基于机器学习算法的干旱区绿洲地上生物量估算
2023-09-06王雪梅杨雪峰赵枫安柏耸黄晓宇
王雪梅,杨雪峰,赵枫,安柏耸,黄晓宇
1. 新疆师范大学地理科学与旅游学院,新疆 乌鲁木齐 830054;2. 新疆干旱区湖泊环境与资源实验室,新疆 乌鲁木齐 830054
植被地上生物量(aboveground biomass,AGB)是陆地生态系统生产力的重要体现,对陆地生态系统的构成和功能具有重要作用(陶冶等,2013)。研究植被地上生物量的传统方法主要有直接收获法、平均生物量法以及生物量经验模型等基于样地的清查方法。直接收获法操作简单,精度较高,但工作量较大,耗时费力,且会对样地内的植被及其生境造成一定程度的破坏,故常用于小区域尺度的草地和农作物生物量的精准估算(Byrne et al.,2011;党晓宏等,2017)。平均生物量法则以区域内典型样地的单位面积平均生物量为基础,结合区域面积对植被生物量进行估算,常用于植被分布较为均一的草地、人工林地、灌草植被以及枯落物生物量的测定(方精云,2000;姚雪玲等,2019;童新风等,2018)。在生物量经验模型中,异速生长模型应用最为广泛,可通过测定标准株的胸径、树高、冠幅等各生态因子估算其地上生物量,并根据不同植被根茎比推算其地下生物量(杨宪龙等,2016;Khan et al.,2022)。在生物量经验模型的基础上,生物量过程模型逐渐发展起来。作为可解释植物生态过程的机理模型,生物量过程模型通过复杂的数学模型对植物的光合作用、呼吸作用和蒸散发等关键生理过程中的物质能量流动进行模拟,常用于大尺度植被生物量的估算(薛海连等,2021)。
随着对地观测技术与研究手段的不断发展,基于多源数据借助机器学习算法和机理过程模型估算植被地上生物量已成为植被碳储量研究的发展趋势(Sun et al.,2020;Cohen et al.,2021)。与传统的统计回归方法相比,支持向量机(Support Vector Machine,SVM)、反向传播神经网络(Back Propagation Neural Network,BPNN)、极端梯度提升(eXtreme Gradient Boosting,XGBoost)以及随机森林(Random Forest,RF)等机器学习算法在处理大尺度、多源遥感数据方面具有显著优势,已逐渐用于森林、草地和农作物生物量的估算(Nesha et al.,2020;Morais et al.,2021;Wang et al.,2022)。丁家祺等(2021)通过从 Landsat-8、ALOS PALSAR-2 和Sentinel-1 数据中提取光谱信息,结合地形因子构建了多元线性回归(Multiple linear regression,MLR)、RF 和SVM 模型,对湖南西北部森林地上生物量进行估测,研究发现RF 模型相较于MLR 与SVM 模型具有更好的估测能力。Huang et al.(2016)利用光学图像和合成孔径雷达图像对杭州西溪湿地公园的地上生物量进行估测,通过比较曲线估计、MLR 和BPNN 模型的精度指标,发现BPNN 模型的精度最高。