加油站潜力测算的大数据分析方法与实证检验
2023-08-31张蕾邢治河高鲁营顾曦
张蕾,邢治河,高鲁营,顾曦
中国石油天然气股份有限公司规划总院
0 引言
加油站的销售潜力是指在现有的软硬件条件下,加油站可能达到的最大销售量在外部条件允许时可以转化为加油站的实际销售能力[1]。从实际应用来看,对加油站进行精确的潜力测算有两方面的意义:一是可以对正在运营的加油站进行测算,作为加油站提高量效的标准或者参考,也可以作为加油站转让或者运行评估的重要指标;二是对于准备规划或者建设的加油站进行虚拟测算,可以作为加油站建设可行性的重要参考。
加油站的潜力测算是成品油销售企业在站点投资、实际经营等方面非常重要的参考工具,是企业决策的重要依据。但从应用情况来看,当前常用的潜力测算方法存在较为明显的问题。一方面是投资决策的影响因素复杂:从国内外已有文献来看,全部影响因素指标可能达到50 个甚至上百个;对于不同的站点之间,其影响因素的权重存在差异,甚至同一个站点的影响因素也会随时间和周边环境而变化。另一方面则是数据客观性不足:一是人工取数导致客观性不足,如道路车流量的估计一般由当地管理人员手工统计,可能由于地点、时间、人为操作等情况出现误差,导致数据不能反映周边道路的真实情况;二是调研数据存在滞后性,由于当前对周边环境、站前道路、站址条件等数据获取主要采取走访调研的方式,数据获取渠道不固定,指标权威性欠缺,且数据更新不够及时,导致站点投资的基础数据准确性不足,无法满足动态评估需求。因此,在愈加激烈的成品油零售市场竞争中,如何充分利用内外部数据信息和先进分析技术精确测算销售潜力,是当前亟需解决的重要问题。
过去几十年,不断有新的预测理论和算法被提出,从传统的线性模型到现在广泛使用的机器学习、深度学习[2],各种线性与非线性模型层出不穷。国内外用于能源领域的主流预测方法有各类基于回归模型[3-4]、时间序列模型预测的方法[5],灰色预测的方法以及基于BP 神经网络模型的预测方法[6],等等。近些年来LSTM(长短期记忆网络)已被广泛应用于能源领域的预测问题中:Tulensalo 等[7]使用LSTM 学习电力市场与天气之间的关系,并对电力系统的总网损进行预测;Laib 等[8]使用LSTM 模型来对不同地区的天然气消耗量进行预测;Li 等[9]提出结合LSTM 模型与特征选择技术来对电价进行预测。众多的模型与其他领域的预测案例也为加油站潜在销量预测提供了方法思路和参考经验。
传统的加油站销量预测一般转化为时间序列的预测问题,使用时间序列的滑动平均模型、指数平滑模型、ARIMA(差分整合移动平均自回归)模型等预测方法对销量进行预测。李艳东等[10]提出了一种采用指数平滑对加油站销量进行预测的方法,该方法预测速度快但精度相对较低,对销量数据的平稳性有很高的要求,并且无法刻画其他因素对于销量的影响;杨庆等[11]基于线性判定将销量序列分为是否线性,对于非线性的销量序列则使用BP神经网络对未来销量进行预测;张晨等[12]基于决策树与集成学习,使用混合决策树的方法,将随机森林与梯度提升树的预测结果进行加权作为对加油站销量的预测;卢晨辉等[13]与潘诗元等[14]都使用LSTM 结合其他对销量影响的特征构建加油站销量预测模型,对销量序列进行预测。
