基于视频和文本的机器人技能指令生成方法研究
2023-09-04黄可思陈俊洪林大润王思涵刘文印
黄可思 陈俊洪 林大润 王思涵 刘文印
(广东工业大学计算机学院 广东 广州 510006)
0 引 言
随着科技的迅速发展,机器人的智能化水平有了大幅度的提高,其功能也愈加复杂,例如可以通过深度摄像头进行目标的识别与抓取[1]、可以利用激光雷达进行巡检导航[2]等。然而现有的机器人大多是执行预先编写好的程序,在遇到新的场景时需要重新进行编程,降低了部署效率。为了解决该问题,近些年来人们提出通过新的学习方式让机器人学会新的技能。Akgun等[3]介绍了一种结合视频关键帧和动觉示教的机器人技能学习方法,该方法一方面抽取操作视频中的动作关键帧作为动作特征,另一方面通过让操作者拽动机器人进行运动记录操作轨迹作为运动特征,最后作者将两种特征进行结合识别并最终应用到机器人身上。Garcia-Hernando等[4]提出了一种结合RGB-D视频和3D手势标注的方法来识别人类动作,该方法利用多传感器对人体手势进行识别,并取得不错的效果。虽然以上方法都可以生成相应的技能指令,但是却需要操作者进行操作或者昂贵的传感器进行采集,限制了机器人的应用场景。对此,Yang等[5]建立了一个可以让机器人观看互联网视频从而学习动作的系统,该系统首先从视频中提取物体和动作,然后根据语义语法规则建立语法树,最终找出最接近视频的操作指令。该方法虽然通过视觉输入进行操作指令的组合,但是当识别出现错误时,其生成的操作指令也必定是错的。
为了解决该问题,本文提出一种结合视觉和文本知识的多模态视频转译技能方法框架。该框架包含两个模块,其中第一个模块主要从视频中提取语义信息,该模块首先使用I3D网络对视频中操作者的动作进行识别,其次利用Mask R-CNN网络和XGBoost分类器对物体进行识别分类,最后将识别所得的元语义组合成机器人指令。由于得到的指令是基于视觉输入进行生成,所以当识别算法发生错误时,将产生不符合逻辑的指令。