邢晓语等(2021)利用高分一号卫星影像和野外调查数据对内蒙古锡林郭勒盟草原地上生物量进行遥感估算,进一步证实RF 算法能够较好地解决生物量建模中的多元共线性问题,比MLR 和SVM 模型具有更好的适用性。张亦然等(2021)通过采集牧草冠层光谱反射率构建植被指数,利用MLR 和RF 以及XGBoost算法构建草甸地上生物量估算模型,研究发现RF与XGBoost 算法在估算草地生物量方面具有较好的效果。综上分析发现,以往的研究多侧重于单一植被类型的地上生物量估算,而对复杂地表多种植被地上生物量的反演相对较少。目前在干旱区绿洲地上生物量的估算主要集中在荒漠植被,且多以统计模型为主(张华等,2020;Zhou et al.,2023)。同时,已有研究还发现,合适的变量组合以及机器学习算法对准确估测复杂地表的植被地上生物量具有重要作用( Wongchai et al. , 2022 ;Tappayuthpijarn et al.,2022)。基于此,以新疆渭干河-库车河三角洲绿洲2019 年7 月不同植被类型地上生物量野外调查数据与同时期Landsat 8 OLI遥感影像为数据源,通过多种变量组合与机器学习算法构建干旱区绿洲地上生物量最佳估测模型,对植被地上生物量的空间分布格局进行定量反演,以期为绿洲生态系统生产力评价与碳储量的准确估算提供依据。
1 材料与方法
1.1 野外调查与样品采集
渭干河-库车河三角洲绿洲位于新疆维吾尔自治区南部,塔里木盆地北缘,中天山南麓,为典型的冲洪积扇形平原绿洲。气候特点为夏季干热、冬季干冷,降水稀少、蒸发强烈,多年平均气温为11.6 ℃,多年平均降水量为52 mm,多年平均蒸发量在2 000 mm 以上,为典型温带大陆性干旱气候。该绿洲的主要农作物为棉花(Gossypium spp.)和玉米(Zea mays),经济作物有红枣(Ziziphus zizyphus)、核桃(Juglans regiaL.)等;荒漠植被主要包括胡杨(Populus euphratica) 、 柽柳(Tamarix ramosissima)、盐节木(Herculaneum strobilaceum)和盐穗木(Halostachys caspica),以及芦苇(Phragmites australis)、骆驼刺(Alhagi sparsifdia)和白刺(Nitraria tangutorumBobr)等(张殿岱等,2021)。该绿洲土壤类型较为多样,其中潮土、灌淤土和棕漠土分布十分广泛,而沼泽土和盐土也有一定的空间分布。
2019 年7 月13-24 日在渭干河-库车河三角洲绿洲开展了为期12 d 的地上生物量调查工作,共调查50 m×50 m 大小的样地94 个,其中农田植被样地63 个,荒漠植被样地31 个,调查样地分布如图1 所示。在调查样地内设置样方进行植被调查,农田植被样方大小为50 m×50 m;在荒漠植被样地内,调查50 m×50 m 乔灌草样方1 个,10 m×10 m 灌草样方3 个以及1 m×1 m 的草本样方5 个。