自适应聚合和代价自学习的多视图立体重建
2023-09-12张晓燕
张晓燕,陈 祥,郭 颖
(1.厦门大学嘉庚学院信息科学与技术学院,福建 漳州 363105;2.厦门大学电子科学与技术学院,福建 厦门 361005;3.西安机电信息技术研究所,陕西 西安 710065)
0 引言
近年来,移动设备和无人机获取二维图像变得越来越简单,但是二维图像缺少空间信息的真实性和完整性,不能够表达空间对象间的立体关系,因此,多视图立体重建技术得到了广泛重视和飞速发展。多视图立体重建是在已知多个视角的图片集合及其对应的相机内外参数条件下,恢复场景或者物体的三维几何模型,该技术不仅能给人以更真实的感受,而且还能描述和表达物体之间的图像场景和深度关系。在三维可视化、虚拟现实、场景理解、智慧医疗和自动驾驶等领域中有着广泛的应用[1-2]。
传统的多视图重建方法是利用摄像机从多个角度拍摄物体,之后通过各个角度视图之间的几何关系计算并优化深度。文献[3]开创性地提出了Colmap,该方法采用手工设计特征提取器提取特征,由于其在公共数据集上的重建结果较理想,Colmap经常被选为对比方法来证明提出方法的有效性;然而Colmap重建耗时长,即便小场景也需要耗费若干小时。文献[4]提出名为OpenMVG的开源库,包含运动结构恢复(SFM)所需的工具,代码开源可读性强,方便二次开发;但OpenMVG的缺点在于只能恢复场景的稀疏点云,无法恢复场景的稠密点云。针对这个缺点,文献[5]提出了OpenMVS,重建结果即为场景的稠密点云。虽然OpenMVS是目前重建效果最好的开源库,但仍存在无纹理区域、弱纹理和遮挡区域重建效果差的困扰。
为了解决这些问题,有学者使用卷积神经网络[6-7]进行多视图立体重建。文献[8]提出利用卷积神经网络直接对单张图像恢复深度,该网络采取了多尺度的结构进行深度预测,并且将尺度不变特性引入损失函数中,极大地增强了网络的泛化能力,为后续学者使用深度学习方法进行多视图重建奠定了基础。文献[9]提出3D-R2N2(3D recurrent reconstruction neural network)网络,该网络构造了卷积神经网络和长短期记忆(long short-term memory,LSTM)相结合的编解码器架构,通过投影操作将相机参数编码到网络中,输出三维网格来重建三维场景。