结合服务相似性的Bandit智能推荐模型
2023-09-04周礼亮
周礼亮 李 涛
(中国电子科技集团公司航空电子信息系统技术重点实验室 四川 成都 610036)
0 引 言
Web服务是一种具有统一标准的、平台无关的网络资源服务提供方式,因为其部署简单、调用方便等特性,在电子商务、分布式计算等领域都有着广泛的应用。随着计算机技术的发展,互联网中的Web服务也日益丰富[1]。目前,关于Web服务的推荐已有大量研究。
个人终端本身并不提供Web服务,它只是接入了拥有大量服务的互联网。除引入服务质量的概念外,服务推荐的过程本质上与传统的商品推荐并无太大的不同。具体而言,个人终端的地理位置虽然会发生频繁变化,但是用户的需求在一定时间范围内却相对稳定;此外,传统的CS架构在个人终端上仍有广泛应用,对于推荐算法的执行过程,一般个人终端只完成复杂度较低的计算,而开销较大的计算任务往往由服务器端完成。正因为如此,Web服务推荐的这种应用场景有局限性。
在某些无线移动环境下,终端无法与互联网相连,服务都存在于终端本地中,而为了增加服务的可用性,往往将多个终端组织成一个局域网,这些终端既是服务的提供者,又是服务的使用者。这种情况下,服务的推荐就需要由各终端协作完成。此外,由于移动终端的计算能力有限,如果推荐算法中所有的计算完全由所有终端完成,则耗时较长,如果终端处于一个不断变化的场景中,对推荐结果的实时性要求较高,则现有的服务推荐算法不能得到很好的应用。综上所述,对于完全由终端集群组成的无线移动环境下的服务推荐问题,目前仍然缺少研究。本文将对完全由终端集群组成的无线移动环境下的服务推荐问题展开研究,设计出适合Web服务分布在多个终端中的无线分布式场景的服务推荐算法。
Web服务推荐方法按照对推荐模拟更新的方式的不同可以划分为传统推荐方法和智能推荐方法。在传统推荐方法中,推荐结果由原始数据经过正向计算得到,当数据发生动态变化时,往往认为数据集发生了变化,需要重新计算推荐结果;而智能推荐方法往往会预定义一个智能体,它是独立于数据的存在,数据只起到改变智能体参数的作用,当数据发生变化时,只需要对智能体进行更新即可。传统推荐方法模型简单,在静态场景下有较高的效率,而在场景的不断变化的前提下,服务对终端的效用并不能保持稳定,导致终端对服务的评分会时刻更新,如果使用传统推荐方法则需要频繁重新计算推荐结果,额外增加很多计算开销。本着减少算法时间和空间复杂度的原则,智能推荐方法更适合动态变化的场景。进一步地,智能推荐方法又可分为监督学习、无监督学习和强化学习方法等,对于监督学习和无监督学习方法,一般需要给出全部的数据,模型训练一次完成,处理推荐完成后终端做出的反馈有一定难度,而强化学习算法能根据环境中的反馈信息不断地更新模型,所以智能推荐方法中的强化学习又更适合动态变化的场景。
1 相关研究
1.1 基于强化学习的推荐算法
强化学习是一种能够适应环境的机械学习方法,它的特点在于利用智能体(Agent)在环境交互中的反馈进行模型训练[2-3]。强化学习以其在复杂非线性系统中表现出优秀的性能被广泛应用于四类领域:过程控制、任务调度、机器人设计、游戏[4]。
