一种基于多模型联合学习的方面情感分析方法
2023-09-04滕奇志卿粼波何小海
杨 强 滕奇志 卿粼波 何小海
(四川大学 四川 成都 610065)
0 引 言
作为情感分析的一个重要子任务,基于方面词的情感分类是一种细粒度的情感分类任务,旨在识别句中不同方面的情感极性[1]。例如,给定一个句子“They use fancy ingredients, but even fancy ingredients don’t make for good pizza unless someone knows how to get the crust right.”,对方面词“ingredients”“pizza”和“crust”的情感极性分别是积极、消极和中立。
在自然语言处理(Natural Language Processing,NLP)领域,基于方面词的情感分类正受到越来越多的关注,在实际生活中的应用也越来越广泛,如:网络言论检测、个性化推荐系统[2]等。早期的工作主要是通过人工设置和提取一些特征,然后送入分类器进行情感分类,最典型的分类器就是SVM[3],但是手动提取特征通常会耗费大量的人力和时间,并且效果也不是很理想。为了解决该问题,对自动特征提取技术的研究受到了广泛关注。以前有一些工作提出通过句法关系[8]将上下文词的情感特征自适应地传递到方面词,如通过构建一棵句法分析树去识别不同方面的情感特征。尽管这些方法有效,但它们并没有考虑方面词和上下文词之间的句法关系。TD-LSTM[4](Target-Dependent Long Short-Term Memory)和TC-LSTM[4](Target-Context Long Short-TermMemory)网络模型,对LSTM(Long Short-Term Memory)模型进行了改善,将方面词向量和上下文词向量联合编码,使模型可以捕获方面词周围上下文词的特征,提取出方面词和上下文词之间的句法关系。
注意力机制可以使模型对句子中重要的部分给予更多的关注。随着注意力机制在机器翻译中的广泛应用,很多工作也致力于将注意力机制应用于基于方面词的情感分类的任务中,如AEAT-LSTM[5](Attention Long Short-Term Memory)网络模型、Attention-based LSTM2[6]网络模型。这些模型可以有效提取方面词和其上下文词之间的语义关系[7],却忽略了方面词和其上下文词之间的句法关系,这可能会影响基于方面的上下文表示的有效性。