基于改进DeepLabV3+算法的遥感影像建筑物变化检测
2023-09-05齐建伟王伟峰王光彦
齐建伟,王伟峰,张 乐,王光彦
(1. 黄河水利职业技术学院,河南 开封 475004; 2. 中科北纬(北京)科技有限公司,北京 100043; 3. 江苏省工程勘测研究院有限责任公司,江苏 扬州 225002)
随着中国城市化进程的不断推进,城市违建等现象频频发生,传统依靠人力执法作业的方式效率低下,已无法满足日益增长的现实需求。根据卫星影像进行执法的任务量与日俱增,近10年来,人工智能技术飞速发展。2012年是深度学习元年,在著名网络结构AlexNet[1]一举拿下当年大规模视觉识别大赛[2]的冠军之后,计算机视觉领域迎来飞速发展,以深度学习(deep learning, DL)及卷积神经网络(convolutional neural network, CNN)为基础的算法取得诸多突破。2014年,全卷积网络(fully convolutional network, FCN)[3]首次成功地将深度学习引入语义分割场景。
本文探索DeepLab系列相关算法[4-5],并针对变化检测场景进行改进,在建筑物变化检测开源数据集上进行效果验证,论证人工智能算法在遥感建筑物变化检测场景下的可行性,为人工智能技术在通过卫星影像执法等场景提供实践经验。
1 算法理论基础
1.1 DeepLab系列算法
DeepLab系列是语义分割领域中最常使用的算法之一,自2014年首篇文章DeepLabV1[6]发表以来,有学者不停地优化改进其结构,DeepLabV2[7]、DeepLabV3[8]和DeepLabV3+[9]等随之出现,并不断地刷新语义分割开源数据集性能指标。
DeepLabV1将空洞卷积[10](dilated convolution)引入语义分割网络,通过加大卷积核的空洞率以增加网络的感受野。DeepLabV2在DeepLabV1的基础上,借鉴SPPNet[11]的网络设计思想,提出空间金字塔下采样结构(atrous spatial pyramid pooling, ASPP)。如图1(a)所示,空间金字塔下采样结构通过不同尺度的空洞卷积增加网络多尺度感受野,较大幅度提升了网络性能。DeepLabV3在DeepLabV2的基础上,改进了空间金字塔下采样结构,如图1(b)所示。

图1 ASPP结构
DeepLabV3+是DeepLab系列中性能最优的算法。DeepLabV3+的网络结构如图2所示,区别于常见的编码器和解码器对称结构,DeepLabV3+采用Xception[12]结构为网络主干,网络结构的主要参数量集中于编码器部分,而解码器仅为两个4倍上采样插值操作。
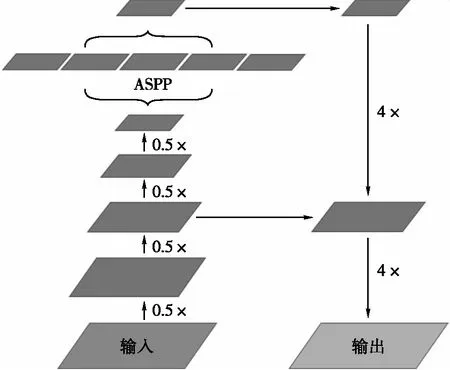
图2 DeepLabV3+网络结构
1.2 损失函数
本文使用Softmax和交叉熵(cross entropy)损失函数。
一般分割网络设计为输出与输入等像素分辨率的预测值,即每个像素均有一个长度为类别数的预测输出。一般使用softmax函数将最后的输出映射为每个类别的概率,公式为
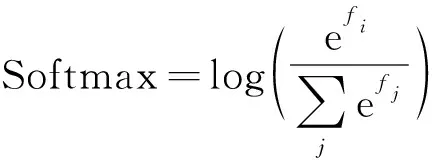
(1)
式中,fj为每个像素的预测向量。
交叉熵损失函数为深度学习领域常用的损失函数,主要用于衡量模型输出与标注样本的接近程度。交叉熵损失越小,说明模型输出与标注样本越相近,模型性能越好。公式为
(2)
1.3 评价指标
建筑物变化检测本质上为基于语义分割的相关算法,该场景一般使用平均交并比(mean intersection over union, mIoU)进行模型评估。
以本场景为例,由于建筑物变化检测为单一类识别,因此平均交并比转换成交并比(intersection over union, IoU)。可以将模型输出分为以下4类。
(1)正确预测的正样本(true positive, TP):表示模型预测为正例,实际是正例。
(2)错误预测的正样本(false positive, FP):表示模型预测为正例,实际是负例。
(3)正确预测的负样本(true negative, TN):表示模型预测为负例,实际是负例。
(4)错误预测的负样本(false negative, FN):表示模型预测为负例,实际是正例。
评价指标交并比可以表示为
(3)
若任务场景为多类别场景,则评价指标将每一类的交并比求均值,即平均交并比为
(4)
式中,N为目标场景类别数,在本文场景中,N=1。
2 DeepLabV3+算法应用及改进
2.1 语义分割算法在变化检测场景中的应用
在计算机视觉领域,语义分割是对输入图像进行像素级分类。通用语义分割任务为“单入单出”,即输入一张图像,输出与图像等分辨率的预测结果。变化检测与语义分割不同,是一种“双入单出”任务,输入为一对等分辨率图像,输出与图像等分辨率的预测结果。
一般如需将语义分割算法直接应用于变化检测场景,需要将两张图像在通道维度合并。如图3(a)所示,以DeepLabV3+网络结构为例,要对一组三通道可见光图像进行变化检测,则需要将这两张三通道可见光图像合并成六通道图像,再输入语义分割网络。

