基于PSO-XGBoost 的矿井突水水源快速判识模型
2023-08-29董东林张陇强张恩雨傅培祺陈宇祺林新栋李慧哲
董东林 ,张陇强 ,张恩雨 ,傅培祺 ,陈宇祺 ,林新栋 ,李慧哲
(中国矿业大学(北京) 地球科学与测绘工程学院, 北京 100083)
0 引 言
煤炭作为我国短时间内不可替代的稳定主体能源,煤炭资源的安全、清洁、高效开采关乎我国能源安全和经济的健康可持续发展[1-3]。然而,我国煤矿水文地质条件异常复杂,煤层在开采过程中水害频发[4],不仅长期制约着我国煤炭资源的安全开采,还严重威胁着井下矿工的生命安全。矿井发生突水后,快速、准确地判识突水水源是矿井水害治理的关键[5-6]。传统的矿井突水水源判识法主要有水位动态观测[7]、水温、水化学[8-9]、同位素示踪[8-10]及基于GIS[11-12]等方法。地下水化学能真实反应地下水中不同离子的本质特征[13],众多学者基于水化学参数分析,以不同离子作为主要判别指标,建立相应的突水水源识别模型[14],为基于水化学判识突水水源奠定了深厚基础。常见的突水水源判识模型大体分为基于数学方法(多元统计[15-16]、模糊数学法[17]、灰色系统法[18])和结合计算机技术(神经网络[19]、SVM法[20]、可拓识别法[21])两大类。这些方法在提高矿井突水水源判别准确性的同时,还推动了矿井防治水理论的发展,然而这些方法在应用过程中仍旧存在局限和不足。比如,基于水化学参数的判别模型虽然性能较为稳定,但识别时间长,效率低,较难适应矿井突水的实时监测[22],不宜在短时间内快速开展矿井突水灾害防治;神经网络具有较强的非线性映射能力、自学习能力和容错性,但对训练样本要求较高,样本选择的合适与否将直接影响到最终的判识结果[23];模糊数学和灰色数学法较难确定因子权重和隶属度[24];可拓识别法在处理差异较小的样本数据时容易造成误判。近年来,紫外−可见分光光度法被广泛应用于医学、环境、化工、地质学等诸多领域,但鲜有文献报道利用该技术方法来识别矿井突水水源的应用研究。紫外可见分光技术凭借时间响应快、精度高和抗干扰等特点,为矿井突水水源判识提供新的思路和方法。
光谱数据承载着测试水源的重要特征信息[25],因此,基于光谱数据的突水水源判别是高维数据的多分类问题。常见分类算法有决策树(DT)、随机森林(RF)、BP 神经网络、支持向量机(SVM)、XGBoost 等。决策树算法易于理解和解释,但如果树深度过大,会导致过拟合问题,此外,决策树算法对于连续性变量处理较为困难[26]。随机森林算法虽然改善了决策树容易过拟合的缺陷[27],但该算法在解决不平衡数据集分类精度方面仍有待进一步提高。