为了解决该问题,我们提出基于BERT-GRU模型的文本的操作指令学习模块,该模块首先在大型文本数据集Recipe1M+上进行预训练,然后在生成指令上进行微调和测试,并最终输出修改过的机器指令。通过在MPII Cooking 2数据集上进行测试,我们发现本文所提出的框架相比于单模态情况下的操作指令生成的框架具有较大的提升,有效地验证了本文方法。
1 相关研究
1.1 机器人视觉转译指令
为了从视频中提取人的动作并转化成操作指令,Mici等[6]提出了一种自组织神经网络模型,用于从RGB-D视频中学习如何识别人和物体互动的动作。该模型由GrowWhen-Required(GWR)神经网络的层次结构组成,可以学习动作和物体的原始表征,并以无监督的方式生成动作-物体的映射;Nguyen等[7]提出使用RNN和CNN模型直接将视频转译成操作指令,他们首先利用CNN对视频进行特征的提取,再使用具有编码器-解码器(encoder-decoder)结构的两个RNN层来对视觉特征进行编解码,最终根据指令模板顺序生成操作指令;Welschehold等[8]为了让机器人直接模仿操作动作,从RGBD视频中分别提取出手和物体轨迹,并输入网络中进行训练,最终实现让机器人可以通过观看人的演示进行开门等复杂的任务。在本文中,我们利用I3D网络抽取动作特征并进行识别,再把动作特征与Mask R-CNN抽取的物体特征进行融合,并将融合特征输入XGBoost分类器中计算得出操作物体,最后组合成操作指令。
1.2 语义指令组合
机器人指令组合是机器人实现学习模仿的关键环节[9],在早期的研究中,Chomsky[10]提出一种类似于人类语言的极简生成语法,该语法定义了描述人类动作所需要的最基本元素;基于Chomsky的研究,Yang等[11]定义了一组描述操作技能的语义上下文无关语法规则,该规则分别定义了动作与物体之间的关系,并使用树形结构将这两者关系进行组合,最终形成技能指令;与Yang等不同的是,Kjellstrom等[12]则提出一种基于上下文识别操作的物体和人类操作动作的方法,该方法能够同时对手部动作进行分割和分类,并对动作中涉及的物体进行检测和分类。