基于高分辨率网络的地铁人体姿态估计研究
2023-09-08刘珊珊冯赛楠田青钱付余豆飞牛志斌
刘珊珊,冯赛楠,田青,钱付余,豆飞,牛志斌
(1.北方工业大学 信息学院,北京 100144;2.交控科技股份有限公司,北京 100070;3.北京市地铁运营有限公司,北京 100044)
1 概述
随着交通行业的快速发展,我国铁路发生了翻天覆地的变化,见证了从无到有、从弱到强,从蹒跚起步、艰难延伸到铁路密布、高铁飞驰的发展历程[1],面对新时代,为了满足人民群众高质量出行的需要,坚持和发展铁路技术创新尤为重要。目前来说,地铁成为人们工作生活中主要的出行方式,也正因为其过大的人流量,导致地铁车站及车厢的人流量密集,传统的行人检测在密集场景下容易出现误检、漏检的情况。人体姿态估计的任务是确定图像中人体某一身体部位出现的位置,估计人关节点的坐标,广泛应用于地铁等密集场所下行人的动作识别,保证出行安全。研究依靠改进的人体姿态估计算法能够更好地避免背景遮挡、光照变化等影响行人检测,通过在地铁等实际场景中利用人体姿态估计的方法来追踪某段时间内人体姿势的变化完成动作识别[2-4],得到对人体姿态的实时监测与估计。
人体姿态估计方法可以分为自顶向下和自底向上2类[5]。其中自底向上的方法虽然在检测效率上具有一些优点,但检测精度并不高,而自顶向下的方法可以先检测出所有人体目标,再分别对每个目标的关键点进行检测,因此检测精度较高[6-8],所以本研究采取了自顶向下的方式进行人体姿态估计。
对于基于深度学习的人体姿态估计主要分为基于回归的方式和基于热图的方式[9-10],前者直接预测每个关键点的位置坐标,后者针对每个关键点预测一张热力图。热图是关键点的概率分布图,通常建模成围绕每个关键点的高斯分布的叠加,每个像素都给1 个值,这个值对应像素属于某个关键点可能性的值。当前基于热图的方式检测效果更好,因此,本研究高分辨率网络采用基于热图的方式进行关键点检测[11]。
在人体姿态估计的网络中,高分辨率网络(High-Resolution Net,HRNet)在整个检测过程中都保持着高分辨率的表征[12],将多分辨率子网通过并行的方式进行连接,同时进行多次多尺度融合[13],使该网络能够更加准确地预测热图。因此,采用了高分辨率网络作为主干网络,并在其基础上做了如下改进:首先添加了注意力机制模块,从空间维度和通道维度获取关键特征信息,增强特征的提取能力;其次为了更加精确地定位关键点,对损失函数进行了改进,使网络能够容忍背景像素上的微小误差,获得更好的收敛速度。
2 网络结构
2.1 HRNet整体结构
HRNet 主要是针对2D 人体姿态估计任务提出的。不同于其他网络通过下采样得到强语义信息,然后通过上采样恢复高分辨率,在不断地上下采样过程中丢失大量的有效信息,HRNet 可以在整个过程中保持高分辨率表征,因此较其他网络来说会明显提升人体姿势识别的效果。首先将高分辨率子网络作为第1 阶段的开始,逐步增加高分辨率到低分辨率的子网形成更多的阶段,并将多分辨率子网并行连接,通过在并行的多分辨率子网络上反复交换信息,进行多次多尺度融合,使每个高分辨率到低分辨率的表征都从其他并行表示中反复接收信息,从而得到丰富的高分辨率表征,多次融合之后的结果会更加精确[12,14],之后通过网络输出的高分辨率表示来估计关键点,提升预测的关键点热图的准确性(见图1)。