BP 神经网络基于反向误差传播原理,网络训练耗时长,且需多次训练才能获取较为稳定的模型。SVM分类适合于处理高维模式下的小样本数据[28],但受参数影响明显,对于噪声和异常值较敏感[29]。XGBoost 算法是一种提升树模型,基于对GBDT 算法的高效改进,兼具对高维数据集的规模求解和精准分类,并且该算法引入正则项技术避免了过拟合情况,有效提高了模型分类识别的泛化能力。
研究基于辽宁抚顺煤田老虎台矿不同类型水样的40 组光谱数据,采用XGBoost 模型进行矿井突水水源识别研究,并利用粒子群优化算法(PSO)对XGBoost 模型的学习率(learning rate)、随机采样率、最小叶子节点样本权重(min child weight)和树最大深度(max depth)等7 项参数进行优化,建立PSOXGBoost 分类识别模型,以实现对矿井突水水源的精准高效预测,为矿井突水水源识别提供新的思路与方法。
1 PSO-XGBoost 模型基本原理及构建
1.1 XGBoost 算法基本原理
XGBoost 是基于 Gradient Boosting Decision Tree(GBDT)算法高效改进而来,兼具良好的分类性能和运行速度[30]。相较于Boosting 库,XGBoost 算法通过对损失函数二阶泰勒展开,并引入正则项以实现整体最优解,以此来控制模型整体复杂度,从而有效提高了算法的泛化能力。此外,为防止出现过拟合问题,该算法采用同时对特征选择并行处理的方法,使得该算法运行速度更快,且结果更具有可解释性。
假设给定包含n个样本数量的数据集D={(xi,yi)|xi∈Rm,yi∈R,i=1,2,···,n}由m个特征组成,共n个样本,其中Rm和R分别为m维实数向量数据集和实数集合。
式中:fk为一棵回归树;K为回归树的总数目;F为回归树空间。
目标函数Obj为
式中:l为损失函数,用来衡量分类预测值和真实值之间的误差;为分类预测值;yi为真实值;Ω(fk)为正则项。
XGBoost 算法采用梯度提升迭代运算,每经过一次迭代过程,将添加新的回归树,则第t次迭代运算结果为:
将式(3)代入式(2),计算出第t次迭代的目标函数表达式为Obj(t):
式中:σ为常数项。
将式(4)二阶泰勒展开,并加入正则项Ω(fk)防止出现过拟合现象。
式中:γ为叶子树惩罚系数;T为树叶子节点数目;ω为叶子权重;λ为权重惩罚系数;|| ||为对ω2进行正则运算。
由于XGBoost 算法中参数较多,调参过程随机性大,需要通过参数寻优来提高模型的分类预测精度。因此选用处理多参数优化问题效果显著的PSO算法优化模型参数,通过减少参数选取的随机性,以此来提高模型的分类预测性能。