实验表明上下文信息可以有效地改善物体和动作的分类结果。然而以上方法只考虑了从视频中提取元语义进行组合,忽略了语义组合上的逻辑关系。为了解决该问题,本文提出利用BERT-GRU文本模型来学习文本数据集中隐藏的操作指令,提高指令的生成准确率。
2 方法研究
本文总体框架如图1所示。可以看到,本文所提出的框架一共分为两个模块,其中:第一个模块为机器人视觉转译指令模块;第二个模块为基于BERT-GRU模型的文本操作指令学习模块。接下来我们将具体介绍每个模块的实现方法。
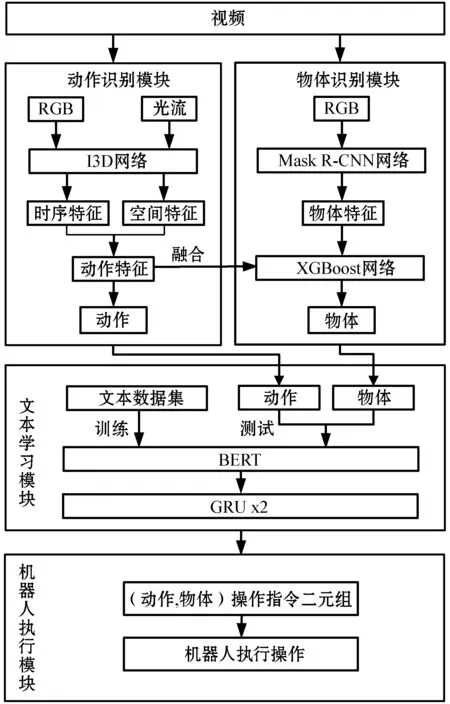
图1 基于视频和文本的机器人技能指令生成框架
2.1 动作特征提取
在提取动作特征之前,我们首先对输入视频进行预处理,具体来说,我们将视频尺寸大小裁剪为224×224×3,并且为了降低计算代价,我们对输入视频进行下采样处理,采样率大小设置为5,即每五幅图片中我们只选取中间的图片进行计算,其余的图片将直接舍弃。由于动作特征包含了时间和空间两个维度信息,所以我们使用了具有双流结构的I3D(Two-Stream Inflated 3D ConvNet)[13]网络进行特征的提取。具体来说,对于空间流的特征提取,我们使用下采样后的RGB视频进行输入,然后使用Ioffe等[14]所提出的改进Inception-V1模块进行特征的抽取,其结构如图2所示。
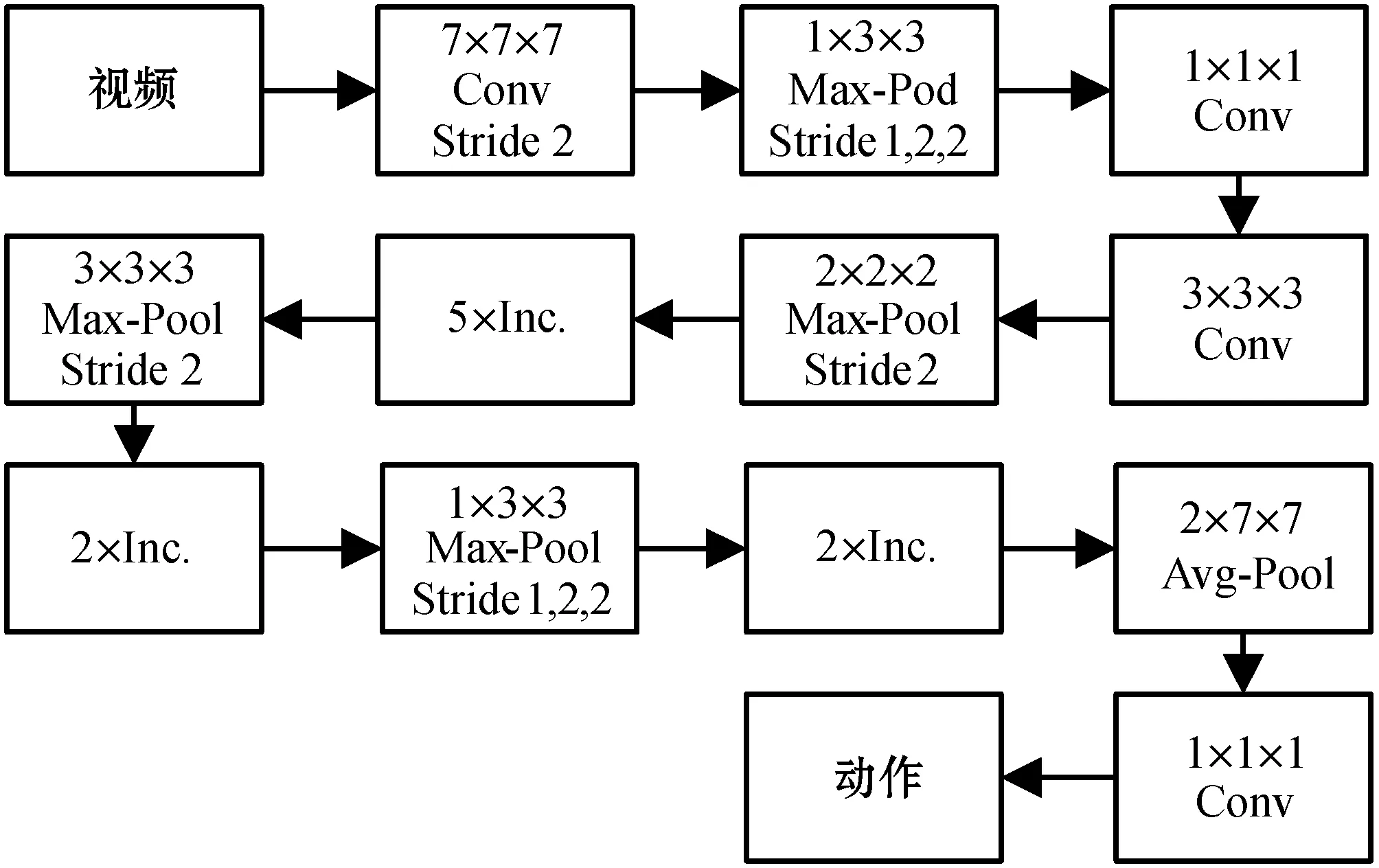
图2 Inception-V1模型