图3 算法结构
这种直接使用语义分割算法的技术方案有很多优点,如不需要较多开发成本,对研发人员要求较低,现有开源方案较多,可以直接使用等。但这种方案的弊端也较为明显,语义分割网络结构本身不是针对变化检测任务设计的,且没有针对变化检测任务特性进行结构调整,在等网络参数量的条件下,无法充分发挥网络性能。
2.2 改进的DeepLabV3+结构
图3(a)对两张图像合并通道,在同一个网络中提取特征,无法充分融合两张图像特征,且容易丢失两张图像各自的特征。
本文以DeepLabV3+结构为主体,提出一种针对变化检测场景的交互孪生网络,如图3(b)所示,该网络的每一层特征不仅与当前网络的前一层特征相关,还与其对应的另一个网络的前一层特征相关。此设计中,两张图像的特征在网络浅层开始交互,使网络的每一层都参与了语义变化信息的学习。
在网络深层,提取两张图像的变化特征后,对两张图像特征进行融合,本文使用的融合方案是在通道维度合并两个特征图,再使用两个卷积核尺寸为3的卷积操作充分混合特征。在特征采样过程中,融合网络中间层的特征,对特征细节辅以修正。
上述改进充分考虑了变化检测场景的任务特殊性,针对两张图像输入,网络各自提取图像特征,同时辅以孪生网络同级特征,即充分学习图像自身特征,又保留了网络对变化区域的敏感性,较原始方案有较大提升。
3 试验结果分析
3.1 试验数据集
选用由北京航空航天大学发布的建筑物变化检测数据集LEVIR-CD[13]。该数据集是一个大规模遥感建筑变化检测数据集,是评估变化检测算法的新基准,尤其是基于深度学习的算法。
LEVIR-CD数据集由637个约0.5 m空间分辨率的谷歌地球图像对组成,所有图像为RGB三通道,均被裁切成1024×1024像素的影像,如图4所示。所有图像对时间跨度为5~14 a,有明显的土地类型变化,尤其是建筑增长。LEVIR-CD涵盖各种类型的建筑,如别墅住宅、高层公寓、小型车库和大型仓库。该数据集重点关注建筑相关的变化,包括建筑新增和建筑消失,主要是土壤、草地、硬化地面或在建建筑到新建筑区域之间的变化。图像标签是通用的二进制标签,标签中1表示变化,0表示不变,与常见语义分割数据集格式相同。整个数据集包含共31 333个单独的建筑物变更实例。

图4 LEVIR-CD数据示例
3.2 试验参数
使用的GPU为NVIDIA Tesla V100,所有试验均为单机8卡配置。通过两种算法的对比试验,训练学习率为0.01,训练轮次为30轮,每张GPU的批处理大小为1,学习率下降策略为poly[14]。
3.3 试验结果及可视化
表1为2种算法的效果对比,改进的DeepLabV3+算法性能有明显提升。

表1 算法模型指标
两个模型的预测结果如图5所示,两种算法在轮廓及细节上有一定差距。直接将DeepLabV3+应用于变化检测场景,模型存在一定漏检和少许误检,且变化轮廓在建筑物密集处容易粘连。DeepLabV3+改进算法能较好地平衡误检及漏检,同时保证建筑物轮廓清晰完整。

图5 算法模型结果对比
3.4 消融试验
本文选用DeepLabV3+改进算法展开消融试验(ablation experiment),即控制变量法,每次试验变化一个超参(Hyperparameter),通过多组试验对比,得到超参的最优配比。
表2为DeepLabV3+改进算法在不同超参下性能对比,根据试验结果,可得到以下结论:

表2 DeepLabV3+改进算法在不同超参下性能对比
(1)初始学习率为0.01时更适合本文任务场景。
(2)学习率下降策略poly比cosine[15]策略更适合该场景。
(3)训练轮次越多,模型的效果越好。
(4)批处理越大,模型的效果越好。
根据以上4点结论,本文使用最优超参再次对DeepLabV3+改进算法进行训练(见表2第8行)。最终通过模型效果对比,默认超参有4.1%的提升。
4 结 语
针对遥感建筑物变化检测场景,本文根据任务特性及网络结构特点,对DeepLabV3+算法结构进行改进,改进的结构更适合变化检测任务场景。同时,针对改进的DeepLabV3+算法进行消融试验,得到一组适合本场景的超参。
本文成功地将人工智能领域中DeepLabV3+算法应用于遥感建筑物变化检测场景,论证了方案的可行性,对于人工智能在通过卫星影像执法、城市违建等场景落地具有借鉴意义。
