近红外光谱技术快速检测甜叶菊中绿原酸含量
2023-09-01未俊丰高伟程远欣吕兴娜吉桂珍石文杰
未俊丰,高伟,程远欣,吕兴娜,吉桂珍,石文杰*
1(晨光生物科技集团股份有限公司,河北 邯郸,057250) 2(河北省植物资源综合利用重点实验室,河北 邯郸,057250)
甜叶菊原产于南美洲高山草地,是菊科多年生草本植物,也是天然甜味剂的主要来源之一[1-2]。甜叶菊中含有丰富的功能性成分,如甜菊糖苷、黄酮类、绿原酸类等[3]。有研究表明,甜叶菊中的绿原酸含量可达到1.7%~7.2%,是绿原酸重要的来源之一[4]。绿原酸是一种重要的代谢物质,具有抗菌、抗病毒、增高白血球、保肝利胆、抗肿瘤、降血压、降血脂、清除自由基和兴奋中枢神经系统等作用,目前已成功应用于食品、饮料、保健、医药、日用化工等多个领域中[5-6]。
近红外光谱检测技术是一种操作简单、快速、绿色、可满足大批量样品检测的方法,已广泛应用在农业、医药、食品、工业等领域[7-8]。张楠楠等[9]应用近红外光谱技术对土壤盐分进行了分析,模型的交互验证残差均方根(root mean square error of cross validation,RMSECV)和相关系数分别为0.016 8和0.987 5,取得了较为理想的实验结果;张孝红等[10]利用漫透射近红外光谱对小麦面粉中的呕吐毒素进行了建模分析,模型的相关系数和均方根误差为0.876和0.21,识别准确率达到了90%;刘秋芳等[11]采用近红外光谱对石脑油分子组成进行了测定,建立了石脑油的族组成和单体烃分布比例预测模型,研究表明所建的模型的预测值与实测值吻合度高,预测准确性好。近红外光谱在甜叶菊检测中也有应用,汤其坤等[12]研究了使用近红外光谱技术直接扫描甜叶菊干叶片,建立了甜菊苷和莱鲍迪苷A的检测模型;高乐乐等[13]研利用近红外光谱分析技术结合化学计量学方法对甜菊糖吸湿过程进行表征、解析,从而揭示吸湿过程中水的吸附方式和键合作用;通过吸湿过程光谱并采用外部参数正交算法消除样品中水分的影响,建立甜菊糖中莱鲍迪苷A含量的快速分析方法。目前甜叶菊中绿原酸含量的测定主要是通过高效液相色谱法,该方法虽然结果较为准确,但是其操作复杂繁琐,分析时间较长,成本较高,难以满足大批量样品的测定[14]。因此需要一种新的快速检测方法,用来测定绿原酸含量。张苹苹等[15]基于漫反射近红外光谱法建立了甜叶菊中甜菊糖苷、绿原酸和水分的模型。但研究中未对光谱预处理和特征光谱选择方法的深入研究和探讨。本研究利用近红外光谱技术,对144个甜叶菊样本原始光谱进行了不同方式的预处理,随后使用多个波长选择算法提取特征波长,最后采用偏最小二乘法建立预测模型进行比较,对近红外检测绿原酸的光谱处理和波长选择进行了比较和研究,以期为近红外检测检测绿原酸过程中光谱预处理和特征波长选择提供参考。
1 材料与方法
1.1 样本收集
收集不同品种、不同种植地区的154个样本(包括甘肃、新疆、内蒙、河北等产地,包括普兴1号、普兴3号、普兴6号等品种)。
1.2 仪器与设备