可以看出,改进后的Inflated Inception模块主要将原有的2D卷积核以及2D池化替换成3D卷积核和3D池化,其中3D卷积核是由2D卷积核在时间维度上复制N次所得,该做法使原来2D网络参数可以直接应用到3D网络上,降低了重新训练所需要的时间和计算成本,提高识别效果。除此之外,为了保留更多的时间信息,改进后的Inflated Inception模块将前两个最大池化层维度替换为(1,2,2),将最后两层均值池化层替换为(2,7,7)。与空间流处理方式相似,时间流使用相同的网络配置,但其输入则使用光流堆叠图进行计算。在训练过程中,两个流的权重并不互相共享。
本文将I3D网络在Kinetics数据集[13]上进行预训练,然后再使用MPII Cooking 2数据集进行微调。在模型设置方面,我们使用随机梯度下降作为网络优化器,将网络的学习率设置为0.1,网络的权重衰减值设置为0.5,并使用Dropout方法防止模型过拟合。最终,我们将分别输出2×1 024的动作特征以及动作分类结果进行进一步的使用。
2.2 操作物体识别
对于操作物体识别,我们将下采样后的RGB视频输入到Mask R-CNN模型[15]中进行物体特征的提取,其中Mask R-CNN模型分为两个步骤,首先是通过Region Proposal Network(RPN)[16]生成大量的物体候选边框,然后再将这些候选框通过卷积网络输出标签和置信度。本文将Mask R-CNN在MS-COCO数据集[17]上进行预训练,然后再将模型应用到MPII Cooking 2数据集上进行微调,最后输出操作物体的特征。值得一提的是,为了让操作物体与操作动作能有效地结合起来,我们将输出的物体特征与动作特征进行拼接融合,并输入到XGBoost分类器[18]中进行操作物体的分类,最终输出操作物体的类别。
2.3 文本指令学习
虽然从视频中识别所得到的动作和物体可以组合成二元组指令给机器人进行操作,但是由于识别过程中可能发生动作和物体的误识别,从而导致生成的指令信息无法让机器人进行操作。对此,我们提出通过从文本数据集中进行指令的学习来提高指令生成的准确率,其模型如图3所示。