因为给定的方面可能会出现在描述上接近该方面但在语法上与该方面不相关的几个上下文单词中,例如“Its size is ideal and the weight is acceptable.”,基于语义相关性,方面词“size”会很容易被“acceptable”描述,但实际上并非如此。以前的一些工作已经使用了句法分析,但是单词级别的句法解析可能会阻碍跨不同短语的特征提取,因为一个方面的情感极性通常是由关键短语而不是单个单词决定的。
为了解决上述方法的不足,受位置机制启发[10],句子中离方面词越远的上下文词对方面词情感特征的提取贡献越少。据此,本文利用不同上下文词在方面上的句法接近性,依据上下词在句中的位置不同分配给它们不同的权重,用来度量不同上下文词对方面词的重要程度。本文采用位置权重和依赖权重两种方法来提取方面词和上下文词之间的句法关系。
本文在SemEval 2014[19]Task4数据集进行了多组对比实验,实验结果表明,与一系列最新模型相比,本文提出的模型在情感预测的准确率和F1值上均有明显提升,充分验证了该模型的有效性和可靠性。
1 相关工作
1.1 基于注意力机制的方面情感分析
情感分析也称为观点挖掘,是自然语言处理领域中重要的研究课题[15-16]。目前,将注意力机制与神经网络相结合的方法,已成为特定方面情感分析问题的主流方法。注意力机制的应用使得模型对句子中重要成分的关注度进一步增强,有效避免了长距离情感特征在传递过程中出现的特征丢失问题[17]。ATAE-LSTM[5]网络模型将LSTM网络和注意力机制结合,该模型将方面词与上下文词联合编码进行方面级情感分类;RAM[2]网络模型在双向LSTM的基础上构建多头注意力,使模型对句子的情感特征进行更深层次的关注;AOA[17](Attention-Over-Attention)网络模型在计算注意力权重时,同时计算横向和纵向的注意力得分,然后将注意力得分进行融合,使模型可以从不同角度关注句子的情感特征。
1.2 基于句法分析的方面情感分析
注意力机制可以有效地捕捉长距离的情感特征,但它更加关注的是句子上下文词和方面词之间的语义关系,却忽略了方面词和其上下文词之间的句法关系,因为给定的方面可能会出现在描述上接近该方面但在语法上与该方面不相关的几个上下文单词中,从而导致对某方面情感极性的误判。
PWCN[14]网络模型利用上下文词在方面上的句法接近性,依据上下文词在句中的位置赋予它们不同的权重信息,以确定其在句中的重要性,从而捕获方面词和上下文词的句法关系。
2 基于联合学习的方面情感分析模型
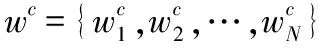