上述销量预测方法主要是基于单个加油站销量的时间序列数据对其未来销量进行预测,因此纳入的特征也主要是天气、油价、气温等对销量有影响的时间序列数据,而对于反映加油站自身属性的特征(如加油站分类、站点类型、占地面积等)以及所处的地理空间信息均没有纳入考虑,例如:占地大小不同的加油站之间销售能力存在差异;高速公路沿线加油站的销售能力也与城区内加油站的销售能力存在差异。因此上述方法无法适用于不同地点、不同特征的加油站的销售潜力预测。
地理信息数据在国民经济各个领域都有着十分广泛的应用,POI(Point of Interest,兴趣点)数据作为一种代表地理实体的点状地理空间数据,反映了实体所承载的人类活动与地理位置之间的相互关联性。通过POI 数据与其他地理信息数据的应用,能够在商业设施建设前综合考虑资源配置、交通条件、地理特征等当地的市场潜力因素,辅助设施建设的选址工作[15]。杜兰等[16]结合景区内道路网与POI 信息,对景区游客接待中心的最优选址进行了研究。此外,帅春燕等[17]也曾结合换电数据、外卖数据和POI 数据,使用线性回归与K-Means 聚类算法,研究换电柜的需求与周边POI 之间的关系,提出电动自行车换电柜的选址策略。
本文结合加油站自身的属性、运营数据以及周边的地理空间信息,通过因子分析的方法构建指数,并通过聚类、分类等方法对影响加油站销售的周边地理空间环境进行建模,从而实现对不同地点、不同特征的已有加油站的销售情况的评价以及对新建加油站的销售潜力的预测,解决当前实际测算中遇到的问题,是利用大数据技术实现站点管理精细化的有益探索。
1 数据清洗与变量构建
考虑到影响加油站销售的变量较多,本文通过客观数据对加油站周边信息进行分解,如:用车流量数据来实现对汽车保有情况的估计;用网格内的人口、活动、道路、光强度等反映经济发展、消费需求、交通发展等;用POI 数据反映周边的人流、车流、商业服务、竞争对手、能源替代等。
本文所使用数据包括空间信息数据及运营数据,其中:空间信息数据包括道路环境数据、地理POI数据及车流量数据;运营数据包括加油站自身明细数据及销售数据(汽油销量、柴油销量及非油品收入)。通过研究加油站周边的地理空间信息对加油站销售水平的影响,构建指数体系与预测模型对加油站的销售潜力进行预测。由于包头市是呼包鄂城市群中心城市之一,具有发达的公路交通,代表性较强,因此以包头市为例对预测方法进行阐述。
1.1 数据来源
道路环境数据来源于中国科学院地理科学与资源研究所(简称地理资源所),包括调查和计算所得的人口数(POP)、活动指数(DAI、NAI)、道路密度(RD)、夜光强度(LI)和建筑地表面积(BSA)。