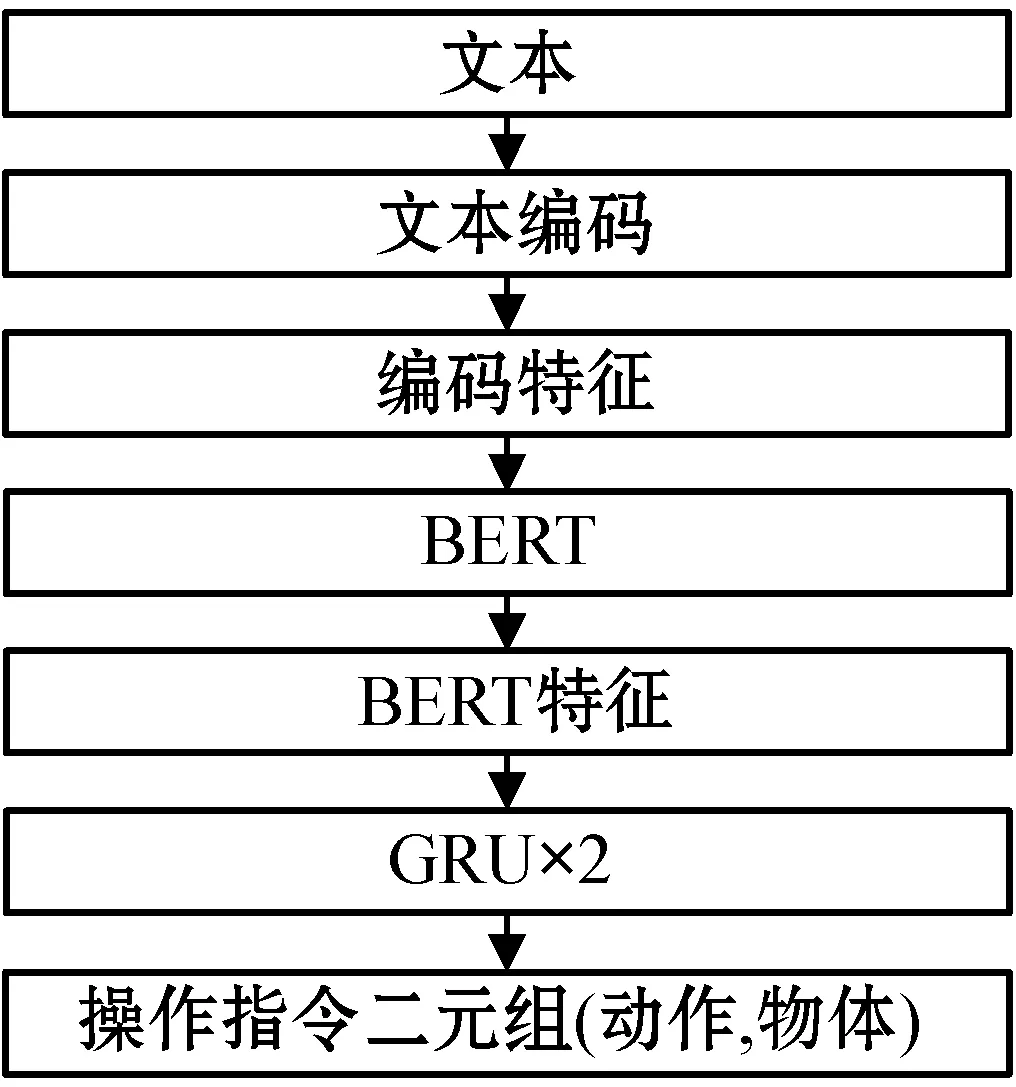
图3 文本学习模块
我们首先使用了BERT模型进行训练,其中BERT模型[19]采用了Multi-Headed Attention机制,该模型一共由12层Transformer Encoder[20]组成,每一层的隐藏层状态数量为768,整个网络参数规模达到1.1×108。并且为了进一步提高网络的精度并获取时序上的特征,我们提出在BERT最后一层FC层前接入两层GRU[21]网络。该做法使得由Multi-Headed Attention所提取的不同层级特征可以通过更新门和重置门进行融合,从而提高识别效果。本文将GRU的输入节点数设置为768,与BERT所输出的特征保持一致。最终通过特征的提取和分类,模型将分别输出2个Onehot矩阵代表动作概率和物体概率,并根据概率最高的概率结果分别输出最终的动作和物体组合成机器人指令给机器人执行。
本文首先把视频输出的二元组放入与文本训练集相似的句式中进行填充,例如(action) the (object)、use (object) to (action)等,使得测试的输入与训练的输入格式一致。紧接着我们将测试的短句输入进BERT模型中进行编码和提取特征,其中embedding是通过BERT预训练模型fine-tune得到,在通过BERT模型训练学习后,模型将输出特征给GRU进行进一步的特征提取,最终分别输出操作指令二元组给机器人执行。
3 实 验
3.1 数据集介绍
MPII Cooking 2 数据集[22]:MPII Cooking 2数据集一共包含了273个做菜视频,它是由不同的操作者从真实环境中进行采集,视频帧数长达2 881 616帧,时长超过27 h。特别地,MPII Cooking 2 数据集中包含了有三十多种菜谱,但操作者并不限定于某种固定的顺序来制作菜肴,这使得数据集包含的信息量更大,识别难度更大。