一种基于属性值权重的k-modes 聚类分析算法*
2023-08-31郝荣丽胡立华
郝荣丽 胡立华
(太原科技大学计算机科学与技术学院 太原 030024)
1 引言
聚类分析是数据挖掘和机器学习等领域中的主要研究内容之一,它是将物理或抽象的数据对象根据某种相似准则划分成多个对象类的过程,使得同一个类中的对象之间具有较高的相似性,而不同簇中的对象具有较高的相异性[1],并已经广泛地应用在基因分类[2]、股市波动的特征分析[3]、天光光谱特征分析[4]、文档的分类[5]、图像处理[6]等许多领域。聚类分析主要分为划分聚类[7]、层次聚类[8]、密度聚类[9]和网格聚类[10]。k-means算法[11]是一种经典、常用的划分聚类算法,具有简单高效,易于理解和实现等优点,但在实际应用中,由于存在大量的分类型数据,k-means 方法不能处理包含分类属性的数据集,限制了其实际应用领域。
k-modes[12]作为k-means 聚类分析算法的一种扩展,可适用于含有分类属性的数据集,具有计算简单、复杂度低等优点,但该聚类算法采用简单匹配差异法,未能充分体现数据集的分布特征,将所有属性视为同等地位,忽略了属性之间的重要性差异,若频率最高的属性值有多个,传统k-modes 算法无法选出最恰当的属性值作为该簇模式。本文利用粗糙集中的等价类计算属性值权重的思想,提出了一种k-modes 聚类分析算法。由于该算法充分利用了属性值在数据集中的分布特征与属性值自身的差异,有效地解决了属性值之间的差异性度量,并利用属性值频率和各属性值的权重,给出一种聚类中心更新途径,从而有效地提高了聚类分析的效果。本文主要贡献为
1)利用属性值之间的差异和属性值的权重,重新定义了相异度度量公式;
2)采用属性值频率和各属性值的权重,给出了一种聚类中心更新迭代公式;
3)提出了一种基于属性值权重的k-modes 聚类算法。
2 相关工作
k-modes 作为k-means 算法的一种扩展,根据分类数据的特点,采用简单的0-1 匹配法来度量分类数据间的距离,用模式代替均值,但是这种采用简单匹配差异法忽略了属性之间的差异性,导致差异性度量不准确。对k-modes 改进的典型成果为:He[13]等使用属性值在类内出现的频率提出新的类内属性距离计算公式;Hsu[14]等提出一种基于概念层次的方法来计算属性值之间的距离,但该方法需要专家经验;贾彬[15]等使用信息熵为属性加权来解决属性之间的差异问题,但是该方法在确定属性权重时只考虑了某一属性的分布,没有考虑相关属性对其的影响;白亮[16]等利用粗糙集中的上、下近似提出了一种新的相似性度量,改善了聚类效果,却提高了计算的复杂度;赵亮[17]等基于朴素贝叶斯分类器中间运算结果计算属性值之间的距离;黄苑华[18]等基于相互依存的冗余理论提出一种新的距离公式,采用内部距离和外部距离共同衡量两个对象属性值之间的距离,在进行外部距离计算时,仅从相关属性的角度对属性值在整个数据集上的分布情况进行描述,导致差异性度量不准确,这些算法不能够准确应用属性空间中数据间的关系,因而会丢失数据间的相似关系。针对传统k-modes 算法中的模式问题,贾彬[15]提出了多属性值modes 的相异度度量方法,每个属性都保留全部属性值和其出现频率,但这样也使得数据对象与modes 之间的距离计算变得复杂化。
综上所述,k-modes 虽然将k-means 聚类分析算法应用范围扩展到了分类数据集,但其多种距离度量都无法有效地度量分类数据之间的距离,未能充分体现分类变量间的差异,以及在整个数据集中的分布特征。