主要调查植被物种的类型、频数、植被盖度、高度、冠幅等生长参数;同时,选择不同物种的标准株测量其株高、长短轴冠幅和基径,以及进行标准直立枝或整株的采样。在生物量测定过程中,将采集的标准枝/株样本的各器官进行现场分离,用电子天平称其质量后分别装入写好标签的牛皮纸袋中,为确保测定结果的准确性,天平秤的精确度为0.1 g。在室内80 ℃恒温干燥箱内经24 h 烘干处理后测定其干物质的质量。乔灌木地上生物量通过所采的标准枝生物量采用间接估算法进行整株生物量估算;矮小的草本和农作物可采用直接收获法获取整个标准株的生物量。依据样方内各物种的频数、植被盖度等生长参数以及标准株的生物量推算出各样地的植被地上生物量。在取样的同时还需进行立地条件调查,记录地表环境信息和每个样地中心点经纬度并进行景观拍照。
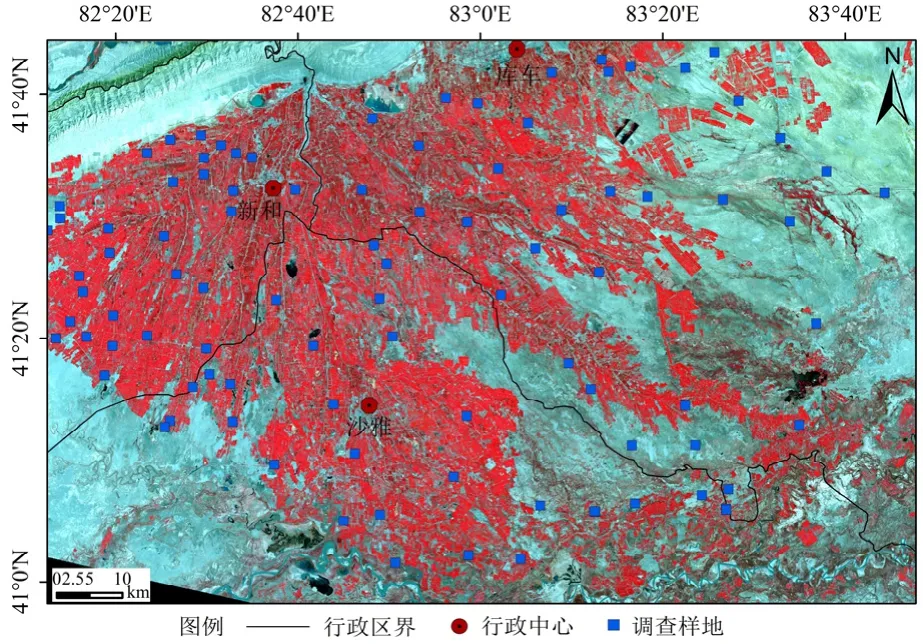
图1 研究区调查样地分布示意图Figure 1 Distribution map of survey sample plots in the study area
1.2 光谱因子的选择与植被指数的计算
选择与野外调查同时期的2019 年7 月26 日Landsat 8 OLI 遥感影像进行辐射定标和大气校正。首先打开原始影像头文件,采用辐射定标工具选择多光谱数据,设置输出格式为BIL,数据类型为Float,转换系数为0.1,即可输出辐射定标文件。打开大气校正工具导入辐射定标数据,选择传感器类型并输入研究区平均高程,然后确定大气模型为中纬度夏季(MLS),气溶胶模型选择乡村(Rural),设置多光谱参数为660:2 100 nm,完成影像校正后进行裁剪等预处理。为保证实地调查数据与遥感影像空间上完全匹配,需要将遥感影像重采样为50m的空间分辨率。通过提取Landsat 8 OLI 影像的海岸波段(b1)、蓝光波段(b2)、绿光波段(b3)、红光波段(b4)、近红外波段(b5),以及短波红外1 波段(b6)和短波红外2 波段(b7)的反射率,并计算各波段反射率的倒数。同时选取与地上生物量密切相关的7 个植被指数,分别是归一化差值植被指数(Normalized Difference Vegetation Index,NDVI)、差值植被指数(Difference Vegetation Index,DVI)、比值植被指数(Ratio Vegetation Index,RVI)、增强型植被指数(Enhanced Vegetation Index,EVI)、大气阻抗植被指数(Atmospherically Resistant Vegetation Index,ARVI),以及土壤调整植被指数(Soil Adjusted Vegetation Index,SAVI)和修正土壤调整植被指数(Modified Soil-Adjusted Vegetation Index,MSAVI)。各植被指数的计算公式如下(Kaufman et al.,1992;Qi et al.,1994;Gitelson et al.,1996):
式中:
INDVI——归一化差值植被指数;
IDVI——差值植被指数;
