GM卫星测高数据海面时变校正程序的I/O并行优化研究
2023-09-02徐方正梁建国
傅 游,徐方正,梁建国
(山东科技大学 计算机科学与工程学院,山东 青岛 266590)
平均海平面(mean sea surface,MSS)是指相对于参考椭球在一定时间内的平均动态海面高,由平均海面地形和大地水准面两部分相加得到[1]。MSS在研究地壳形变、大洋环流、海洋重力计算[2]、大地水准面起伏确定和地壳形变[3]等问题中得到广泛应用,对地球科学和环境科学研究具有重要意义。
建立MSS模型面临的挑战是在有限的时间跨度内实现对时间海面变化的最精确滤波,同时获得最高的空间分辨率。通常结合来自精确重复任务(exact repeat mission,ERM)的数据与ERS-1、GEOSAT等早期的大地测量任务(geodetic mission,GM)测高数据实现[1]。校正GM数据中的海面时变信号时,需要读取大量的卫星轨迹数据文件[3],比如在构建日本海周边区域的平均海平面模型中对GM数据进行海面时变校正时,共使用了5颗卫星的GM卫星测高数据及其对应的ERM测高数据[4]。以Crystat-2卫星(2011.01.28—2019.12.12)为例,其GM卫星测高数据包含112个周期,总共92 669个轨迹文件。生成结果的精度和分辨率要求越高,I/O的数据越多,计算耗时和I/O耗时越长,必须利用并行计算技术进行加速。并行计算已在卫星数据处理领域发挥了重要作用[5-7]。在I/O性能优化方面,Schenck等[8]提出将突发式数据缓存使用快速存储介质作为缓冲区,将进程之间由I/O引起的负载不平衡降到最低限度,同时加快I/O的整体速度;Thakur等[9]提出的ROMIO使用双阶段I/O调度算法优化后的集中式I/O,尽可能对同一文件但不同数据段的多次访问进行合并以减少访问次数;Behazad等[10]使用遗传算法考虑影响I/O性能的各个参数,再进行全局空间搜索,从而寻找最优参数解;Chen等[11]使用遗传算法对并行I/O性能进行自动调优;Guedes等[12]针对运行在基于容器的服务器虚拟化集群上的I/O密集型应用进行研究,在虚拟环境下提供缓存服务,在大规模集群的存储文件系统中(如Lustre、通用并行文件系统和Panasas文件系统),将单个文件分为多个子文件存储在多个数据服务器上,通过服务器的并发来提高I/O效率。这些方法在一定程度上确实能减少I/O耗时,但不同程序具有不同I/O特征,要取得更好的I/O优化效果,必须针对具体程序进行分析,制订具体优化策略。