地理POI 数据来源于百度地图开放平台提供的API(接口),通过基于Python 2.7 的爬虫程序爬取获得。POI 通常包含名称、地址、坐标、类别等4个属性,一个POI 可以是一个小区、一家商场、一个公交站等。加油站周边的POI 信息可以反映各个加油站所在区域的地理特征,侧面反映人流量和车流量,对加油站的销售情况起到重要影响。
车流量数据采用年度月平均道路车流量,包括汽油汽车、柴油汽车、摩托车。对于没有记录车流量的加油站,采用反距离加权插值法对其车流量进行插补处理,即该加油站的道路车流量是所有有记录加油站道路车流量的加权和,权重与距离成反比。
加油站自身内部数据多为分类变量和定序变量,转化变量类型后可直接使用。销售数据中非油品收入采用当年日平均收入;汽油销量和柴油销量均采用当年日平均销量,且已合并油品型号。即使是同一个加油站,汽油、柴油和非油品的销售水平也并不一致。图1 为各加油站3 类商品销量对比,图中每一行代表一个加油站,每一列分别代表汽油、柴油与非油品的销售情况,网格中颜色越深表示该加油站该类商品的销量(或收入)越高。可以看到:汽油和非油品的销售水平比较相似,汽油销量较高的加油站倾向于有较高的非油品销量;而柴油销售水平则与二者不太一致,柴油销售高的加油站往往汽油与非油品的销售水平较低。

图1 各加油站3 种商品销量对比
1.2 数据清洗
原始的POI 数据以每个POI 作为个体,包括每个POI 的名称、地址、地理坐标、所属类别等属性,数据量十分庞大,且不利于以加油站为个体分析周边地理环境对销售水平的影响。本研究认为加油站的销售水平只会受周边的地理环境影响,因此,为方便后续的数据分析,以加油站为中心检索周边的POI 数据,并据此整理出每个加油站周边各类POI的分布,以便用于接下来的数据分析。
基于地理资源所提供的网格(边长为1/600 的经度或纬度,约合160 m),以加油站所在网格为中心,附近的n×n个小网格组成网格单元,根据图2 所示A、B、C、D 这4 个边界点的经纬度确定检索范围,将网络单元内n2个网格的道路环境数据及POI 数据汇总。

图2 确定检索区域范围示意(以n=5 为例)
POI 数据提供的信息由检索范围的大小控制,若搜索范围过小,提供的信息太少;反之则会使得各加油站周边存在交叉,减小了各加油站之间的地理差异。为了探索合适的搜索范围,分别尝试以多个检索范围(n=5,n=9 和n=15)获取各个加油站的地理POI 数据,得到对应的POI 数据分布。最终确定以n=15(即2 400 m×2 400 m)为检索范围进行POI 数据的获取,得到83 个POI 变量,其中每个变量的数据代表相应关键词下的POI 个数。
由于数据中存在某些变量全部单一取值或是取值0 的比例很高,这些变量无法在数据分析中提供有效的信息,为了提高后续数据分析结果的准确性,采取了两步预处理去除质量不佳的冗余变量,即去掉单一取值的变量以及取值为0 的比例超过80%的POI 变量。
1.3 指数构建
