企业轻量化大数据架构研究
2023-09-07李军
李军
关键词: 轻量化大数据架构 MPP 数据库 数据任务调度 数据接入
中图分类号: TP392 文献标识码: A 文章编号: 1672-3791(2023)15-0062-04
1 常用大数据架构
与传统数据分析一样,大数据信息时代首先要考虑的就是数据存储问题[1],其次是数据的计算问题。在Hadoop 生态中,包含数十种大数据存储和计算相关组件,如HDFS、Yarn、Hive、HBase、Presto、Azkaban、Spark、Flink、Flume 等。在不同业务场景中,通过不同组件的组合来满足多样的需求。在Hadoop 生态大数据架构中,常见的架构有如下几种。
1.1 离线计算架构
应用Hadoop(HDFS、YARN、MapReduce、Hive 等)的存储和计算能力来替代传统的BI 组件,实现大数据的ETL 批处理计算。该架构的优点是能够处理海量的大数据,支持数据重播和历史统计,缺点是缺乏实时的支撑。
1.2 流式架构
通过流式计算(Spark、Flink 等)实时对数据流进行分析。此架构的优点是数据的实效性非常高,缺点是对于数据的重播和历史统计无法很好的支撑。
1.3 Lamda架构
实时和离线分别处理,最后统一对外提供服务,但在使用过程中,需要维护两套代码[2]。此架构的优点是能够同时满足实时计算和离线计算的需求,缺点是架构复杂,开发周期长,可能出现实时与批量计算结果不一致等问题。
1.4 Kappa 架构
改进流计算系统来解决数据全量处理的问题,使实时计算和批处理过程使用同一套代码。Kappa 架构,解决了代码维护和一致性问题,但是在kafka 里进行各种逻辑计算,逻辑越来越复杂,有数据不一致的问题[2]。
1.5 Unifield 架构
对Lamda 进行了改造,將机器学习和数据处理揉为一体。该架构的优点是提供了一套数据分析和机器学习结合的架构方案,缺点是实施复杂度较高。
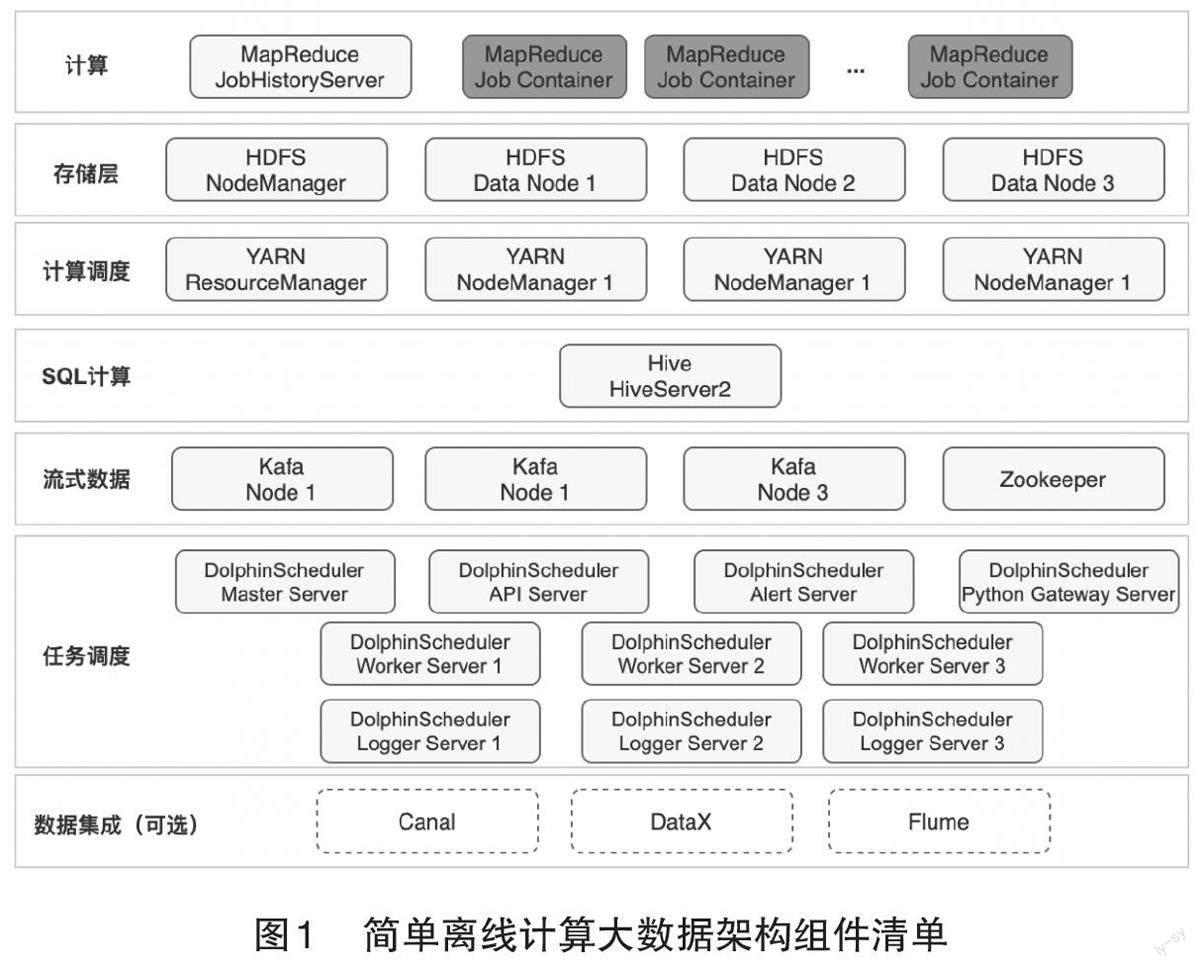