3 聚类目标函数与多属性权重
为适用于分类数据的聚类分析,Huang 等于1998年提出了k-modes聚类算法,给定一组分类数据对象X={x1,x2,…,xn}和整数k(k≤n),数据集随机初始划分成k个互斥的簇,对数据对象迭代重定位簇,最终搜索得到使簇内平方误差和,即目标函数F最小化的k个互斥的簇,参照文献[12],其目标函数定义如下:
聚类目标函数为
在式(1)中,W是一个n×k的{0 ,1} 矩阵,n表示数据集U中数据点的个数,k表示聚类的个数,Z={z1,z2,…,zk},zl为第l 个类的中心点,zl={zl1,zl2,…,zlm} ,zlm是第l个类的第m个属性上出现频率最高的属性值,d(xi,zl)为简单的0-1匹配计算得出的分类变量间的距离。
多属性值权重是属性值在属性空间中分布特征的体现,可从本地属性和相关属性两个角度,来有效地刻画属性值在属性空间上的分布特征。则参照文献[19],相关概念如下:
对于任意ai∈A,设xki∈Vai,从本地属性ai的角度度量xki的单属性权重为
从相关属性aj的角度度量xki的多属性权重为
结合本地属性和相关属性定义属性值的权重为
其中:[xk]ai表示数据对象xk在属性ai的等价类,表示属性值xki和xkj的共现次数。属性值权重W(xki)体现了属性值在整个属性空间中的分布特征。
4 基于属性值权重的k-mode 聚类分析
两个数据对象同一属性下两个值之间是否相似既取决于属性值本身,又取决于其所处的环境,即属性值所处的属性空间[16]。可利用属性值的权重来表示属性空间的分布特征对属性值相异度的影响,即外部相异度;同时,也需考虑属性值本身之间的差异性,即内部相异度。因此,数据对象属性值之间的相异度是由外部相异度和内部相异度共同决定,其相异度越大,距离也越大。
设xi和xj为数据集中的任意两个数据对象,at为任一属性,则参照文献[18],数据对象xi和数据对象xj在属性at上的相异度度量公式重新定义如下:
在式(5)中,d1(xit,xjt)表示两个数据对象属性值本身的差异度,即内部相异度;d2(xit,xjt)表示两个数据对象在整个属性空间中分布的差异度,即外部相异度;1 2 表示两种差异度的重要性相当,共同决定了属性值之间的距离,差异度越高,距离越远。
参照文献[18],数据对象xi和数据对象xj在属性at上的内部相异度的度量公式如下:
在式(6)中,使用简单0-1 匹配来计算两个属性值间的内部相异度。
由式(4)引入的属性值权重,可得出第i个数据对象和第j个数据对象在属性at上的外部相异度的度量公式如下:
式中W(xit),W(xjt)分别代表属性值xit和xjt对应的权重,用权重的差值来表示他们之间的外部相异度。
传统的k-modes 算法在每个簇的每个属性上选择出现次数最多的属性值作为该簇中心点在该属性上的值,但是属性上出现频率高的属性值有多个的话难以获得最合适的中心点,因此,利用属性取值的频率以及属性值的权重,重新描述类中心,并找出类中心对应的平均权重,从而可有效提高聚类精度。聚类族中心和对应的平均权重定义如下:
定义1 类l中某属性at上某一属性值的平均权重为该类中属性at对应的该属性值的所有权重之和的平均值。
定义2 类l的中心为zl={zl1,zl2,…,zlm} ,其中zlm为类l中数据对象在属性am上出现频率最高的,且具有最高平均权重的属性值。每一个中心点对应一个平均权重集平均权重集代表模式中每个属性值在属性空间中的分布情况。
5 基于属性值权重的k-mode 聚类算法