在全球平均海面模型的建立过程中,在Yuan等[13]研究基础上,开发了基于时空客观分析法的GM卫星测高数据海面时变校正的串行程序,完成了向高性能集群系统的移植。该串行程序读取的多源卫星总数据量约2 TB,输出数据约500 GB,总读取轨迹文件数约10 000万个。在CPU为Intel i7-10875H、内存16 GB的个人电脑上需运行约3个月,严重影响研究进度。而在完成高性能集群系统移植后,程序计算时间大大减少,但I/O作为系统性能瓶颈的情况并未改善,影响了系统可扩展性。
为了缩短I/O耗时,实现系统可扩展性,本研究从两方面对GM卫星测高数据海面时变校正程序I/O特征进行分析;为了提高I/O效率,提出按周期分配方案,并针对该方案可扩展性不佳、易导致负载不均衡的问题,提出一种合并再分配方案;使用消息传递接口(massage passing interface,MPI)文件视口函数对合并再分配算法进行优化,进一步提高I/O效率。
1 GM卫星测高数据海面时变校正程序
1.1 GM卫星测高数据的海面时变校正程序计算过程
以进行海面时变校正的GM卫星测高数据在相同时间跨度的ERM测高数据为参考基准,先将ERM测高数据的海平面异常(sea level anomalies,SLA)与GM卫星测高数据进行时空匹配,再进行海面时变校正,即可得到校正后的GM卫星测高数据。采用时空客观分析法进行GM卫星测高数据海面时变校正的关键是如何选取与待校正GM卫星测高数据在时间和空间相匹配的ERM测高数据并计算SLA。GM卫星测高数据海面时变校正串行算法流程如图1所示,图中左侧为ERM的SLA数据的筛选和计算过程,右侧为GM卫星测高数据的筛选和计算过程。
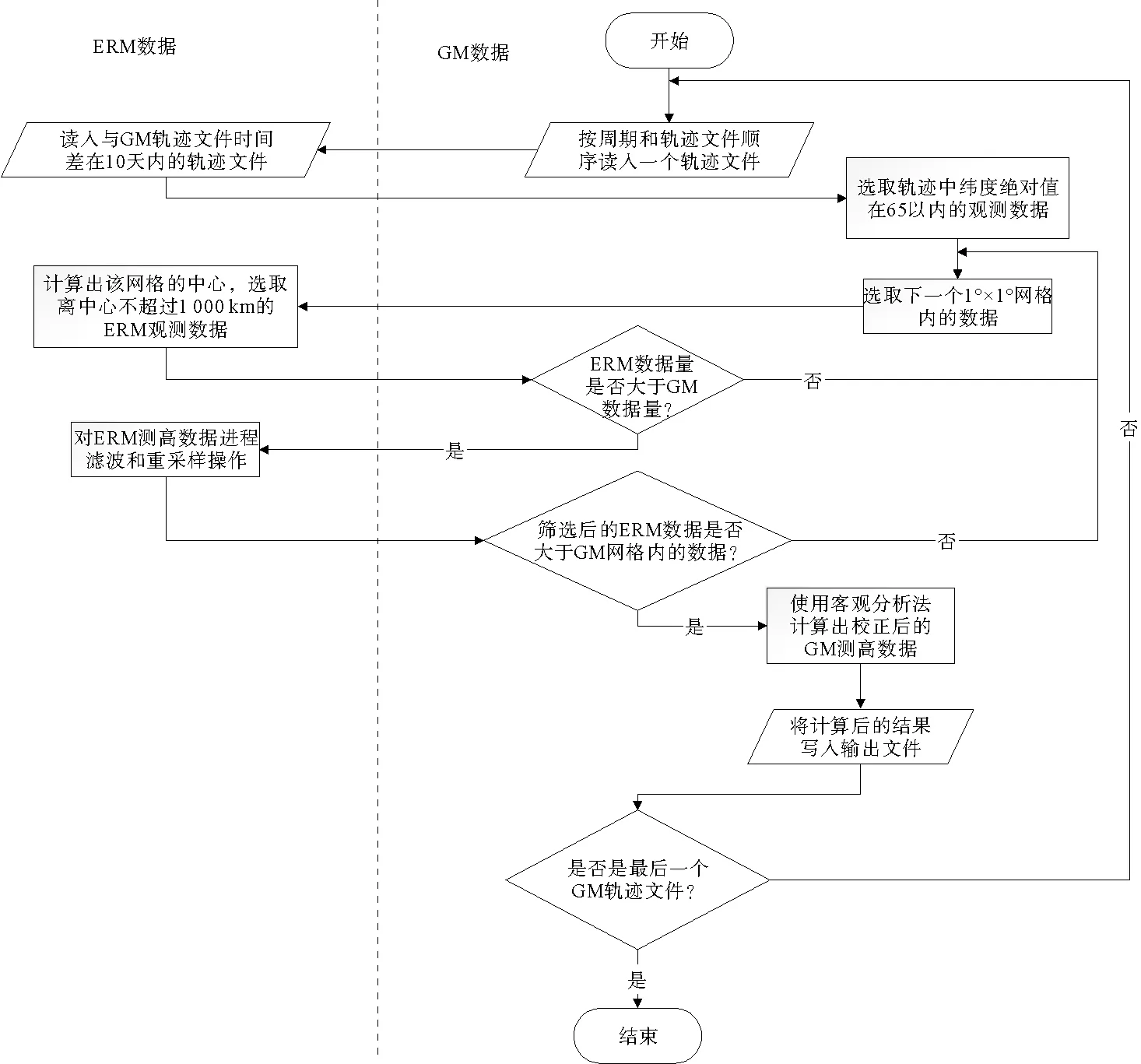
图1 串行算法流程图
1.2 GM卫星测高数据的海面时变校正程序I/O特征分析
在对原串行Fortran程序使用插桩法进行热点检测后,发现该串行程序读写文件耗时占比达80.44%,而数据计算部分仅占10.37%。若能优化程序的I/O部分,则该程序的整体耗时会大幅减少。
时空客观分析法的特征是在考虑时空尺度的前提下,将沿测高轨迹的SLA数据格网化为规则的格网SLA,再对同时空范围内的GM卫星测高数据进行校正。GM和ERM卫星测高数据文件结构的特点是包含多个周期文件夹且每个周期文件夹包含多个轨迹文件,文件目录结构如图2所示。
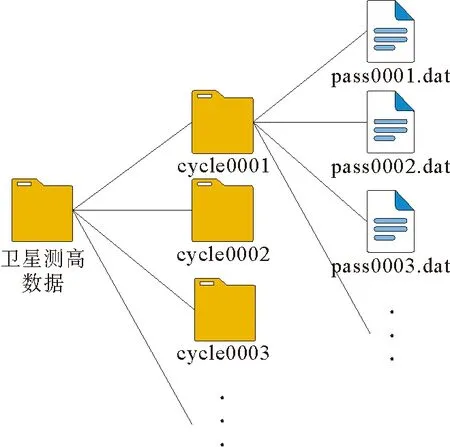
图2 卫星测高数据文件目录结构图
