基于目标分割与检测的无人机滩区安全预警方法
2023-09-12周爱平王明慧孙旭辉马晓静
周爱平,张 滨,兰 超,王明慧,孙旭辉,马晓静
(1.滨州黄河河务局,山东 滨州 256600;2.山东恒泰工程集团有限公司,山东 滨州 256600;3.山东大学海洋研究院,山东 青岛 266200)
0 引言
我国人口密集,河流纵横交错,很多城市建造在河流沿岸地区,这为城市居民用水和城市景观绿化提供了便利,但是也对人员安全带来一定影响。儿童或者醉酒人员长时间在河岸边或河滩嬉戏很容易发生安全事故,因此必须加强对河流的安全管控力度,规范河流安全巡查。河流巡检的主要对象包括沙滩、人工岸线,这些地方受丰水期和枯水期影响,是河流巡检的重点区域。如今人工巡检已经较少大面积使用;而随着对河流巡检的实时性和分辨精度要求的提升,现有的卫星巡检和航空巡检发挥作用也越发受限。近年来,无人机巡检在电力、森林、管道等多领域逐步推广应用,成为卫星遥感巡视和航空巡检之外的可靠补充巡检方案。
基于无人机的河滩巡检可实现在自由视角下对巡检视野的智能化分析、风险预警和及时响应。具备安全预警能力的巡检系统需要解决视野中目标像素小、尺度变化大、检测背景复杂等问题,目标检出准确率是实现可靠巡检的关键。因此无人机视角的目标检测算法在本系统中占有相当重要的位置。
0.1 无人机图像中的复杂背景
无人机图像中目标检测属于自然图像目标检测,一些学者开始尝试利用优秀的自然图像目标检测方法对无人机影像中的目标进行检测。Wang X[1]等人尝试将一些具有代表性的卷积神经网络网络运行在斯坦福无人机数据集上测试其效果,最终得出RetinaNet检测器展现出最快和最准确的检测性能;Yakoub Bazi[2]在其文章中提出一种新的卷积支持向量机,此网络在拥有有限训练样本的数据集中依旧表现良好,并在多个车辆数据集中进行测试时得到接近最好卷积网络的检测效果;Dimitrios Meimetis[3]等提出将DeepSORT与YOLO检测相结合的方法,在数据集和各种实地飞行视频中对车辆和行人实现多重跟踪。
0.2 无人机场景中的小目标问题
小目标的定义主要有两种:第1种是绝对小的目标,其像素值不超过32×32时,此物体即可被看作是小目标;第2种是相对小目标,当目标尺寸小于图像尺寸的0.1时可以被看作相对小目标[4]。而无人机视野中目标又存在多尺度和小像素的特点,所以该类检测算法发展早期代表性算法有YOLO、Faster R-CNN等,只使用主干网络最后一层特征进行目标检测,造成网络检测小目标能力较弱;刘颖[5]等人提出的SSD中首次使用多尺度预测方法,改善小目标检测性能。在机器学习目标检测中,图像金字塔是构建多尺度特征的主流方法,通过对图片的多尺度缩放来提取不同尺度特征,然后在每个分辨率图像上分别利用基于滑动窗口的方法进行目标检测,以求检测出低层特征中的小目标,MTCNN就是利用这一思想首先构造图像金字塔,从而检测出不同分辨率的人脸目标[6];而随着深度学习的发展,卷积神经网络逐渐替代图像金字塔的方式。Fu[7]等学者认为SSD用于小目标检测的特征层含有的语义不丰富,导致误检和漏检,因此于2017年提出DSSD使用ResNet-101代替VGG16作为特征提取网络,并将高层特征的语义信息融入底层特征,提高底层特征的表达能力;Liu[8]等又提出FPN网络,它实现了不同尺度的信息提取,提升了小目标的检测性能,2018年提出的PANet[9]网络在此基础上又进一步融合高层和低层的语义信息并将其应用于目标检测中,而在此之后学者们又陆续提出ASFF[10]、AugFPN[11]网络从不同角度对FPN结构进行改进;SNIP[12]提出在训练中只对和ImageNet数据集中目标尺度相近的ROI区域计算梯度,并利用图像金字塔得到多尺度高分辨率目标信息;TridentNet[13]针对尺度变化问题,通过控制空洞卷积参数来控制感受野大小,并通过卷积层信息融合来提高算法检测精度。
1 河滩数据集
本文训练所需要的河滩-人员数据集主要由两部分组成:人员目标检测数据集和河岸场景数据集。其中人员目标检测数据集主要用于River-YOLO训练,河岸场景数据集则主要用于DeepLabV3+模型进行河岸场景分割训练。而本文最终的目的是实现河岸人员安全检测,因此数据集存在一定的重叠。
1.1 河滩地貌分割数据集
河岸地貌场景特殊,在不同天气和光照条件下亮度和颜色均所差异。为了防止过拟合和提升网络的泛化能力,对河道图像进行数据增强操作。本文取不同季节、天气条件下黄河河岸视频36个,用Labelme进行数据集标注,然后通过旋转、裁剪、椒盐噪声、高斯噪声、调节亮度和对比度等方式进行了数据集扩充。样本增广完成后,将9000帧图像用于训练,2250帧图像作为验证集,剩余的2250帧图像作为测试集。河流地貌分割数据集如图1所示。