在将强化学习方法应用到推荐系统的过程中,Auer[5]提出了LinRel算法,该算法将物品的特征向量融入多臂老虎机模型。Li等[6-7]提出Lin UCB算法解决了UCB等MAB算法缺少推荐上下文信息的问题。文献[8-9]使用协同过滤的思想对Lin UCB算法进行改进:对用户和物品进行聚类,根据反馈调整这些聚类,并基于用户聚类来完成物品的推荐。在推荐的应用问题方面,Li等[6]提出的Lin UCB算法被应用于Yahoo的个性化新闻推荐,提高推荐多样性。Katzman等[10]提出的生存模型DeepSurv被应用于治疗方案推荐系统。
1.2 移动服务推荐
移动推荐利用终端的历史行为信息以及Web服务自身属性为终端推荐他有可能感兴趣的服务。与一般场景下的推荐系统类似,移动推荐主要包括协同过滤推荐、基于内容的推荐和基于数据挖掘的推荐系统及混合推荐系统等不同类型。其中,协同过滤推荐系统利用用户历史信息为用户建模进而做出推荐[11-12],基于内容的推荐系统通过构造物品画像,为用户推荐与过去满意的物品相似的物品[13],基于数据挖掘的推荐系统是将数据源进行处理[14-15],转化为知识后,进而为用户推荐。混合推荐系统则是综合采用以上方法来实现推荐功能[16]。
2 完全由终端集群组成的无线移动环境下的服务推荐方法
在算法设计的过程中,除充分考虑终端内Web服务选择的准确度和效率外,还应当兼顾终端间信息的传递效率。为保证信息在终端间传递的高效性,终端内Web服务的推荐应具有较低的时间和空间复杂度。
本文涉及的服务推荐的主要依据是评分矩阵S,本模型将使用各种手段,根据各种数据(例如服务的属性、终端对推荐的反馈等)生成或修正终端m(m=1,2,…,M)对服务n(n=1,2,…,N)的评分smn,并根据评分作出推荐。服务推荐算法的流程如图1所示。
2.1 初始评分的计算
在模型刚刚建立时,每个服务的评分数据是极为有限的,这时需要充分结合服务的属性对评分进行扩充。但是,服务的属性和其评分间的关系较为复杂,使用轻量级模型拟合效果难以令人满意。但是可以肯定的是,一般情况下,用户对相似的服务的评分也比较相近。因此,我们考虑使用相似服务的评分对缺失数据进行扩充。
首先,需要明确服务相似度的计算方法。我们使用服务的语义相似度来描述服务的相似程度:每个服务都有一段文本描述信息,服务之间的相似度就是这段描述信息的语义相似度:首先使用HanLP工具对服务描述信息进行分词并计算其词向量vi(i=1,2,…,N),那么服务i和服务j的服务相似度dij=vi·vj。
计算完相似度后,即可进一步计算扩充的数值。设第i个服务和第j个服务(i,j=1,2,…,N)之间的相似度为dij,特定终端t(t=1,2,…,M)已给出评分的服务集合为St。如果i∈St,则无须进行任何操作;而如果i∉St,则需要使用终端t对其他服务的评分估计其对服务i的评分,计算公式为:
(1)
式中:η为相似度的阈值,也就是说当服务j和服务i的相似度过低时,服务j的评分不参与服务i的评分的估计。如果计算过程中发现式(1)的右端为0/0,即终端t未对除i以外的其他相似服务给出评分,则sti的取值为所有终端产生的所有评分的均值。
2.2 评分的调整与更新——UCB算法