1.2 粒子群优化算法(PSO)
粒子群优化算法(PSO)是一种基于模仿鸟群觅食行为构建起来的群智能算法[31-32]。相比于蚁群、遗传和模拟退火等智能优化算法,该算法完善了蚁群算法收敛速度慢和遗传算法、模拟退火算法易陷入局部最优解等缺陷[33]。PSO 算法凭借参数少、结构简单、效率高、容易实现以及能解决非凸问题等优点,已被广泛用来解决支持向量机(SVM)[34]、BP 神经网络[35]、极限学习(ELM)等算法的优化问题,并且优化效果显著。PSO 算法将优化问题的解定义为在有限维度空间内搜索粒子,每个粒子由一个位置矢量和速度矢量组成,所有粒子共同合作择优,通过自身最优值和粒子群的最优值向更好的位置搜索。每个粒子通过适应度函数计算适应值来衡量自身位置的优劣,同时粒子群中所有粒子都追随当前最优粒子在解空间中位置进行搜索。
假设有一个D维的搜索空间,群中粒子总数为m,第i个粒子的位置表示为向量Xi=[xi1,xi2,···,xiD]T,速度向量表示为Vi=[Vi1,Vi2,···,ViD]T,该粒子自身搜索到的最优位置为Pi=[Pi1,Pi2,···,PiD]T,整个种群搜索到的最优位置表示为Pg=[Pg1,Pg2,···,PgD]T,这里g为粒子编号,g∈(1,2,3,···,m)。初始化粒子群后PSO 算法将计算每个粒子的适应值,通过不断更新迭代来搜索最优解。每进行一次迭代,粒子Xi通过个体最优值Pi和群体最优值Pg来更新自身的位置和速度,迭代公式如下:
式中:k为迭代次数;ω为惯性系数,用来控制算法的收敛和搜索能力;r1、r2为[0,1]之间的随机数;c1和c2分别为加速因子,表示将粒子推向个体最优值Pi和群体最优值Pg的加速项权重。
1.3 PSO-XGBoost 模型构建
基于XGBoost 原理与PSO 算法理论,将PSO 应用于XGBoost 分类器的参数寻优,构建PSO-XGBoost矿井突水水源光谱分类预测模型(图1),流程为:
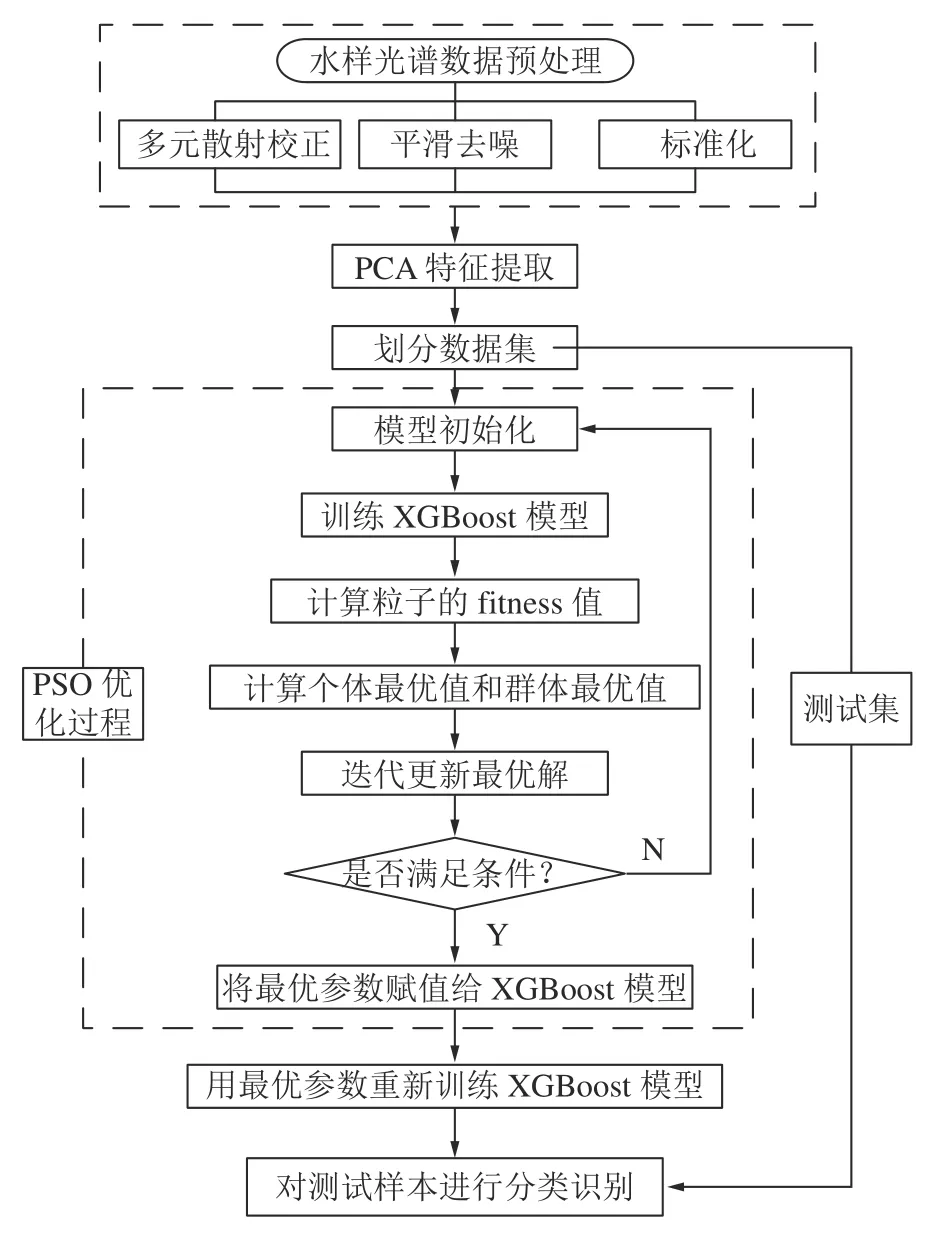
图1 矿井突水水源识别模型流程Fig.1 Flow of mine water inrush source identification model
1)对测量得到的光谱数据进行多元散射校正、平滑去噪及标准化预处理;
2)对预处理后的光谱数据进行主成分分析,依照累计贡献率选取若干主成分,根据主成分分析结果重新计算数据集,以此来实现数据集降维;
3)按照7∶3 的比例划分训练集与测试集,设定适当的适应度函数并初始化粒子个体最优值和全局最优值,对learning_rate、max_depth 等参数进行寻优;