图1 河流地貌分割数据集
1.2 人员检测数据集
无人机视角目标检测数据集与普通行人检测数据集有显著差异。无人机俯拍图像的目标像素小、信息少,背景复杂,且可能有抖动和光照变化。因此,需要构建专门针对无人机视角的数据集,以训练适应这些特殊场景的目标检测模型。
本文采用的人员检测数据集除了1.1中包含的河岸行人视频帧以外,还加入了Okutama-Action数据集进行数据集扩充。从而搭建了无人机视角下的人员目标检测数据集。其中数据集部分图像如图2所示。

图2 新增河滩人员数据集
2 模型设计
2.1 DeepLabV3+河滩地貌分割
DeepLabV3+是Chen、Zhu等[14]在2018年提出的一种基于DeepLabV3的改进算法,通过将原有的DeepLabV3结构作为编码模块,在此基础上添加了一个简单有效的解码模块。自从DeepLabV3+语义分割网络被提出后,凭借其出色的图像分割效果,经常被用于高精度的图像分割[15],目前已经成为非常热门的分割网络之一。DeepLabV3+的结构如图3所示。

图3 DeepLabV3+网络结构
2.1.1改进DeepLabV3+网络结构
DeepLabV3+语义分割网络能够达到较高的精度,但它使用修改后的aligned Xception主干网络由于网络层数多,参数量大,且特征提取后在ASPP模块中进行卷积操作,参数量大,模型复杂度高,增加了网络训练的难度,网络训练速度较慢,收敛性较差。为了提高网络分割能力和训练效率,本文针对DeepLabV3+网络结构做了三点改进,如图4所示为改进后的DeepLabV3+网络结构。

