一种基于分层结构的设备故障领域本体实例关系抽取方法
2023-09-04葛天一杨长春陈延雪
葛天一 杨长春 陈延雪 周 婷
(常州大学阿里云大数据学院 江苏 常州 213016) 2(常州大学微电子与控制工程学院 江苏 常州 213016)
0 引 言
复杂设备系统各组成单元之间的关系错综复杂,存在各种关联耦合因素,因此导致其故障原因难以区分。基于本体的知识表示方法可以清晰地展现这种复杂的故障领域知识[1]。优质的设备故障知识本体需要本体实例之间拥有丰富而准确的关系。设备故障领域拥有大量相关文本,其中蕴含了大量的领域知识,可以满足设备故障领域本体实例关系抽取任务的需求[2]。
一个本体实例关系示例可以以三元组形式表达,即(eh,r,et),其中eh与et为本体实例,r为两实例之间的关系,本体实例关系抽取任务即为抽取出eh与et(后称目标实例对)之间的关系r。从领域相关文本中可以较深入地挖掘领域知识,抽取本体实例关系,构建质量较高的本体[3]。传统的基于人工标注的实例关系抽取方法花费的时间、人力成本过高。目前,使用神经网络模型从非结构化文本中进行实例关系抽取的方法得到了一定的成果。这类方法先定义需要抽取的实例关系,并使用神经网络训练一个关系分类模型,将包含目标实例对的句子的特征作为模型的输入,得到句子中目标实例对的关系,进而通过统计等方法,完成实例关系抽取。
尽管先前的研究已经取得了一定的成果[4-7],但使用神经网络模型,从非结构化领域文本中抽取故障领域本体实例关系仍然面临着一些挑战:当前研究普遍使用单层的神经网络多分类器进行实例关系抽取,同时也没有考虑到运用领域本体自身的语义信息,容易将意思相近的关系误分。同时设备故障领域文本的句子通常比在一般领域的句子要长,因此,目标实例之间的距离往往也较长,获取目标实例对之间的关系需要较丰富的句子结构信息,因此使用传统分析方法获取间隔较远的实例间的关系较为困难。
本文提出了一种基于分层结构的设备故障领域本体实例关系抽取方法,从非结构化文本中抽取实例关系。在第一层,结合领域本体自身的知识,通过识别目标实例对中实例所属的类别,为目标实例对匹配可能的关系,有效解决因无法识别实例类型带来的关系误分的问题;在第二层,使用预先训练的基于神经网络的关系分类器,对目标实例对进行精确关系抽取,在基于神经网络的关系分类器中使用结合自注意力机制的双向长短期记忆网络(Bidirectional Long Short-term Memory,BiLSTM)对目标实例对所在句子进行编码,以获取更多的句子结构信息,改善了间隔距离较长的实例之间关系抽取效果,最终通过统计的方法完成实例关系抽取。本文提出的方法能够有效提高设备故障领域本体实例关系抽取的效果,进而提高构建的故障领域本体的质量。
1 相关工作