轨迹文件中以文本形式记录卫星测高数据,GM卫星测高数据和ERM卫星测高数据文件内容结构分别如图3、图4所示。图3和图4中,每一行代表一个观测点的信息,每一列代表一个属性,其他信息筛除。GM卫星测高数据的观测点信息属性包括观测时刻、经度、纬度、动态海面高、大地水准面和平均动态海面高,其中大地水准面和平均动态海面高在本研究的海面时变校正中未被采用,但在后续海面高建模中采用,因此未去除。ERM卫星测高数据包含时刻、经度、纬度和SLA。

图3 GM卫星测高数据文件内容结构图

图4 ERM卫星测高数据文件内容结构图
GM卫星测高数据海面时变校正程序I/O占比大的主要原因包括:①测高数据分布在数量繁多的轨迹文件中,如引言中提到的Crystat-2卫星包含92 669个轨迹文件,而对应的同时期ERM轨迹文件83 058个,共计175 727个轨迹文件;②读入GM卫星测高数据和查找时空对应的SLA数据过程中,需要多次读入不同文件,频繁切换文件句柄,切换频率约5 000次/s。每次完成一个观测点的计算均需要写入文件,每次写入的数据量仅48字节,输出文件时需写入约10 000次/s。可见GM测高数据时空客观分析法程序具有I/O密集型程序的特征,频繁的I/O导致程序运行速度受限于I/O带宽,无法充分发挥大规模集群中多核计算机性能。
2 GM测高数据海面时变校正时空客观分析法程序的I/O并行优化
2.1 按周期分配数据的并行方案
为了将该程序移植到高性能集群系统,实现多进程并行I/O,本研究提出一种按周期分配数据的并行方案。在该方案中,以一个周期的GM卫星测高数据为最小任务分配粒度,即每个进程处理整数个周期的GM卫星测高数据,尽可能把所有数据按周期数平均分配给每个进程进行计算,两两进程之间分配到的周期数差最大为1。设n为总进程数,T为总任务数,进程i处理的任务数为ti,
(1)
式中:/为取商运算,%为取余运算。
在多进程运行时发现,各进程运行时间会有较大差异。以10个不完整周期(包含约100个轨迹文件)的GM卫星测高数据为测试集,该方案并行程序分别开启1到10个进程的运行时间与加速比如图5所示,9进程时各进程运行时间如图6所示。
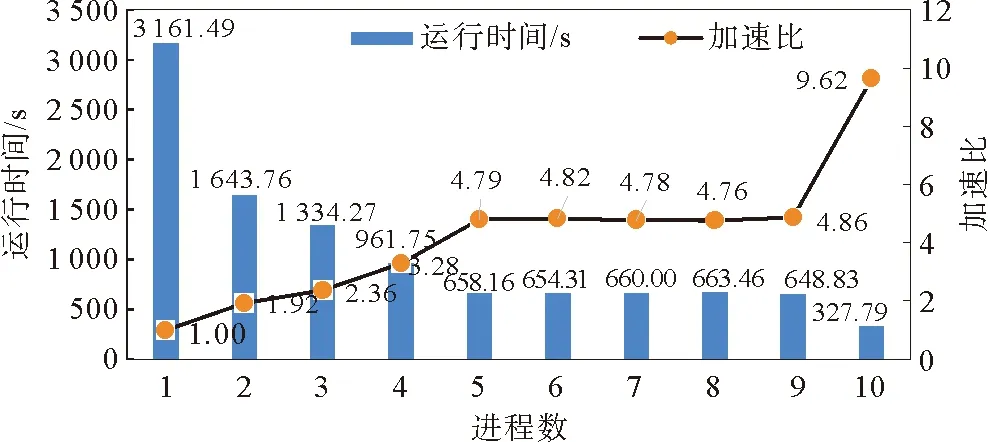
图5 并行程序运行时间与加速比图
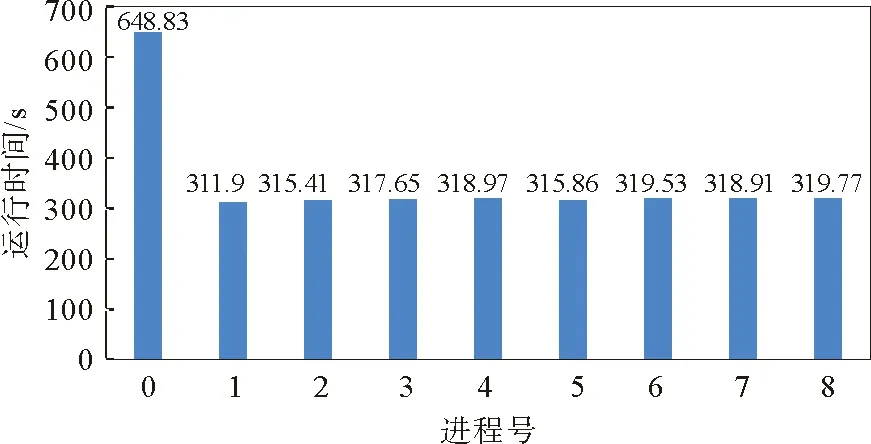
图6 并行程序9进程时各进程运行时间