为了探究影响加油站销售情况的因素,结合清洗后的数据,将各加油站的销售情况作为响应变量,将能够对其产生影响的解释变量用于解释与说明加油站销售情况的变化。解释变量主要分为以下3 类:反映加油站自身属性信息的变量,如资产性质、所在道路等;有关加油站各类面积的变量,如占地面积、便利店面积等;反映加油站周边区域空间信息的道路环境变量和POI 变量。由于变量个数众多,达到109 个,且POI 变量取值较为稀疏,因此考虑在第二类和第三类原始变量的基础上构建指数,增强模型的效果与可解释性,同时也可以通过指数来反映加油站区域范围内潜在客户群体的规模。
为构建指数,需要先将原始变量按照一定的特征(如都是反映加油站周边商业服务设施的变量,或都是对加油站自身规模的变量等)分成几类,然后在每一类原始变量的基础上构建一个因子反映这一类变量中的信息,其作为一个指数变量,用于后续的分析。
本文首先构造了6 个连续型的指数。将预处理后的变量根据意义相近的原则,参考GB 50137—2011《城市用地分类与规划建设用地标准》划分成了6 个指数类,分别为活动指数、公共管理服务设施、商业服务设施、交通道路、绿地广场和加油站综合面积。各指数类包括变量如下:
1)活动指数:POP、DAI、NAI、RD、LI、BSA、AREA。
2)公共管理服务设施:厕所、疗养院、养老院、大学、中学、小学、幼儿园、图书馆、培训、科研、博物馆、高尔夫球场、滑雪场、赛马场、体育馆、羽毛球馆、网球场、溜冰场、健身房、医院、邮局。
3)商业服务设施:移动、联通、电信、小区、美容、商场、超市、便利店、烟酒、特产、服装店、体育用品、家具、建材、电器、度假村、农家乐、餐饮、银行、典当、证券、保险、影院、KTV、夜总会、棋牌室、网吧、婚庆、彩票、杂志社、报社、出版社、商务写字楼、工业园、工厂。
4)交通道路:汽车销售、汽车服务、汽车维修、驾校、汽车租赁、高速服务区、停车场、检测站、火车站、地铁站、客运站、公交车站、码头、汽油汽车道路车数量合计、柴油汽车道路车数量合计、摩托车道路车数量合计。
5)绿地广场:公园、教堂、寺庙、钓鱼、动物园、植物园、水族馆、游乐园。
6)加油站综合面积:占地面积、罩棚面积、停车场面积、便利店面积。
基于上述分类,使用因子分析方法对每个指数类分别构建因子作为指数,通过方差贡献率反映变量对因子的依赖程度,包头市每个指数因子的方差贡献率见表1。

表1 包头市各指数因子方差贡献率
其次,各加油站周边竞品加油站数量转化为0-1 变量作为竞品指数,以反映加油站周边是否存在竞争,即在加油站周边不存在竞品加油站时将竞品指数记为0,反之记为1。
最后将上述构建的指数变量与原始解释变量中第一类反映加油站自身属性的变量合并,共同作为后续建模分析所使用的解释变量。
2 模型搭建与实证
建立大数据模型的目的是对加油站的潜在销售能力进行测算。基于构建的指数因子,通过聚类分析评价现有的加油站销售水平,再通过判别分析实现对新加油站销售潜能的预测。图3 为建模流程示意,主要分为超高销量(收入)甄别、非超高销量(收入)加油站的聚类分析、基于聚类结果判别新加油站的所属类别等3 个步骤。