图1 HRNet结构
将HRNet 结构分为4 个部分,每个部分均存在1 个蓝色框和1个橙色框,其中蓝色框代表基本结构,橙色框代表过渡结构。HRNet 中第1 部分蓝色框使用的是BottleNeck,其他部分蓝色框使用的是BasicBlock。第1 部分橙色框是1 个TransitionLayer,第2 和第3 部分橙色框是1 个FuseLayer 和1 个TransitionLayer 的叠加,第4部分橙色框是1个FuseLayer。
(1)BottleNeck 结构能够降低参数量,首先它利用PW(Pointwise Convolution)对数据进行降维,再进行常规卷积核的卷积,最后PW对数据进行升维,它的核心思想是利用多个小卷积核替代1 个大卷积核,利用1×1 卷积核替代大的卷积核的一部分工作。BottleNeck搭建模块见图2。

图2 BottleNeck搭建模块
(2)BasicBlock 结构包含1 个残差支路和short-cut支路,它比传统的卷积结构多了1个short-cut支路,用于传递低层的信息使得网络能够训练地很深。Basic-Block搭建模块见图3。
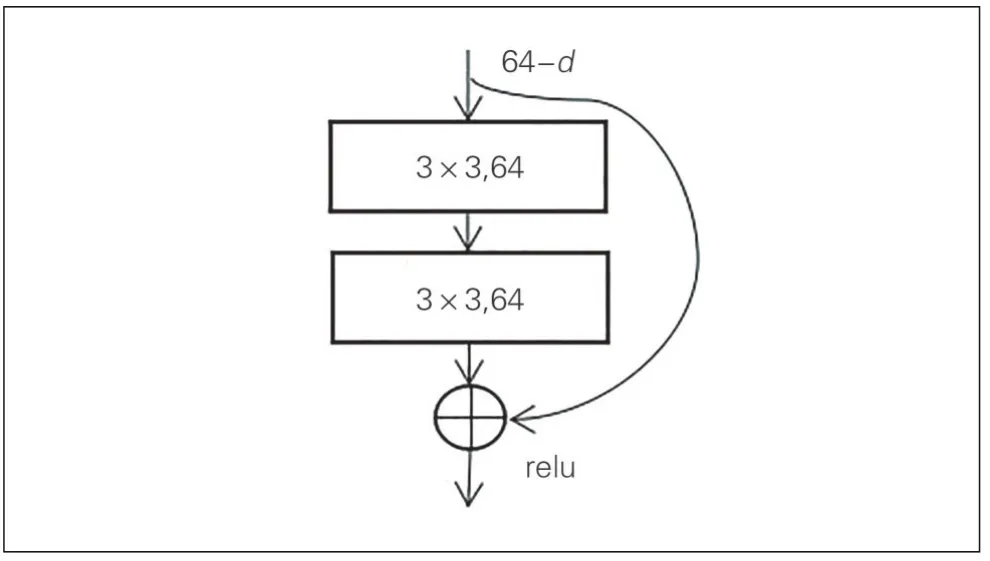
图3 BasicBlock搭建模块
(3) FuseLayer 用来进行不同分支的信息交互,TransitionLayer 用来生成1 个下采样2 倍分支的输入feature map。
HRNet是高分辨率的网络模型,面对频繁的下采样会导致空间方向特征丢失的问题,在进行特征提取和特征融合时,从输入到输出一直保持高分辨率表征[14],为了增强对输入图片的特征提取能力,因此在HRNet 中引入注意力机制模块,突出图像中尺度较小和遮挡人体关键点的特征,从而极大地提高HRNet 的性能。改进后的HRNet结构见图4。
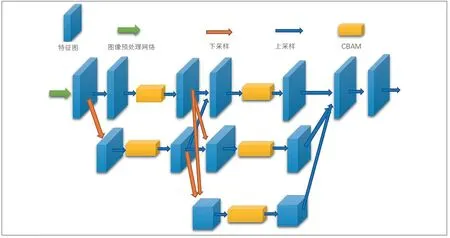
图4 改进后的HRNet结构
2.2 注意力机制模块
在计算机视觉中把聚焦图像的重要特征、抑制不必要的区域响应方法称作注意力机制(Attention Mechanisms),它在分类、目标检测、人脸识别、动作识别、姿态估计、3D 视觉等任务中发挥着重要作用,极大地提升了计算机网络的性能。