1.1 设备故障知识本体
本体是对概念形式及概念间关系的一种规范、明确的定义[8],利用本体表示设备故障领域知识的方法目前取得了一定的成果[9-12]。文献[9]通过七步法构建了装载机故障领域本体,结合推理规则进行故障分析。文献[10]使用语义网技术收集机床故障诊断知识,并将其导入在线平台以构建不同机床的故障知识本体,提高了知识集成的效率。
OWL语言是一种本体描述语言,它具有描述类和属性的强大语义能力[12]。本文使用OWL语言中的OWL DL来描述设备故障领域本体,同时采用Protégé软件来最终构建并展示设备故障领域本体模型。
1.2 基于神经网络的实例关系抽取方法
在领域本体的构建过程中,实例关系的抽取效果很大程度上决定了该领域本体的质量。目前,在基于非结构化文本的关系抽取的工作中,很多研究使用一个单层的神经网络关系分类器,将句子作为输入进行关系抽取。文献[13]通过将句子的句法依存信息添加至深度神经网络模型,抽取医疗领域实例关系。文献[14]根据中文语义中主要以词为基本单位的特性,使用基于全词掩模的双向变形编码器卷积神经网络模型来提升在中文心血管疾病领域语料中进行关系抽取的性能。文献[15]开发了一个BO-LSTM(Biomedical Ontologies LSTM)模型,它从现有的生物领域知识库提取目标实例对的背景信息,将背景信息与句子结构信息一起加入LSTM模型,以抽取文本中的生物领域实例关系。文献[16]使用了结合注意力机制的神经网络模型获取包含目标实体的句子结构特征,来进行实体关系抽取。
然而,在实际使用传统的基于神经网络模型的方法抽取本体实例关系时,容易将意思相近的关系误分。在本体实例关系抽取任务中,很多意思相近关系的误分情况是由分类器无法识别实例类型引起的[17]。如关系“SameLevelFaultMode”描述两个故障模式类实例之间是同一层级关系,“SameLevelEquipment”描述两个故障组件类实例之间是同一层级关系,这两种关系表达的意思相近,但是各自连接的实例类型不同,在现有的模型中容易被混淆。同时,由于设备故障领域文中的目标实例对之间的距离往往较长,传统的RNN(Recurrent Neural Networks)和CNN(Convolutional Neural Networks)无法得到句子中每个词对输出的影响,因此使用传统的方法获取的句子结构信息不能满足设备故障领域实例的关系抽取。文献[15]在解决实例长距离问题方面取得了良好的效果,但是需要高质量的外部知识库,在本文的研究中难以满足此要求。文献[16]考虑到了句子中每个输入对模型输出的影响,但是,文中制定的注意力机制的查询向量仅仅考虑了句子中待抽取实体的特征向量,忽略了句子中其他词汇之间的关系,获取的句子的内部结构信息并不充分,因此不能有效捕获长距离的实体之间的关系。