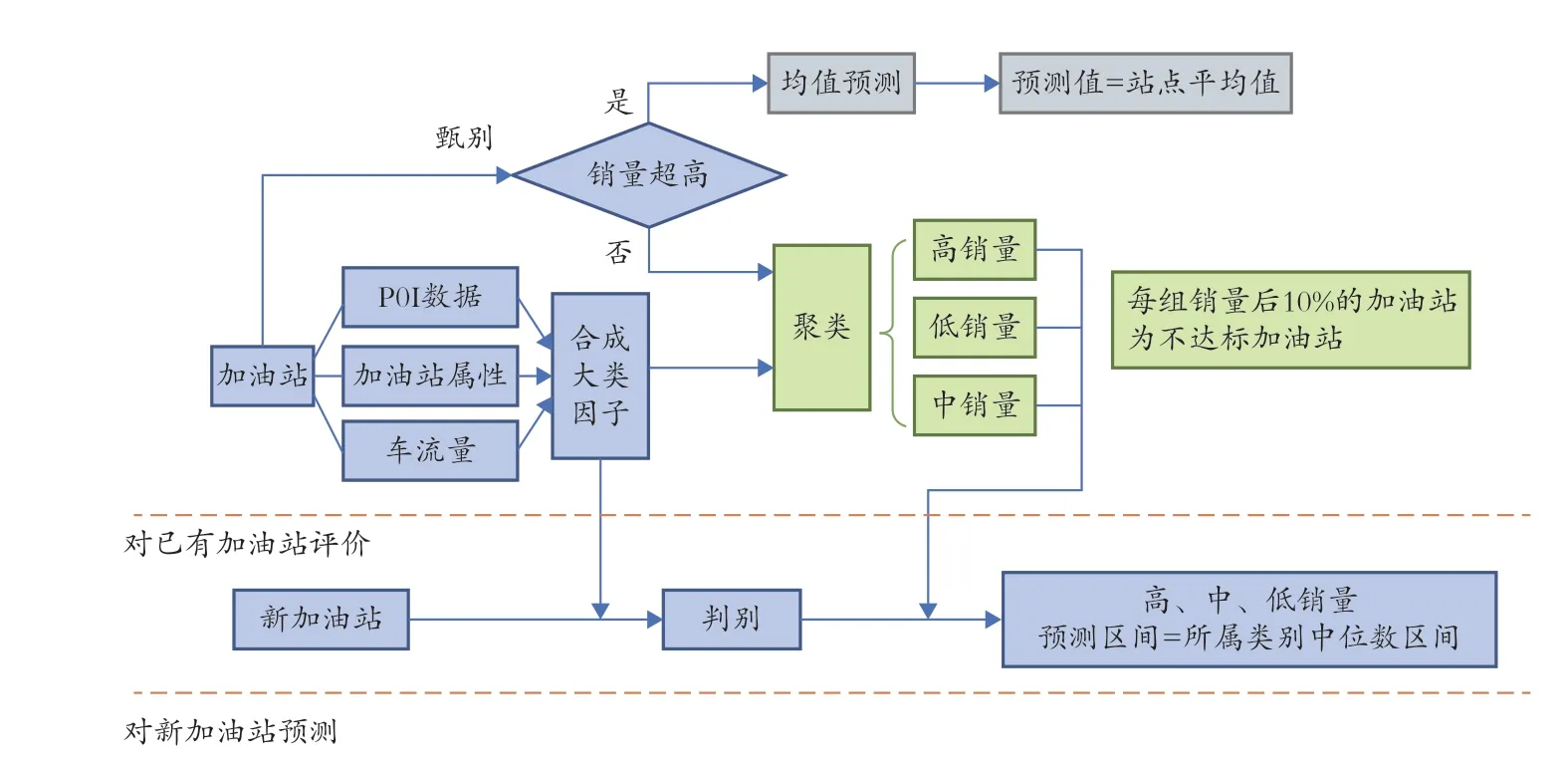
图3 模型主要流程示意
2.1 超高销量甄别
进行超高销量甄别的主要原因是,一个城市内存在个别加油站的销量(收入)远高于其他加油站的情况,为保障模型的稳定性,需要对这些特殊加油站进行专门的分析。依据加油站经验分布图中是否存在断层现象识别这类特殊加油站是否存在,若无断层现象则不存在超高销量(收入)的加油站。若一个加油站被判断为超高销量(收入)加油站,则其销量(收入)预测值为所有超高销量(收入)加油站的均值;若其被判断为非超高销量(收入)加油站,进行后续的分析。
根据包头市67 个加油站汽油销量的经验分布中的断层,将超高销量的加油站记为1,非超高销量的加油站记为0。如图4 所示,汽油销量在8 000 L处存在断层,因此将汽油销量超过8 000 L 的8 个加油站标注为超高销量的加油站。
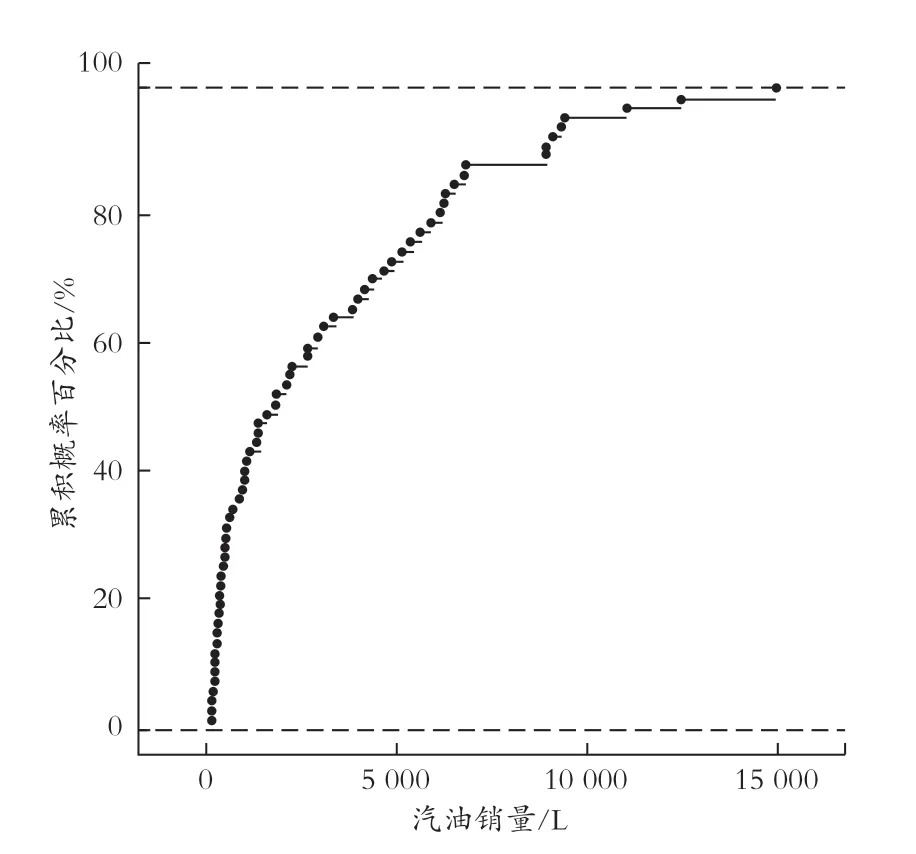
图4 包头市加油站汽油销量的经验分布
根据人工标注的结果,基于原始解释变量训练了随机森林分类器,参考随机森林分类器给出的重要变量和树的划分准则确定甄别准则。需要注意的是,由于超高销量与非超高销量的加油站数目过于悬殊,为了提高模型对于前者的识别能力,在训练随机森林模型前,先对超高销量加油站的数据进行了过采样处理,即通过有放回地抽取超高销量加油站,提高超高销量加油站的占比以构建一个平衡的数据集进行建模。根据随机森林分类器,找到重要性排名前三的变量,分别是便利店、培训、特产。图5 为重要变量分布图,其中较深的蓝色反映了超高销量加油站汽油销量的分布,反之则反映了非超高销量加油站汽油销量的分布。

图5 重要变量分布
综合选出的重要变量以及随机森林分类器中树的分节点情况,最终得到甄别为超高销量的标准为:便利店数量大于30 个,培训机构数量大于55 个,且特产店数量大于7 个。
使用超高销量加油站销量的平均值10 583 L 作为包头市超高销量加油站销量的预测值,即:对于一个加油站,若其被甄别为超高销量的加油站,则使用10 583 L 作为对其日均销量的预测;对于其他非超高销量的加油站则继续进行建模分析。
2.2 聚类模型搭建
考虑到特征上相近的加油站应当具有类似的销售潜力,因此对于其他未被甄别为超高销量的加油站,通过上文合成的指数及自身属性所构造的解释变量对加油站进行聚类分析。
为了在对加油站聚类时能够充分考虑加油站在特征上的差异以及在地理空间分布上的差异,本文采用加油站之间的Gower(高尔)距离和空间距离的加权距离进行聚类。Gower 距离是一种可以同时处理特征中连续性变量、分类型变量及定序型变量的距离计算方法。设Gower 距离为dg,空间距离为ds,则加权距离dw为:
式中权重w使用遍历搜索来确定最优权重,即令权重从0.30 到1.00,以0.05 的间隔逐步增加,选择使得聚类效果最佳的权重作为最终用于构造距离的权重。
