对数据样本的初步分类中,除去正常的流量数据,剩下的异常数据大多呈现出以下几种攻击方式。
①SQL注入。SQL注入是一种web安全漏洞,允许攻击者干扰应用程序对其数据库的查询。它允许攻击者查看通常无法检索的数据。这可能包括属于其他用户的数据,或者应用程序本身能够访问的任何其他数据。②跨站脚本攻击。跨站脚本攻击(XSS)是一种注入,恶意脚本被注入正常可信的网站中。当攻击者使用web应用程序向不同的终端用户发送恶意代码时,XSS攻击就会发生。允许这些攻击成功的缺陷非常普遍,并且发生在web应用程序在其生成的输出中使用来自用户的输入而没有验证或编码的任何地方。③命令注入攻击。命令注入是一种攻击,其目标是通过易受攻击的应用程序在主机操作系统上执行任意命令。当应用程序将不安全的用户提供的数据(表单、cookie、HTTP报头等)传递给系统shell时,就可能发生命令注入攻击。在这种攻击中,攻击者提供的操作系统命令通常使用易受攻击应用程序的特权执行。命令注入攻击可能主要是由于输入验证不足。④文件包含攻击。本地文件包含是通过利用应用程序中实现的易受攻击的包含过程来包含服务器上本地已经存在的文件的过程。例如,当页面接收到必须包含的文件的路径作为输入时,就会发生此漏洞,而该输入没有正确地清除,从而允许注入目录遍历字符。
4.1.3 数据初步分类结果
通过上述的几种分类方式对接收的流量提取HTTP请求包的请求头和请求数据,且根据响应包的内容可对样本结果进行初步标注和数据清洗,数据样本如图1所示。
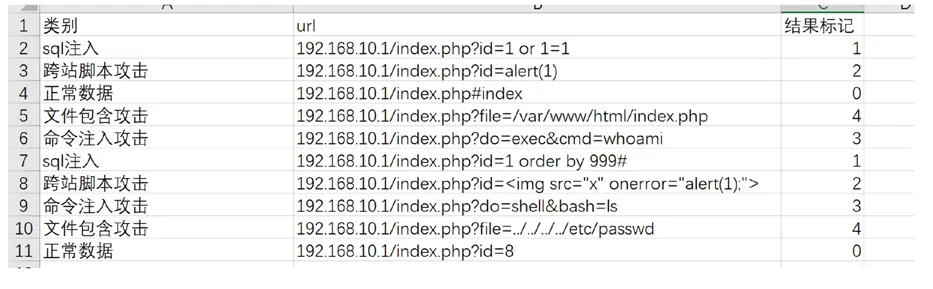
图1 样本数据预览
对流量进行初步的人工分类,通过人工判别的结果进行标记,初步标记为五种状态,正常流量以及上述异常流量所分类的四种结果,通过结果转化为数字型类型0、1、2、3、4状态识别码,即0表示正常流量,1表示出现sql注入攻击行为,2表示出现跨站脚本攻击行为,3表示出现命令注入攻击行为,4表示出现文件包含攻击行为。将样本进行合理的训练集与测试集划分后输送至模型侧进行建模分析。
4.2 标签值标准化
为了模型更好地识别数据,且鉴于当某列数据不是数值型数据时,将难以标准化,此时要将数据进行转化或者对特征进行提取,如url长度、特殊字符出现的频次、一段时间范围内多次攻击衍生的次数等。
4.3 模型训练与准确度比较
对样本数据二八划分为测试集与训练集(图2),且对参数进行轮询评估,评价不同的k对精度的影响,选择最优的k训练结果如下。
图2 样本数据训练
Accuracy: 0.7017543859649122
Accuracy: 0.5789473684210527
Accuracy: 0.7368421052631579
Accuracy: 0.631578947368421
Accuracy: 0.7017543859649122
Accuracy: 0.6842105263157895
Accuracy: 0.6666666666666666
Accuracy: 0.6842105263157895
Accuracy: 0.7368421052631579
Accuracy: 0.6666666666666666
Accuracy: 0.6842105263157895
Accuracy: 0.5964912280701754
Accuracy: 0.7192982456140351
Accuracy: 0.6842105263157895
best_n_neighbors=3 best_score=0.7368421 052631579
通过训练结果可知,当参数k为3时,准确度达到了最优。
5 结语
本文通过对广播电视行业的需求分析,挖掘行业痛点,针对当前网络安全形势复杂、对网络管理员考验较大等问题,结合公司信息系统现存安全架构情况,对网络安全建设提出了新的改良方案。通过人工智能手段对海量攻击数据进行机器学习断定,大幅度提升了当网络安全事件发生时网络运维人员的应急响应速度和判别辅助能力。