文献[10]提出了SurfaceNet网络,该网络通过将相机参数和图像以三维体素共同编码表示构建的卷积神经网络,其核心优势在于能够解决多视图立体中的图像一致性和几何相关性问题。这两种方法都使用了基于体素的方法,重建中需要耗费大量显存,只适用于小规模场景的三维重建。文献[11]提出MVSNet,该方法参照了传统平面扫描法的策略,基于参考视图的相机视锥体构建三维代价,然后使用三维卷积对代价体进行正则化,回归得到深度图。由于是第一个完整的基于深度学习多视图立体重建方法,MVSNet已经成为其他基于深度学习的多视图几何重建的基准。文献[12]提出了R-MVSNet,此网络将三维卷积神经网络(3D CNN)替换成门控循环单元(GRU)进行正则化,极大降低了显存的消耗,但同时增加了重建时间。文献[13]提出P-MVSNet,主要创新点在于提出了基于区域匹配置信度的代价体,通过学习的方式将每个假想面上的特征匹配置信度聚合变为一个向量而非常量,从而提高了匹配的准确度。文献[14]提出了一种基于跨视角一致性约束的无监督深度估计网络Unsupervised-MVSNet,该网络提出了一种无监督的方法来训练网络,并且利用多个视图之间的光度一致性和像素梯度差异作为监督信号,来预测深度图,取得了不错的重建结果。文献[15]提出一种直接基于点的匹配代价正则化方法——Point-MVSNet,该网络的核心是把三维几何先验知识和二维纹理信息融合到特征增强点云中,得到的重建结果精度更高,效率更优。文献[16]提出AA-RMVSNet,该网络提出自适应逐像素视图聚合匹配代价模块,能够在所有视图之间保留更好的匹配代价体,克服了复杂场景中弱纹理和遮挡的问题。文献[17]提出EF-MVSNet,该网络仍然以MVSNet为基本框架,在深度图优化阶段引入边缘检测模块来预测深度图边缘像素的偏移量,并通过多次迭代得到最终深度估计结果。
虽然深度学习多视图立体重建具有很强的学习能力,能够挖掘更多的图像潜在特征,在特征匹配时具有更高的准确性,进而得到更优的结果。但是由于其特征提取结果未将不同尺度图像特征进行聚合,得到的结果仅仅是输入图像经过连续下采样后的输出,并且匹配代价体在正则化后仍然存在离群点问题,将会影响加权回归得到的深度图,进而影响整个重建的准确性和完整性。为此,本文在深度学习网络基础上提出自适应聚合和代价自学习的多视图立体重建,提高重建结果的完整性和整体性。