在本文中,我们挑选了7种动作和48类常见物体进行识别,数据情况如表1所示。对于数据集的划分,我们选择了包含指定动作和物体的3 168段视频作为数据集,其中我们随机抽取2 852段视频(90%)作为训练集,316段视频(10%)作为测试集。

表1 物体和动作类别数据
Recipe1M+数据集[23]:Recipe1M+数据集包含了超过一百万种菜谱和一千三百万幅食物图片,菜谱种类涵盖主食、配菜、小吃等,每种菜谱标记了标题、食材清单和制作菜肴的方法介绍。然而由于文本没有对指令进行标记,所以我们基于Recipe1M+数据集制作了符合本框架的文本二元组数据集。具体来说,每条数据集将存储为字典形式,如:{"text": "peel and thinly slice yukon gold and sweet potatoes", "tuple":[["peel", "potato"], ["slice", "potato"]]}。为了让BERT-GRU模型能够更好地学习指令,我们在数据集中添加了负样本,即text文本中可能有不合理的地方,但二元组中仍输出该句子正确含义的结果。最终我们选取了2 152条文本作为我们的数据集,其中1 506条(70%)数据作为训练集进行训练,剩下的646条(30%)作为测试集进行测试。表2统计了每个动作的分布情况。

表2 文本数据集分布情况
3.2 评测指标
为了更好地对各种模型进行评估,我们采用了以下评测指标。
准确率(Accuracy):输入样本中预测正确的个数占总个数的大小,公式如下:
(1)
精确率(Precision):输入样本中预测正确的个数占正样本的总个数大小,公式如下:
(2)
召回率(Recall):实际中正样本中预测为正样本的数量大小,公式如下:
(3)
F1值:兼顾了Precision和Recall的综合评测指标:
(4)
3.3 动作识别结果