为了评价、比较不同权重下的聚类效果,使用“中位数差/标准差”指标(MS 指标)。该指标取值越大,表示各个类别的中位数之间存在差异越大且类别内部标准差较小,说明各个类别的销售水平差距越大,解释变量对销售水平的差异刻画得越好。因此选择使MS 指标达到最大的权重。
若聚为2 类,MS 指标取值的定义为:
若聚为3 类,MS 指标取值的定义为:
式中:MMS——MS 指标的值;m1,m2和m3——从小到大排列后的各类中位数;s1,s2和s3——对应各类内的标准差。
MS 指标只能用在确定类数K之后选出最优的距离权重,无法直接比较不同类别个数对应的聚类结果。为了确定最优的类别个数,研究使用DBI(Davies-Bouldin Index,戴维森堡丁指数)指标,DBI 越小表示类内的样本距离类中心的距离越近,同时类间距离越远,即聚类效果越好。由于包括包头市在内的6 个城市的加油站数量较少,只需要考虑类别个数是2 或3 的情况,选择使得DBI 最小的类别个数。
因此,在对加油站进行聚类时,首先固定类别个数为2 和3,通过MS 指标分别选择聚成2 类与聚成3 类的最优权重,再通过DBI 指标对比以上两个结果,确定最终的类别个数。
2.3 类别判断与应用
去掉8 个超高销量的加油站,将剩下的59 个非超高销量加油站按照解释变量进行聚类。根据DBI指标,确定最优类别个数为3 类。
当聚成3 类时:MS 指标随权重的变化情况见图6,最终选择能够使MS 指标取值最大的权重w=0.9;按照加权后的距离,将剩下的59 个加油站聚成3 类,将这3 类按销量中位数从高到低分别命名为高销量(1 类)、中销量(2 类)、低销量(3类),各类加油站的汽油销量箱线图见图7。

图6 MS 指标随Gower 距离权重变化情况
对于现有的加油站,将每个销量分类的销量的10%分位数作为对其销售水平评价的指标,销量低于该值的加油站评价为销量不达标。最终可以得到3 个销量分类10%分位数分别为1 362、265 和217,即对于高销量分类的加油站,若其汽油月均销量低于1 362 L 则判定其销量不达标。
为了探索解释变量对销售水平影响的重要性,研究比较了不同类加油站之间变量分布的差异。在不同销量分类中差异越大的变量,说明其对聚类的影响越大,也即对汽油销量的影响越大。图8 为6 个连续型指数在不同销量分类中分布的箱线图,可以从中比较这些指数在聚类后所得不同分类中的分布差异。

图8 各因子在不同销量组别中的分布箱线图
对于8 个非连续型的解释变量(1 个竞品指数和7 个描述加油站自身属性的变量),则可使用卡方检验法检验变量与分类之间的独立性,利用卡方检验法的P值来反映解释变量对于聚类的影响,P值越小反映变量与分类之间的相关越强。各变量卡方检验P值见表2。
2.4 新加油站销量(收入)预测
若要在一个给定的坐标点建立一个新的加油站,也可使用本模型对该加油站的销售潜能进行预测。