以上几种大数据架构,虽然在不同程度能够满足实时计算和离线计算的需求,但是其架构都有一定的复杂性。以上述5 种架构中最简单的离线计算架构为例,部署一个简单的离线计算架构的大数据环境至少需要部署24 个Java 组件节点,如图1 所示。按照平均一个节点需4 G 内存计算,则至少需要96 G 内存。由于Hadoop 生态的大数据架构比较耗费资源,且架构复杂,导致实施Hadoop 大数据架构的人力、财力成本较高,很多中小型的项目因此弃用Hadoop 大数据技术。
2 轻量化大数据架构特性
大部分企业应用中的大数据容量规模在1 TB~10 PB之间。对于这些容量规模不大的大数据应用,应用Hadoop架构比较耗费资源,且在实时计算业务场景中需要较大开发工作量。因此,轻量化的大数据架构,在中小型项目中有较大需求。
为满足企业应用中大部分的大数据需求,本文研究的轻量化大数据组件主要满足以下特性:(1)部署的组件尽量少,组件占用资源尽量低;(2)支持可配置的数据接入;(3)支持可配置的ETL 计算;(4)支持准实时计算;(5)支持秒级DWD、DWS 层数据查询;(6)支持TB 级到10 PB 级别的数据存储和计算。
3 轻量化大数据架构实现方案
3.1 概述
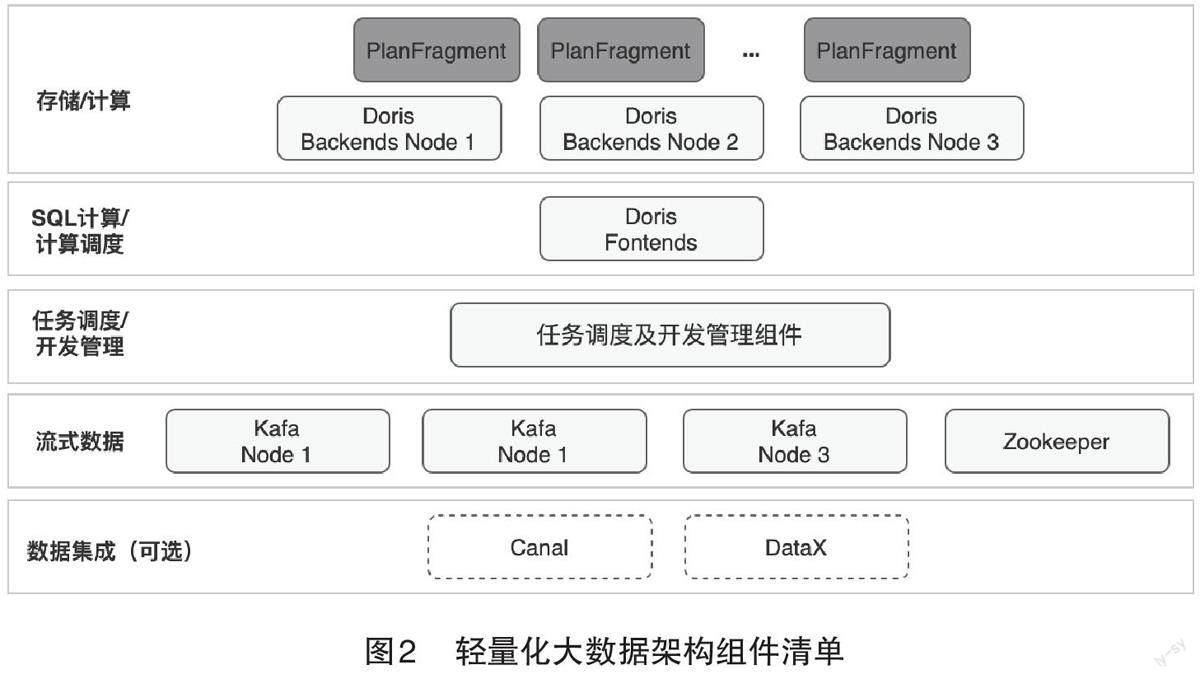
在满足企业大数据需求的同时,主要从部署架构轻量化、开发架构轻量化两方面来设计企业级轻量化大数据架构。其中,部署架构轻量化是指部署的组件尽量少、占用的CPU、内存等资源尽量低;开发架构轻量化是指通过少量代码开发即可实现企业大数据业务需求。具体实现方案为:首先,在核心的大数据计算和存储层面,采用轻量级的MPP 数据库(Apache Doris)替代Hadoop 技术,满足企业级别TB 级到PB 级别数据到存储及准实时计算能力;其次,设计并研发任务调度和开发管理一体的轻量化组件,实现企业常用大数据开发管理业务。
轻量化大数据架构最低仅需要部署9 个组件节点(其中包括3个C语言开发的组件、6个Java组件),按照平均一个节点4 G 内存计算,则最少需要36 G 内存,具体见图2。对比前面所述的传统简单离线计算架构,轻量化架构可以减少15个组件节点,折合减少60 G内存。