4)迭代更新粒子速度与位置,通过计算其适应度值,不断更新个体最优值与全局最优值至达到迭代终止条件;
5)选取最优参数值,构建参数优化的XGBoost 分类模型,导入训练集进行模型训练学习。
1.4 模型评价指标
研究选择判识正确率和对数损失值对模型的分类判识效果进行评价。其中正确率A计算公式为
其中:np为模型正确分类样本个数;n为样本总个数。模型正确分类的样本数越多,正确率越高,模型分类效果越好。
对数损失值类似于逻辑回归中的损失函数值,通过对错误分类结果的惩罚修正,实现对分类器的分类效果量化,其计算公式为:
其中,Y为输出变量;X为输入变量;L为损失函数;N为输入样本量;M为分类类别数;yij用于表示类别j是否是输入实例xi的真实类别;pij为模型输入实例xi属于类别j的概率。对数损失值越接近0,表示损失越小,模型分类效果也就越好。
2 PSO-XGBoost 模型应用
2.1 矿区概况
老虎台煤矿开采于1907 年,位于辽宁省抚顺煤田中部,井田东西部分别与龙凤矿报废井田和西露天矿井田相邻,南至煤层露头,北至最终开采境界线,面积约为6.88 km2(图2)。矿区整体地势南高北低,南部最高为老虎台山,中部矿区地势平坦,浑河从矿区北部由东向西流过,是矿区水系的主干流。

图2 研究区位置Fig.2 Location of the study area
矿区共发育4 个含水层,自上而下依次为:第四系冲积砂及砾石孔隙含水层、古近系西露天组泥灰岩裂隙含水层、古近系栗子沟组和老虎台组凝灰岩、玄武岩弱含水层和白垩系龙凤坎组砂砾岩含水层,其中第四系冲积砂、砾石含水层为主要含水层,其余为弱含水层(图3)。各含水层水文地质特征如下:
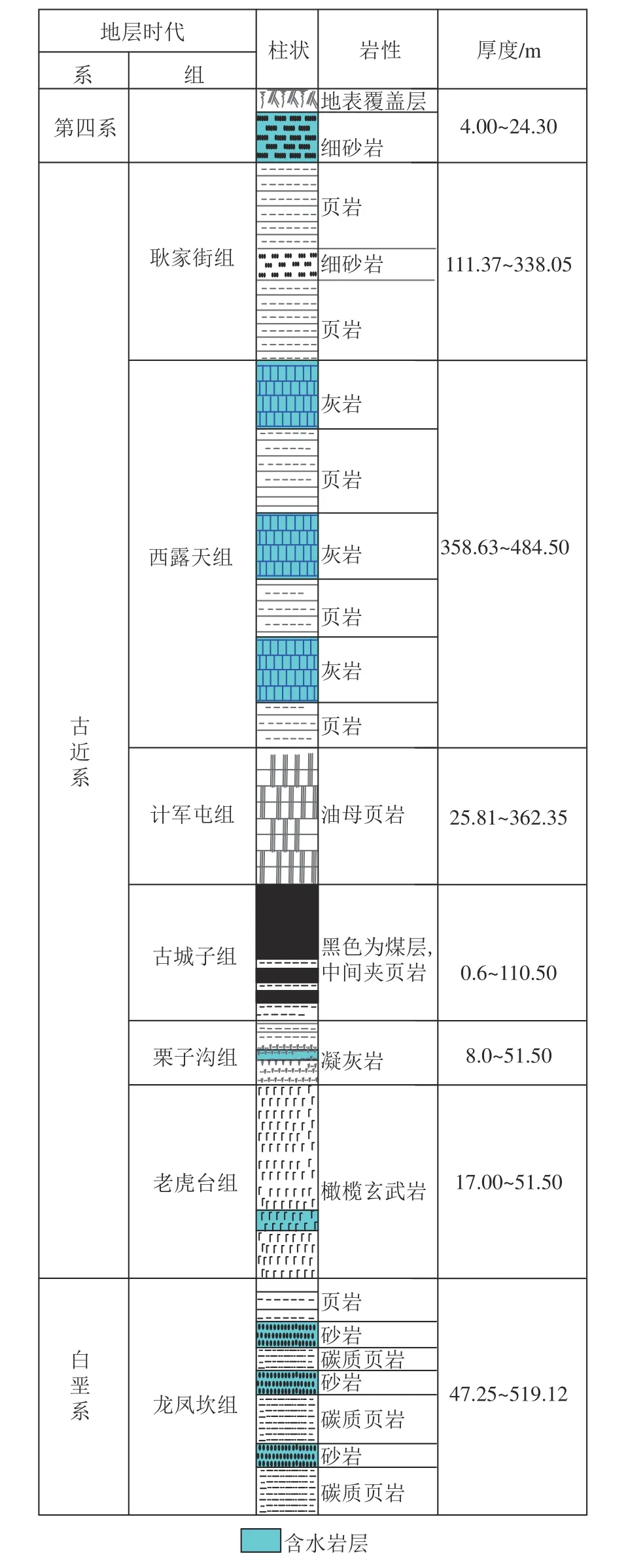
图3 含隔水层垂向示意Fig.3 Vertical of aquifer layer
1)第四系冲积砂及砾石孔隙含水层。第四系冲积层位于基岩剥蚀面之上,厚度4~24.3 m,由粗细不等的砂卵石组成。含水层上部为黄色亚粘土及砂土覆盖,底部为卵石, 单位涌水量q=0.841~4.12 L/(s·m),渗透系数k=10.27~92.8 m/d。该层受大气降水补给,富水性强,是矿井主要含水层,水质类型为HCO3-Ca-Mg 型。
2)古近系西露天组泥灰岩裂隙含水层。该层全区发育,属泥灰岩绿色页岩系,为绿色含钙质页岩及绿色石灰岩互层,其单位涌水量q=0.07l L/(s·m),渗透系数k=0.065 m/d,水质类型为SO4-HCO3-Ca-Mg型,属弱矿化淡水。