一般来说,注意力机制通常被分为通道注意力机制、空间注意力机制、时间注意力机制、分支注意力机制,把通道维度和空间维度组合[15],提出Convolutional Block Attention Module (CBAM),用于前馈卷积神经网络的简单而有效的注意力模块。相较于其他注意力机制模块,CBAM模块不仅保留了通道注意力,还添加了空间注意力,这使得网络模型能够注重关键信息的重要程度和关联程度、提升对关键区域的特征表达;空间注意力使神经网络更加关注图像中对分类起关键性作用的像素区域而忽略不重要的区域,通道注意力用于处理特征图通道的分配关系,同时使用2个维度上的注意力机制使模型性能得到更加明显的提升;CBAM内部使用轻量级卷积来获取通道和空间的注意力权重,因此它是1种可以嵌入到任何主干网络中以提高性能的轻量级模块,具有通用性;引入CBAM 可以提高目标检测和物体分类的精度,用到的计算量和参数都比较少,因此本研究引入CBAM 模块提高网络的检测性能。给定1 张特征图,CBAM 模块能够序列化地在通道和空间2 个维度上产生注意力特征图信息,然后2种特征图信息再与之前原输入特征图进行相乘进行自适应特征修正,产生最后的特征图。
CBAM模块主要由通道注意力模块和空间注意力模块组成,2个注意力模块采用串联的方式,首先在空间和通道上进行注意力机制处理,沿着通道和空间2个维度推断出注意力权重系数,然后再与feature map 相乘,CBAM结构见图5。
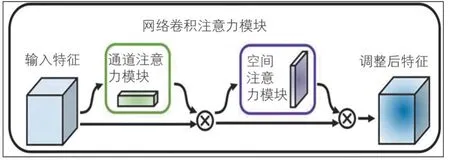
图5 CBAM结构
2.2.1 CBAM总体流程
首先输入网络主干生成的特征图F∈RC×H×W,经过通道注意力模块处理后,获得通道注意力图MC∈R1×1×C,通过跳跃连接的方式乘以输入特征图F中的相应元素,将结果F′送入空间注意力模块中,之后利用空间注意力模块生成带有空间注意力权重的特征图MS∈RH×W×1,最后乘以特征图F′得到最终的输出特征图F′′。CBAM 模块整体运行过程可以描述为以下公式:
式中:×表示元素级相乘。
2.2.2 通道注意力机制模块
通道注意力机制通过特征内部之间的关系来产生注意力机制特征图(见图6),特征图的每个通道可以当作一个特征检测器。
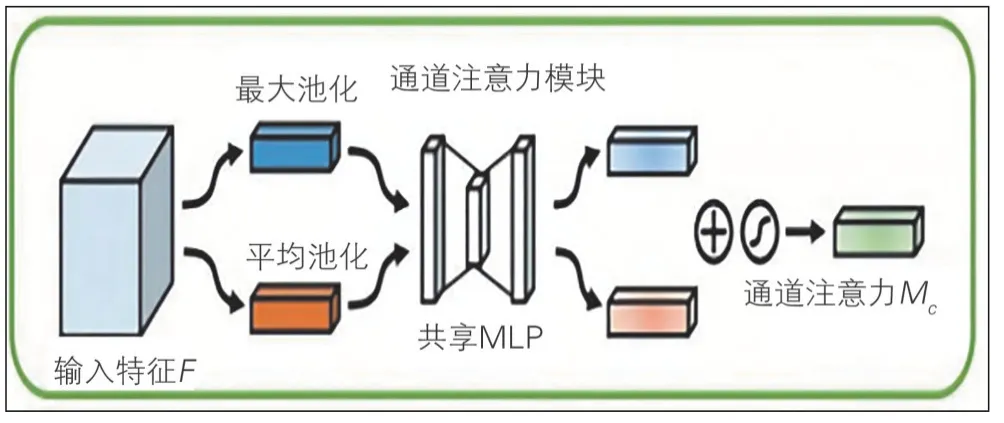
图6 通道注意力机制模块
压缩特征图的空间维度能够更高效地计算通道注意力特征,平均池化方法和最大池化方法都能够学习到物体的判别特征,同时使用这2种方法得到的效果更好,经过池化之后产生了2 种不同的空间上下文信息:代表平均池化特征的和代表最大池化特征的,然后再将该特征送入到一个共享的多层感知机(MLP)网络中,产生最终的通道注意力特征图Mc∈RC×1×1,为了降低计算参数,在MLP 中采用了一个降维系数r,Mc∈RC/r×1×1。
通道注意力计算公式为:
2.2.3 空间注意力机制模块
空间注意力机制通过特征图空间内部的关系,来产生空间注意力特征图(见图7)。
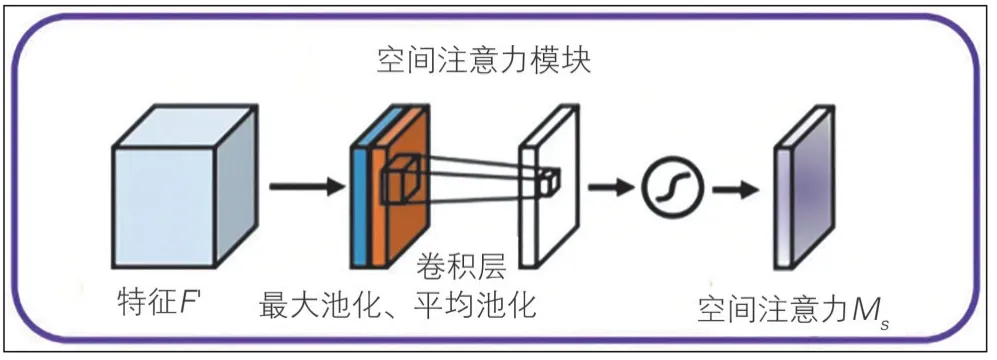
图7 空间注意力机制模块
为了计算空间注意力,首先在通道维度通过平均池化和最大池化产生2D 特征图:,然后拼接起来它们产生的特征图,在拼接后的特征图上,使用卷积操作产生最终的空间注意力特征图:Ms(F)∈RH,W。