1 多视图立体重建网络架构的建立
虽然MVSNet网络可以得到不错的重建结果,但该网络仍忽略了聚合不同尺度特征信息和匹配代价体优化。为了解决上述问题,本文设计了一个自适应聚合特征提取模块,针对标准卷积具有固定感受野,在弱纹理和无纹理区域特征提取困难的问题,使用可变性卷积来自适应调整感受野的大小,并且将不同尺度的具有不同纹理丰富度的图像特征聚合,提升纹理特征提取的丰富度。同时,设计了一种代价自学习模块,针对匹配代价体中存在的离群点问题,通过使用可变形卷积来改变卷积核形状,为离群点寻找一些可靠且关系密切的相邻点,用相邻点的代价分布来替代离群点的代价分布,从而提升匹配代价体的准确性。
本文设计的多视图立体重建网络架构如图1 所示。从图中可看出本文工作主要包括:1) 引入一个自适应聚合特征提取模块,通过可变形卷积自适应地聚合具有不同纹理丰富度的特征区域;2) 引入一个代价自学习模块,通过可变形卷积自适应优化匹配代价体离群值。
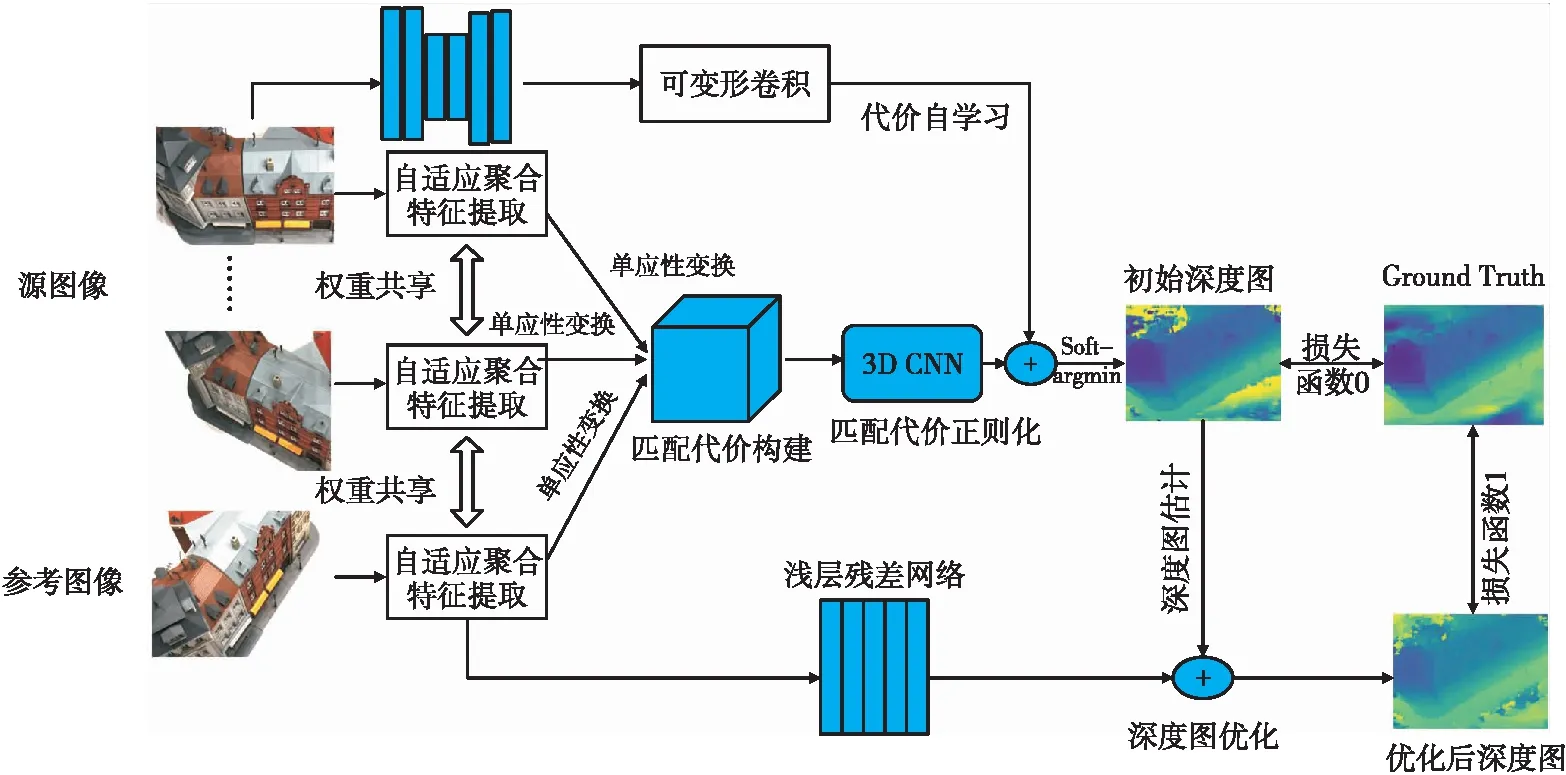
图1 网络整体架构
2 自适应聚合和代价自学习的多视图立体重建
本文的多视图立体重建网络实现包含以下主要步骤:自适应聚合特征提取、匹配代价体构建、匹配代价体正则化、代价自学习、深度图估计和优化以及损失函数选定,最后得到优化后的深度图。
2.1 自适应聚合特征提取
由于标准卷积具有固定的感受野,在面对弱纹理和无纹理区域时无法有效地提取出较好的特征结果。为了弥补这个不足, 本文引入了可变形卷积[18-19]进行自适应聚合特征提取。
可变形卷积是将标准卷积的卷积核在每个空间采样位置上都增加一个2D偏移量。通过这些偏移量,使得卷积核可以在每个空间采样位置附近自适应地采样,而不再局限于规则格点。因此,可变形卷积可以自适应地调整尺度或者感受野的大小,提取到更多有效的目标区域特征。可变形卷积和标准卷积的卷积核形状对比如图2所示,图(a)为标准卷积的卷积核形状,图(b)、(c)和(d)为可变形卷积的卷积核形状,其中蓝色的点是新的卷积点,箭头是位移方向。
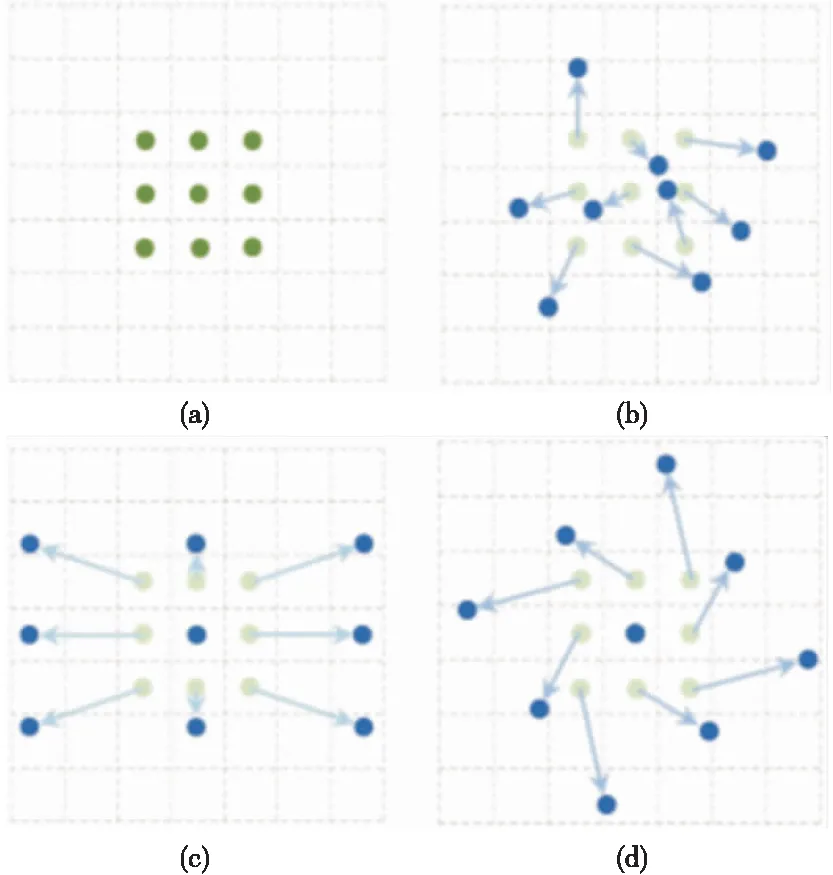