在初始评分已存在的情况下,推荐时就可以直接选择评分最高的服务。但这种方法存在一个明显的缺陷:部分服务在初始化时利用的评分信息很少,其评分等于或接近于所有终端产生的所有评分的均值,导致这部分终端在推荐时很难被选中,由此埋没了部分潜在的适合服务。为了解决此问题,本项目使用强化学习算法对评分进行适当的调整。
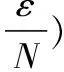
UCB算法基于两个观测:
观测1如果一个服务已经被推荐了k次(获取了k次反馈),该服务的评分:
(2)
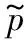
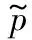
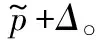
下面开始计算真实得分和估计得分之间的差值Δ。从直观上看,对于被选中的服务,多获得一次用户的反馈会使Δ变小,最终会小于其他没有被选中的服务;对于没被选中的服务,Δ会随着轮数的增大而增大,最终会大于其他被选中的服务。
为了定量地计算Δ,需要使用如下假设:
假设1Chernoff-Hoeffding Bound假设[17]假设reward1,reward2,…,rewardn是在[0,1]之间取值的独立同分布的随机变量,用式(2)表示样本均值,用p表示分布的均值,那么有:
(3)
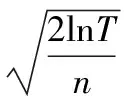
(4)
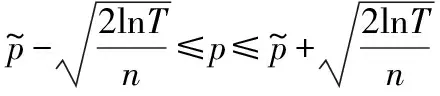
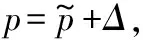
(5)
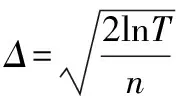
2.3 服务的选择策略
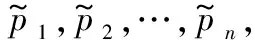
(6)
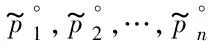
2.4 算法流程
对于每个终端,都使用一套独立的UCB算法,算法流程为:
输入:服务数N,各个服务推荐的次数T,评分矩阵R。
输出:推荐的服务target。
fori=1 toNdo
if 当前终端未对第i个终端进行评分 then
当前终端对第i个终端的评分ri=average(R);
end if
end for
fori=1 toNdo
end for
fori=1 toNdo
end for
采样target~p(prob1,prob2,…probN);
returntarget
推荐算法完成后,需要请发出推荐请求的终端给出评分,以作为反馈数据更新算法。如果数据集中已经包含了对服务的评分,则可以使用评分进行预训练。
2.5 分析和讨论
以上使用了UCB算法解决了服务的推荐问题,一个显然的问题就是它的合理性。事实上,在强化学习中,当明确状态空间、动作空间,而不明确状态转移空间时,存在着许多可行的算法。与UCB比较相似的是LCB算法,另一个比较常用的算法是策略梯度算法。下面将这两种算法与UCB算法进行比较和分析。
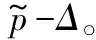