空间注意力计算方式为:
2.3 损失函数的改进
2.3.1 均方误差损失(MSE)
均方误差损失(MSE)存在2 个问题:(1)MSE 损失的梯度是线性的,对微小误差不敏感,这影响了正确定位高斯分布mode 的能力;(2)在训练过程中,所有的像素具有同样的损失函数和权重[16],但是,在热力图中背景像素相对于前景像素是占有绝对主导地位的。这2 个问题导致由MSE 训练的模型预测出结果的前景像素是模糊和膨胀的,这样的低质量热力图可能会导致关键点的错误估计,因此将原本的MSE 损失函数改为Adaptive wing loss。
2.3.2 Adaptive wing loss
对于热图回归的理想损失函数,当误差很大时,损失函数具有恒定的影响,因此它将对不准确的注释和遮挡具有鲁棒性。经过不断地训练后误差减小,会出现以下情况[16]:
(1)对于前景像素(y=1),影响和梯度应开始增加,训练能够更专注于减少他们的错误,当误差接近于0时,影响会快速减少,此时这些已经“足够好”的像素不再被关注,正确估计的影响能够帮助网络保持收敛。
(2)对于背景像素(y=0),梯度应随着训练误差的减小,梯度会减小到0,因此,当误差较小时影响也会相对较小,训练时对背景像素的关注减少,对背景像素微小误差的敏感程度降低,能够稳定训练过程。
由于ground truth 热图的像素值范围是(0,1),这个损失函数应能够根据不同的像素值进行平滑的转换,且对于强度接近于1的ground truth像素,应增加小误差的影响,对于强度接近于0 的ground truth 像素,损失函数应该像MSE loss 一样,故而可以使用Adaptive Wing (AWing) loss[16],定义如下:
式中:y和分别为真实热力图和预测热力图的像素值;ω,θ,ε和α是正值;A=ω(1/(1+(θ/ǫ)(α-y)))(α-y)((θ/ǫ)(α-y-1))(1/ǫ),C=(θA-ωln(1+(θ/ǫ)α-y))是为了使损失函数在|y-|=θ时保持连续和平滑,变量θ作为阈值实现线性和非线性部分的转换。
3 实验
3.1 数据集
为了对提出的方法进行验证,在大型公开COCO数据集上进行训练和测试。COCO 数据集由微软团队发布,目前COCO keypoint track 是人体关键点检测的权威公开数据集之一,包含超过20 万张图像和25 万个标记有17 个关键点的实例。COCO 数据集中把人体关键点表示为17 个关节,分别是鼻子、左右眼、左右耳、左右肩、左右肘、左右腕、左右臀、左右膝、左右脚踝[17-18]。
3.2 评价准则
在关键点检测任务中一般用OKS(Object Keypoint Similarity)来表示预测关键点与真实关键点的相似程度,其值域在0~1,越靠近1 表示相似度越高,OKS 越大,表示检测关键点的空间位置越准确[17]。
评价指标:
式中:i为第i个关键点;vi为第i个关键点的可见性,vi=0为在图像外无法标注的点,vi=1为标注了但是被遮挡的点,vi=2 为标注了并且可见的点;对于δ(x),当x为True 时值为1,x为False 时值为0,di为检测的关键点与数据集中标注的关键点之间的欧氏距离;s为目标的尺度因子,值为目标面积的平方根,这里的面积指的是分割面积;ki为用来控制关键点类别i的衰减常数。
一般用平均精度(Average Precision,AP)来评价实验结果的准确性,在COCO数据集的实验结果中,主要关注AP 这个指标,AP 的数据结果通过OKS 计算得出,对于单人姿态估计中的AP,计算方式为:
对于多人姿态估计而言,由于1张图片中有M个目标,假设总共预测出N个个体,那么ground truth 和预测值之间能构成一个M×N的矩阵,然后将每一行的最大值作为该目标的OKS,则:
式中:AP 为所有图片的OKS 大于阈值T的百分比,T由人为给定,在本实验中AP 是指OKS=0.50,0.55,…,0.90,0.95时10个阈值之间所有检测关键点准确率的平均值,AP50是在OKS=0.50时的检测关键点的准确率,AP75 是在OKS=0.75 时的检测关键点的准确率;APM 为中尺寸物体检测关键点的准确率,APL 为大尺寸物体检测关键点的准确率。
3.3 实验结果
普通场景下的人体姿态估计效果见图8。

图8 普通场景效果图
真实地铁场景下的人体姿态估计见图9。

图9 地铁场景效果图
在真实的地铁场景行人检测实验中,在遮挡严重情况下,依然能够得到较好的检测效果,因此该网络适用于在地铁等人流量密集、遮挡严重的场景下进行行人检测任务。不同网络模型在COCO数据集上的结果对比见表1。
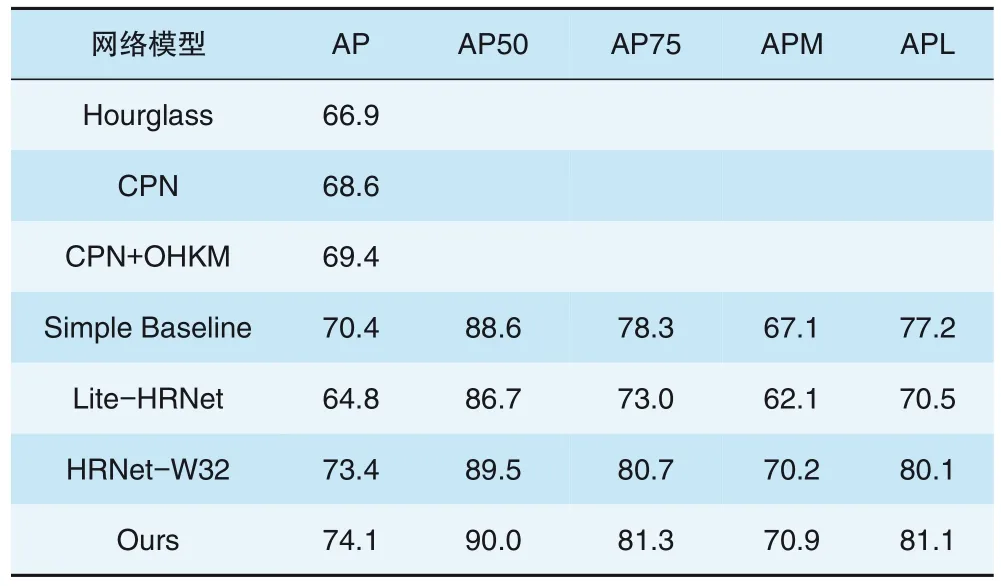
表1 不同网络模型在COCO数据集上的结果对比
由实验结果可知,本次研究提出的方法精度比原HRNet网络提升了0.7%,达到了74.1%,与当下流行的人体姿态估计网络相比,如Hourglass、CPN、CPN+OHKM、Simple Baseline、Lite-HRNet、HRNet-W32,研究所使用的网络在预测关键点的平均精度上分别提升了7.2、5.5、4.7、3.7、9.3、0.7个百分点,且对比表中所示的所有指标,网络模型平均精度均高于其他网络模型的平均精度。因此,改进后的网络模型在人体姿态估计过程中,精确度更高、具有更好的鲁棒性,证明本研究提出方法的有效性。
4 结束语
基于高分辨率网络HRNet 对人体姿势识别进行研究,在网络中添加了注意力机制模块CBAM,该模块将空间和通道2 个维度进行结合,极大提高了网络的性能,提升了重要特征的权重。使用Adaptive wing loss 作为损失函数,当误差很大时,损失函数具有恒定的影响,但当误差较小时,会减少在训练时对背景像素的关注,稳定训练过程。实验结果证明,改进后的网络模型能够准确的检测出尺度较小和遮挡的关键点,具有较好的检测能力和鲁棒性,因此,在地铁实际情况中能够更好应对人群密集、遮挡严重的问题。