图2 卷积核对比图
本文设计的可变性卷积自适应聚合特征提取模块结构如图3所示。该模块使用了12层结构的卷积层,其中,从第三个卷积层开始,每隔3个卷积层步长均除以2,得到的特征图大小分别为原尺寸分辨率的1、1/2、1/4和1/8。对于每种尺度特征,都是经过三层卷积处理得到的,最后四种特征均通过可变形卷积自适应处理并经过双线性插值沿特征维度进行堆叠,得到最终的输出特征图,其维度为H/4×W/4×64。可变形卷积定义如下:
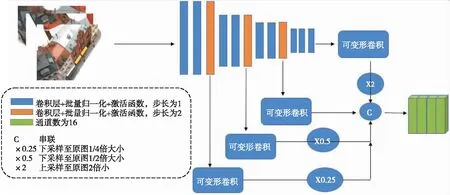
图3 自适应聚合特征提取
(1)
式(1)中,f(p)表示像素点p的特征值,wk和pk分别表示卷积核参数和偏移量,Δpk和Δmk分别表示可变形卷积的可学习子网络自适应产生的偏移量和调制权重。
2.2 匹配代价体构建
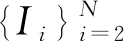
(2)
式(2)中,d为深度值,K为相机的内参数,R为旋转矩阵,RT和KT为转置矩阵,nT为平面法向量的转置。
为了引入任意数量的输入视图,构建匹配代价体时使用基于方差的方法,以此来衡量各个视角构成的匹配代价体之间的相互关系。其计算公式为
(3)
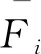
2.3 匹配代价体正则化
由于真实场景中存在遮挡,得到的初始匹配代价体往往存在噪声。为了减弱噪声对结果的影响,需要对得到的初始匹配代价体进行正则化。本文使用具有多尺度的3D CNN对匹配代价进行正则化,具体结构如图4所示。由于匹配代价体是三维结构,因此仅仅对匹配代价体下采样两次,目的是为了减小正则化所需的大量内存。
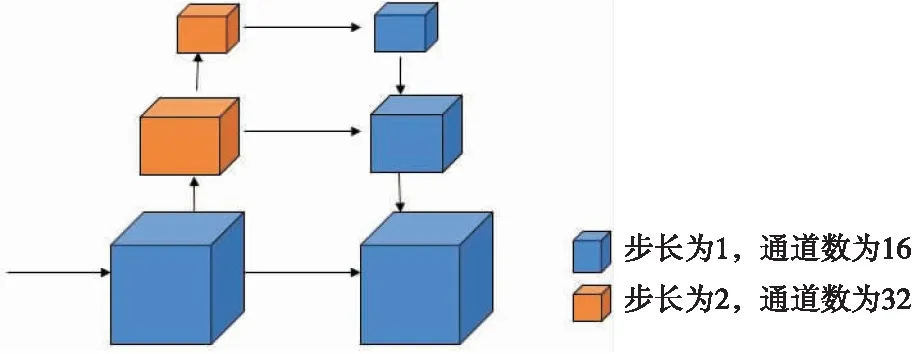
图4 匹配代价正则化
2.4 代价自学习
匹配代价体的优化方法一般通过使用普通的卷积网络预测残差来纠正离群值,但由于卷积核形状的固定性,普通卷积很难优化离群值。因此,为了解决这个问题,本文提出代价自学习模块,具体结构如图5所示,利用可变形卷积自适应地调整卷积核的感受野大小,使得离群点可以自适应寻找到其最可靠的相邻像素。该模块首先将参考图像作为输入并输出密集特征;之后,使用可变形卷积对每一个像素点使用特征预测几个偏移量,每个偏移量包含两个通道,表示相邻点的像素坐标。利用这些坐标,对相邻像素匹配代价进行采样,并计算其平均值来更新该像素的匹配代价。该模块可用如下公式表示:
图5 代价自学习
(4)
式(4)中,Cr和Co分别为优化后的匹配代价体和初始匹配代价体;(Δxi,Δyi)是在(x,y)像素坐标上预测的偏移量;mi是调制权重,范围为0~1;N是控制采样相邻像素数量的超参数,若点数越多,结果越好,但消耗的内存也越多。
2.5 深度图估计和优化
2.5.1深度图估计
优化后的匹配代价体经过soft-argmin函数处理,可以获得每个像素在不同深度采样值处的概率估计。通过将所有深度假设值与概率估计加权回归计算可得到每个像素的深度估计值,即完成了深度图估计。其原理是概率估计上的每个点都对应在某一深度值下的置信度,如果直接选取概率值最大的深度值作为估计值,在网络中将无法通过误差反向传播获取最优结果。因此,在得到概率估计后,计算每个深度下的加权平均值。具体公式如下:
(5)
式(5)中,dmin和dmax表示深度范围,d为深度范围内均匀采样深度值,P(d)为在某一深度d处对应的概率估计值。
2.5.2深度图优化
由于深度学习网络具有较大的感受野区域,得到的深度图边界可能会过平滑,因此需要使用浅层残差网络对深度图进行优化。浅层残差网络由6个卷积层构成,首先输入初始深度图和其对应的RGB图,将其串联成通道为4后即可输入第一层卷积层,在经过连续的6层卷积层后,输出通道数为1的卷积结果,将此结果与初始深度图相加,得出的结果即为最终的深度图。
2.6 损失函数选定
本文中使用L1函数作为损失函数,在网络训练时,损失函数计算每次迭代的前向计算结果与真实值的差距,并通过反向传播更新各个参数,使得模型生成的预测值向真实值靠拢。损失函数公式如下:
(6)
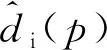
3 实验验证
3.1 数据集
DTU数据集是为了解决多视角立体重建问题专门拍摄并预处理过的室内数据集,通过可调节拍摄角度和亮度的工业机器臂拍摄得到。DTU数据集由124个不同场景组成,每个场景包括49或64个不同方向在7种不同光照条件下拍摄的图像,每张图像原始分辨率是1 600×1 200像素。
3.2 模型训练与测试