图4 改进后的DeepLabV3+网络结构
2.1.2改进的主干特征提取网络
在编码模块,将用于特征提取的Xception网络改为较轻量级的MobileNetV2网络,与Xception网络相比,MobileNetV2网络的参数更少,模型结构更简单,网络训练速度更快。
2.1.3D-ASPP模块
通过在ASPP模块上引入深度可分离空洞卷积,减少计算和模型的复杂度,从而构建出D-ASPP模块。如图5所示,首先将经过MobileNetV2网络特征提取后的深层特征输入到D-ASPP模块中,经过一个1×1扩张率为1、3×3的扩张率分别为6、12、18的深度可分离空洞卷积和全局平均池化5条支路。
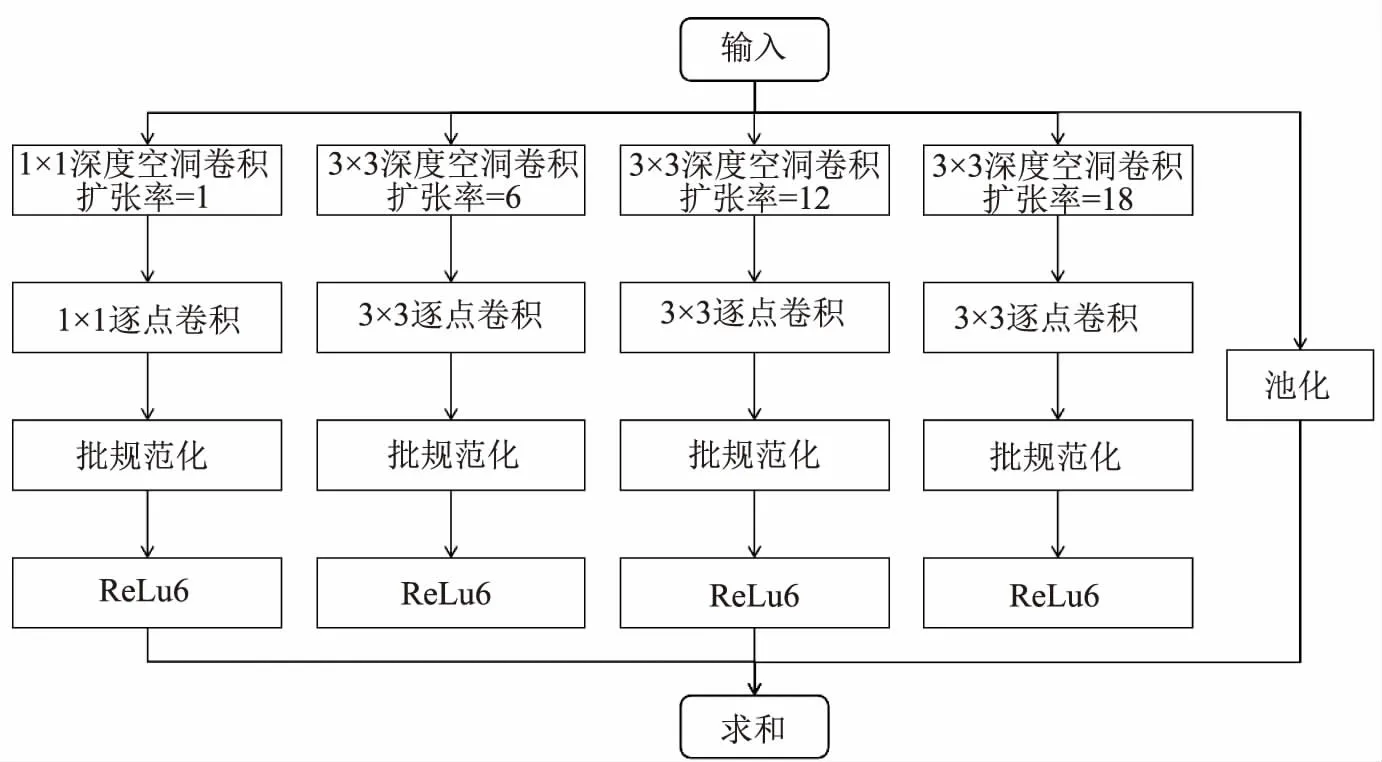
图5 D-ASPP模块
2.1.4CA注意力机制
为了增强图像深层特征的表示能力,在MobileNetV2特征提取网络提取的浅层特征和D-ASPP模块之后,加入CA注意力机制以提高模型的分割精度。CA注意力机制(CoordAttention)首先使用两个一维全局平均池化操作,将通道注意力分解为两个沿不同方向进行聚合的特征编码过程,形成具有两个独立方向感知的特征图;然后对特征图进行编码形成一对具备位置敏感和方向感知的特征图;最后两个特征图通过乘法可以互补地应用于输入特征图中以强调对感兴趣目标的表示。
在训练DeepLabV3+模型时,首先选取采集的无人机视频数据中包含河岸和河水的图片作为训练集,并使用lableme软件标识出河水区域,然后将标识后的数据集送入DeepLabV3+模型进行训练,当反馈的模型误差值不再降低,模型收敛时停止训练,此时训练好的模型即可用于预测无人机视频图像中的河水区域。
2.2 Beach-YOLO河滩人员检测
2.2.1River-YOLO算法设计
YOLOv7[16]作为目前YOLO系列的最新作品,其具有检测速度快、准确度高、易于训练和部署等特点,比同体积(FPS)的YOLOv5快120%,在实时目标检测领域中独占鳌头,但在深度卷积神经网络中计算量大,且在进行特征计算时,卷积神经网络对特征的关注度较为分散。因此本文针对巡检任务需求,在算法实时性、精度和鲁棒性方面做出针对性的改进,使其具备更加优异的性能,符合无人机河岸巡检系统设计要求。改进的YOLOv7的网络模型如图6所示。