由图5可以看出,当进程数由5升至9时,运行时间基本保持不变;只有当进程数为1、2、5和10时,加速比与进程数接近。由图6可以看出,0#进程的运行时间约为其他进程的2倍,产生了明显的负载不均衡。由式(1)可知,当T不能被n整除时,分配给各个进程的任务数不均等,任务差为一个周期的GM卫星测高数据校正任务。任务差越大,负载不均衡的情况越明显。由于GM卫星测高数据各周期的数据量不等,即使每个进程都分配相同数量的周期,实际的任务数据量差别也很大。除此之外,按周期分配方案的可扩展性不佳,能开启的进程数不能大于周期数。
2.2 合并再分配的并行方案
由1.2节中的数据文件结构分析可知,若将行数据均匀地划分给每个进程,需将所有文件的行数进行汇总,统计每个进程的行数。由于数据分布在多个轨迹文件中,在进行SLA数据匹配过程中依然存在频繁切换文件的问题,出现同一个轨迹文件数据被分配给不同进程的情况,降低任务分配的效率。为避免此类问题的发生,本研究提出合并再分配的并行方案。在实际的任务计算中,最小计算任务单位是一个GM卫星测高的观测点数据,即一行数据,若能以行为进程分配最小任务单位,可大大提高负载均衡程度。
合并再分配的并行方案将所有卫星测高数据和轨迹文件汇总为如图7所示的natt个属性文件。图7中,call_input表示的汇总文件总行数,即各进程需要读入的行数之和,ci_input表示进程i分到的卫星测高数据行数。将卫星测高数据汇总整合为数个文件,文件个数为需要测高数据中包含的属性数(如时间、经度、纬度等),并按时间顺序排序。ERM数据的汇总属性文件除了图4所示的4个属性外,每行数据还需要加上该观测点的周期号和轨迹号,以便于时空匹配。其中,
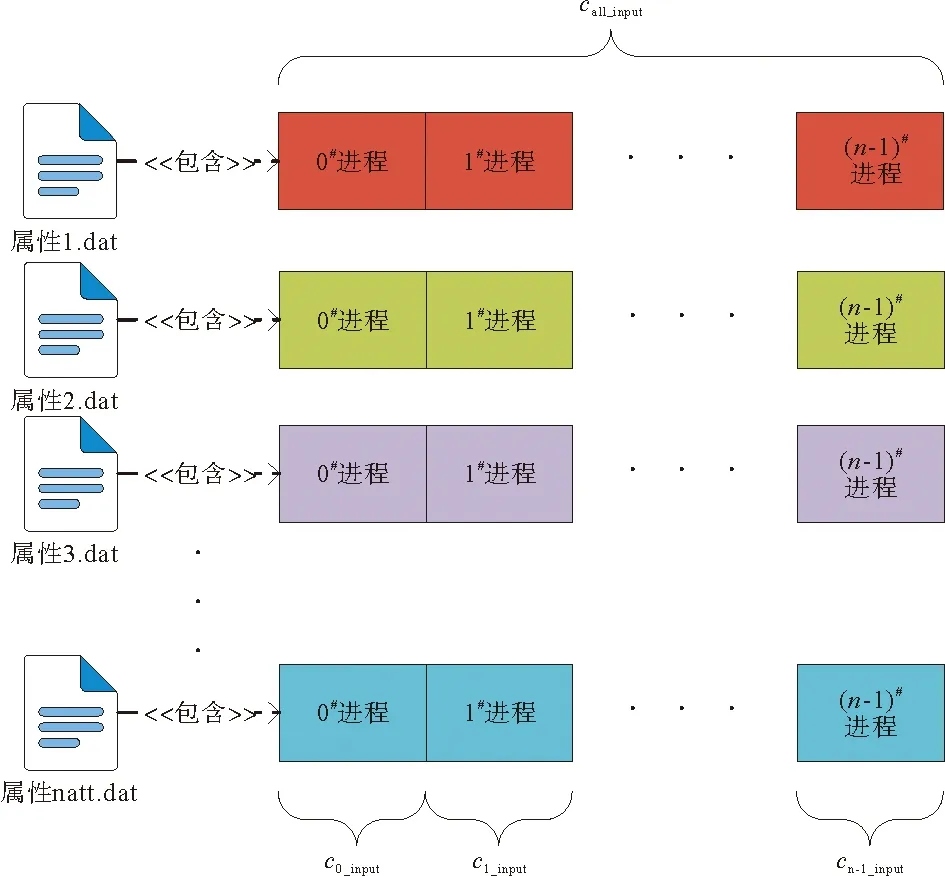
图7 合并再分配方案图
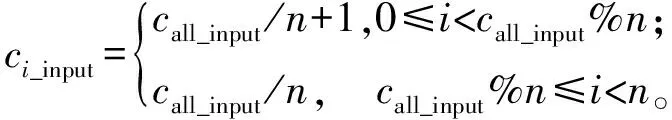
(2)
设进程i在汇总文件开始读数据的起始偏移量
(3)
各进程可以自行计算出ci_input和oi_input,无需通信。
基于合并再分配方案的并行GM卫星测高数据海面时变校正具体实现如算法1所示。

算法1 基于合并再分配方案的并行GM卫星测高数据海面时变校正算法输入:GM卫星测高数据gm_data,ERM卫星的SLA数据sla_data输出:校正后的GM测高数据result_data1: Begin2: MPI及其常用参数初始化,获取进程号i,进程数n3: 多进程读取sla_data的不同轨迹文件,并将其汇总为6个SLA属性文件4: 多进程读取gm_data,并将其汇总为6个GM属性文件5: 