基于无人机高光谱的马铃薯冠层叶片全氮含量反演
2023-08-29郭发旭杨婉霞
郭发旭,冯 全,杨 森,杨婉霞
(甘肃农业大学 机电工程学院,甘肃 兰州 730070)
氮肥在马铃薯生长发育过程中具有关键作用:氮素缺失会导致马铃薯植株矮小,生长弱,并引发减产;但若长期过量施用氮肥,不仅提高生产成本,而且残留的氮肥会造成土壤板结,加剧土传病害的发生,还会对土壤、水、大气等环境造成一定的不利影响[1-2]。因此,在马铃薯的大田生产中,应合理施用氮肥。
马铃薯与水稻、小麦、玉米并列为全球4大粮食作物[3],是我国西北干旱地区主要的粮食作物。对马铃薯氮素水平的快速准确检测,可以为科学施肥提供基础数据,在马铃薯精准化管理中具有关键作用[4-5]。传统的氮素估测需先在田间取样[6],然后在实验室内进行化学分析。虽然该方法的准确度较高,但对作物具有破坏性,并且耗时耗力。高光谱遥感技术可以快速、非破坏性地获取作物的冠层光谱信息,是当前精准农业研究的重点内容[7-9]。
目前,采用高光谱技术对作物氮素进行估测的研究已有不少。张瑶等[10]利用偏最小二乘和支持向量机方法建立了苹果叶片叶绿素含量与氮素含量的回归模型,发现支持向量机回归模型可以精确地估计果树叶片的叶绿素含量。李金梦等[11]采用连续投影法提取特征波段,结合偏最小二乘、多元线性回归和反向传播人工神经网络3种建模方法,建立了柑橘叶片的含氮量预测模型。张筱蕾等[12]建立了油菜叶片3个生长时期叶片氮含量和12个特征波段的最小二乘-支持向量机模型,并对不同时期油菜叶片的氮含量进行可视化分布表示。于雷等[13]基于迭代和保留信息变量法筛选大豆叶片的特征波长,建立大豆叶片SPAD值(代表叶片叶绿素含量的相对值)估算模型,发现支持向量机模型的估算效果最优。部分研究尝试从光谱信息中提取植被指数,用于构建氮含量估测模型。吴伟斌等[14]将英红九号茶树的叶面积指数和氮含量与高光谱特征变量进行相关性分析,选取相关性高的特征变量建立估算模型,发现用植被指数变量(红边面积/黄边面积)与氮含量建立的指数模型效果最佳。李粉玲等[15]发现,利用550~770 nm波段吸收峰总面积建立的叶片氮含量指数估算模型,其效果要优于用敏感波段建立的模型。还有研究人员通过分析夏玉米各生育期不同层位叶片氮素含量与光谱反射率的关系,选取最佳比值光谱指数建立起拟合各时期叶片氮含量的估测模型[16-17]。秦占飞等[18]用738、522 nm光谱反射率的一阶导数构建比值光谱指数(ratio spectral index,RSI),建立水稻叶片全氮含量预测模型。李岚涛等[19]通过构建的冬油菜冠层光谱参数R1259/R492和742 nm处一阶微分光谱值(FD742)与油菜植株氮素积累量建立指数模型,有效评价了油菜植株的氮积累量。