3.2 轻量化存储计算引擎
MPP(—种海量数据实时分析架构)是通过一定的互联网节点连接多个SMP(对称多处理)服务器协同完成工作任务。MPP 数据库将任务并行地分散到多个服务器和节点上,在每个节点计算完成后,将各自的结果汇总在一起从而得到最终结果[3]。ClickHouse 等列式数据库从某种意义上来说,也是一类NoSQL 数据库,但鉴于列式数据库本身的独特性,与MongoDB、Redis 等有很大不同,所以可以视为另外一种单独的解决方案。在很多场景下,比Hadoop、Spark 技术栈具有更高的性能更小的系统资源开销[4]。对于新型数仓中实时性要求高的统计分析业务中,使用MPP 存储通常较为合理[5]。因此,在存储计算层,采用轻量的MPP 数据库替代Hadoop。目前,主流的MPP 数据库有Apache Doris、ClickHouse、Greenplum 等。由于Apache Doris 使用更简单、运维更简单、分布式更强、SQL 支持更好、国内技术支持更好,因此选用Apache Doris 来搭建轻量化大数据架构。
Apache Doris 数据库和Hadoop 技术对比,存在以下优势:(1)Doris 所需部署的组件数量更低,占用CPU内存资源更少;(2)Doris 数据库核心的Backends 组件采用C 语言开发,运行性能更好,占用内存更低;(3)Doris 数据库的结构化数据批量写入性能更好,支持200~300 MB/s 的结构化数据批量写入(在Hadoop 生态中结构化数据的实时写入和在线分析需要引入Hbase、Hive、Presto 等组件,部署架构比较复杂,耗费CPU、内存资源也更多);(4)Doris 数据库原生为数据分析设计的Aggregate、Uniq、Duplicate 等模型,能很好的支撑企业应用中的数据分析场景;(5)Doris 数据库在大数据量、多表join、聚合查询等场景下的性能优于Hadoop 生态中的组件;(6)Doris 数据库原生对Kafka 数据导入、Mysql 