根据第3 节和第4 节的描述,在分类型数据集中,采用重新定义的相异度度量方式以及聚类簇中心选择的聚类分析基本步骤为利用粗糙集中的等价类,计算数据集中所有数据对象的属性值的属性权重;随机选择数据集U中k个数据点作为初始的聚类中心;计算数据集中所有数据对象与k个聚类中心之间的相异度,然后将每个对象分配到与其相异度最小的聚类中心所在的簇中;在得到的k个簇中,更新簇的中心点及其对应的权重;重复上述两个步骤,直到目标函数达到最小值,k个簇的类中心不再发生变化为止。算法伪代码描述如下:
算法:MCAMAW(K-modes clustering algorithm based on multiple attribute weights)
输入:分类数据集,簇的个数k
输出:聚类簇
1)for(int i=0;i<n;i++){
2)for(int j=0;j<m;j++){
3) 利用xit在属性at上的等价类,根据式(2)~(4)计算出属性值xit的属性权重W( )xit。
4)}
5)}
6)随机初始找出k个簇中心,平均权重集为其对应的属性值的权重
7)for(int i=0;i<n;i++){
8) for(int cu=0;cu<k;cu++){
9) for(int j=0;j<m;j++){
10) 根据式(5)~(7)计算出所有数据对象与簇中心之间的距离,然后将各个数据对象
11) 分配到离其最近的簇中。
12)}}}
13)for(int cu=0;cu<k;cu++){
14) 根据定义1 和定义2 更新各个簇的中心及其平均权重集
15)}
16)重复第7)步到第17)步,直至式(3)达到最小值,k个簇的类中心不再发生变化为止
17)返回聚类簇
6 实验结果及分析
为了验证所提MCAMAW 算法的有效性,从UCI数据集中选取Mushroom、Vote、Breast-cancer三个数据集,详见表1 所示。采用python 语言实现了MCAMAW 算法、传统k-modes 算法[12]和基于相互依存冗余度量k-modes 算法[18],并分别从分类正确率、分类精度和召回率三个指标进行评价。
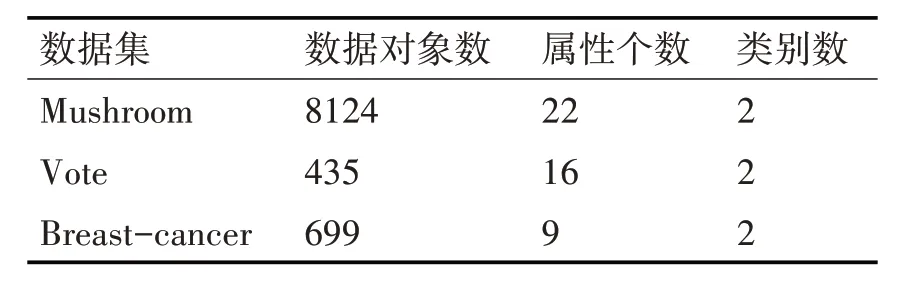
表1 UCI数据集
表2~4 给出了MCAMAW 算法与传统k-modes算法[12]和基于相互依存冗余度量k-modes 算法[18]的实验比较结果。可以看出在Mushroom、Vote、Breast-cancer数据集上MCAMAW 算法的三个指标均有所提高,聚类效果也优于其他两个算法。其主要原因是MCAMAW 算法充分利用数据对象在数据集中的空间特征,准确地描述了数据对象之间的关系,有效地避免了其他两个对比算法中分类数据对象之间距离度量不准确的问题。
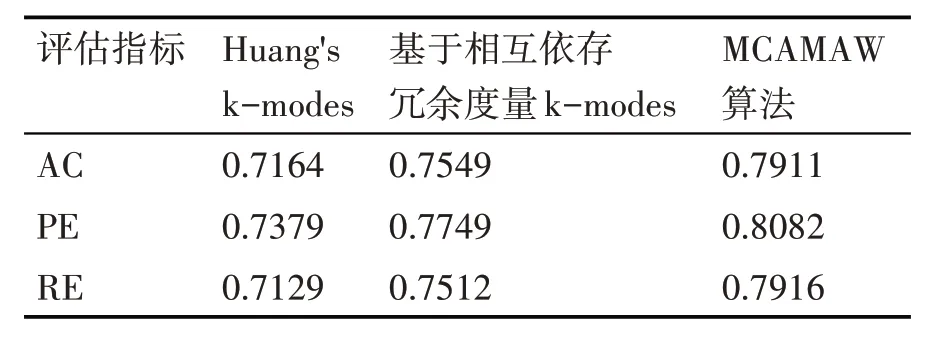
表2 Mushroom数据集
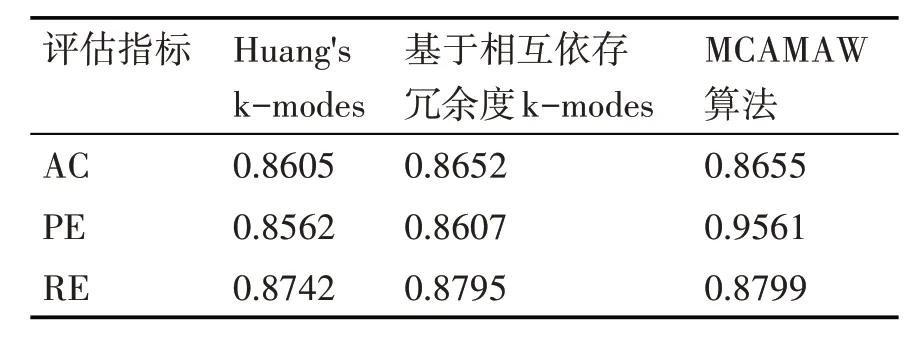
表3 Vote数据集
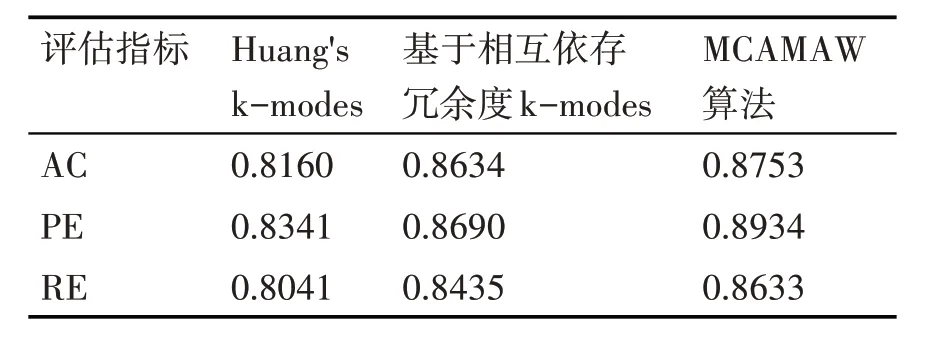
表4 Breast-cancer数据集
7 结语
本文采用多属性权重,提出了一种k-modes 聚类算法。该算法从本地属性和相关属性两个角度,描述了数据对象的属性空间分布特征。在度量数据对象间的距离时,不仅考虑了数据对象本身的差异性,而且考虑了数据对象在整个属性空间结构中的差异性。此外,在属性值分布过于分散或相对均等时,可以根据属性值的平均权重进一步确定模式中的属性值,以便能够找到更恰当的属性值作为该类的模式,从而有效地提高聚类效果。