根据i和n确定本进程读取的gm_data在文件中的起始位置与长度6: 每个进程将本进程gm_data时间差在10天内的SLA数据读入内存7: 前6号进程读取sla_data并广播给所有进程,存入6个SLA属性数组8: end_line_gm_data←start_line_gm_data + my_gm_data_length9: for start_line_gm_data←my_gm_data_offset to end_line_gm_databy max_size do ∥每次循环取最多max_size 个观测点的GM数据,max_size为一次最多可读取观测点数,自行设置10: block_gm_data←read_gm_data_to_array(start_line_gm_data,max_size,end_line_gm_data)∥将本次循环要校正的gm_data读入内存11: for grid_gm_data in block_gm_data do ∥按顺序从当前的block_gm_data中选取1°×1°格网内的gm_data12: grid_sla_data←choose_sla_data(my_sla_data) ∥ 筛选距离网格中心不超过1 000 km的sla数据13: grid_sla_data←filter_sla_data(grid_sla_data) ∥ 进行滤波和重采样操作14: grid_result_data←objective_analysis(grid_sla_data,grid_gm_data)∥使用时空客观分析法计算出校正后的GM卫星测高数据15: block_result_data←add_result_data(block_result_data,grid_result_data)∥将当前格网的结果数据加入到当前周期结果数据16: end for17: write_block_result_data(block_result_data)∥将一个block的结果数据写入磁盘18: end for19: 0#进程将所有block的结果文件汇总为一个文件并输出20: End
2.3 利用MPI文件视口函数实现I/O并行加速
为了减少合并再分配时对文件汇总的耗时,利用MPI文件视口函数实现多进程I/O并行加速。MPI文件视口会给每一个进程定义一个独立文件指针,读写位置由当前文件指针确定[14],各进程可以同时读/写一个文件,互不干扰。