近期,分层结构(Hierarchical Structure)在处理多分类任务中,取得了一定的进展。文献[18]提出了一种基于深度卷积神经网络的下水道缺陷检测和分类方法,使用采用分层分类的思路,高层检测任务试图从正常图像中区分出有工程缺陷的图像,低层次分类计算每个缺陷出现的概率。该方法解决了数据不平衡带来的工程缺陷图像分类困难的问题。文献[19]针对有些图像类别比其他类别更难区分的问题,提出了HD-CNN(Hierarchical Deep CNN)模型,使用简易分类器来分离能简单识别的图像类别与识别困难的图像类别,接着使用高性能分类器来专门区分识别困难的图像类别。
自注意力机制是一种改进的注意力机制。传统的注意力机制无法获取输入句子中各个词语之间的联系,而自注意力机制通过计算句子中每个词之间的相似度,可以更容易地捕获句子中词与词的依赖关系,更好地获取句子内部特征[20]。基于分层结构的思想,本文提出一种基于分层结构的设备故障领域本体实例关系抽取方法,从非结构化文本中抽取实例关系。在第一层,根据领域本体自身的知识(本体类别与实例关系的定义域、值域),通过识别目标实例对中实例所属的类别,为目标实例对匹配可能的关系,进行初步的关系抽取,有效避免意思相似关系的误分问题;接着在第二层通过结合自注意力机制的BiLSTM神经网络模型进行精确分类,改善间隔距离较长的实例的关系抽取效果,最后通过统计的方法完成实例关系的抽取。
2 研究方法
本文的研究框架如图1所示。(1) 预备工作指明确待构建领域本体的和基础概念类别与类别的层次,结合领域专家指导,为每个概念类别添加相应的实例,制定待构建领域本体实例关系;(2) 输入待处理的相关文本,完成文本的预处理;(3) 通过基于分层结构的实例关系抽取方法,进行设备故障领域本体实例关系抽取,第一层识别目标实例对中实例的类别,进行初步关系分类,第二层使用基于神经网络模型的方法,结合统计完成实例关系抽取;(4) 形成最终本体。接下来,本文将详细介绍该方法的实施过程。
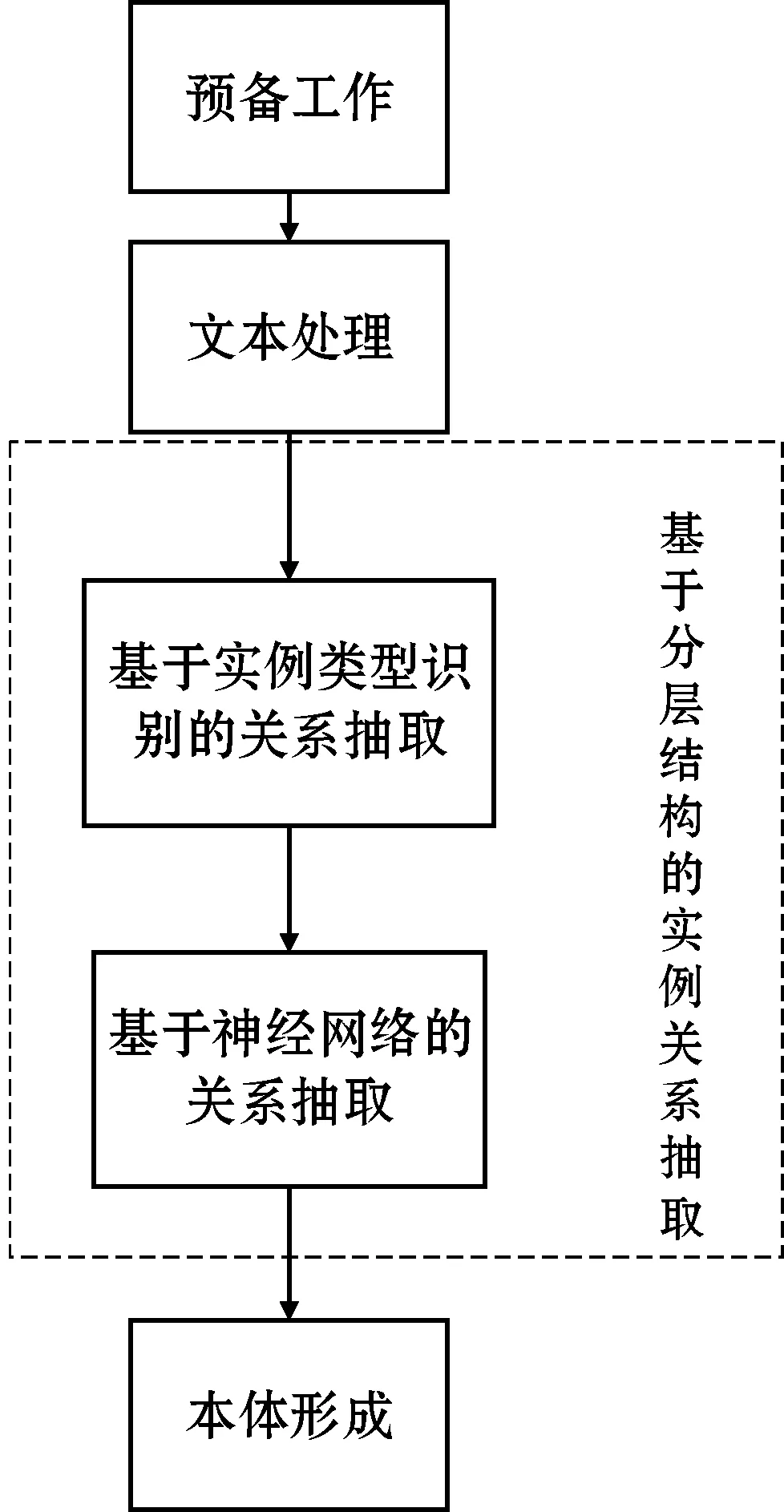
图1 本文研究框架
2.1 预备工作
待构建的设备故障领域本体主要描述设备的故障知识。一种故障现象可能不是由一个故障原因引起的,低层级组件的故障不仅会使同一层级的组件产生故障,还会引起更高层级组件的故障。因此,为了处理设备故障知识的复杂性,故障诊断本体模型主要定义了五个类:故障模式、故障组件、故障处理方法、故障现象和主要故障参数。根据文献[9],本文将设备结构由高层到底层分为设备级、系统级、模块级和子模块级4个层级。由于故障模式是发生在相应的故障组件上的,故障模式也需要按上述4层进行分类。因此故障模式类、故障组件类需要进一步各自添加“设备级”“系统级”“模块级”和“子模块级”4个子类。图2为设备故障领域本体的类与类的层次图。同时,本文结合领域专家的指导,为每个概念类别添加相应的实例。