目前,基于高光谱的氮素反演研究多集中于小麦、水稻、大豆、玉米等禾本科作物上。马铃薯属于茄科植物,生长周期内对营养元素的吸收、传输等过程不同于禾本科植物:前期,营养元素由地下往地上输送,促进幼叶长成;后期,营养元素由地上往地下输送,以保证块茎的有效生长[20]。因此,已有的作物氮素状况监测模型并不能直接用于马铃薯氮素状况监测。植物冠层的高光谱数据能够直接反映植被特征,与植被指数相比可以提供更丰富的信息;但是,高光谱数据波段众多,波段之间具有多重共线性。偏最小二乘模型是多元线性模型的一种延伸,能够减少多重共线性问题;支持向量机可以解决高维特征回归问题,能够克服变量之间共线性的问题。为此,本试验首先对马铃薯原始光谱数据进行4种光谱变换,同时为减少全谱数据建模的冗余度,采用相关性分析(correlation analysis, CA)、竞争性自适应重加权(competitive adaptive reweighed sampling, CARS)、无信息变量消除(uninformative variables elimination, UVE)筛选特征光谱波长,然后使用偏最小二乘回归(partial least squares regression, PLSR)和支持向量机(support vector machine, SVM)算法建立马铃薯冠层叶片全氮含量(leaf nitrogen content, LNC)的估测模型,并比较不同模型精度,确定适用于马铃薯LNC估测的最佳模型,以期为大田马铃薯氮素的快速监测和养分精准管理提供理论依据和技术支持。
1 材料与方法
1.1 研究区和试验田概况
试验田位于甘肃省武威市黄羊镇河西绿洲现代农业试验示范基地(37°81′49″N,102°92′38″E)。该区域属温带大陆性干旱气候,光照充足,昼夜温差大,蒸发剧烈,降水稀少,多年平均气温8 ℃,年积温3 550 ℃,多年平均降水量164 mm,多年平均水面蒸发量2 000 mm,干旱指数15~25,年均日照时数3 000 h,无霜期150 d。试验区系典型的荒漠绿洲灌溉农业区,一般为一年一熟。试验区种植的马铃薯为青薯9号,属于晚熟鲜食品种,生育期115 d左右。马铃薯于2021年5月种植,10月中旬收获,采用全膜覆土垄播种植模式[21],行距400 mm,株距290 mm,灌溉方式为膜下滴灌。为了保证马铃薯生长条件基本一致,在整个生育期内不做任何特殊处理。
1.2 成像系统与无人机平台
使用Gaia Sky-mini2机载高光谱成像系统获取影像。该成像系统由江苏双利合谱科技有限公司自主研发,成像方式为内置推扫型,光谱范围是400~1 000 nm,光谱分辨率为3.5 nm,全幅像素为1 392 pixel×1 040 pixel,质量约1 kg,使用一个垂直于运动方向的面阵探测器,在运动平台向前运动中完成二维空间扫描。搭载成像系统的无人机平台为经纬M600 Pro六旋翼无人机(深圳市大疆创新科技有限公司)。空载时,该无人机单组电池的续航时间约为35 min,当最大负载6 kg时,单组电池的续航时间约为16 min。
1.3 影像获取与数据处理
1.3.1 高光谱数据获取