3)古近系栗子沟组和老虎台组凝灰岩、玄武岩弱含水层。由浅灰绿−暗灰绿色凝灰岩及橄榄玄武岩组成,位于煤层底板以下,弱含水。单位涌水量q=0.516~0.000 015 l L/(s·m),渗透系数k=1.178~0.228 m/d。该层在煤层露头接受大气降水和第四纪冲积层孔隙水补给,采掘工作面揭露时,局部表现为滴水和淋水,有的地点为裂隙水。
4)白垩系龙凤坎组砂砾岩含水层。该层分布在井田西部,由不同岩石的角砾组成,岩石主要为花岗片麻岩,石英及玄武岩,微弱含水,其单位涌水量为0.001 89~0.002 47 L/(s·m),渗透系数为0.000 462 3~0.007 84 m/d,平均水位标高76.20 m。
2.2 数据采集与处理
在老虎台煤矿防治水专业人员的指导下,依据矿井突(淋)水特点和以往突水情况,科学选取了地表水体、第四系冲积砂及砾石孔隙含水层、古近系西露天组泥灰岩裂隙含水层和老虎台矿东部龙凤井田老空积水4 种水样类型。每种类型水单独采集10 组,总计40 组水样,水样信息及编号见表1,对采取的水样进行密封、避光运输和保存。采用DR-3900 型分光光度计对采集到的水样进行紫外-可见光光谱测量,波长范围设置为320~1 100 nm,采样间隔为1 nm,在测量前用静置10 min 的超纯水作为参比溶液进行基线校准,最终测得40 组光谱数据,各水样光谱曲线如图4 所示。

表1 水样信息及编号Table 1 Water sample information and number

图4 原始水样光谱曲线Fig.4 Spectral curve of the original water sample
图4 显示光谱数据测量波段内的最大值均集中在紫外光区,符合物质对光的波长选择性吸收的原理。由于本次研究集中在紫外−可见光波段,因此只选取320~700 nm 的波段测量值作研究数据集。在光谱测量过程中,可能受到光源不稳定性、光路衰减和末端吸收、电路噪声及外界杂散光等多种因素的影响,使得光谱图像受到噪声干扰。对此选用平滑去噪和多元散射校正法对光谱数据进行预处理,以增强光谱数据特征并消除干扰。平滑去噪选用Savitzky-Golay 卷积平滑法,先从4 类水样中各取一组样本计算不同窗口宽度和多项式阶数取值下的均方差值(MSE),确定出最佳的S-G 法参数取值,得到的评价见表2。综合来看,当窗口宽度取5,多项式阶数取3 时有最小的MSE 值,采用该参数组合对数据集进行去噪处理。

表2 Savitzky-Golay 卷积平滑评价指标Table 2 Evaluation indexes of Savitzky-Golay convolution smoothing