波通 DA7250型近红外分析仪,波通瑞华科学仪器(北京)有限公司;安捷伦1260液相色谱仪,安捷伦科技(中国)有限公司;CLF-02100克密封形手提式中草药粉碎机,温岭市创力药材器械有限公司;SQP 电子天平,赛多利斯科学仪器(北京)有限公司。
1.3 化学真实值测定
确定的待检样品在混样机中混合15 min,充分混匀。平行准确称取2份1.0~1.1 g(精确至0.1 mg)甜叶菊粉末样品于150 mL或250 mL锥形瓶(广口或磨口)中,用50 mL移液管准确加入100 mL纯净水。用天平准确称取样品瓶和液的总质量m1(精确至0.01 g),然后使用保鲜膜密封锥形瓶瓶口,置于(80±2) ℃水浴锅中水浴萃取1 h。水浴完成后取出锥形瓶,取下保鲜膜,擦干锥形瓶表面水滴,置于天平上补足样品质量至m2(m2和m1质量差应小于0.1 g),摇匀样品液,过0.45 μm滤膜后,装液相小瓶进行检测。留样需4 ℃保存(样品液需在8 h内进液相检测)。
1.4 近红外光谱采集
将上述确定的待检含量样品混合完全后装入样品杯中,轻轻压平,将样品杯放入旋转台上,采集样品漫反射光谱信息。
1.5 模型预处理和特征波长选择
为提高建立模型的准确性和精度,减少光谱中掺杂的干扰信息、噪声和大量的冗余,建模前需要对原始光谱进行预处理[16-17]。本研究使用的预处理算法包括:无光谱处理(original)、标准正态变换(standard normal variate,SNV)、多元散射校正(multiplicative scatter correction,MSC)、Savitzky-Golay卷积平滑(SG)、SNV+MSC、MSC+SG、SNV+SG、SNV+去趋势校正(de-trending,DT)[18]。
由于光谱中存在着大量的干扰信号,如果使用全光谱建模,必定会降低模型的准确性和精度。因此在建模之前,需要找到真正能反映目标成分的波长或波段,改善模型的各项性能,降低计算成本[16]。本研究使用的特征波长选择算法包括:竞争自适应重加权采样法(competitive adapative reweighted sampling,CARS)、无信息变量消除法(uninformative variables elimination,UVE)和连续投影算法(successive projections algorithm,SPA)[19-22]。
1.6 模型建立及评价
本研究使用偏最小二乘法(partial least squares,PLS)创建近红外模型,通过交互验证相关系数(correlation coefficient in cross validation,RCV)和RMSECV来判断模型的准确性,一般来说,RCV越大,RMSECV越小,模型的准确性和可信度就越高[23]。用验证集相关系数(correlation coefficient in validation,RP)和验证集残差均方根(root mean square error of prediction,RMSEP)来验证模型的精度,RP越大,RMSEP越小,模型的准度就越高,预测效果就越好[23]。