整个模型框架如图1所示。嵌入层将单词映射成低维度的数值向量矩阵E∈R|V|×de,|V|是句中单词个数,de表示单词向量维数。由词嵌获得单词向量表示后送入Bi-LSTM(Bi-directional Long-Short Term Memory)网络获得隐藏层的输出向量H={h0,h1,…,hn-1},其中hi∈R2×dh是从前向LSTM和后向LSTM获得的隐藏状态的级联,dh是单向LSTM中隐藏状态向量的维数。
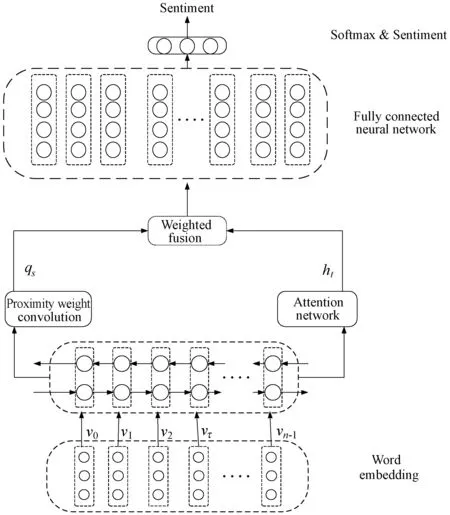
图1 基于联合学习的方面情感分析模型框架
先将隐藏层状态的输出送入注意力机制网络,如捕获方面词和上下文词之间的语义关系;然后再将隐藏层输出送入邻近加权卷积神经网络,捕获方面词和上下文词之间的句法关系;最后将注意机制网络输出的特征向量与邻近权重卷积网络输出的特征向量加权融合,送入全连接神经网络中得到某方面的情感极性。
2.1 单词嵌入层
嵌入层将每个单词映射到高维向量空间。采用预训练的词嵌矩阵GloVe[18]去获得每个单词的固定词嵌。每个单词由一个固定的嵌入量表示为et∈Rdemb×1,上下文单词的嵌入表示为矩阵Ec∈Rdemb×1,第i个方面的嵌入表示为矩阵Eai∈Rdemb×Mi。本文模型中如果方面词是一个短语,会对方面词短语进行去停用词处理,只保留方面短语中更为重要的部分,充分提高模型对重要方面词的关注。
2.2 Bi-LSTM网络
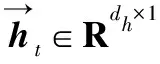
ht={h0,h1,…,hn-1}
(1)
式中:hi∈R2×dh是分别从前向LSTM和后向LSTM获得的隐藏状态的级联,dh是单向LSTM中隐藏状态向量的维数。
2.3 注意力机制网络
获得了方面词和上下文词的表示ht后,会将ht送入注意力机制网络以获得方面词和上下文词之间的语义关系。注意力网络将会输出连续的一维向量v,是被注意力系数加权之后的向量:
(2)
式中:αi∈[0,1],为每个单词的注意力分数。
(3)
特定方面的注意力机制网络如图2所示。
2.4 邻近权重
以往基于注意力的模型主要关注如何根据句子中上下文词和方面词的语义关联性来获得文本的表示[20]。这些模型在不考虑句法信息的情况下,根据潜在语义空间中的词向量表示计算注意力权重,这可能会限制模型的有效性,因为它们可能错误地识别表示方面的上下文单词。本文通过构建句法依赖树来发现方面词的情感特征,获得方面词和上下文之间的句法关系。我们将这种句法依赖信息形象的称为邻近权重,它表征了方面词对上下文词的句法接近度。如“Its size is ideal and the weight is acceptable.”上下文词“ideal,acceptable”与方面词“weight”在语义上是很相关的,有很大可能去描述方面词“weight”。但是,从句法的角度来看,“ideal”在句法上与“weight”是不相关的。事实上“acceptable”是对“weight”真正的描述,表达了积极的情感倾向。