DTU数据集原始分辨率为1 600×1 200像素,由于存在三维卷积,如果直接输入需要耗费巨大的显存。因此,在训练阶段将输入图像大小裁剪为640×512像素,输入数量为5,选取DTU数据集中79个场景作为训练样本。学习速率初始值设为0.001,并且在训练10个批次后每隔两个批次学习率减半。深度假设平面数量设置为160,深度间隔大小为1.272。本网络是基于Pytorch的神经网络搭建,显卡为NVIDIA RTX 2080Ti,使用显存大小为11 GB,损失函数中μ0和μ1分别设置为1和0.8(此值通过多次训练调整得出),训练批次为16。
因为训练阶段需要额外的内存来保存中间梯度用于反向传播,而在测试阶段不需要,因此输入图像分辨率设置为1 184×1 600,输入视角数量为7,测试集样本为DTU中的22个场景,深度假设平面数量设置为256,深度间隔为0.795。
3.3 测试结果比对
本文方法与传统方法和深度学习方法的评估对比结果如表1所示。表1中前四种方法为传统方法,后两个为基于深度学习的方法。官方公布的DTU数据集重建结果评估[20-21],具体为三个值:准确性、完整性和整体性。 准确性是重建点云与真实点云之间作差的结果,完整性是从真实点云到重建点云之间作差的结果,整体性是准确性和完整性求和的平均值,这三个值越低表明模型重建结果越好。

表1 DTU数据集评估对比结果
从表1可知,与传统方法和深度学习方法相比,本文方法重建的整体性为0.432,完整性为0.420,是所有方法中重建结果最好的。与深度学习基准方法MVSNet相比,本文方法在整体性上提升了3.0%,完整性上提升了10.7%,充分说明了本文方法的有效性。本文方法重建的准确性为0.444,相比较MVSNet,准确率降低了4.8%。导致这种现象的原因可能是网络模型复杂度增加,反向传播的参数量增多,使得模型泛化性能降低。
图6为DTU部分场景的重建结果对比图,从图中可以发现本文方法重建结果相较于MVSNet的完整性上有了很大的提升,尤其是在边缘和弱纹理区域,本文的重建结果更精确且完整,与Groud Truth更接近。这些从图中框出的部分能够明显看出,充分说明了本文方法的有效性。
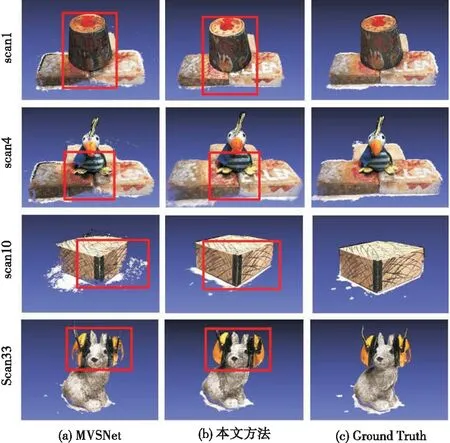