2 结果与分析
2.1 剔除异常样本
异常样本会影响模型的准确性和精度,因此在建模前需要剔除异常样本。本研究使用马氏距离法(mahalanobis distance,MD)剔除异常样本,其可以计算2个未知样本集的相似度,排除变量之间的相关性的干扰[24]。
2.2 样本集的划分
本研究共使用了144个实验样本,按照4∶1的比例随机划分为建模集和验证集,即建模集的样本数量为115个,验证集的样本数量为29个(表1)。

表1 样本划分统计表
2.3 原始光谱及预处理
光谱在测量的过程中会产生噪声和散射,因此在建模前需要对原始光谱进行预处理(图1)。预处理算法包括:SNV、SG平滑和MSC。由表2可知,与原始光谱相比,每一种预处理算法下的模型都有一定的提升,表明在建模之前进行光谱预处理是非常有必要的。每个预处理下所建立模型的RCV均大于0.9,RMSECV均小于0.352,说明每个预处理均有较好的预测能力。但是每个预处理的模型评价参数之间的差异较小,因此选择所有的预处理算法进行后续的特征波长算法建模。
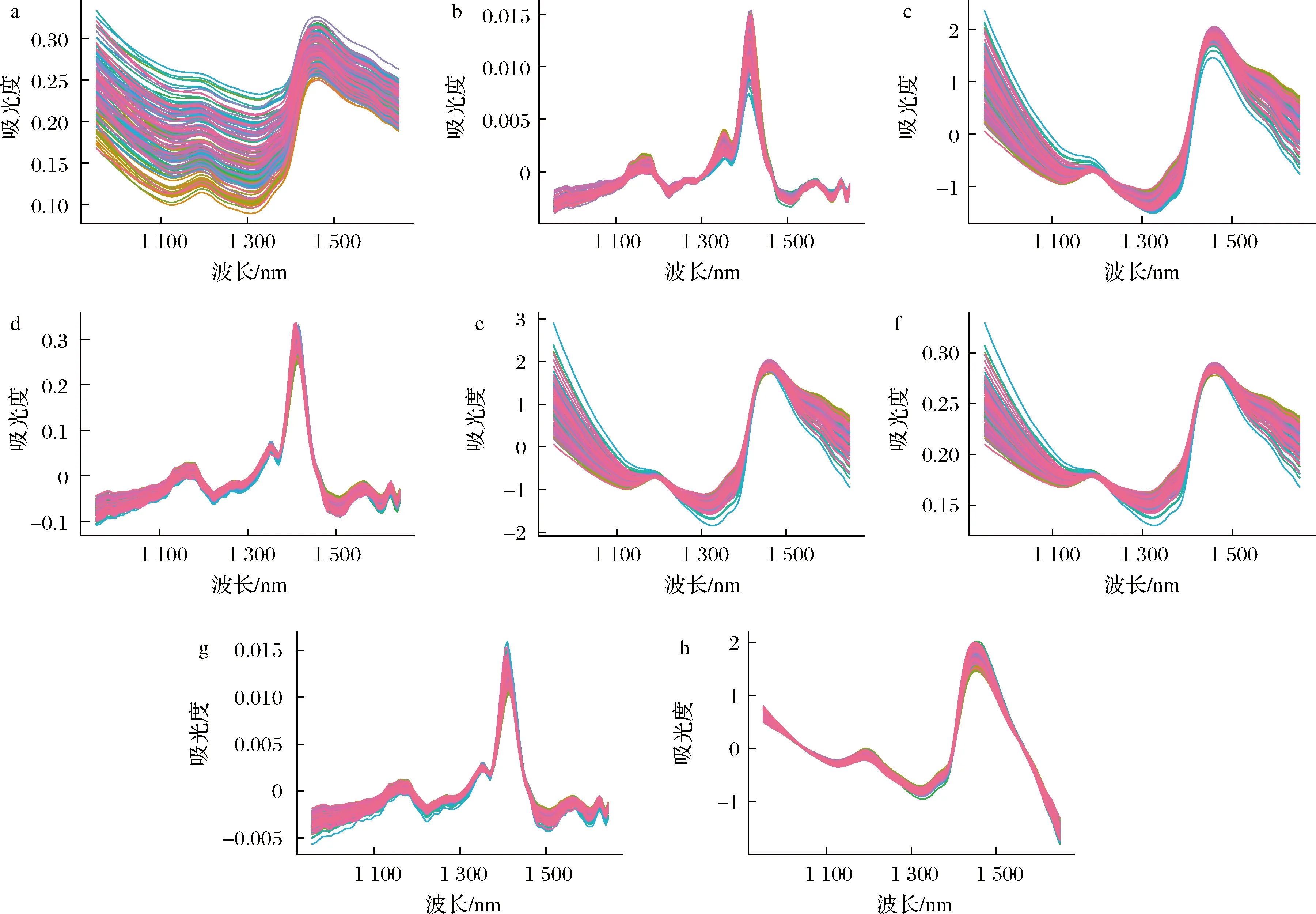
a-绿原酸原始光谱图;b-SG平滑处理后的光谱图;c-SNV处理后的光谱图;d-SNV+SG平滑处理后的光谱图;e-SNV+MSC处理后的光谱图;f-MSC处理后的光谱图;g-MSC+SG平滑处理后的光谱图;h-SNV+DT处理后的光谱图
2.4 特征波长的筛选
2.4.1 基于UVE特征波长筛选
无信息变量消除法算法可有效去除与目标物质无关的波长,降低模型计算量,提高模型准确性。与原始光谱建模效果相比,筛选之后每一种预处理算法下的模型性能均有一定幅度的提升,直接对原始光谱进行UVE特征波长筛选的建模效果依然是最差的(表3)。在7个预处理算法中,MSC+SG平滑算法提升效果最为明显,该算法只使用了22.7%的波长RMSECV却提升了25.26%,该模型的RMSECV、RCV、RMSEP和RP分别为0.263 1、0.945 3、0.247 2和0.952 1。
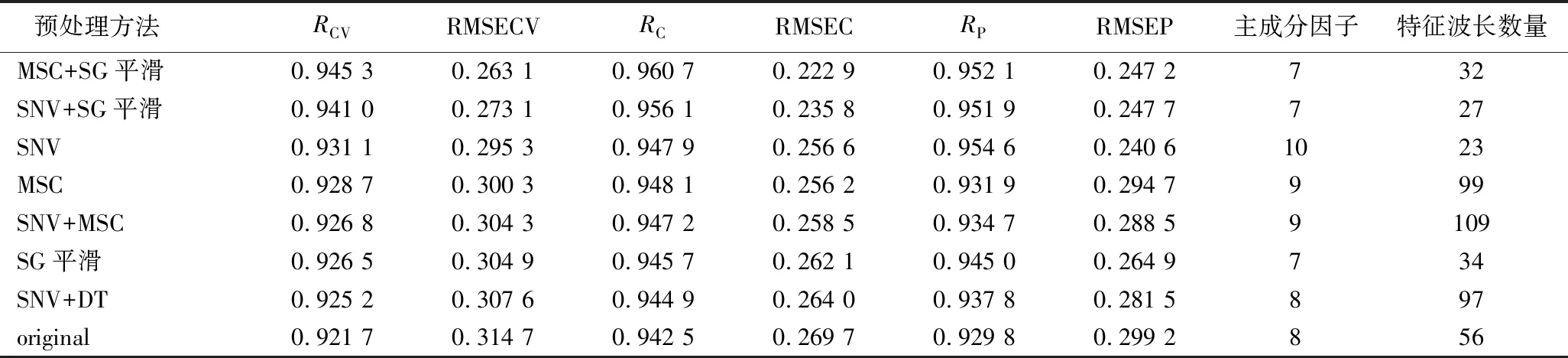
表3 UVE特征波长筛选结果
2.4.2 基于CARS特征波长筛选
竞争自适应重加权采样法是一种结合蒙特卡洛随机抽样与PLS模型回归系数的特征变量选择方法,可有效筛选出最佳波长组合。从表4可知,每一种预处理算法下的模型的RCV均小于0.307,RMSECV均大于0.925,均优于原始光谱的建模效果。通过比较不同预处理算法的建模效果,SNV+SG平滑算法优化效果最好,该算法只使用了23.18%的波长RMSECV缩小了23.52%,该模型的RMSECV、RCV、RMSEP和RP分别为0.269 2、0.942 7、0.245 2和0.952 8。

表4 CARS特征波长筛选结果
2.4.3 基于SPA特征波长筛选