本文采用两种不同的方式作为上下文词对方面词在句法上的接近度表示:位置权重和依赖权重。
2.4.1位置权重
一般来说一个方面词周围的词都是描述这个方面的,因此可以将这种位置信息视为近似句法接近度的测量。位置权重可以由式(4)表示。
(4)
式中:τ表示方面词短语开始的位置;i表示第i个上下文词的位置;n表示句子中单词的总数;m表示方面词短语包含的单词个数;Pi表示第i个上下文词的位置权重。直观上来讲,上下文词离某一方面词短语越远,其位置权重越小。
2.4.2依赖权重
除了上下文中的绝对位置之外,还可以考虑构建一棵句法依赖树,测量上下文词对方面词的距离。
例如:“the food is awesome-definitely try the striped bass.”。以“food”作为方面词,本文首先构建一棵依赖树,然后为上下文词计算基于树的距离。每个上下文词和方面词“food”之间的距离都是这棵树中最短的路径。如果方面词不止包含一个单词,本文取上下文词与所有方面词组成词之间基于树的最小距离作为结果。在不常见的情况下,如果上下文中存在多个依赖树,本文手动将其他树中方面词和上下文词之间的距离设置为恒定,该值为句子长度的一半。
为了更好地解释该方法,图3显示了一个示例句子。通过上述方法,句子中所有单词基于方面词“aluminum”的距离d={d0,d1,…,dn-1}已在图中进行了标注。句子中上下文词的权重系数如式(5)所示。
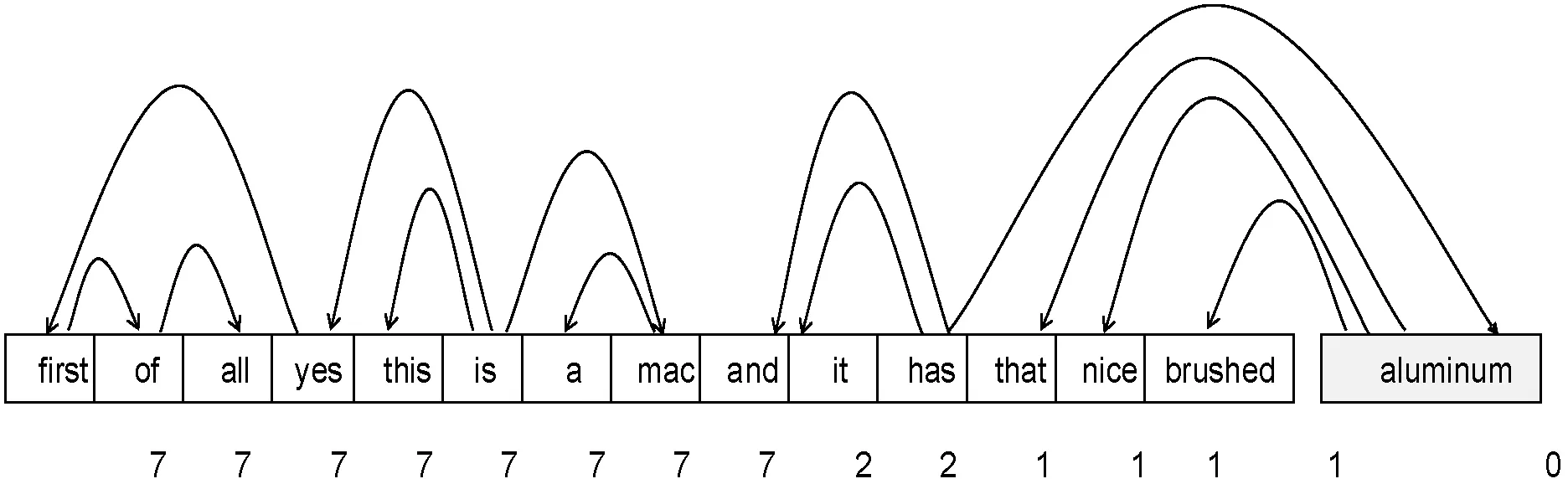
图3 依赖权重
(5)
2.5 邻近加权卷积神经网络
与使用单词级功能相比,具有短语级功能的方面级情感分类效果更佳。本文采用一种邻近权重卷积神经网络,其本质上是一维卷积,使用长度为l的内核,即l-gram。不同于传统的卷积神经网络,在进行卷积计算之前,卷积神经网络会被分配邻近权重。邻近权重的分配如下:
ri=pi*hi
(6)
式中:ri∈R2×dh表示句子中第i个单词的邻近加权表示。
此外,本文对句子进行零填充以确保卷积输出与输入句子长度有相同的序列,卷积过程如式(7)、式(8)所示。
(7)
(8)
式中:qi∈R2×dh表示从卷积神经网络中提取到特征,Wc∈Rl·2dh×2dh和bc∈R2dh是卷积核的权重和偏差,t是一维卷积的长度。