IRVI——比值植被指数;
IEVI——增强型植被指数;
IARVI——大气阻抗植被指数;
ISAVI——土壤调整植被指数;
IMSAVI——修正土壤调整植被指数;
b2——蓝光波段的反射率;
b4——红光波段的反射率;
b5——近红外波段的反射率;
L——土壤调节系数,研究中取值为0.5。
1.3 地上生物量估测模型
研究中选择SVM、BPNN、XGBoost 和RF 这4 种机器学习算法进行植被地上生物量估测模型的构建。模型的参数设置以及拟合过程可通过R 语言编程实现,使用R Studio 中的R 包e1071、nnet、xgboost 和randomForest 算法完成模型的训练和验证。SVM 是一种基于统计学习理论的机器学习算法,包含线性、非线性和径向基函数等不同类型的核函数,可用于分类和回归问题。通过核函数,支持向量机可以转化为非线性模型。本研究以径向基函数为核函数,通过反复训练和调试Cost、Epsilon和Gamma 这3 个参数最终确定最优结果。
BPNN 是一个多层渐进式神经网络,由输入、隐藏和输出3 层构成。输入层主要负责向量的输入,经由神经元传输到隐藏层,确定合适的隐藏层及其神经元的数量,最后通过神经元传输到输出层与真实值进行比较。通过不断调整神经元之间的权值进行反复学习,直到满足输出条件。该算法具有很强的非线性处理能力以及自适应学习能力,抗噪声能力强,能快速建立输入与输出之间的映射关系,可用于模拟人脑学习,建立多元非线性关系。本研究中BPNN 算法模型的隐含层设定为15,迭代次数为1 500,权重衰减分别为3 和5,通过反复训练该模型以获得最佳效果。
XGBoost 是一种集成学习算法,属于梯度提升树算法类别,其基本思想是让新的基模型去拟合前一模型的偏差,从而不断降低加法模型的偏差(Si et al.,2020;Ching et al.,2022)。通过调整XGBoost训练集的步长(learning_rate)、最小损失函数下降值(gamma)和树的最大深度(max_depth)等关键参数,以达到优化模型的目的。
RF 作为集成学习思想下的产物,使用Bootstrap重采样技术从原始训练集中随机采样m个样本,共进行n次采样,生成n个训练集,形成可用于构建目标变量和建模因子之间关系的随机森林。该算法具有极高的准确率、很好的抗噪声能力,以及不容易过拟合、训练速度快等优点,是目前应用最为广泛的机器学习算法之一。研究中通过指定CART 决策树的数目n进行反复训练,从而寻找估测模型的最优参数mtry。
1.4 模型精度评价
机器学习模型的估测精度和预测能力可通过决定系数(R2)、平均绝对误差(σMAE)、均方根误差(σRMSE)和相对分析误差(σRPD)反映(Ghosh et al.,2020)。其中R2越大,表明模型的拟合程度越高;σMAE和σRMSE值越小,则显示该模型估测效果越好,精度越高;σRPD代表了模型的估测能力和稳定性,当1.4≤σRPD<1.8 时表明该模型估测能力一般;1.8≤σRPD<2 表示模型的估测能力较好;σRPD≥2则说明该模型的估测能力极好,稳定性高。各评价指标的计算公式如下:
式中:
yi——调查样地生物量的实测值(g·m−2);
——生物量估测模型的估测值(g·m−2);
——调查样地生物量的平均值(g·m−2);
σSD——为调查样地生物量的标准差;
n——调查样地的数量。
1.5 数据分析
通过对各调查样地植被地上生物量进行统计整理和数据运算,结合影像数据提取的各建模变量,采用R 语言的4 种机器学习算法构建研究区植被地上生物量的估测模型;通过分析不同建模方法下研究区植被地上生物量的估测精度,最终确定出地上生物量的最佳估测模型,并采用ArcGIS 10.2软件绘制研究区植被地上生物量的空间反演图。
2 结果与分析
2.1 地上生物量的特征统计
通过对研究区各样地植被地上生物量进行基本统计分析(表1),发现研究区94 个调查样地的地上生物量(AGB)在7.4-1 448.5 g·m−2范围内变化,平均水平为387.9 g·m−2,标准差为319.4 g·m−2,变异系数为82.3%,地上生物量整体水平偏低,具有中等程度的空间异质性。将调查的94 个样本数据随机分成64 个训练样本和30 个验证样本,分别用于模型的训练和验证。统计训练样本和验证样本的地上生物量发现,两种样本集的平均水平均较低,分别为402.9 g·m−2和355.8 g·m−2;变异系数分别为81.7%和84.5%,呈中等强度的空间变异。
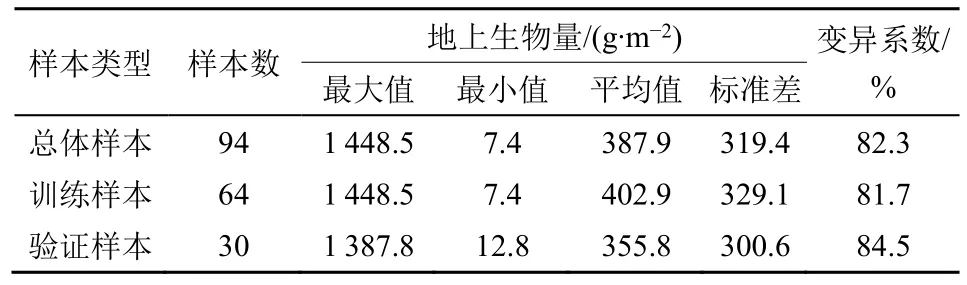
表1 各样地地上生物量的基本统计特征Table 1 Basic statistical characteristics of aboveground biomass in various sites
2.2 建模变量的选择
根据各调查样地中心点的地理坐标,在遥感影像上提取出各坐标点的波段反射率值以及波段运算得到的光谱指数,分别与调查样地实测生物量进行相关分析(见图2)。通过相关显著性检验(P<0.001),初步筛选出与研究区植被地上生物量存在极显著相关的7 个植被指数和13 个光谱波段共20 个光谱因子,作为本研究中植被地上生物量估测模型的建模变量。其中与地上生物量相关最为密切的植被指数为比值植被指数(RVI),相关系数为0.77(P<0.001);在各波段反射率中,与地上生物量相关最密切的是红光波段的倒数(1/b4),相关系数达到0.81(P<0.001)。将7 个植被指数与13 个波段作为全变量(Total Variable,TV),7 个植被指数为指数变量(Index Variable,IV),13 个光谱波段为波段变量(Band Variable,BV),同时对全变量采用随机蛙跳算法筛选出5 个植被指数(DVI、EVI、ARVI、SAVI 和MSAVI)与5 个光谱波段(1/b2、1/b3、1/b4、1/b5和1/b6)作为优选变量(Preferred Variable,PV),分别以这4 种变量组合作为建模变量进行生物量估算模型的构建,从而筛选最佳估测模型对研究区的地上生物量进行空间反演。
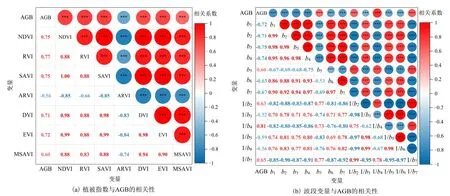