图6 改进后的YOLOv7网络模型
2.2.2基于GhostNet的主干网络改进
通过将主干网络替换为较轻量级的GhostNet网络,降低了计算量并提高了算法的实时性,同时保持了对特征的识别性能。GhostNet的核心思想是采用一种分阶段的卷积计算模块,利用线性卷积在非线性卷积特征图的基础上获取更多特征图,从而消除冗余特征,实现了轻量级模型的目标。
GhostNet的工作方式是首先使用少量的普通卷积核来提取特征信息,并减少输出通道数。接着,通过线性变换和恒等映射来增强特征。最后,将特征信息进行拼接,生成相应的特征图。
GhostBottleneck模块与ResNet中的基本残差块相类似。它由两个Ghost模型堆叠而成,其中第1个Ghost模型主要用于增加通道数,而第2个Ghost模型则用于减少通道数量。这种堆叠的结构有助于更好地优化特征提取和降低计算复杂性,从而提高GhostNet的性能。
2.2.3NAM注意力机制的特征融合网络
为了降低非显著的特征的权重,提高在复杂光照条件、人员像素小等情况时的检测精度,在网络模型的颈部加入了4个NAM注意力机制,使得权重计算更加合理,有效提高算法的检测精度,抵消因主干特征提取网络模型参数量减少而导致的检测精度下降问题。本文在CBAM注意力机制基础上进行集成,并对通道和空间注意力子模块重新设计,最后将其嵌入主干网络提取的3个有效特征图末尾。
对于通道注意力子模块(CAM),通过BN中的比例因子来计算通道方差,如式(1):
(1)
式中,μβ—均值;σβ—标准差;γ、β—可训练的尺度和位移。Mc—CAM的输出特征,如式(2):
(2)
式中,γi—通道的缩放因子,权重由Wγ获得。同样的,将BN的比例因子也应用于空间注意力子模块(SAM),用来衡量像素的重要程度,在SAM中被命名为像素归一化(Pixel Normalization),SAM的输出特征Ms如式(3):
(3)
式中,λi—缩放因子,权重由Wλ获得。
2.2.4基于SIoU的损失函数改进
根据坐标损失函数计算公式,当预测框的长宽比和真实框的长宽比相同时,长宽比的对比项v为0,没有起到作用,CIoU损失函数无法得到稳定表达,且会导致训练过程中预测框的漂移问题,降低模型训练速度。因此采用SIoU函数替换原来的CIoU损失函数。将回归之间的角度成本纳入考虑范围,通过向量角对距离重新进行定义,降低损失函数的总自由度。
SIoU损失函数由角度成本、距离成本、形状成本和IoU成本组成,其定义分别如下:
(1)角度成本。角度成本的计算公式如式(4):
(4)
式中,Ch—预测框和真实框的高度差值;σ—预测框和真实框的距离。
(2)距离成本。距离成本代表预测框和真实框的距离,根据角度成本对距离成本重新定义如式(5):
(5)
式中,A(ax,ay)—预测框;B(bx,by)—真实框;Cx、Cy—预测框和真实框组成的最小外接矩形的长和宽。
(3)形状成本。形状成本的定义如式(6):
Ω=∑t=w,h(1-e-wt)θ
(6)
式中,(wa,ha)—预测框的宽和高;(wb,h,)—真实框的宽和高,θ—控制对形状成本的关注程度。
(4)IoU成本。IoU成本的定义如式(7):
(7)
综上所述,最终SIoU损失函数定义如式(8):
(8)
通过加入角度成本,在减少长宽比的对比项为0的概率的同时,使得坐标损失函数收敛更平稳,改善回归精度,提高了模型预测的准确性和预测速度。
综上所述,本文通过分析现有方法存在的问题,根据河岸巡检系统需求对YOLOv7算法进行针对性的改进,降低计算量并提高算法实时性;通过在颈部添加NAM注意力机制来有效提高算法的检测精度,抵消因主干网络模型参数量减少而导致的检测精度下降问题;最后采用SIoU函数替换原来的CIoU损失函数,提高算法的鲁棒性和实用性。
3 模型评估
3.1 DeepLabV3+模型评估
本文提出的改进DeepLabV3+网络效果如图7所示。