除了读/写的文件路径之外,每个进程在读/写前还需要获取自己在文件中进行读/写操作的偏移量和读/写的数据量。每个进程读操作的数据量依据进程数平均分配,并行读操作的文件起始偏移量可根据其进程号用式(3)计算得到。但是在并行写操作时,输出文件中的数据顺序需要与进程顺序保持一致,而每个进程写入输出文件的数据量并不相等,所以进程号大于0的进程进行写操作时的偏移量需由上一个进程传入。
各进程偏移量通信流程如图8所示。图8中,ci_output为i号进程需要向输出文件写入的数据行数,oi_output为i号进程在输出文件中的起始偏移量,
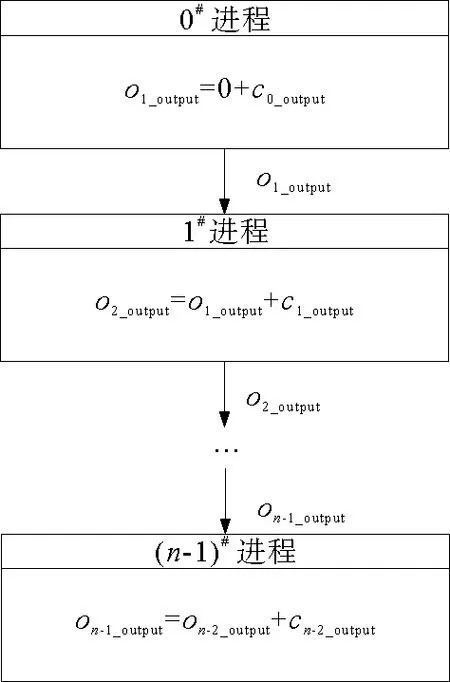
图8 写文件偏移量通信流程
(4)
所有进程的偏移量传输过程按进程号从小到大依序进行,在获得其输出文件的偏移量后,通过MPI文件视口输出函数将结果数据并行写入输出文件。
传统的主从并行方案(以下简称传统方案)中,往往只将计算任务并行化,输入数据时需要由主进程读文件并向从进程分发数据;输出数据时需要从进程向主进程发送数据,再由主进程写文件。并行I/O方法可避免主从进程间进行大量数据通信,理论上将读/写时间缩短为传统方案的1/n。
3 实验测试
3.1 实验平台
实验平台为17台多核计算机组成的集群系统,其中16台为计算节点,1台为管理节点。计算节点的整体配置相同,均包含2个14核Intel Xeon Gold 6132处理器和96 GB的DDR4内存。因实验平台使用多处理器计算(multi-processor computing,MPC)技术,每个核心可开启一个进程,可开最大进程数为16×28=448。实验平台软件环境如表1所示。

表1 实验平台软件环境
3.2 实验数据集
实验数据集来源于AVISO(archiving,validation and interpretation of satellite oceanographic data)发布的沿测高轨迹的Level-2+(L2P)SLA数据产品(以下简称L2P)。L2P包含多个卫星测高数据,实验使用其中的T/P、Jason-2和Cryosat-2测高卫星数据集。L2P中每个测高卫星均包含若干周期数据,每个周期数据中又包含若干轨迹数据,而每一个轨迹数据均包含了观测时间、纬度、经度、卫星轨道高度、卫星到星下点距离、SLA、平均海面高、有效数据标志以及各项误差改正项等。实验数据集对于GM数据,保留了观测时刻、经度、纬度、动态海面高、大地水准面和平均动态海面高;对于ERM数据,保留了观测时刻、经度、纬度和SLA,将该数据集称为大数据集。小数据量数据集系从L2P中按固定时间间隔抽选的文件得到。两组数据集的具体信息如表2所示。