对于策略梯度算法,一般来说,它相比UCB算法更加复杂、精巧,在许多场景下有广泛的应用。具体来说,它的优势主要体现在三点:第一,使用了随机策略,这也就是说在其他条件完全一致时,推荐结果仍具有随机性而不是唯一确定,这种特点运用在推荐系统中可以使推荐结果具有多样性,增加推荐的惊喜度,但是在本文的应用场景中,节点充当了用户的角色,而非真实的人,所以对惊喜度的需求并没有商品推荐高;第二,推荐结果随参数的变化是连续的,在UCB中,参数的微小变化如果引起了得分的最大值不同,则会导致结果发生突变,但是与上文关于LCB的分析类似,本场景中的推荐是一个长期的过程,并不需要模型迅速收敛,所以策略梯度在这一点上优势也不明显;第三,可以表示连续动作,而在本场景中,推荐服务的行为是一个离散的动作,所以从这个角度看,策略梯度的优势也无法发挥。结合策略梯度中由于涉及神经网络而带来的复杂性,可以认为在本文的场景中使用策略梯度算法并不具有优势。
综合以上分析,可以看出在本文的场景中使用UCB算法是相对合理的。
3 实验与结果分析
3.1 数据集
本实验结合使用了数据集Book Crossing和Quality of Web Service(QWS)。其中,Book Crossing数据集由Cai-Nicolas Ziegler在2004年使用爬虫程序从Book-Crossing图书社区上采集得到,是Book-Crossing图书社区的278 858个用户对271 379本书进行的评分,包括显式评分和隐式评分,用户的年龄等人口统计学属性(demographic feature)都以匿名的形式保存并供分析。QWS数据集由Guelph大学的Eyhab Al-Masri对公网上Web Service状况进行数年研究后,使用Web Service Crawler Engine(WSCE)从UDDI、搜索引擎和服务门户网站中收集Web服务,并对这些服务的十几种QoS属性进行度量得到。
但是,标准的Book Crossing数据集还不能满足本项目的实验要求,需要对标准数据集进行处理加工。本实验中,终端数和服务数分别设置为100和100 000,所以从Book Crossing数据集中提取了部分读者和图书数据,提取时尽量选择评分较多的读者和图书。
在服务推荐的过程中,需要提供服务的相关属性用于计算服务间的相似度。而Book Crossing数据集图书数据的字段中并不包含这些字段,所以本项目为每个图书记录都补一个类别数据、一个短文本数据和一个标签数据。对于服务评价,需要由QWS数据集提供响应时间、可靠性等服务性能数据,但由于QWS数据集的记录数不足100 000条,所以本项目根据已有数据的规律人为生成模拟数据,对该数据集进行扩充,并给每个服务分别配上其中一条记录。
得到原始数据后,服务记录将随机放入不同终端中。
为了研究本文算法的适用范围,本文分别模拟了100个终端处于集中式、层次式和分布式集群结构下的算法性能。由于服务间具有较强的语义关系,因此本文采用SimBet算法与PROHET路由算法相结合,并以终端之间的相似度作为权重的通信策略。
3.2 评价指标的选择