数据采集于2021年7—9月。无人机飞行时间均在11:00—13:00,且飞行时天气晴朗无风,光照强度稳定。飞行高度设置为100 m,镜头垂直朝下,视场角为22°,地面分辨率为0.039 m,航向重叠度80%,旁向重叠度60%。为消除大气、水汽对作物反射率的影响,在无人机起飞前,于拍摄区域内放置一块标定过的2 m×2 m的灰布,以便后期对光谱影像进行大气和反射率校准。
1.3.2 LNC测量
地面马铃薯叶片样本的采集时间与无人机飞行时间基本相同,其中马铃薯块茎形成期采集样本50份,块茎增长期采集样本60份,共采集样本110份。于每个样点采集半径约0.2 m范围内的马铃薯冠层健康叶片20片左右。采后立即装入自封袋,带回实验室。将采集的马铃薯新鲜叶片先于105 ℃杀青30 min,然后于80 ℃烘至质量恒定。取烘干的样本研磨粉碎,称取0.2 g,浓H2SO4消煮后,使用KjeltecTM8400凯氏定氮仪(瑞士FOSS公司)检测样本全氮含量。
1.3.3 高光谱数据处理
高光谱数据采集完成后,先在SpecView Version 2.9.3.8软件中对影像进行镜头校准、黑白帧校准、大气和反射率校准。为了消除环境噪声和仪器本身对光谱数据的影响,采用9点平滑法对采集的光谱数据进行平滑处理,并剔除首尾受水汽影响的波段,共获得176条有效光谱波段数据,波段范围为400~1 000 nm。将校正后的数据导入图像处理软件HiSpectral Stitcher 1.0.1中进行影像拼接,得到研究区完整的高光谱图像。在ENVI 5.3软件中,对应于地面样本采集位置,提取样点四周4个像素点的光谱反射率,取平均值,作为该样点的光谱反射率。
1.4 数据处理与分析
1.4.1 建模集和验证集划分
为提高模型预测精度,防止样本集出现极值化和聚集化,使用浓度梯度法(CG)[22]将本试验采集的样本划分建模集和验证集。具体地:将采集的110个样本看作总样本集,将各样点的LNC值由大到小排序,每间隔2个样本抽取出来作为验证集,最终共得到37个验证集样本,把剩余的73个样本作为建模集样本。将建模集和验证集的样本基本情况整理于表1。

表1 样本的冠层叶片全氮含量(LNC)统计值Table 1 Statistics of leaf nitrogen content (LNC) of samples
1.4.2 光谱的数学变换
本试验除了对原始反射率(R)进行分析外,还对R进行了4种简单数学变换,分别获得R的倒数反射率(1/R)、R的一阶微分反射率[D(R)]、R的二阶微分反射率[D(2R)]、R的倒数之(常用)对数反射率[lg(1/R)],旨在压缩背景噪声对目标光谱的影响,使数据更接近真实值,以便从中寻找出对LNC敏感的光谱指标。
1.4.3 特征波段筛选