首先,在前述聚类结果的基础上训练随机森林和支持向量机(SVM)作为分类模型,对新加油站所属的类别进行判别;其次,根据判别结果将其划分到上一步聚类所得到的高销量、中销量、低销量类别之中;最后,以其所属类别的销量分类的中位数作为对该加油站的预期销售潜能。
此外,对于每一类加油站,都可使用Bootstrap方法构建其销量中位数的99%置信区间。这样,新加油站可以使用分类模型给出其所属类别销量中位数的99%置信区间作为新加油站销量的预测区间。各销量分类中汽油销量的预测区间见图9,图中颜色部分表示中位数的置信区间即预测区间,红色字体标注中位数置信区间覆盖这一类样本的占比。

图9 各销量分类中汽油销量的预测区间
2.5 模型的延伸与验证
为了验证模型的有效性,另选了5 个城市对模型进行验证,分别是呼和浩特、巴彦淖尔、哈尔滨、太原和运城。模型建立和运行结果与包头模型基本一致,仅在最终的建议结果方面存在一定的差异。
本文对6 个城市加油站模型的结果进行了评估。对于超高销量(收入)甄别部分,按“甄别正确的加油站数量/总加油站数量”计算准确率,6 个城市3 类商品的甄别准确率均达到90%以上。对于新加油站销售预测部分,分别使用留一法交叉验证、5折交叉验证法及10 折交叉验证法对分类模型的准确率进行评估,准确率均达到85%以上。结果显示,本研究能够合理准确地对加油站的销售水平进行评价和预测。
3 结论与应用
本文提出了一种基于地理信息数据的加油站销售潜力预测模型。该模型基于加油站地理信息数据使用因子分析构建了指数,并作为后续分析的解释变量,同时反映加油站区域范围内的客户群体规模。为了对不同加油站的销售潜力进行评价,采用聚类分析将销售潜力非超高的加油站聚成几类,并使用类中位数作为对加油站销售潜力评价的标准。
对于新建加油站则通过其所处区域的地理特征及加油站本身特征,使用分类模型将其分到聚类所得到的几类加油站中,并使用类中位数的置信区间作为销售潜力的区间预测,尽管对预测精度有所牺牲,但提高了预测的稳定性及可解释性。结果显示,本文提出的预测模型能够对加油站的销售潜力进行合理评价和准确预测。从业人员能够根据预测结果进行运营决策,也能够将模型对销售潜力的预测作为新建加油站选址决策的量化依据。目前来看,实际经营中,将潜在销量作为加油站经营能力提升参考值的做法较多,且多个站点均取得了较为明显的效果,例如2018 年应用该指标并优化的加油站单站日销量平均提升0.6 t。在新站选址中,本文给出的方法可以作为一种客观的参考值,但目前还没有实际的数据进行佐证。
本文是对加油站潜力数据测算的一种方法探索,还有进一步深化的空间:一是在实际应用中,将本方法进行工程化后,可以实现对线上数据的自动采集和实时动态更新,保证数据测算的准确性;二是可以在不同区域考虑大样本的聚类分析,并加入对不同区域站点的异质性讨论,能够对实际的站点经营和站点选址实现精确化的测算;三是本方法探索中给出的中位数等参数,也可以根据市场和公司整体战略需求进行调整,以实现对实际经营的支撑。