图2 建模变量与地上生物量的相关系数矩阵Figure 2 Correlation coefficient matrix between modeling variables and aboveground biomass
2.3 地上生物量反演模型的构建与验证
基于SVM、BPNN、XGBoost 和RF 这4 种机器学习算法,以全变量(TV)、指数变量(IV)、波段变量(BV)和优选变量(PV)这4 种变量组合作为建模变量,各调查样地的地上生物量为因变量,构建渭干河-库车河三角洲绿洲地上生物量的估测模型,具体估算精度如表2 所示。在SVM 模型中,4 种变量组合构建的反演模型估测效果均较好,模型的训练集和验证集R2均大于0.6,σRPD值在1.6 以上,反演模型具有较好的估测能力。进一步分析比较发现,全变量(TV)和波段变量(BV)构建的SVM 模型估测效果优于指数变量(IV)和优选变量(PV)。其中,BV-SVM 模型的估测能力最佳,验证集的σRPD达到1.70,σMAE和σRMSE分别为88.1 g·m−2和149.1 g·m−2,估测精度较其他3 种变量组合更高。相较于SVM 模型,BPNN 模型具有更好的训练结果,训练集的σRPD均在2.0 以上,但模型整体验证效果较差,稳定性低。在4 种组合变量构建的BPNN 模型中,由优选变量构建的PV-BPNN 模型相较于其他3 种组合变量具有较高的估测能力,验证集R2为0.617,σMAE和σRMSE分别为98.3 g·m−2和155.4 g·m−2,σRPD为1.63。在XGBoost 模型中,4 种变量组合构建的反演模型均具有较好的估测能力,其中BV 和PV 组合模型的估测效果明显优于全变量(TV)和指数变量(IV)模型,且以优选变量构建的PV-XGBoost 模型的验证效果最佳,R2为0.719,σMAE和σRMSE分别为100.0 g·m−2和133.0 g·m−2,σRPD达到1.91。RF 模型作为一种先进的机器学习算法,与其他3 种模型相比,估测能力有了明显的提高,4 种变量组合模型的训练集和验证集的σRPD均在1.8 以上,模型的估测能力较高,稳定性强。进一步比较不同变量组合估测结果认为,BV 和PV 组合构建的RF 模型的估测能力明显优于TV 和IV 组合;与PV-RF 模型相比,BV-RF 模型的训练集和验证集的σRMSE降低了2.3 g·m−2和1.3 g·m−2,σRPD分别由3.07、1.90 提高至3.14 和1.92,模型的估测精度更高,预测能力和稳定性更强。
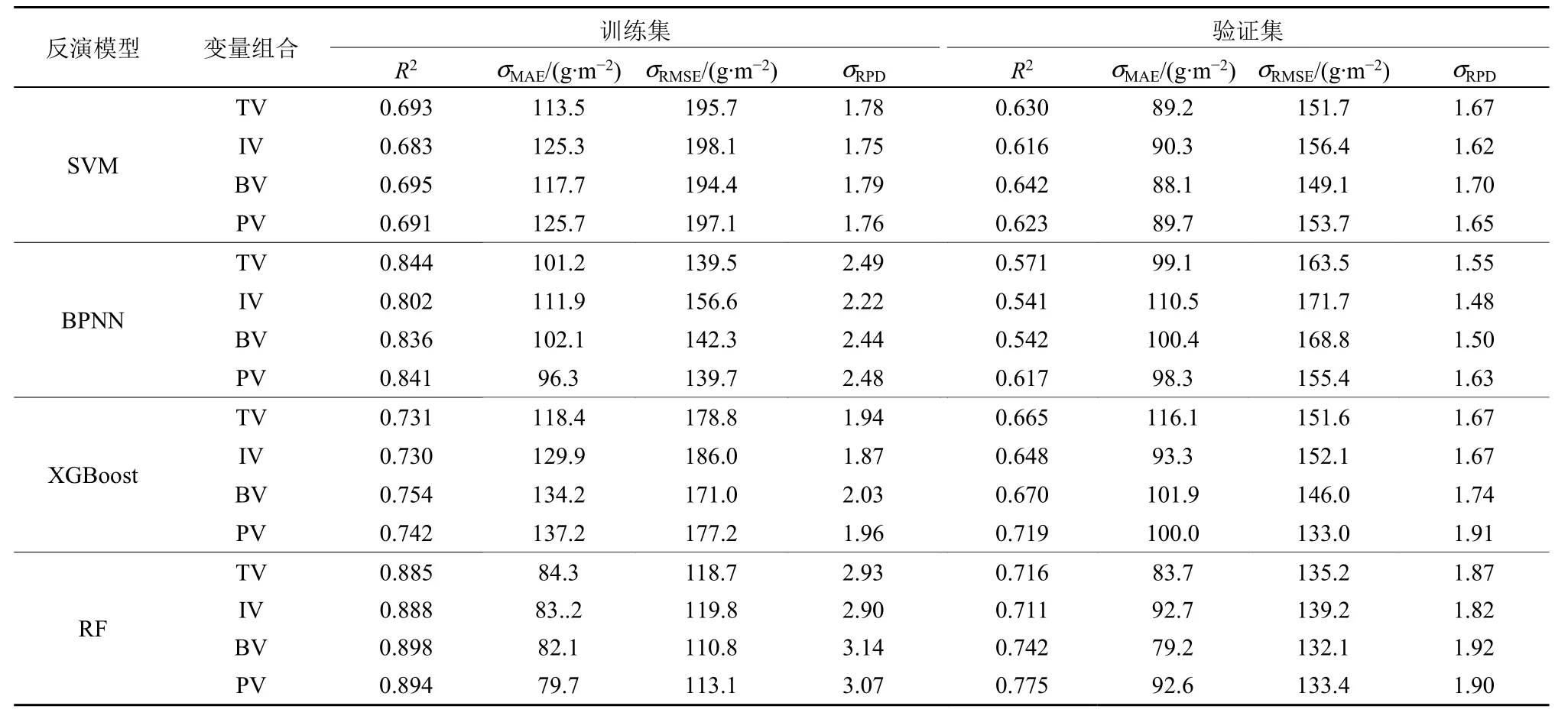
表2 不同反演模型的估算精度Table 2 Estimation accuracy of different inversion models