高光谱的数据波段多,波段之间可能存在共线性。为了降低模型的冗余度,提高模型精度,需要筛选特征波段。本试验分别使用CA、CARS、UVE方法筛选特征波段。CA根据因变量与响应变量的相关系数来确定特征光谱波长[23]。CARS使用重加权采样(ARS)选取出PLSR模型中回归系数绝对值大的波段,淘汰权重小的波段,然后采用交叉验证方式选择模型交叉验证方差最小的集合,以此来选择最优波长组合[24]。UVE通过建立偏最小二乘回归交互验证模型,基于各波长的稳定性指数进行取舍,保留稳定值大的波长,剔除稳定值小的波长[25]。
1.4.4 建模方法
为了找到适于估测LNC的模型,本试验分别使用PLSR和SVM建立LNC含量估测模型。PLSR集成了多元线性回归、主成分分析和典型相关分析的优点[26-27],可同时考虑LNC和光谱反射率中主成分的提取,从而保证建模效果。SVM是一种有监督的机器学习模型,利用核函数将低维输入映射到高维特征空间,基于交叉验证法寻找最佳参数——C(惩罚参数)、径向基核函数中的核函数带宽λ和损失参数ε,利用最佳的参数训练模型[28],其中,λ控制了样本点在核函数中的衰减速度,ε控制了核函数的平滑度或模型的复杂度。
本试验采用决定系数(R2)、均方根误差(RMSE)来评价和解释光谱反射率与LNC的关系[29]。其中,R2表示实际值与估测值拟合的优劣,R2值越接近1,表明实际值与估测值的拟合度越高;RMSE反映实际值与估测值的离散程度,RMSE值越接近0,表明模型的预测结果越准确。
2 结果与分析
2.1 原始光谱与变换光谱的全波段建模
原始光谱与经过变换的光谱反射率之间存在明显差异(图1)。1/R和lg(1/R)变换对R进行了反转,原来的反射峰转换为吸收谷,光谱在750 nm以后趋于稳定,且值达到最低,可能会导致部分有效信息缺失;经过D(R)和D(2R)变换后,反射率在红边位置650 nm附近陡升,在730 nm附近反射率达到最大值后,又开始急速下降,符合植被光谱的典型判据。

R,原始光谱;1/R,取倒数;D(R),取一阶微分;D(2R),取二阶微分;lg(1/R),取倒数之常用对数。R, Raw; 1/R, Reciprocal; D(R), First-order differential; D(2R), Second-order differential; lg(1/R), Common logarithm of reciprocal value.图1 原始光谱与经过变换的光谱反射率曲线Fig.1 Spectral reflectance curves before and after transformation
建立R、1/R、D(R)、D(2R)、lg(1/R)反射率全波段光谱与LNC的PLSR和SVM模型。在利用PLSR构建的LNC预测模型中,D(2R)的建模效果最佳,其R2值(0.856 9)最大(表2),而RMSE值(0.201 7)最小;在利用SVM构建的LNC预测模型中,同样以D(2R)的建模效果最佳,其R2值(0.777 2)最大,而RMSE值(0.268 0)最小。这说明,经过二阶导数变换后的光谱数据适于建模,以下选择经过二阶导数变换后的光谱数据进行后续分析。