数据库同步等支持较好,不需要部署额外组件即可实现常用的数据集成工作;(7)Doris 数据库处理结构化数据优于Hadoop,企业应用中大部分数据也为结构化数据,因此Doris 更适合企业应用中大部分的结构化数据需求;(8)大部分企业应用的数据量在PB 级别以内,Doris 数据库能够较好地支撑10 PB 内的数据分析。
3.3 轻量化任务调度及开发管理组件
数据管理应主要包含数据导入、数据清洗和数据治理3 个方面[6]。一体化轻量管理组件将大数据分析中常用的数据管理功能(如任务调度、库表管理、SQL开发、Kafka 数据接入、关系数据库接入等)整合到一起,实现单应用、单进程轻量化部署与应用。一体化轻量管理组件的主要功能如下。
(1)任务调度。任务调度组件支持SQL 计算任务调度即可满足大部分的企业应用需求,且大部分企业应用中的调度任务较少,因此调度组件的摒弃DolphinScheduler、Azkaban 等较重的架构,开发单应用架构的轻量化任务调度组件。
(2)库表管理。开发Doris 数据库的库/表元数据管理、数据预览功能。
(3)SQL 开发。支撑在线的Doris sql 编辑、执行、结果显示等功能。
(4)Kafka 数据接入。支撑在线的Doris RoutineLoad 配置、管理、监控等功能。
(5)关系数据库接入。支持在线的Doris Sync Job配置、管理、监控等功能。
3.4 总体架构
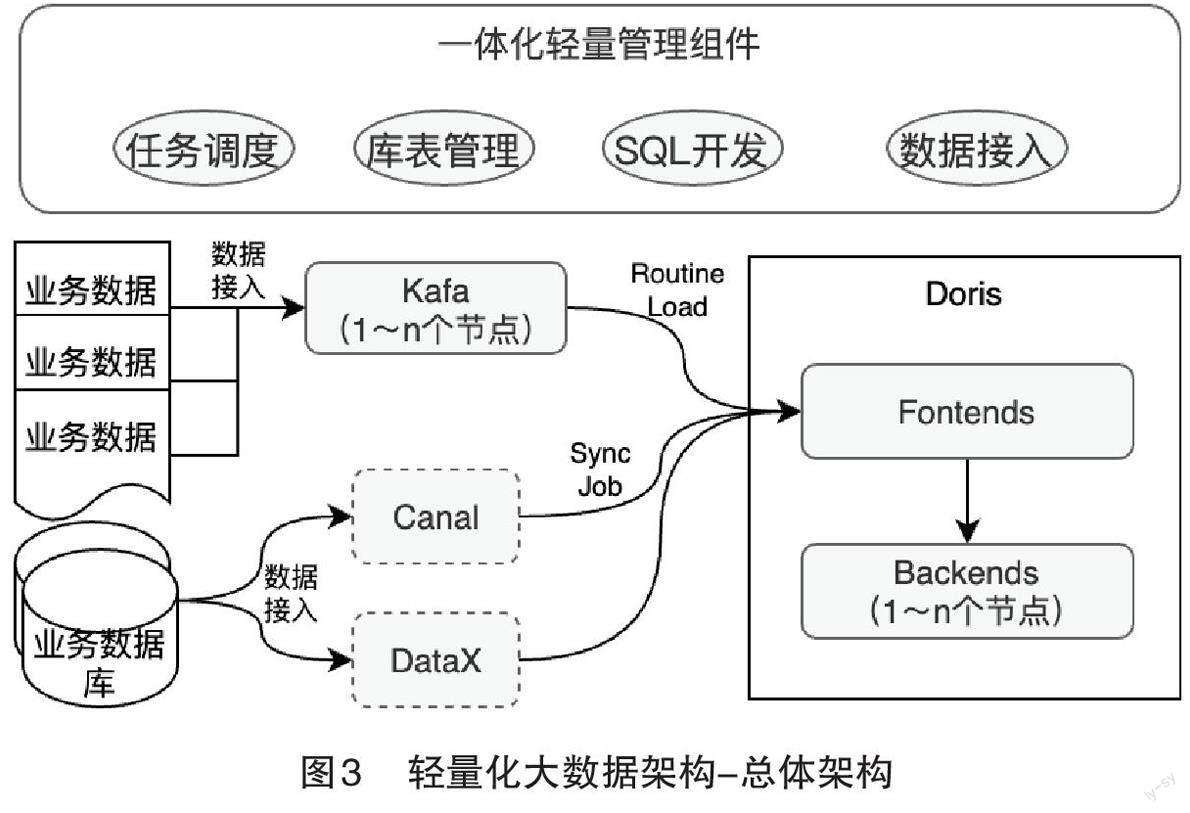
轻量化大數据架构支持多种类型的业务数据接入,包括mysql 业务数据库、其他非数据库中的业务数据。对于数据库中的业务数据,可以借助Canal、DataX等组件实时或定时接入Doris 存储;对于非数据库中的业务数据,可以接入Kafa 中,再借助Doris Routine Load技术实时存储到Doris。一体化轻量管理组件负责为开发人员提供便捷的任务调度、库表管理、SQL 开发、数据接入等常用服务。总体架构如图3 所示。
4 应用场景分析
4.1 适用场景