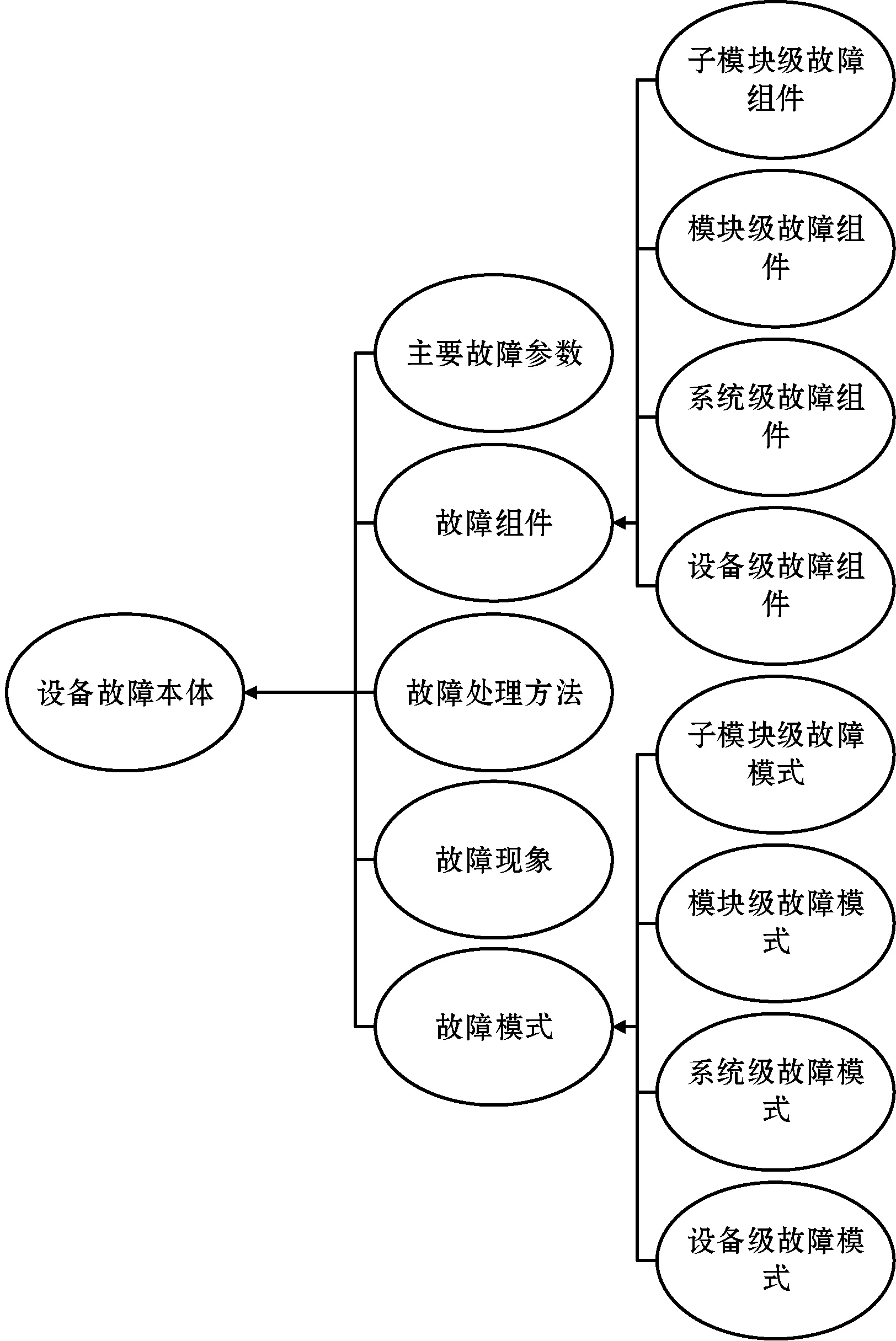
图2 故障领域本体类别层次图
领域本体实例之间的关系(即Object Properties,实例对象属性)指将实例关联到实例的属性,每个实例关系需要定义定义域(domain)与作用域(range),一个本体实例关系的定义域与作用域指向固定的本体类,实例关系起到将其定义域类的实例连接到其作用域类的实例的作用。本文为设备故障领域本体制定了以下实例关系(见表1)。编号1和编号2的实例关系描述故障组件之间的层级关系,如多个低层次组件可以构成一个高层次组件,则这些低层次组件与高层次组件就有“HighLevelEquipment”关系,低层次组件之间可以添加“SameLevelEquipment”关系。编号3和编号4的实例关系描述故障模式的层级关系,如一个高层次故障模式可由数个低层次故障模式引起,那么这个高层次故障模式与低层次故障模式之间就有“HighLevelFaultMode”关系,这些低层次故障模式之间关系为“SameLevelFaultMode”关系。编号5的实例关系描述故障模式引起故障主要参数变化。编号6的实例关系描述故障组件对应的故障参数。编号7的实例关系描述故障模式拥有相应的故障现象。编号8的实例关系描述故障模式能被相应故障处理方法解决。编号9的实例关系描述故障模式发生在相应的故障组件。编号10的实例关系描述故障组件会发生的故障现象。
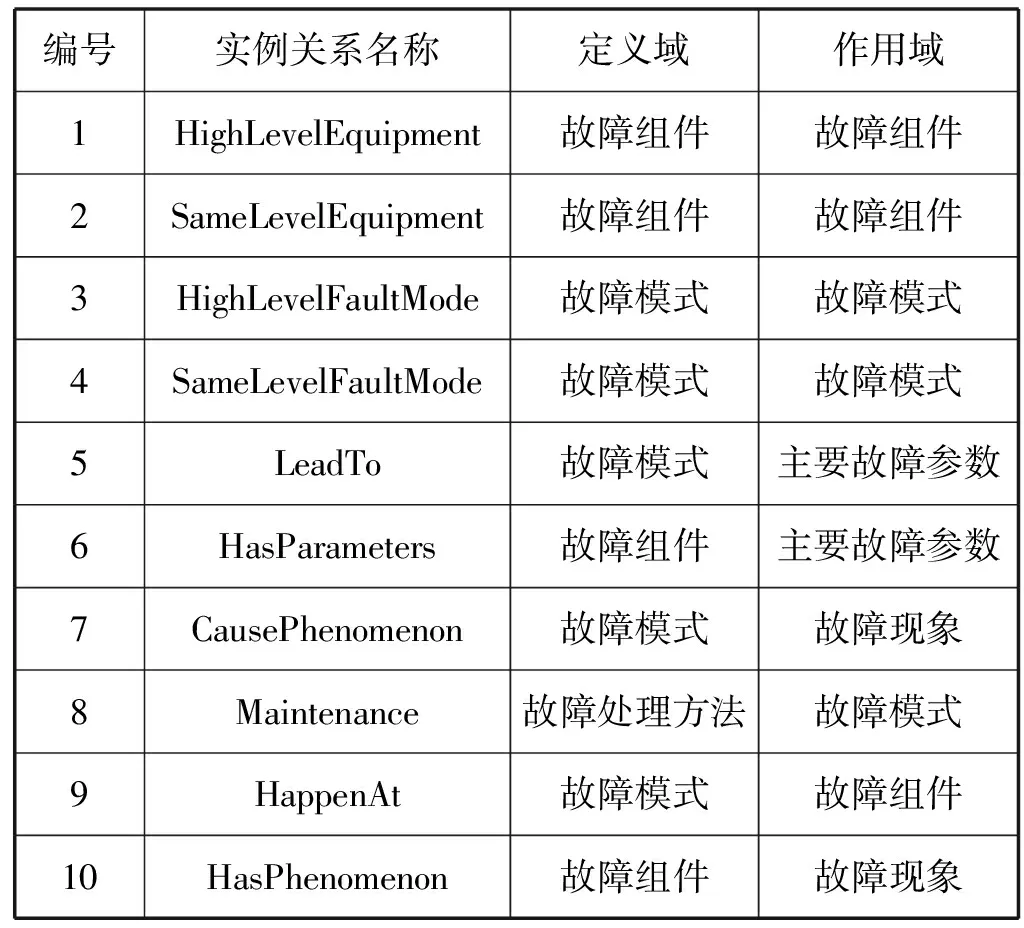
表1 设备故障领域本体的实例关系
2.2 文本处理
实例关系抽取任务需要的相关文本主要来自于互联网或相关制造商公开的电子文档,主要为设备结构说明书、故障分析手册和FMECA(Failure Mode, Effects and Criticality Analysis,故障模式、影响和危害性分析)报告等。这些资料包含丰富的领域知识,可以满足故障领域本体的构建需求。
文本处理阶段需要过滤掉无用的符号和单词。使用自然语言处理(NLP)工具用于解析输入文本中的每个句子。本文根据句子分隔符“。”“,”“!”等来分割中文文本。在获得单个完整的句子后,使用分词工具(Jieba)对这些句子进行分词、去除停止词、词性标注等工作。
由于相关文本中含有大量专业词汇,普通的分词方法可能会带来一定的错误。为了提高分词的准确性,本文将领域实例的名称总结为一个txt文件格式的中文领域词典,该词典能够直接导入分词工具(Jieba),以提高分词的准确性,保证之后实例关系抽取的质量。