综合分析4 种变量组合的建模效果认为,在BPNN 和XGBoost 模型中,通过随机蛙跳筛选变量可以有效提高建模精度。估测精度最高的是PV 组合,其次是BV 和TV 组合,而IV 组合的估测精度最低。而在SVM 和RF 模型中,BV 组合构建的模型精度略高于其他3 种组合。进一步比较4 种机器学习算法构建的地上生物量估测模型发现,RF 算法明显优于SVM、BPNN 和XGBoost;相较于BPNN算法模型,SVM 和XGBoost 算法构建的模型估测能力更为稳定。综合分析认为,由波段变量构建的随机森林模型BV-RF 具有最佳的估测精度和稳定性,其验证集R2为0.742,σMAE和σRMSE分别为79.2 g·m−2和132.1 g·m−2,σRPD为1.92。为了进一步比较不同机器学习算法估算结果的准确性,分别对4种机器学习模型的最佳估测结果绘制散点图(图3),分析发现4 种算法模型的估测结果与实测值均表现出较为一致的拟合性,大多数散点在1:1 线附近集中分布;其中BV-RF 模型的估测值与实测值更为接近,估测结果能更准确反映研究区植被生长的实际状况,可作为研究区植被地上生物量的最佳估测模型。
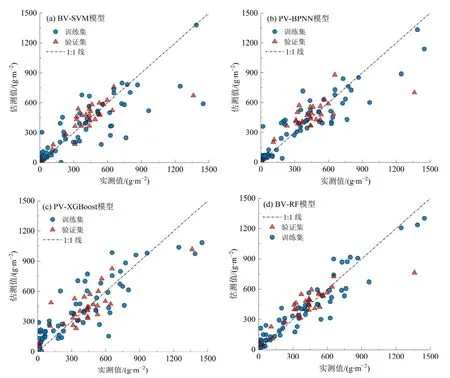
图3 4 种机器学习算法构建的最优估测模型散点图Figure 3 Scatter diagram of optimal estimation models constructed by four machine learning algorithms
2.4 地上生物量的空间反演
以最佳估测模型BV-RF 模型的训练结果为基础,采用R 语言对研究区植被地上生物量进行定量反演。利用归一化差值水体指数(Normalized Difference Vegetation Index,NDWI)提取水体并结合反演结果绘制研究区植被地上生物量空间分布图。由地上生物量空间反演图可以看出(见图4),渭干河-库车河三角洲绿洲的地上生物量(AGB)呈现出明显的空间分异特征,AGB 整体呈扇形分布,绿洲内部的地上生物量明显高于绿洲外围。以农田为主的绿洲区域约占研究区总面积的44.45%,AGB 在300 g·m−2以上。其中位于塔里木河中游和渭干河下游的南部绿洲和东南区域,由于地势较低,水资源丰富,植被生长状况良好,地上生物量相对较高,AGB 在650-1 500 g·m−2之间变化,地表植被以高产农田和荒漠胡杨林为主;绿洲-荒漠过渡带的地上生物量普遍较低,AGB 主要分布在100-300 g·m−2范围之间,地表以荒漠盐碱草地为主,约占研究区面积的23.29%;而在荒漠区,由于水资源缺乏植被覆盖极为稀疏,且地表主要为沙地和光板盐碱地,AGB 在100 g·m−2以下,可占区域总面积的32.26%。从空间分布格局来看,研究区植被地上生物量整体呈现出绿洲区高,荒漠区低,空间分异十分明显,由绿洲内部向荒漠腹地逐渐递减的变化特征。

图4 研究区植被地上生物量反演图Figure 4 Inversion map of vegetation aboveground biomass in the study area
3 讨论与结论
3.1 讨论