本项目使用的离线评价方法为10次10折交叉验证法。首先把数据集中的所有评分数据随机均分成10份。然后将推荐算法运行10次,每次使用其中的9份数据建立模型,分别模拟每个终端发出请求,得出推荐结果。再使用剩下的1份数据评价推荐结果,如果算法推荐出的服务在剩下的1份数据中有相应的评分,则记录下此评分。最后计算所有记录下的评分的平均值,该评分越高表明推荐算法的效果越好。最终得到10次运行结果的平均值及标准差,其中平均值反映了推荐效果的整体好坏,标准差反映了推荐效果的稳定性。用本文设计的推荐方法和随机推荐方法分别执行10次10折交叉验证法,比较两者最终得到的平均值及标准差。
在上述算法中,将K取不同的值并进行重复实验,得到不同的评分平均值及标准差。最终可以绘制出评分平均值和标准差关于K值的曲线图并进行分析。
3.3 结果分析
本实验中,由于测试集数据过于稀疏,所以使用“统计测试集中所有评分在推荐系统模型中的UCB值,观察评分和UCB值之间的相关性”的方法评价推荐系统的效果。
统计完成后,分别在集中式、层次式和分布式三种体系结构的前提下,对测试集中已有评分的所有服务,作出用户真实评分关于服务UCB值的散点图,如图2所示。进一步计算两个变量之间的相关系数,三种体系结构下的结果分别为0.961、0.949和0.935,这表明用户真实评分数据和作为推荐依据的UCB值之间具有强相关关系。有理由相信,根据此UCB值计算出采样概率并最终采样服务推荐给用户,在很大程度上能保证推荐的准确性。
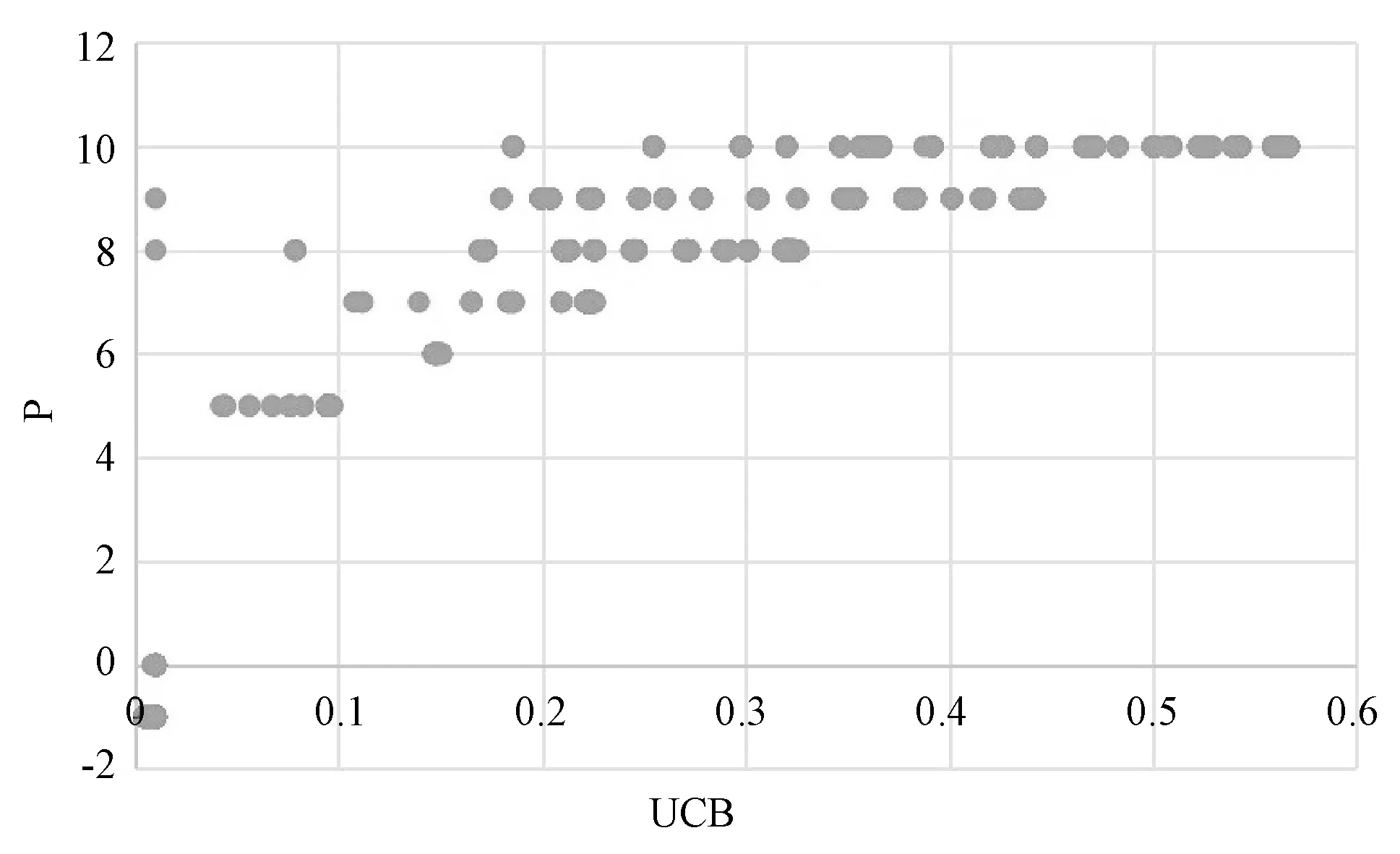
(a) 集中式结构
除此之外,在集中式、分布式和层次式3种结构下推荐花费的平均时间如表1所示(不考虑节点之间的通信时延),结果显示本文提出的推荐算法具有较高的性能,满足应用场景的需求。
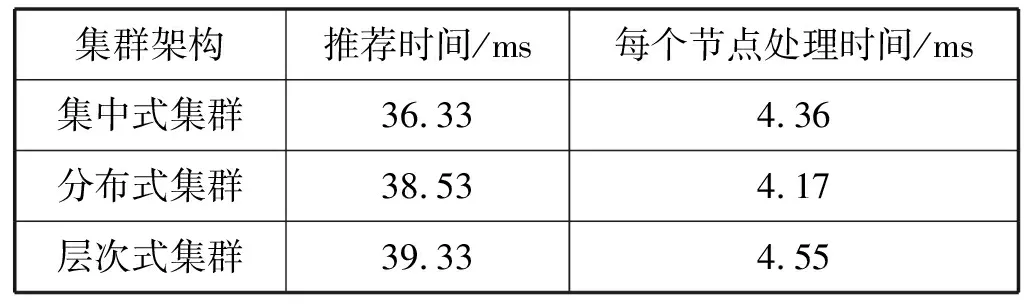
表1 实验结果
3.4 分析和讨论
本文算法的实际应用场景是由多个移动终端组成的集群,移动终端在计算能力、存储空间等方面均受到限制。本文提出的结合服务相似性的Bandit智能推荐算法对UCB算法进行了改进,并取得了良好的效果:
(1) 简化了算法计算流程,减少了算法的时间复杂度和空间复杂度:本算法仅需要保存各个服务的UCB值和2.2节式(5)中模型更新所需要的几个变量,算法的空间复杂度为O(N)(N为服务数量);如2.4节所述模型更新的时间复杂度为O(1)。在3.3节的实验结果方面在3种集群结构中本文算法的平均推荐时间花费均在50 ms以内也显示了算法的高效性。
(2) 结合服务的语义相似度这一特征来改进UCB算法最终得到的推荐结果表明用户真实评分数据和作为推荐依据的UCB值之间具有强相关关系。
4 结 语
本文以具体的无线应用场景为目标,分析总结了常见的推荐系统算法,提出结合服务相似性的Bandit智能推荐模型。该系统使用了强化学习中的UCB算法并增加了随机采样过程。该算法时间和空间复杂度较低,能适应无线移动环境下恶劣的通信条件。由于终端内部的推荐算法和终端间的数据传输策略相对独立,该算法的迁移也非常简单方便。本文通过实验模拟了场景中的终端在集中式、层次式、分布式体系结构下的服务推荐过程,推荐消耗的时间和推荐准确度令人满意。
本文提出的结合服务相似性的Bandit智能推荐模型更注重节点内部的Web服务推荐,节点之间的服务推荐采用SimBet算法与PROHET路由算法相结合的寻找策略。在未来的工作中,将考虑结合推荐的上下文环境和移动自组织网络结构的特点对节点之间的路由算法进行进一步优化。