对去噪后的数据集进行多元散射校正处理,减少由于水样散射水平不同导致的光谱差异,将同一类水样的谱线进行聚拢,最终预处理完成得到的水样光谱曲线如图5 所示。经过光谱预处理后,各水样光谱图像之间的差异得到了显著增强,谱线的灵敏度也有所提高,更易于后续模型的分类识别。
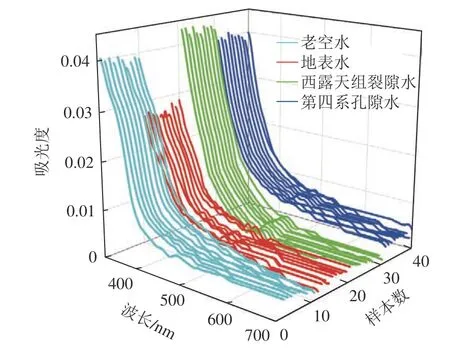
图5 预处理后的水样光谱曲线Fig.5 Spectral curve of pretreatment water samples
对预处理后的光谱数据min-max 标准化处理,并采用主成分分析法(PCA)对其进行特征提取。低维度的数据能加快识别算法的运算速度,同时让数据的特征更明显,提升识别准确度。设置累计贡献率为90%,获取5 个主成分,其累计贡献率见表3,降维处理后的各主成分荷载得分如图6 所示。主成分分析后的总数据点数从15 240 个减少到200 个,数据量减少了98.69%,极大地简化了数据处理工作量。基于PCA 得到的特征向量重新计算并划分数据集,考虑到样本数量较少,采用随机划分训练集、测试集的方式不能保证数据分布的一致性,因此采用分层随机抽样的方法按照比例7∶3 将数据集划分为训练集和测试集。

表3 主成分及其累计贡献率Table 3 Cumulative contribution of principal components
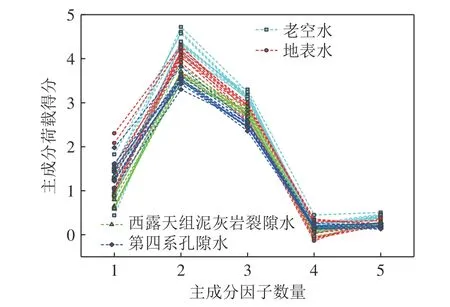
图6 主成分荷载得分Fig.6 Plot of principal component load scores
2.3 水源判别结果
对训练集运用PSO 算法对XGBoost 分类器的参数进行寻优,并将适应度判断标准设定为每次迭代中模型经过15 次交叉验证得到的平均准确率,同时设置输出迭代过程中相应的对数损失值进行辅助判别。本次需要优化的参数有7 类:包括learning_rate、n_estimators、max_depth、min_child_weight、gamma、subsample 和colsample_bytree,其中learning_rate 为学习率,控制每次迭代更新权重时的步长;n_estimators 代表树(弱分类器)的数量;max_depth用于指定树的最大深度;min_child_weight 用于指定叶子节点最小权重和;gamma 值表示节点分裂所需的最小损失函数下降值;subsample 用于控制每棵树随机采样的比例;colsample_bytree 用于控制每棵树随机采样的列数占比。经过100 次的迭代寻优运算,PSO 算法的准确率迭代至最大值0.924,相应输出的对数损失值也达到最小值0.427 6,并且在迭代18 次时收敛,最优参数迭代寻优过程如图7 所示,最终寻优得到的最佳参数取值如下:
基于最优参数组合建立PSO-XGBoost 分类预测模型,在训练集学习后对测试集进行分类判识,分类结果如图8a 所示。通过图8a 得出,PSO-XGBoost 算法分类性能良好,12 组测试集判别正确11 组,仅在对第九份样本分类时将泥灰岩裂隙水误判为了地表水,模型的分类准确率达到了91.67%。表明PSO-XGBoost 模型对于水源光谱曲线有很好的分类性能。
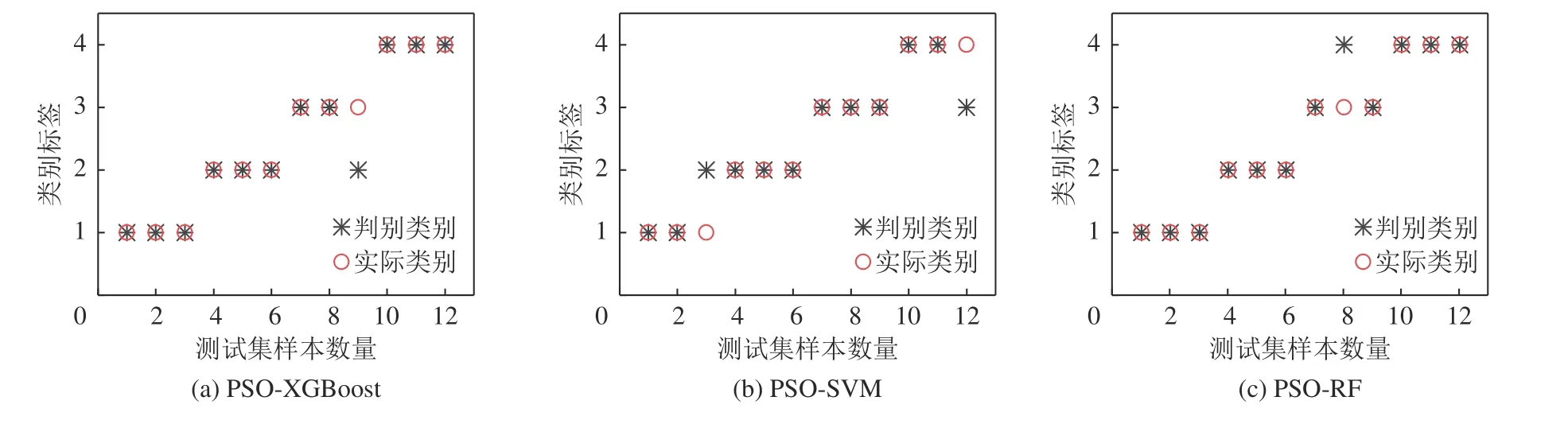
图8 3 种不同算法测试集判识结果Fig.8 Three different algorithm test sets to identify the results
3 不同模型判识结果对比
为进一步验证PSO-XGBoost 算法模型在突水水源识别研究中的优越性,在测试集上分别选择PSO 优化后的支持向量机(PSO-SVM)和随机森林(PSO-RF)两种不同分类方法与PSO-XGBoost 进行对比,各模型的迭代寻优过程如图9 所示。相较于PSO-XGBoost 模型的寻优迭代过程,PSO-RF 模型在第28 次迭代时收敛,最大准确率91.8%,最小对数损失值0.488 4;PSO-SVM 模型在第18 次迭代收敛,最大准确率89.3%,最小对数损失值0.650 5。综合判识准确率和对数损失值得出,PSO-XGBoost 的迭代寻优结果最好。其中PSO-SVM 模型中核函数选择为多项式核Poly,优化后的参数取值为C=9.18,degree=6.67;PSO-RF 模型优化参数取值为n_estimators=129,max_depth=3.86,min_samples_splits=6,min_samples_leaf=6,max_features=0.8。最终3 组对比算法得到的测试集分类结果如图8 所示,其中PSO-SVM模型判错2 组,准确率83.33%,PSO-RF 模型判错一组,准确率和PSO-XGBoost 模型相同,达到91.67%。

图9 3 种不同算法迭代寻优结果Fig.9 Iterative optimization search results of three different algorithms