由于卷积层的输出特征只有部分对分类有指导意义,因此通过一个核长度为n的一维max-pooling层来选择最显著的特征,如式(9)所示。
(9)
2.6 特征融合
如上文所述,由注意力机制网络得到了方面词和上下文词之间语义关系的向量表示v,由邻近权重卷积神经网络得到了方面词和上下文词之间句法关系的向量表示qs。为了充分考虑方面词和上下文词之间的句法及语义关系,本文将qs和v进行加权融合,送入到一个全连接层,最后进行Softmax得到对方面词的情感极性,如式(10)-式(11)所示。
qs=α×qs+(1-α)×v
(10)
(11)
式中:bf∈Rdp是全连接层偏置,Wf∈R2dh×dp是要学习的权重参数。
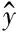
(12)
式中:j是情感标签的索引,分别是:积极、中立和消极。i是句子的索引;λ是L2正则项,θ表示所有可训练的参数。
3 实 验
3.1 实验数据集
为了验证本文提出的模型性能,本文在SemEval 2014[19]数据集上进行实验,此数据集包含对笔记本电脑和餐厅的评论信息。表1显示了SemEval 2014[19]数据集的基本信息,每一个数据集都包含训练集和测试集。数据集中的每个评论包含一个或多个方面词及其对应的情感极性,即积极、消极和中立。具体而言,表1中的数字表示每个情感类别的数量。
3.2 实验参数设置
实验使用Glove[18]词向量语言模型作为初始化词嵌。每个单词向量的维度为300。初始权重矩阵由正态分布N(0,1)进行随机初始化,隐藏状态向量的维数设置为300。本文用Adam作为优化器,学习率设置为0.001。L2正则化项设置为0.000 01,batch-size设为32,dropout设为0.5。
本文采用Accuracy和Macro-Averaged F1作为评价指标,来验证本文提出的模型的有效性。此外,n-gram的长度设置为35。
3.3 实验结果分析
本文提出两种对方面词周围上下文词进行权重分配的方法,分别是位置权重和依赖权重。后面要将本文提出的注意力机制网络的输出和这两种邻近权重网络的输出分别进行加权融合。
为了选取最佳的融合阈值,本文将融合阈值α的初始值设置为0.1,然后以0.1为步长以寻求最佳的融合阈值,本文将注意力机制网络与两种邻近权重网络的输出分别进行融合,实验结果如表2和表3所示。

表2 注意力网络结合位置权重(%)
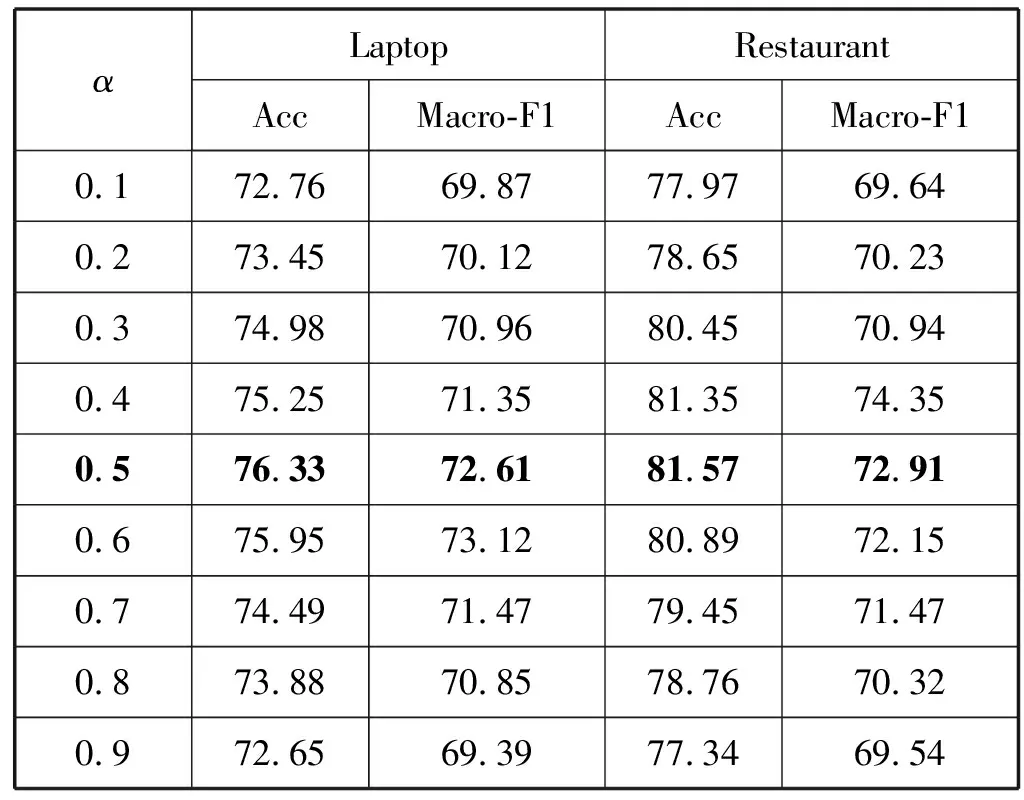