表2 卫星测高数据信息表
3.3 实验结果与分析
1) 负载均衡度测试
为了验证合并再分配方案的负载均衡度的优势,使用小数据量数据集,收集了在单节点上开启6~10进程时,按周期分配方案和合并再分配方案的各进程空闲时间之和,结果如图9所示。
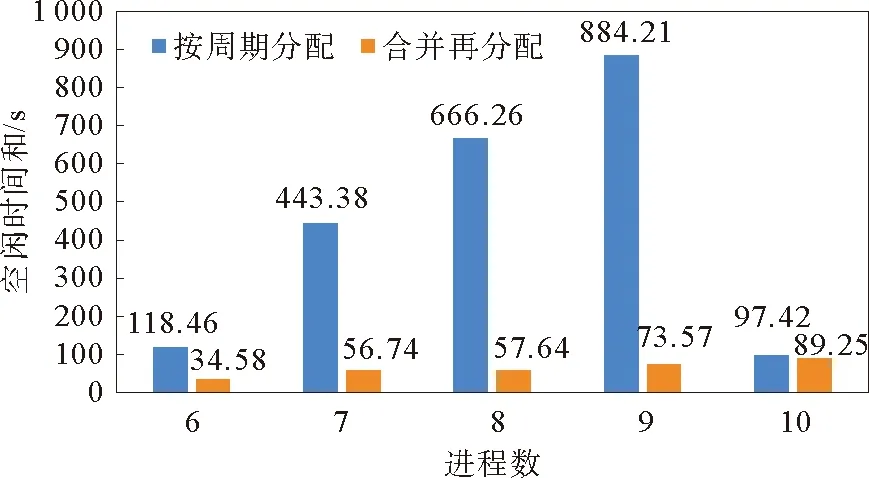
图9 多进程下不同并行方案进程空闲时间和
由图9可以看出,按周期分配方案的进程空闲时间之和,在6到9进程时随着进程数的上升而增加,而在10进程时大幅降低。这是因为10进程时,周期数刚好能被进程数整除。而合并再分配方案的进程空闲时间在6到9进程时远低于按周期分配方案,只有在10进程时相近,且随着周期数上升幅度很小,可见合并再分配方案的负载均衡度优于按周期分配方案。
2) 两种方案和I/O并行加速效果测试
使用原版串行程序利用小数据量数据集进行实验,耗时为1 027.89 s。
为验证两种并行方案以及I/O并行加速的优化效果,使用小数据集分别进行测试。小数据集包含10个周期,使用按周期分配方案时,若进程数超过10会出现闲置进程,故最大进程数不超过10。合并再分配方案中待匹配的ERM数据有6个属性(时间、经度、纬度、SLA、所在周期、所在轨迹),每个进程读入一个属性,故进程数至少为6。测试结果如图10所示。
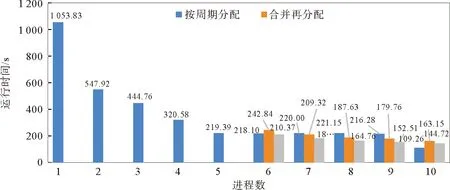
图10 多进程下不同并行方案运行时间
由图10可以看出,对比串行程序,按周期分配方案在单进程时耗时更长,是因为启用MPI需要耗时并且多了任务分配的步骤。6到9进程时,按周期分配方案的耗时基本不变,这是因为出现了任务分配不均,只分配到1个周期的进程需要等待2个周期的进程执行结束。
合并再分配方案在6和10进程时比按周期分配方案耗时更长,是因为分配任务的步骤更加复杂,当按周期分配方案中周期数可以被进程数整除或者余数很小时,按周期分配方案负载较为均衡,合并再分配方案的负载均衡优势没有体现出来。当进程数为7到9时,按周期分配方案的负载产生了很大的不均衡,耗时大于合并再分配方案。同时,I/O并行加速对于按周期分配方案也有一定的加速效果,在6进程时加速最多,缩短耗时32.47 s,加速13.4%。
3) 强、弱可扩展性测试
为了验证经I/O并行加速后的合并再分配方案的强、弱可扩展性,分别使用小数据量和大数据量数据集进行测试。