表2 基于原始光谱与经过变换的光谱反射率曲线构建的模型效果对比Table 2 Comparison of modeling effects based on spectral reflectance curves before and after transformation
2.2 特征波段筛选
2.2.1 CA法
对马铃薯冠层的LNC值与D(2R)做相关性分析(图2),在643.8 nm处,二者相关系数的绝对值(0.841)最大。将各波段二者相关系数的绝对值按照从大到小的顺序排列,选取相关系数绝对值大于0.7的波段作为特征波段。经过CARS变量筛选后特征波段的数量减少到26个,约为全波段的14.8%。

图2 叶片LNC与D(2R)的相关系数Fig.2 Correlation coefficient between LNC and D(2R)
2.2.2 CARS法
设置CARS法运行50次,交互验证20组。在变量筛选过程中,随着变量运行次数的增加,变量个数逐渐减少(图3)。当运行次数在1~30时,随着运行次数的增加,交叉验证的均方根误差(RMSECV)逐渐减小;当运行次数为30次时,RMSECV值最小;但当运行次数超过30次后,RMSECV值随运行次数的增加逐渐增大,可能是随着运行次数的增加,CARS算法去除了与LNC相关性较强的波段,导致构建的PLSR模型的精度下降。从各光谱变量回归系数的变化路径可以看出,当采样次数为1~30次时,回归系数的变化趋于平缓并且收敛到一个稳定值,继续增加采样次数,回归系数出现一些波动,采样次数为30时,RMSECV值最小,说明CARS方法具有较好的稳定性,其结果可靠。经过CARS筛选后特征波段的数量减少到12个,约为全波段的6.8%。
2.2.3 UVE法
基于UVE法的D(2R)光谱特征波段筛选结果如图4所示。图中紫色竖实线为真实变量和随机变量的分隔线,分隔线左侧和右侧均为176个变量,红色曲线是真实波段变量,蓝色曲线为加入的随机噪声变量,两条水平虚线是变量稳定性的上、下限,两条阈值线之间的波段被认作无效信息予以剔除,阈值线之外的波段可作为有用信息波段。经过UVE变量筛选,特征波段的数量减少到19个,消除了原光谱中大部分对建模贡献小的波长变量,筛选后约为全波段的10.8%。

图4 无信息变量消除(UVE)算法的运行结果Fig.4 Running results of uninformative variables elimination (UVE) algorithm
2.2.4 不同方法的结果对比
将采用上述3种方法筛选出的特征波段整理于表3,LNC敏感波段在可见光和近红外区域都有分布。CA、CARS、UVR算法筛选的特征波段分别占全波段的14.8%、6.8%、10.8%,说明上述3种筛选方法均可在一定程度上实现数据降维。

表3 特征波段筛选结果Table 3 Characteristic band screening result
2.3 LNC估测模型构建与比较
2.3.1 PLSR模型