进一步地,使用Word2vec工具训练分词后的词语集,得到各词语的向量化表示。
经过文本处理阶段,可以得到处理后的词语集合、词语向量化表示、分句后的句子集合。
2.3 实例关系抽取
本文的实例关系抽取由两个层次组成,第一层通过对目标实例对中实例类型进行识别,进行初步分类;第二层根据第一层的结果,选择相应的神经网络分类器进行判别,最终通过统计的方法完成实例关系的抽取。本文对每个针对实例关系训练一个基于神经网络的二分类器,以进行精确的关系抽取。选用二分类器可以满足实例关系抽取任务的灵活性,当有新的关系需要加入抽取任务时,可以通过添加新的二分类器来处理新关系。
2.3.1基于实例类型识别的实例关系抽取
在第一层,本文通过识别实例对中实例的类型,进行初步关系抽取。在本体实例关系抽取任务中,由于每个实例关系都有定义域与作用域,因此通过识别目标实例对中实例的类别可以解决很多意思相近关系的误分情况(如“HighLevelEquipment”与“HighLevelFaultMode”容易误分,“HighLevelEquipment”的定义域与作用域都指向故障组件类,而“HighLevelFaultMode”的定义域与作用域都指向故障模式类)。同时一些实例关系也只会在特定类别的实例之间产生,如关系“HighLevelEquipment”只能发生在高层级故障组件与低层级故障组件之间,即该关系只能发生在属于不同子类的故障组件类实例之间。因此通过识别目标实例对中实例的类别,可以得到目标实例对可能存在的实例关系。本文根据每个实例关系的定义域与作用域指向的本体类别,以及设备故障领域本体类别与类的层次,设计了如表2的关系模板,通过对目标实例对中两个实例所属的类别进行识别,进行初步的关系分类,接着自动地选择该实例对可能存在的实例关系所对应的神经网络分类器,进行下一层的精确分类。如识别到目标实例对(“后小齿轮组”“中间轴”),其中的两个实例都属于“模块级故障组件”类,因此选择“SameLevelFaultMode”关系对应的分类器进行第二层的精确分类。本文将实例一一配对,组成多个目标实例对。通过该分类方法,一个实例对之间最多存在一种可能的实例关系,即最多匹配一个神经网络分类器;实例对中两个实例的类型如果可以被模板匹配到可能的实例关系,则进入第二层的精确分类,如果无法被模板匹配,则直接判断这两个实例之间不存在领域本体中定义的关系。
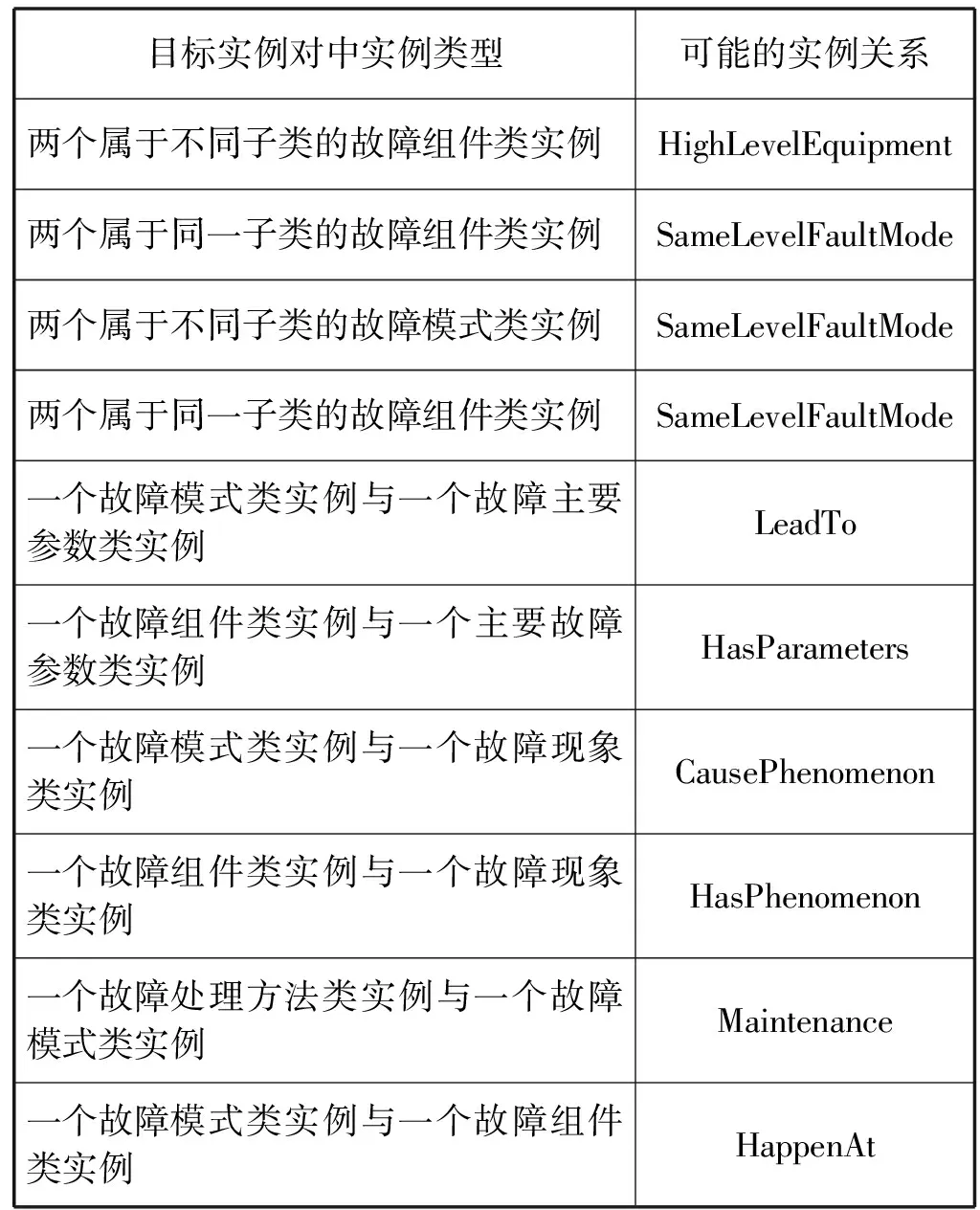
表2 实例关系模板
2.3.2基于神经网络的实例关系抽取