本文所述对轻量化大数据架构适用于以下场景:(1)对结构化或半结构化的数据做大数据分析,数据量规模在1 TB 到10 PB 范围;(2)准实时计算或离线计算的业务场景;(3)结构化或半结构化数据写入和查询性能要求较高的业务场景;(4)ETL 计算不是特别复杂的业务场景(即能够通过SQL 计算,且单次数据计算规模为GB 级别)。
4.2 不适用场景
本文所述对轻量化大数据组件在以下场景中不太适用:(1)实时性要求比较高的复杂业务场景;(2)数据量超过10 PB 以上等业务场景;(3)非结构化数据分析的业务场景;(4)ELT 计算数量很大的业务场景。
4.3 应用场景扩展
应用此轻量化大数据架构,能够满足企业大部分大数据存储、计算需求。对一些特殊等需求,可以在此架构基础上扩展。
(1)对于实时性要求高的复杂业务场景,如秒级别带滑动窗口的大数据实时计算,需要额外引入flink 等实时计算组件。
(2)对于总数据量10 PB 以上或单次ETL 计算数据量很大业务场景,需要引入Hadoop 的HDFS 和Hive等组件。
(3)对于人工智能场景,需要额外引入TensorFlow等AI 计算组件。
4.4 最佳实践
(1)如果原始数据比较大,可以在数据架构设计中删除或缩减原始数据的存储,Doris 中仅存储计算结果数据,避免存储规模过大。
(2)对于单次ETL 数据量较大的场景,可以把大量数据的计算拆分成多个中小规模数据量的计算,来实现计算大数据量的需求。
(3)对于任务量较多的ETL 离线计算,尽量把不同批次的计算任务拆分到不同时间段执行。避免同一时间段执行段任务太多,导致Doris 内存溢出。
5 结语
在企业应用中,大部分是结构化或半结构化的数据做分析,数据规模基本都在10 PB 范围内,因此实施轻量化的大数据组件能满足企业大部分的准实时和离线计算业务场景。如果企业数据规模在10 PB 范围内,实施轻量化大数据架构能帮忙企业减少40%~60%的系统资源,同时基于一体化轻量组件和Doris 易用的Routine Load、Sync job 等功能,帮助企业快速实现大数据业务的开发,减少企业人力、财力成本。