将CA、CARS、UVE方法筛选出的D(2R)特征波段分别记作CA-D(2R)、CARS-D(2R)、UVE-D(2R),分别利用筛选出的特征波段和D(2R)全波段作为自变量,以马铃薯冠层LNC作为响应变量,采用PLSR建立估测模型。对比各模型的效果(表4),基于CA-D(2R)建立的预测模型的R2值最小,小于0.7,而基于UVE-D(2R)建立的预测模型效果最好,在验证集上的R2值(0.806 8)最大,而RMSE值(0.193 2)最小。

表4 基于不同波段的PLSR建模结果比较Table 4 Comparison of PLSR modeling results based on different bands
用基于UVE-D(2R)构建的PLSR模型[简记为UVE-D(2R)-PLSR]的实测值和预测值绘制散点图(图5),若其分布越接近于y=x,则说明模型的估测精度越佳。经分析,所构建的模型的实测值与预测值的散点趋势线斜率为0.803 0,说明该模型能够较为准确地估测马铃薯LNC含量。

图5 基于UVE-D(2R)构建的PLSR模型的验证结果Fig.5 Validation of constructed PLSR model based on UVE-D(2R)
2.3.2 SVM模型
以筛选出的特征波段和D(2R)全波段作为自变量,构建其与马铃薯LNC的SVM估测模型。在建立SVM模型时,核函数类型选择高斯径向基核函数(radial basis function,RBF),采用交叉验证法确定影响模型回归的最佳参数(表5)。在建立的PLSR预测模型中,只有基于D(2R)全波段的预测模型的R2值小于0.7,基于CARS-D(2R)的模型预测效果最好,在验证集上的R2值(0.831 6)最大、RMSE值(0.183 0)最小。将基于CARS-D(2R)构建的SVM模型[简记为CARS-D(2R)-SVM]的实测值和预测值的空间分布绘制成散点图(图6),其散点分布接近于y=x,离散程度较小,模型实测值与预测值的散点趋势线斜率为0.825 2。
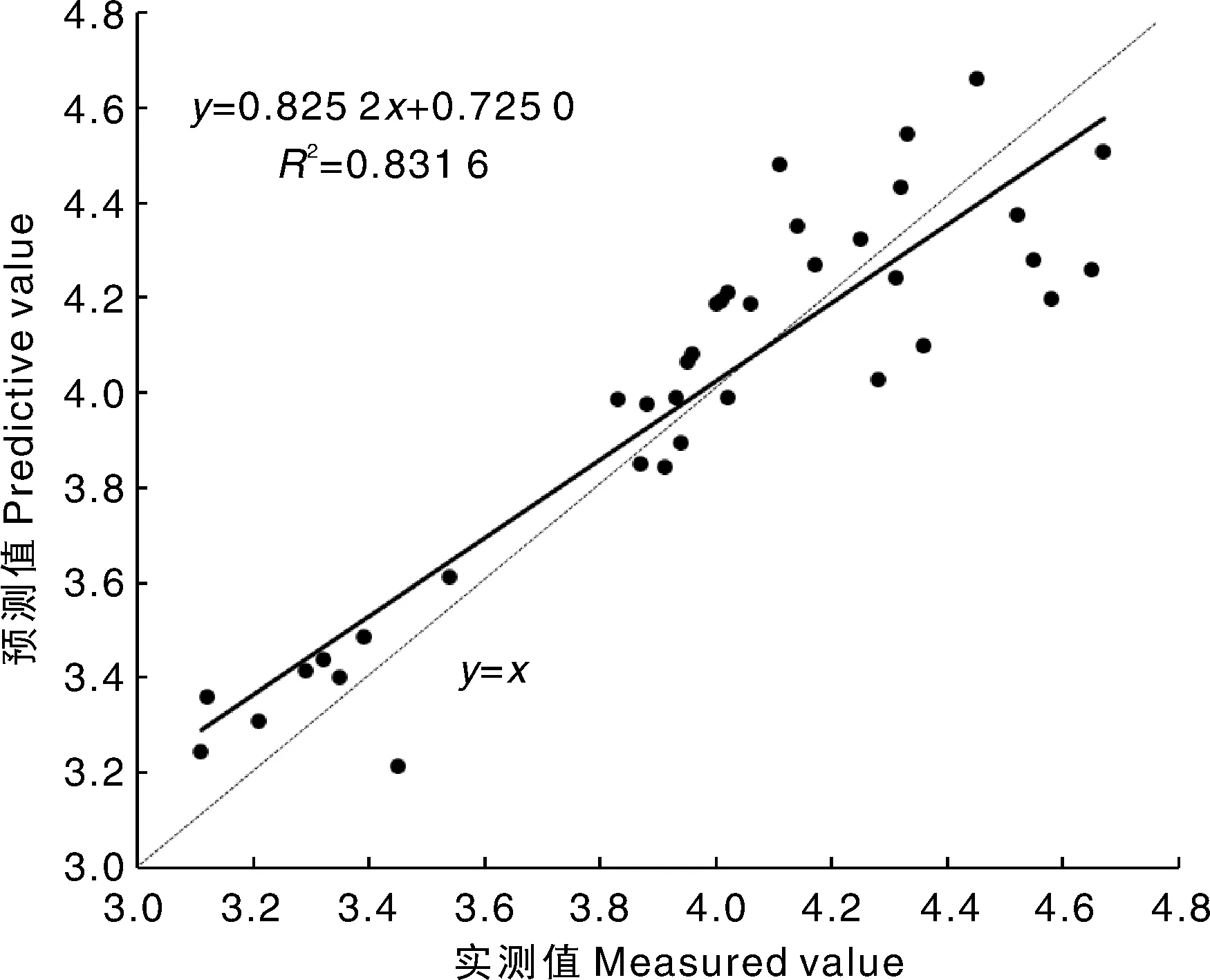
图6 基于CARS-D(2R)构建的SVM模型的验证结果Fig.6 Validation of constructed SVM model based on CARS-D(2R)

表5 基于不同波段的SVM建模结果比较Table 5 Comparison of SVM modeling results based on different bands
2.3.3 模型对比
无论是采用PLSR还是SVM建模,用CARS或UVE筛选的特征波段建立的模型,其在验证集上的效果均要优于用D(2R)全波段建立的模型。这说明,采用CARS、UVE筛选特征波段可以有效地降低马铃薯冠层LNC估测模型的冗余度,提高模型精度。
将上述建立的效果最优的SVM模型与PLSR模型做一对比,CARS-D(2R)-SVM模型在验证集上的R2值更大,而RMSE值更小,说明其优于UVE-D(2R)-PLSR模型。