随着机器学习算法和光谱技术的深入发展,植被地上生物量估算方法也在不断改进中,RF、XGBoost 等非参数机器学习算法已成为目前植被地上生物量常用的估算方法。与传统的统计学习模型相比,机器学习模型具有更高的估测精度和更强的稳定性,针对非线性统计关系具有较好的估测效果(Tappayuthpijarn et al.,2022)。在机器学习算法中,SVM 可处理小样本机器学习问题,并利用核函数应对非线性问题,在选择正确的核函数时需要相当的技巧,而在面对较大数据集时,SVM 算法学习效率很低。XGBoost 算法可实现并行处理,训练速度快,能防止模型过拟合,但该算法只适合处理结构化数据,不适合处理超高维特征数据。BPNN 虽具有较强的非线性映射能力和高度自学习自适应能力,但收敛速度慢,局部极小化问题突出。RF 算法可高度并行化训练数据,能够处理高维度数据,训练速度快,泛化能力强,估测精度高且稳定性强(Nesha et al.,2020;Morais et al.,2021)。相较于BPNN算法模型,SVM、XGBoost 与RF 算法构建的模型在本次验证过程中具有更高的预测精度和稳定性。与其他机器学习算法和传统模型相比,RF 算法在地上生物量估算方面具有明显优势(Wang et al.,2022)。本研究结果进一步证实,RF 算法构建的模型,其估算精度和预测能力要明显优于SVM、BPNN 和XGBoost 算法模型。在机器学习过程中,如果样本容量不足,将会导致模型学习效果不佳。研究结果显示,4 种机器学习算法构建的模型相对分析误差均在1.4 以上,说明实验所用的样本数量可达到机器学习算法模型的学习要求,其中RF 模型的预测能力较好,稳定性最强。
相关研究表明,植被地上生物量与气温、降水、地形,以及土壤质地与养分条件有密切关系,其中降水、地形以及土壤养分是影响地上生物量的重要因素,直接决定了植被的碳固持能力(李妙宇等,2021;Yuan et al.,2019)。在今后的地上生物量估算研究中,除了深入挖掘遥感影像的光谱特征和纹理信息外,还需辅助地表环境要素,通过变量筛选结合多种机器学习算法,不断提高反演模型的估测精度和适用范围(Sun et al.,2020)。同时,雷达影像、高光谱卫星数据以及无人机影像等具有高空谱特征的遥感数据,在未来的植被地上生物量反演研究中将会展现出明显优势(Li et al.,2021;Sharma et al.,2022;Wang et al.,2022)。
3.2 结论
以Landsat 8 OLI 多光谱遥感影像和地面实测样方为主要数据源,采用不同变量组合和多种机器学习算法对新疆渭干河-库车河三角洲绿洲地上生物量进行遥感估算。研究发现波段变量(BV)和随机蛙跳算法优选变量(PV)构建的地上生物量反演模型,其估测精度和稳定性明显优于全变量(TV)和指数变量(IV)模型。通过对4 种机器学习算法模型进行比较,认为RF 算法模型较XGBoost、SVM和BPNN 模型具有更高的估测精度和更强的稳定性。由波段变量结合随机森林算法构建的BV-RF模型的估测精度最高,预测能力最强。研究区植被地上生物量的空间反演结果表明,地上生物量存在明显的空间分异特征,主要表现为绿洲内部的地上生物量较高,而绿洲外缘生物量低,呈梯度分布的空间格局。