在第二层,本文为每个实例关系训练一个基于神经网络模型的二分类器,对进入第二层的目标实例对进行精确关系抽取。具体的,先找出所有包含该目标实例对的句子,针对每个句子,得到该句的局部特征,使用结合自注意力机制的BiLSTM模型对句子的局部特征进行分析,获取句子整体特征,通过句子整体特征得到该句子中目标实例对之间存在该分类器对应关系的概率,接着通过统计的方法,完成目标实例对的关系抽取。该部分的技术框架如图3所示。
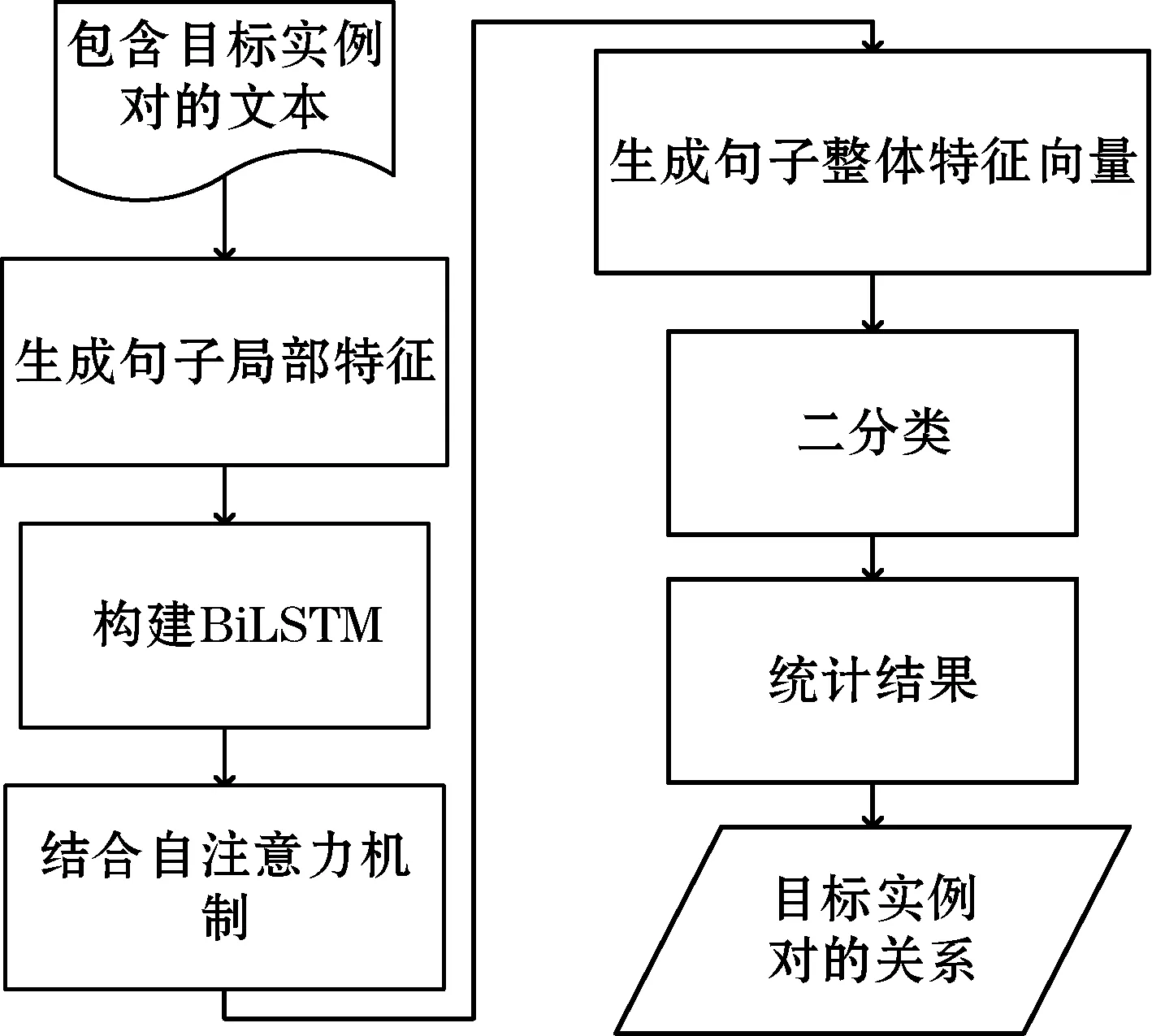
图3 基于神经网络的实例关系抽取技术框架
1) 句子局部特征。设待包含目标实例对的一个句子为:s(w1,w2…,c1,…,c2,…,wn-2),其中wi为句子词汇,句子中一共有n个词汇,c1、c2为目标实例对中的实例。为了获取句子的局部特征,需要对句子词汇进行向量化处理。在关系抽取的任务中,通常与目标距离越近的词语对抽取任务起着越重要的影响。因此,本文将句中词语与两个实例的距离与本身的词向量进行拼接,完成句子的向量化,得到句子的局部特征。如句子“电源过热导致系统主计算机死机”,有目标实例对的实例为c1“电源过热”与c2“主计算机死机”,词语“导致”与c1的距离为-1,与c2的距离为2,拼接后得到该句子的局部特征(见图4)。
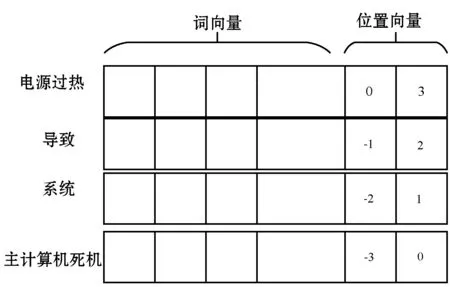
图4 例句局部特征
2) 构建BILSTM。LSTM模型可以批量处理向量化的文本信息。在单个时间状态上,LSTM的输入来自当前状态的输入xt和前一个状态的输出ht-1,以及上一个状态产生的历史信息ct-1。一个LSTM单元由三个控制门组成,分别为一个输入门i、一个输出门o和一个遗忘门f。一个LSTM单元的各状态特征值可以由式(1)~式(6)表示,w为各状态下的权值矩阵,b是各状态下的配偏置向量,σ为一个激励函数,见式(7)。
ft=σ(wf·[ht-1,xt]+bf)
(1)
it=σ(wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(wo·[ht-1,xt]+bo)
(5)
ht=ot·tanh(ct)
(6)
(7)
如图5所示,一个BiLSTM由前后双向的LSTM构成,弥补了前向LSTM无法编码从后到前的信息的缺点,因此其可以较为充分地获取句子中的上下文信息。句子局部特征S{x1,x2,…,xi,…,xn}作为输入,其中xi为向量化处理的句子词语,n为句子中的词语数量。如图5所示,输入前向LSTM得到的特征值记为L{L_h1,L_h2,…,L_hn},后向LSTM得到的特征值记为R{R_h1,R_h2,…,R_hn},最终得到的特征是将前向与后向LSTM得到的特征值拼接而成,即hi=[L_hi,R_hi],最终结果为H{h1,h2,…,hn}。
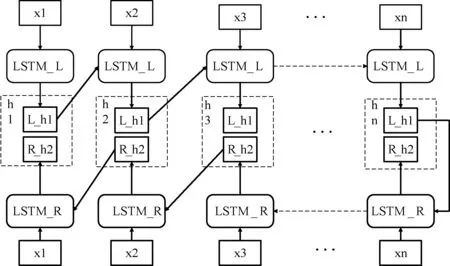