为了证明I3D模型的长视频分割效果比经典模型要好,本文通过与Stack Flow、CNN、CNN3D[24]、LSTM[25]和Two-Stream模型在相同的条件下进行对比实验,得出各个模型的准确率、精确率、召回率和F1的评测结果如表3所示。

表3 动作识别结果(%)
可以看出I3D在准确率、精确率、召回率和F1的评测结果皆优于对比实验中的其他模型。并且通过对比可知,使用双流结构的网络模型要比使用单流的网络模型具有更高的识别率,这表明了双流网络可以从视频中有效地提取时间和空间特征,提高了识别效果;而通过对比I3D网络和Two-Stream网络可知,通过增加时间维度后的3D卷积核可以从视频中提取更多有效的特征,其准确率提高了1.91百分点,有效地验证了3D卷积核的有效性。
3.4 物体识别结果
对于物体识别,我们将Mask R-CNN所提取到的物体特征输入到与I3D网络所提取到的动作特征进行融合并输入到XGBoost进行分类,为了对比不同分类算法的分类效果,我们采用了SVM、Decision Tree、Logistic Regression、Random Forest和Gradient Boosting这五个分类算法进行分类,分类结果如表4所示。
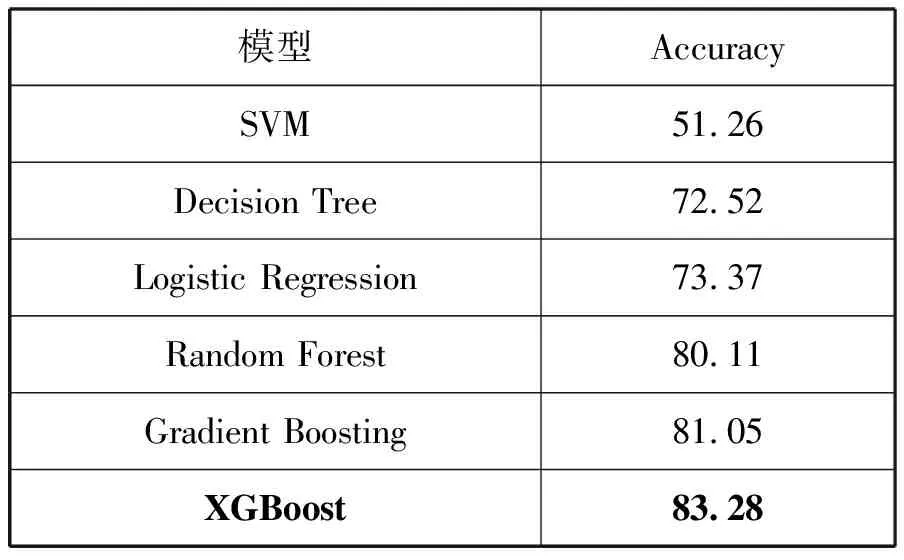
表4 操作物体识别效果(%)
可以看出,对比于其他五个分类算法,XGBoost的准确率为83.28%,相比于其他算法最大提高了32.02百分点的准确率,有效地验证了本文算法的有效性。
3.5 二元组指令生成效果
为了提高视觉转译指令模块的准确率,我们把视觉生成的二元组指令与随机生成的句子模板进行结合输入到文本指令学习模块中,同样地,我们用不同的分类器,如SVM、Decision Tree和BERT等模型做对比实验,评测结果如表5所示。
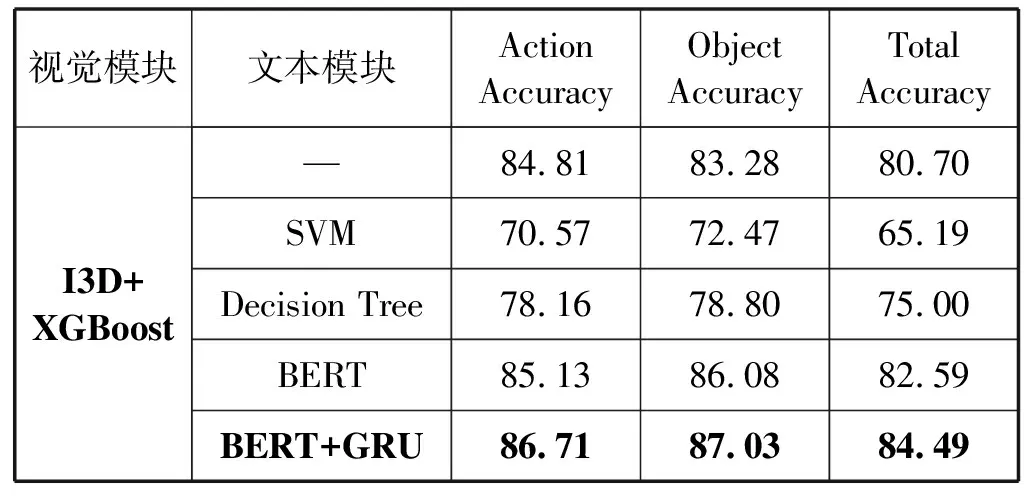
表5 二元组指令生成效果(%)