许多并行计算平台(例如高性能计算集群)能更高效地处理进程数为2的次方数的并行程序,这是因为此类平台通常使用硬件结构来组织二叉树或超立方体拓扑中的节点,使用2的次方数作为进程数允许进程自然映射到硬件拓扑中的节点,可以减少通信延迟并提高性能。因合并再分配方案的进程数不得小于6,故最小进程数设置为8。
小数据量实验组的加速效果如表3所示。表3中,加速比1由串行程序运行时间除以测试算例运行时间得到,加速比2由8进程并行程序运行时间除以测试算例运行时间得到,并行效率由加速比1除以进程数得到。由表3可知,运行时间在64进程时最短,为86.41 s,且加速比1为11.90,加速比2为1.91,但是并行效率最差,为0.19。并行效率在进程数为8时最高,为0.78。

表3 小数据量实验组加速效果
小数据量实验组中,在进程数达到16后,运行时间再无明显缩减,并行效率随着进程数的增加而减少。8进程到16进程加速比1和加速比2上升明显,但是进程数继续增加后,没有明显提升。原因是小数据量实验组的数据量较小,符合Amdahl定律,小数据量实验不具有良好的强可扩展性,难以体现出并行计算的优势。
大数据实验组中数据量大,最小进程数若设置太小会导致运行时间过长,并且可设置最大进程数为448,故设置并行运行的最小进程数为448的1/8,即56。表4为大数据量实验组的加速效果,加速比由并行程序56进程运行时间除以测试算例运行时间得到。

表4 大数据量实验组加速效果
由表4可知,运行时间随着进程数的每次翻倍,加速比的增长速度也接近翻倍,在进程数为448时最短,为9 283.84 s,加速比也在此时达到最高7.21,并且加速比的上升速率没有明显降低,说明该算法具有良好的强可扩展性。
分别以8和56为基准进程数,进程数增加为8倍后,大数据量实验组的加速比提升为小数据量实验组的3.78倍,这主要是因为数据量扩大后合并再分配数据的耗时占比更小了,可见该并行方法的加速比在随着数据量和进程数的增加而提升,也具有良好的弱可扩展性。
4 结论
本研究实现了时空客观分析法对GM卫星测高数据的海面时变校正的串行程序,分析了I/O密集型程序特性。使用按周期分配的并行方案对其进行并行化,提出合并再分配方案以保证负载均衡,并使用MPI文件视口函数进行I/O并行优化。实验结果表明:与按周期分配方案相比,合并再分配方案在多进程运行时耗时更少,并且在周期数不能被进程数整除时,负载均衡度更高,多进程可扩展性也更好;I/O并行加速可缩短合并再分配方案的运行时间;I/O并行加速后的合并再分配方案具有良好的强、弱可扩展性。后续工作可以进一步优化程序的协方差矩阵计算步骤,减少计算环节耗时。