图6 DTU部分场景重建结果比对
3.4 消融实验
在前面部分验证了网络的整体性能,为了检验本文部分模块的有效性,进行消融实验。围绕本文方法中的自适应聚合模块和动态自学习模块,分别建立了2组对比实验,结果对比如表2所示。
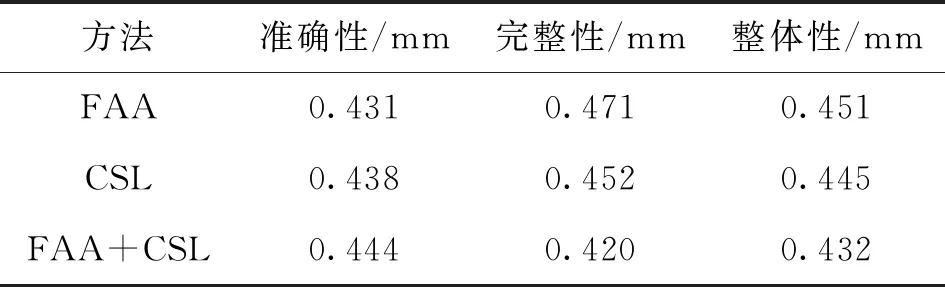
表2 DTU数据集消融实验结果对比
表2中,FAA是自适应聚合特征提取模块,CSL是代价自学习模块。从表2可知,加入FAA后,网络重建结果的完整性为0.471,加入CSL后,网络重建结果的完整性为0.452,相比较于MVSNet分别提升了5.6%和7.5%。在同时加入FAA和CSL后,网络重建结果的完整性为0.420,是所有消融实验重建结果完整性最高的。因此,通过消融实验表明,本文方法充分利用了自适应聚合模块和代价自学习模块的优点,在一定程度上可以获得更完整的重建结果。DTU数据集消融实验对比结果如图7所示。
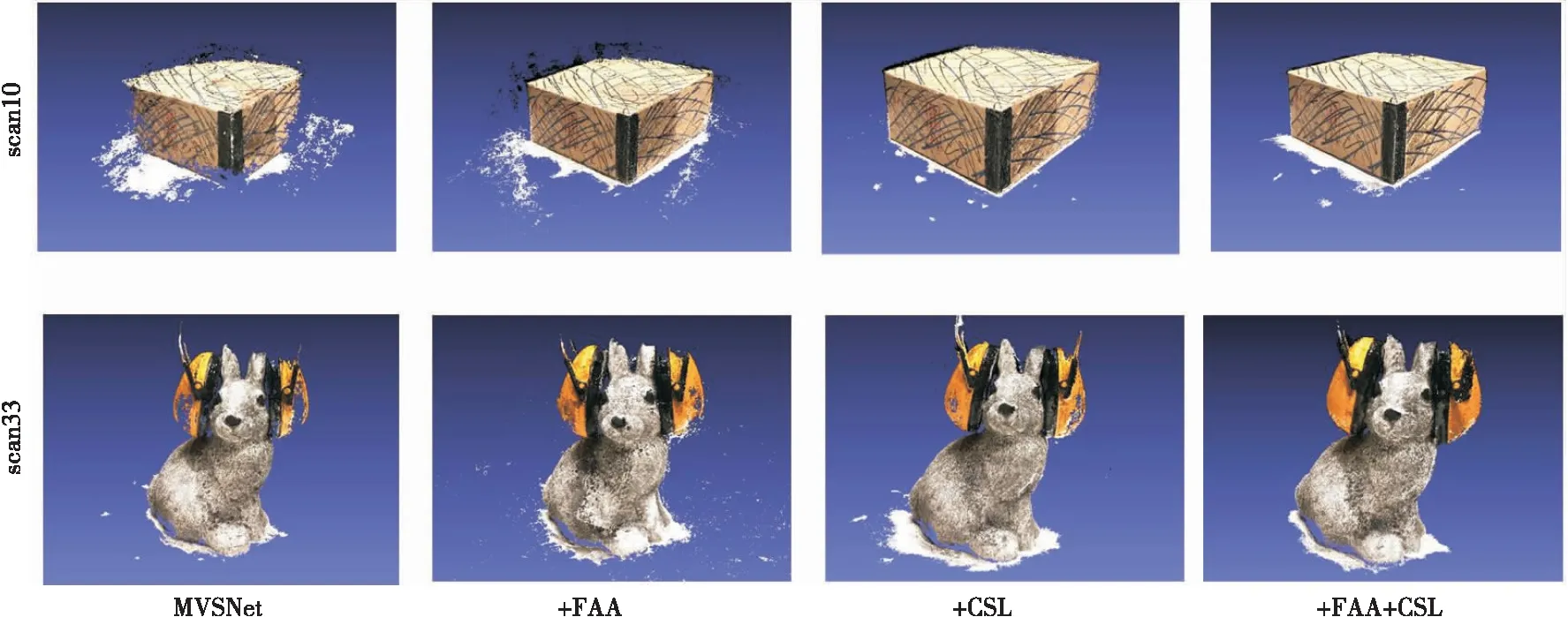
图7 DTU数据集消融实验结果比对
从图7中可以看出,自适应聚合模块的单独加入,使得模型可以重建出更加完整的结果。匹配代价体动态自学习模块的单独加入,使得重建结果边缘更加平滑和更少的噪点。当两个模块同时加入时,重建结果的完整性及边缘质量都好于未加入前的结果,充分证明了本文方法的有效性。
4 结论
针对MVSNet网络重建结果完整性较低的问题,本文提出基于MVSNet的改进网络。通过增加自适应聚合特征提取模块,使得特征提取结果能够包含更加丰富的特征信息。同时,通过增加代价自学习模块,缓解匹配代价体过度平滑问题。经过DTU数据集的测试与评估,本文网络在重建整体性和完整性都有不错的提升。相较于MVSNet,本文网络在整体性上提高了3.0%,完整性上提高了10.7%,得到了质量更优的三维重建结果。本文提出的方法可应用于数字孪生可视化平台、文化遗产保护以及动画电影制作等方面。
由于本文使用了3D卷积,虽然可以得到不错的重建结果,但该方法需要耗费大量的内存,只适用于中小规模场景的三维重建。同时,本文方法需要使用重建场景或物体的真实点云,但往往真实点云很难被获取。因此,未来的研究工作应该寻求无监督学习的方法和耗费计算资源更小的方法以便运用到大规模的室外场景重建。