可以看出,当融合了视觉跟文本特征后,二元组指令生成效果得到了提高,其最终准确率高达84.49%,比单个视觉模块提高了3.79百分点,有效验证了本文方法。从BERT和BERT-GRU实验结果进行对比,我们发现当BERT模型接入GRU模型后,能够更好地处理从BERT提取到的文本数据集的特征,从而提高了准确率。除此之外,从表5我们发现在使用SVM和Decision Tree算法后,二元组的精度相比于原来单视觉模块的精度有所降低,造成该结果的原因主要分为两点:一是这两个模型对训练数据过拟合,导致测试结果较差;二是由于文本学习模块是根据语料库知识进行推荐,其目的是对不符合逻辑的二元组进行替换,这导致了相关正确的指令可能会被错误替换,其中本文所提出的BERT+GRU算法错误替换了4.75%的测试结果,正确替换了8.54%测试结果。为了进一步地展示文本学习的有效性,我们对部分指令结果进行了可视化展示,效果如表6所示。
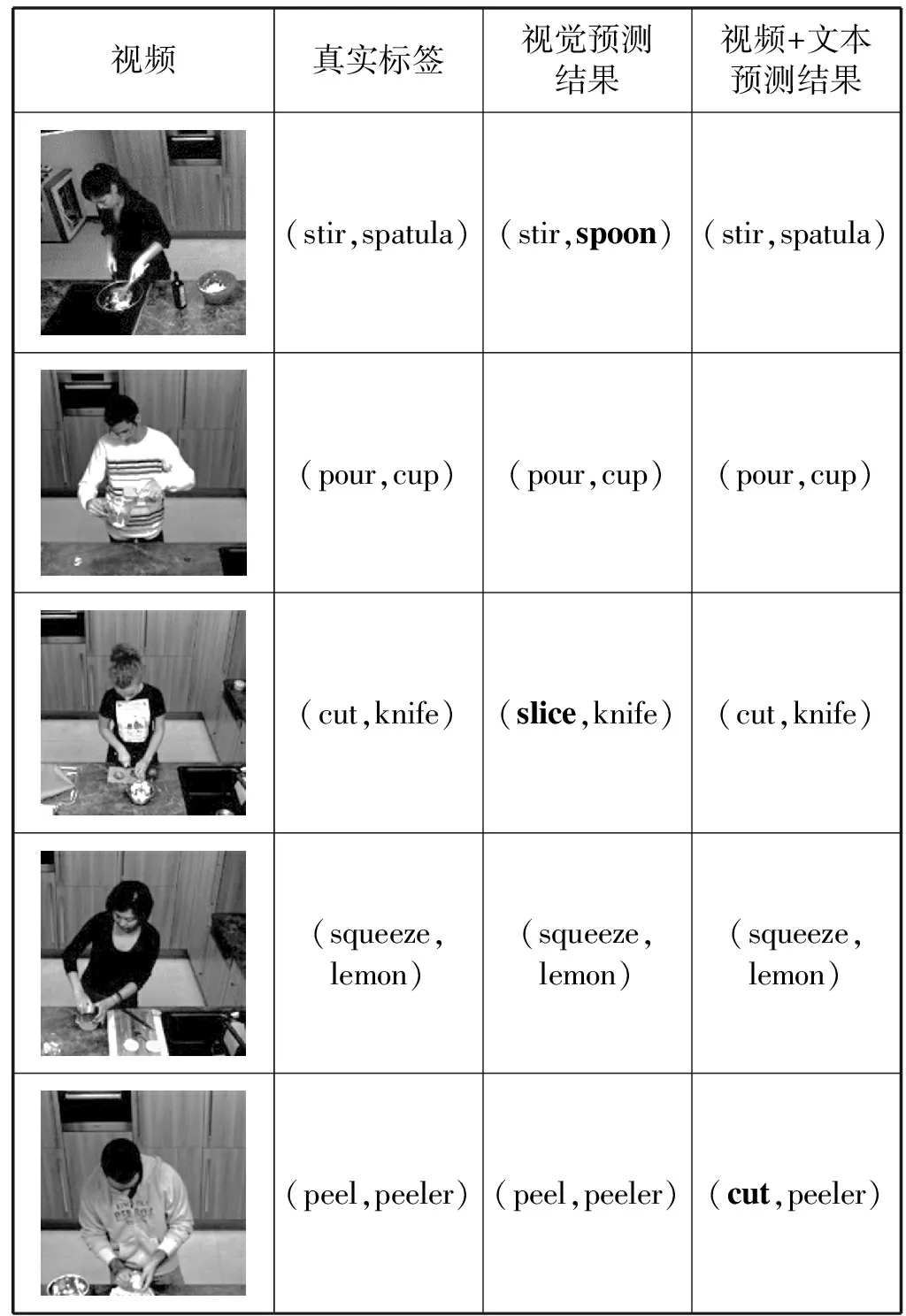
表6 动作指令组的可视化效果
3.6 机器人执行指令
本文的出发点是打造一个可以从视频中学习指令的机器人系统,对此我们将本文所提出来的系统应用到一个人形机器人Baxter上进行验证,效果如图4所示。

图4 机器人执行预测指令
实验结果表明,机器人可以成功地执行本系统所生成的机器人指令,例如执行搅拌、倒油等动作,验证了本文方法的有效性。
4 结 语
本文提出一个结合视觉和文本信息的机器人技能指令生成框架,该框架分别从视频和文本提取元语义信息并进行融合,最后生成机器人指令给机器人执行。大量实验表明,本文方法不仅可以从视频和文本中生成机器人指令,还可以部署到真实的机器人上进行操作,验证了本文方法的有效性。
在未来的工作中,我们将有两个方面的拓展:(1) 使用更高级的语法规则将指令与指令之间进行链接,从而完成更加复杂的动作;(2) 考虑多人协作时的语法规则表示。