连续投影算法是一种矢量空间共线性最小化的前向变量选择算法,它的优势在于提取全波段的几个特征波长,能够消除原始光谱矩阵中冗余的信息,可用于光谱特征波长的筛选。经过SPA算法筛选之后,2个预处理算法下的模型性能不仅没有得到提升,反而有所下降,其他预处理算法的模型性能只有小幅度提升(表5)。相对其他预处理算法的建模效果,MSC+SG平滑算法的建模效果最好,该算法只使用了6.38%的波长RMSECV缩小了19.63%,该模型的RMSECV、RCV、RMSEP和RP分别为0.300 5、0.928 6、0.298 7和0.930 0。

表5 SPA特征波长筛选结果
2.5 最佳模型筛选
基于不同特征波长选择算法的建模结果,3种波长选择算法对模型性能均有一定的提升,UVE和CARS对模型性能的提升效果比较明显,提高幅度也大致一致,SPA对建模效果的优化稍差(表6)。经过特征波长筛选之后,RMSECV和RMSEP均有所降低;RCV和RP均有所升高。MSC+SG平滑预处理算法和UVE特征波长选择算法的结合下,RCV达到最大,RMSECV值最小,说明此时所建立的模型效果最佳。预测效果如图2所示。
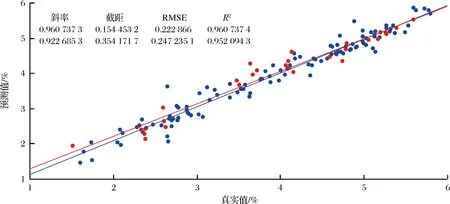
图2 UVE-PLS模型甜叶菊绿原酸预测结果

表6 不同特征波长选择算法的建模结果
3 结论与讨论
本研究利用近红外光谱技术结合PLS对甜叶菊绿原酸含量的光谱数据进行了近红外模型分析。使用了7种预处理算法和3种特征波长选择算法,每一种预处理算法下的模型都有一定的提升,证明了在建模之前进行光谱预处理的必要性。因为甜叶菊样本颗粒的不均匀、采集样本的条件不一致等因素影响,会对原始光谱产生影响,如果直接采用原始光谱及所有波长点建模效果会比较差,因此建模前有必要对样本进行预处理并对波长进行选择。MSC+SG平滑和SNV+SG平滑预处理效果接近,都比单一预处理效果好,SG平滑主要起到降低数据噪声的作用,有效地提高了数据的信噪比。SNV和MSC虽然计算方式不一致,但都能起到消除颗粒大小不均匀,光程变化等因素的影响。UVE和CARS都大幅度减少建模使用的波长数量,从而降低模型的复杂度和计算量。UVE选择的波长数建模主因子数更少,可以有效避免过拟合。连续投影算法下虽然也可以大量减少波长数量,但是波长减少一些有用信息也被剔除,导致光谱信息严重不足,模型的性能只有小幅度提升。
通过不同预处理算法和特征波长选择算法建模后评价参数的比较,确定了绿原酸含量最佳的偏最小二乘法模型。预处理算法为:MSC+SG平滑,特征波长选择算法为UVE,共选择了32个特征波长,此时所建立的模型效果最佳。模型的RMSECV、RCV、RMSEP和RP分别为0.263 1、0.945 3、0.247 2和0.952 1。建模集、交叉验证和验证集的相关系数均大于0.94,残差均方根均小于0.27,模型的准确性和精度都较高,表明使用近红外光谱技术快速检测甜叶菊绿原酸含量是可行的。
为进一步提高预测模型的准确性和精度,应该扩大样本数量,增加样本的多样性,使其满足不同来源甜叶菊样本的绿原酸含量预测。另外还可使用其他预处理算法和特征波长选择算法,使模型的准确性和精度得到提升。