图5 BiLSTM网络架构
3) 自注意力机制。自注意力是一种改进的注意力机制,其使用一句句子中的每个词来和句中所有词计算相似度,在此条件下句中任意两个词语都可以捕获其之间的依赖关系,因此结合BiLSTM可以获取较丰富的句子内部结构信息,有助于抽取句中两个距离较远的目标实例之间的关系。自注意力计算公式如式(8)所示。
(8)
式中:Q为查询矩阵(Query Matrix),K为键矩阵(Key Matrix),V为值矩阵(Value Matrix),dk为矩阵的维度。Q、K和V通过把输入分别乘以三个矩阵Wq、Wk和Wv得到。
将BiLSTM模型输出的H作为输入,使用式(8)对其进行计算,进而得到句子的新的特征值,记为F={f1,f2,…,fn},句中第i个词语得到的新的特征值记为fi。
4) 二分类。将得到的句子特征F进行最大池化操作,得到最终的该句子的整体特征向量G。将G输入二分类器进行关系分类,存在该二分类器对应关系的可能性的计算方法见式(9),其中:P为该句中目标实例对存在关系的可能性,we为二分类器的权值参数,be为偏置向量。
P(G)=σ(we·G+be)
(9)
通过统计的方法完成最终的关系抽取,具体的,将每个包含该目标实例对的句子输出的可能性P进行累加,并取平均值,作为该目标实例对存在此二分类器对应关系的最终可能性,如果该值超过设定阈值β,则判断该目标实例对之间存在此二分类器对应关系,否则不存在。
本文采用梯度下降算法来优化模型,代价函数J(θ)计算如式(10)所示,其中:θ为模型中的训练参数,n为样本数量,yi为第i个样本的结果。
(10)
2.4 本体形成
此步骤主要功能是形成最终的目标本体。在实例间使用抽取到的实例关系进行关系扩展,形成最终的目标本体。
3 实验结果
本文以汽车变速箱故障知识为例,在实验过程中,首先从中国工控网、中国电子论坛等相关领域网站通过手动下载或半自动网页爬取等方法,收集有关变速箱的结构与故障维保方面的文章。为了建立训练和测试数据集,本文建立了一个的变速箱故障中文实例集。实例集中实例的类型仅限于变速箱的故障模式、故障组件、故障处理方法、故障现象和主要故障参数。本文为实例集中每个实例制定所属的领域本体类别,并在实例之间标注表1中制定的实例关系。本文将一款7AT变速箱的所属实例与实例之间的关系作为测试集。表3为该变速箱的部分实例。
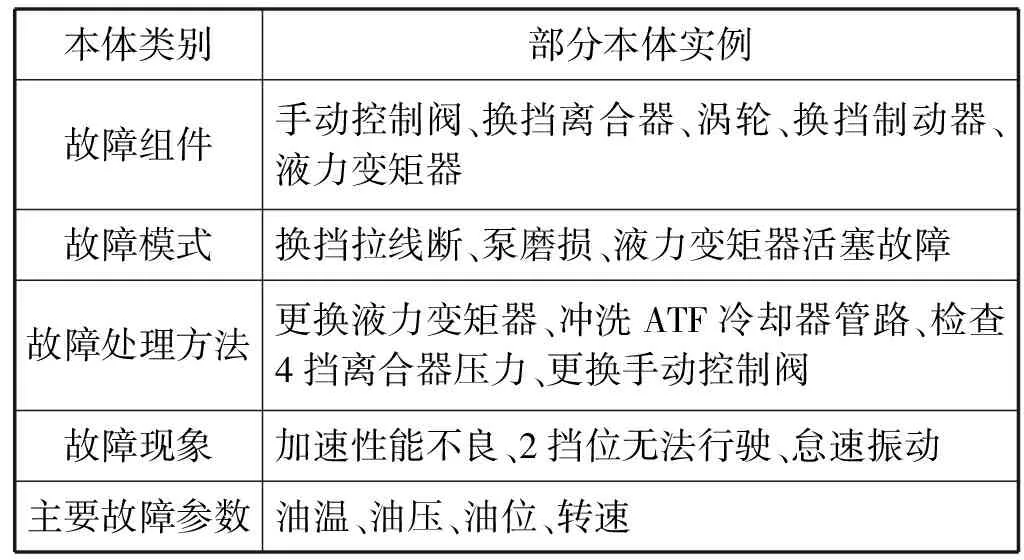
表3 某7AT变速箱部分本体实例
本文使用精确率P(Precision)、召回率R(Recall)和F1值来评估本文方法,计算公式如式(11)-式(13)所示。True 表示预测正确的数目,Output表示所有输出的预测数目,All_num表示测试集的数据数目。