表3 注意力机制网络结合依赖权重(%)
为了验证本文提出的融合方式的有效性,本文尝试将邻近权重网络和注意力机制网络级联,采用两种级联方式:注意机制网络的输出向量被邻近权重加权后送入邻近权重卷积神经网络、邻近权重直接被注意力系数加权,用以与本文提出的融合方式比较。综合考虑,将融合系数α设为0.5,实验结果如表4所示。
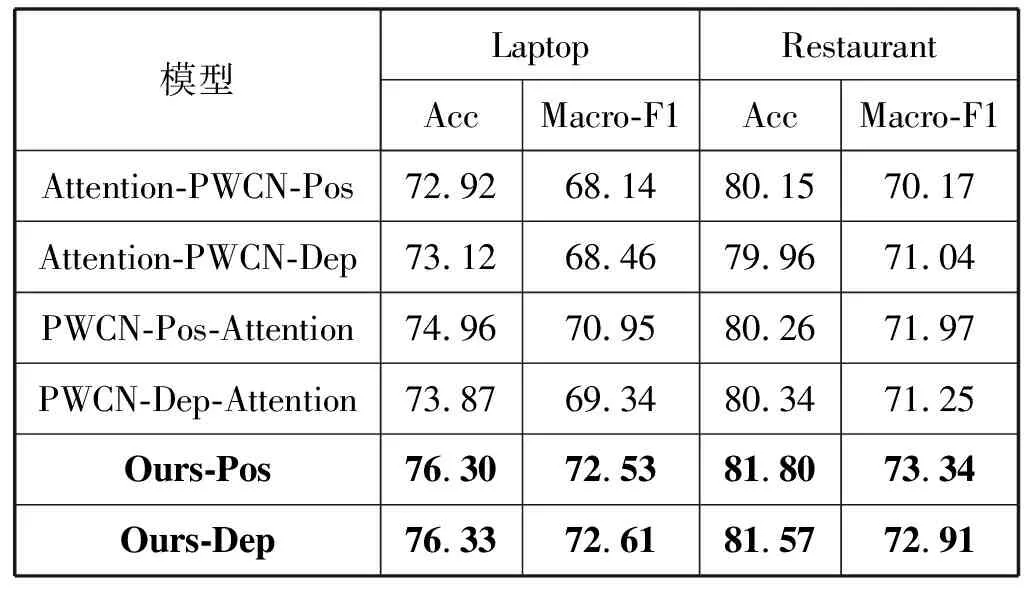
表4 融合方式比较(%)
其中Att-PWCN-Pos、Att-PWCN-Dep是将Bi-LSTM的输出通过注意力机制网络后,送入邻近加权卷积神经网络进一步提取特征后进行情感分类;PWCN-Pos-Att、PWCN-Dep-Att是将邻近加权神经网络的输出送入注意力机制网络进一步提取特征后进行情感分类。
Ours-Pos和Ours-Dep是本文提出的模型。本文对方面词周围上下文词的位置信息进行权重分配时采用了两种方法:Pos是仅仅依赖于方面词和上下文词间的绝对距离进行权重分配的方式;Dep使用句法分析,通过构建一棵句法分析树,以方面词作为树的根节点,通过衡量不同上下文词到树的根节点的距离来为上下词进行权重分配,称为依赖权重。这是两种完全不同的权重分配方式,后面本文会将注意力机制网络的输出分别和这两种邻近权重网络的输出进行加权融合,其中Ours-Pos是将注意力机制网络和位置权重融合后得到的模型,Ours-Dep是将注意力机制网络和依赖权重融合后得到的模型。
为了充分验证本模型的有效性,本文对比了其他公开模型的性能指标,其结果充分验证了本文提出的模型的有效性,该模型性能大大优于LSTM、TD-LSTM、AEAT-LSTM、RAM和IAN,并且该模型在PWCN(PWCN-Pos,PWCN-De)模型上也有了一定程度的提高,实验结果如表5所示。为对本文提出模型的有效性和优势进行更直观的展示,表6中给出了一个实例,给出不同模型对方面词style的情感极性。
表5 对比实验的结果分析(%)

表6 实例结果展示
4 结 语
本文提出了一种融合注意力机制和句法信息的联合训练模型,分析对某方面的情感极性时,既考虑了该方面词和上下文词间的语义关系,同时还考虑了该方面词和上下文词间的句法关系,弥补了现有模型只考虑方面词和上下文词间单一关系的不足,在SemEval 2014[19]数据集上取得了较好的效果。但是虽然该模型同时考虑了句子中方面词和上下文词间的句法关系及语义关系,可一个句子中可能存在多个方面词,该模型并没有将方面词之间的关系考虑进去。在未来的研究中,本文将就如何在模型中融入不同方面词之间的关系进行研究,以提升模型的性能。