图7 DeepLabV3+分割效果对比
由图7可知,在分割边缘部分,改进前的DeepLabV3+模型识别轮廓不够精细,部分像素的分割结果较差,如河段1改进后的边缘部分较改进前包含了更多的河水区域,河段2改进前出现了将部分边缘河岸判定为河水的情况,而本文改进的DeepLabV3+模型识别轮廓更加贴近河岸线,同时分割边缘更为光滑,证明了改进的DeepLabV3+网络模型在分割效果和准确率方面都有了一定的提升。
由表1可知,本文改进后的DeepLabV3+模型的分割速度比改进前快了0.09s,极大地提高了分割速度。同时改进后的模型其召回率、平均像素精度和平均交并比分别达到了97.83%、98.47%和97.11%,比改进前的DeepLabV3+模型分别提高了0.35,0.29和0.57个百分点。综上,改进后的模型表现较好,在检测精度上有一定提升的情况下显著提高了分割速度,在应用于河岸场景实时检测时更具优势。

表1 DeepLabV3+分割结果对比

表2 不同算法在River-person数据集运行效果对比
3.2 River-YOLO模型评估
为验证本文设计的River-YOLO(以下简称:Ours)检测效果,本文将其与MobileNet-SSD、YOLOv5、YOLOv7经典检测算法进行对比,主要从检测准确率、模型大小和运行速度等方面进行分析。
可以看出,本文设计的River-YOLO的mAP最高,达到了90.3%,具有最高的识别准确率,同时FPS作为评价目标检测速度的指标,证明了该算法完全满足河岸巡检系统对于实时性的需求,相比于MobileNet-SSD、YOLOv5算法,无论在精确度或者是实时性上都具有更优秀的表现。而原YOLOv7算法在检测精度上与River-YOLO相比差距不大,但本文通过针对性的改进进一步提高了原算法的实时性,使得River-YOLO算法在保证具有较高检测速度的同时,能够有效平衡了检测速度与精度。实验证明River-YOLO算法更适合部署于软件平台进行安全检测,具有实际应用意义。
在获得不同算法性能对比后,本文从小像素目标检测、光照与尺度变化的角度对River-YOLO、MobileNet-SSD、YOLOv5和YOLOv7算法进行测试。
(1)小像素目标检测
无人机视角下的人员像素一般较小,而目标检测算法针对小像素的检测难度较大。因此算法测试中,在选取河岸周边典型场景后,首先针对小像素目标检测进行对比。
如图8所示,River-YOLO算法在面对小像素目标检测时仍能够准确识别出图像中的人员,YOLOv7表现同样出色,MobileNet-SSD和YOLOv5均有不同程度的漏检情况出现。

图8 小像素目标检测
(2)光照与尺度变化
在无人机巡检过程中,由于飞行距离、相机转动等经常会面对光照与尺度变化所带来的干扰,同时水面反射同样会造成一定程度的影响。光照与尺度变化如图9所示。

图9 光照与尺度变化
通过对比图8—9后发现,在光照和尺度发生变化后,尤其是视频图像较近时,River-YOLO、YOLOv7和YOLOv5均表现出色,MobileNet-SSD在面对树木遮挡时检出率较低,只能检测出较为清晰的目标。
综上,本文所设计的River-YOLO算法在滩区人员预警方面有明显优势,验证了改进算法的有效性。
4 结语
本文针对河流巡检中的人员安全预警算法进行研究。首先,采用基于DeepLabV3+的河滩场景分割算法进行河水区和其他区域的划分;然后,针对人员检测像素小、尺度变化大的特点,设计River-YOLO目标检测算法,采用GhostNet网络减小YOLOv7网络模型,并用Nam注意力机制和SIoU损失函数提高网络预测精度,在算法实时性、精度和鲁棒性方面作出有效平衡,并将改进后的算法和MoblieNet-SSD、YOLO等经典算法进行对比,本算法表现出更优越的性能;最后通过在巡检视频中对DeepLabV3+和River-YOLO进行安全检测的效果进行分析,本文提出的安全预警思路具有良好的检测效果。