(11)
(12)
(13)
在实例关系抽取任务中,词向量的维度设定为100,神经网络的隐藏层节点数目为280。训练轮数为500,批次大小为10,学习率设定为0.05,每个二分类器对应的值域各不相同(训练参数参考文献[17])。
本文使用一个基于自注意力机制的BiLSTM多分类模型作为对比方法之一,该模型(SaBiLSTM)用于检测第一层的基于实例类型识别分类方法的作用。针对第二层,本文引入LSTM与BiLSTM(HS_LSTM、HS_BiLSTM)作为对比方法,检测引入自注意力机制的BiLSTM的效果。总体实例关系抽取结果见表4,表5为本文模型在训练集中抽取的10类实例关系的结果,本文以实例关系“SameLevelEquipment”对应的抽取结果对比各种方法的效果(见图6)。可以看出,由于基于实例类型的识别分类方法可以预先为目标实例对排除无关的关系,以及能有效解决意义相近的关系造成的误分问题,因此相比传统方法(SaBiLSTM),本文提出的基于分层结构的关系抽取的方法可以在保证召回率的条件下,取得较好的精确率。LSTM与BiLSTM虽然解决了RNN的长距离依赖问题,但是,引入自注意力机制的BiLSTM(HS_SaBiLSTM)由于可以更好的获取句子的内部结构关系,效果更优。
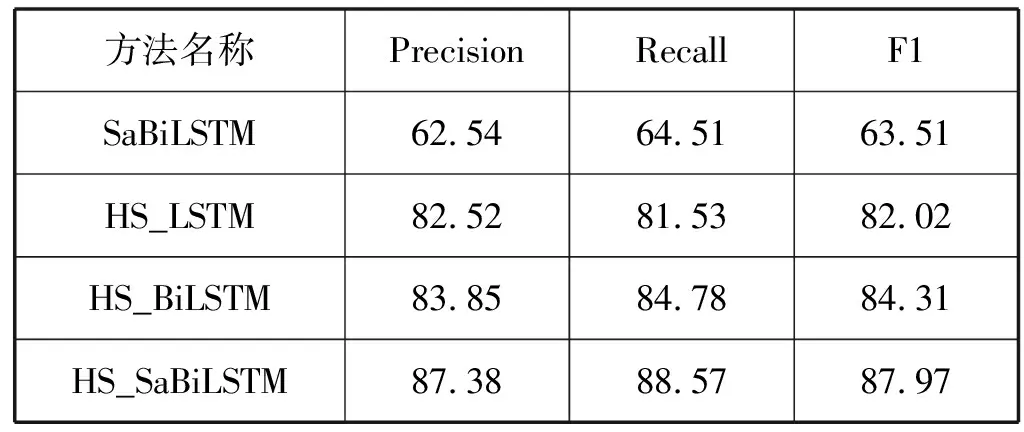
表4 4种方法在实例关系抽取的实验结果(%)
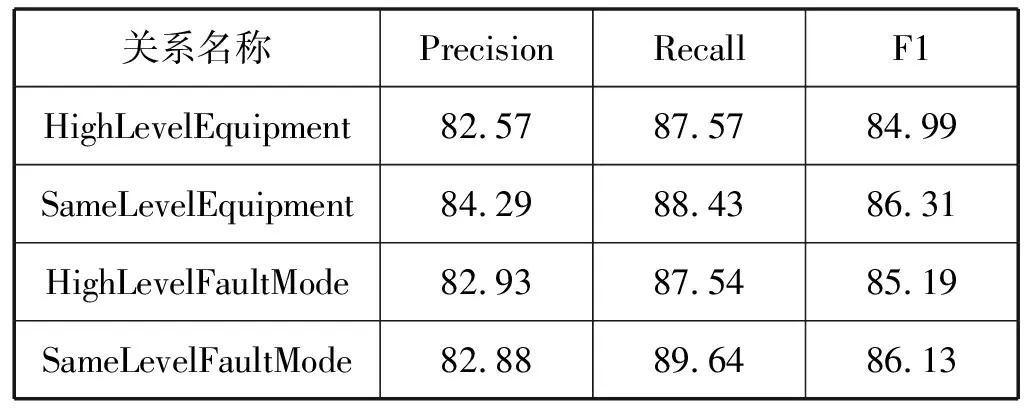
表5 10类实例关系的抽取结果(%)
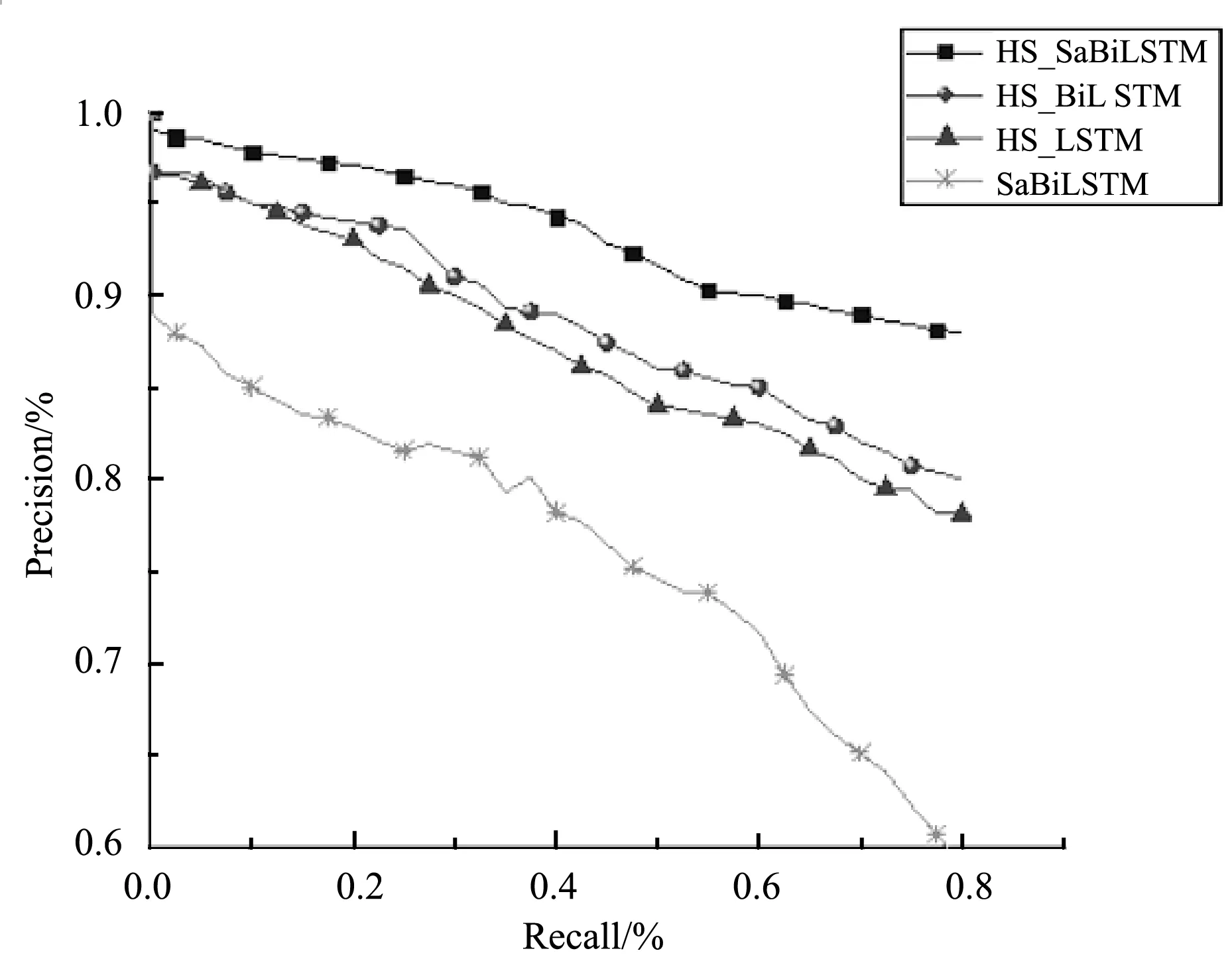
图6 4种方法抽取关系“SameLevelEquipment”的P-R曲线
使用Protégé5.2工具构建并展示最终的故障知识本体。图7给出了7AT变速箱故障知识本体的部分可视化展示。
图7 7AT变速箱故障本体的部分可视化展示
4 结 语
本文提出了一种基于分层结构的设备故障领域本体实例关系抽取方法,第一层使用基于实例类型的识别分类方法进行初步分类;第二层使用融合自注意力机制的神经网络模型对句子进行解析,通过统计的方法完成实例关系抽取。该方法有效解决了由于无法识别实例类型带来的关系误分问题,改善了故障领域文本中间隔距离较长的实例的关系抽取效果。
目前,本文的研究方法仍然存在一些不足,并且制定的实例关系较为简单。在以后的工作中,我们会进一步地融入snowball的机制,减少标注实例关系的成本,同时也需要引入更多的外部知识,进一步改善实例关系抽取的效果。本文的实例关系抽取方法取得了较好的效果,但仍需制定相应的推理规则,进一步验证该方法在基于本体的故障推理方法的效果。