2.4 大田马铃薯LNC估测
利用建立的CARS-D(2R)-SVM模型估算试验地高光谱图像中每个像素点的LNC值,用伪彩色处理绘制出马铃薯冠层LNC反演图(图7),图中的不同颜色和颜色深浅代表了马铃薯冠层LNC的高低。通过对马铃薯冠层LNC值进行反演制图,可以直观地掌握不同区域马铃薯的生长状况,以便对马铃薯追肥实施有效管理。
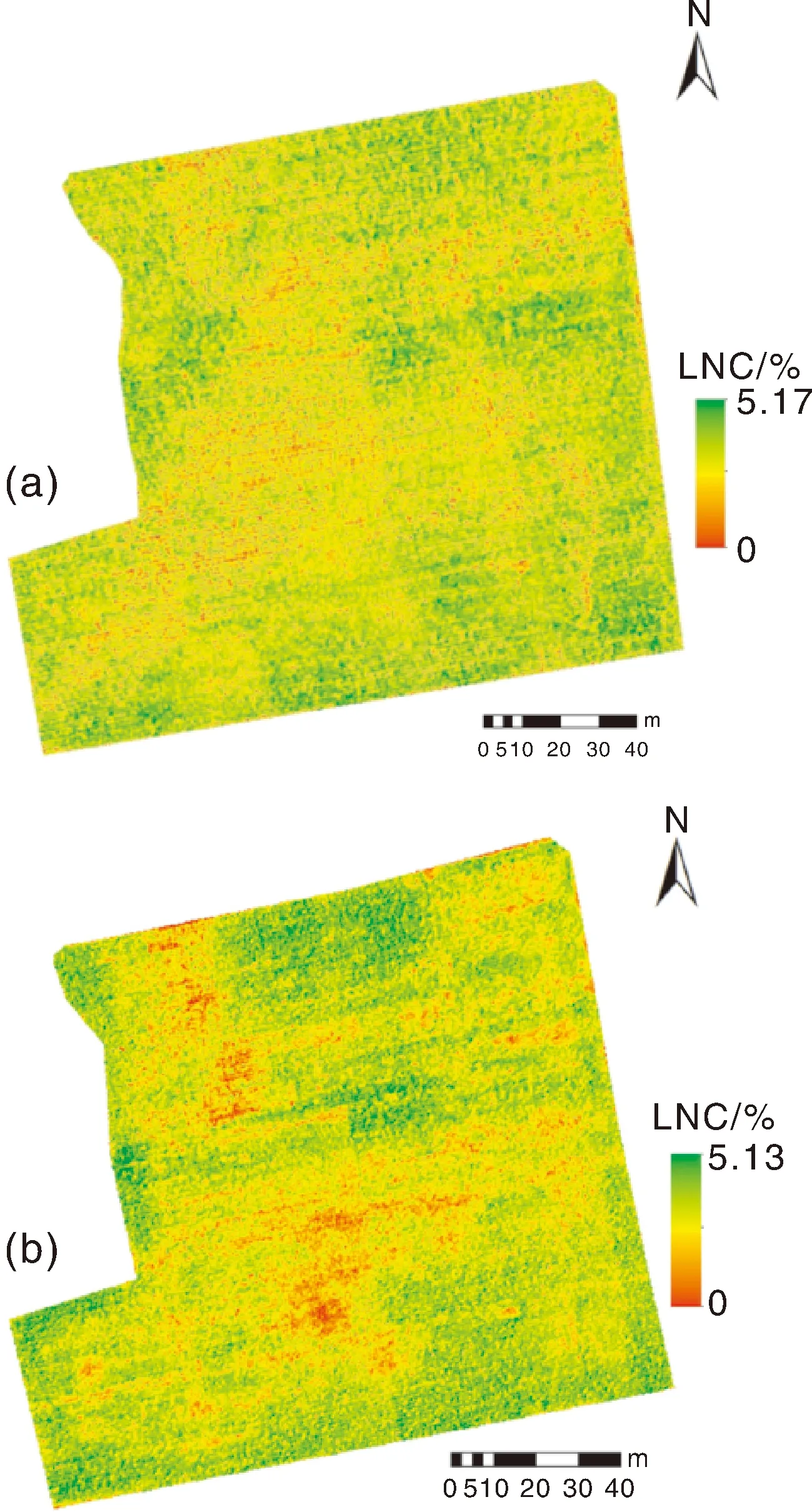
图7 2021-07-28(a)和2021-08-19(b)马铃薯冠层的LNC反演估测图Fig.7 Inversion and estimation of potato canopy LNC on 2021-07-28 (a) and 2021-08-19 (b)
3 讨论
作物冠层光谱易受到作物结构特征和作物周围环境的影响,光谱预处理可以通过消除光谱噪声和环境噪声信息进而增强光谱特征[30]。本研究深入探讨了倒数变换、一阶微分变换、二阶微分变换和倒数之对数变换在马铃薯LNC估测方面的适用性。通过建立不同变换下马铃薯LNC估测的PLSR和SVM模型,对比发现,二阶微分是最优的光谱预处理形式,能够有效反映研究对象的光谱特征,提高模型的稳定性与精度。随着计算机科学的快速发展,当前可用于波段筛选的方法很多,本研究基于D(2R)光谱数据,利用CA、CARS、UVE分别筛选出了特征波段,特征波段在可见光和近红外区域内都有分布,有效降低了数据维度,降低了光谱间的共线性,这与马怡茹等[30]利用连续投影算法和CARS算法筛选的敏感波段相似。本研究中,用CARS筛选的波段建立的SVM模型的效果最好。郭阳等[31]对比了3种波段筛选方法在预测哈密瓜可溶性固形物含量上的效果,得出相同的结论。
机器学习算法已被广泛应用于高光谱数据分析和植被表型参数反演,但针对不同作物和表型参数选用的机器学习算法之间存在差异。张瑶等[10]发现,SVM模型可以很好地估算苹果树叶片的叶绿素含量。张筱蕾等[12]利用PLSR模型反演了油菜不同时期的叶片氮含量。本研究建立的马铃薯LNC估测模型中,SVM模型的表现更优,CARS-D(2R)-SVM模型在建模集上的R2值为0.839 0、RMSE为0.215 2,在验证集上的R2值为0.8316、RMSE为0.1830,这表明在本研究条件下SVM模型在估算马铃薯LNC上更有效。
韩康等[32]利用手持式地物波谱仪获取马铃薯冠层光谱数据,建立马铃薯苗期氮含量预测模型,模型的R2值为0.913,结果优于本研究,但其模型仅适用于马铃薯苗期的氮含量估测。本研究利用无人机获取高光谱数据,基于马铃薯块茎形成期和块茎增长期数据建立模型,可以实现大尺度的LNC估测。但本研究只是针对特定地点和特定品种马铃薯展开的研究,这在一定程度上限制了本文模型在更为复杂环境下的应用。在今后的研究中,应针对不同地区、不同品种和不同种植年份开展试验,提高模型的泛化能力。