为消除训练集、测试集划分时存在的潜在特殊性和偶然性,同时更客观地评估模型的泛化能力,采用100 次重复交叉验证的方法按照8:2 比例的重新划分训练集、测试集, 并选择平均准确率和平均对数损失值作为评价指标。首先将未优化的XGBoost 模型与PSO-XGBoost 模型进行对比,未优化的XGBoost 模型参数设为默认参数:n_estimators=300,max_depth=5,learning_rate=0.1,subsample=1,min_child_weight=1,colsampe-bytree=1,对比结果如图10 所示。可以看出,经过参数寻优后的PSO-XGBoost 模型平均准确率93.18%,高于未优化XGBoost 模型平均准确率87.76%,PSO-XGBoost 模型的平均对数损失值为0.462 5,低于XGBoost 模型的0.545 3。此外,PSOXGBoost 模型在判识平均准确率和平均对数损失值上的变化幅度更小,稳定性更好,表明PSO-XGBoost 判识模型稳定性良好,PSO 优化效果显著。
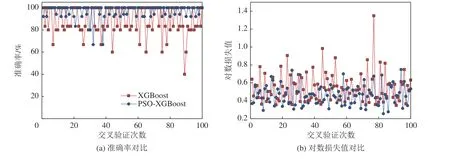
图10 优化前后准确率对比结果Fig.10 Comparison results of accuracy before and after optimization
进一步对PSO-XGBoost、PSO-SVM、PSO-RF 3种预测分类模型的准确性和对数损失值进行比较,对比结果见表4,对3 种不同模型进行100 次重复交叉验证结果如图11 所示。PSO-SVM 模型平均准确率87.56%,平均对数损失值为0.546 0,且稳定性最差;PSO-RF 模型虽然在测试集预测分类中得到了与PSO-XGBoost 模型相同的准确率,但在重复多次交叉验证评价的平均准确率为90.63%,平均对数损失值为0.562 3,综合判识效果低于PSO-XGBoost 的93.18%和0.453 4,表明PSO-RF 模型的稳定性不如PSO-XGBoost 模型。通过对比得出,PSO-XGBoost模型平均准确率达到三者中的最大值93.18%,平均损失值也最小,证明该模型不但具有较强的分类预测和泛化能力,而且还具有良好的稳定性。因此,通过对比不同分类算法得出,基于PSO-XGBoost 的矿井突水水源模型是高效可行的。

表4 不同分类模型的性能对比Table 4 Performance comparison of different classification models

图11 三种算法测试分类准确率比较Fig.11 Comparison of classification accuracy of s algorithms
4 结 论
1)基于水样光谱数据,结合XGBoost 原理与PSO 理论,构建适用基于光谱数据的矿井突水水源分类预测的PSO-XGBoost 模型,为矿井突水水源判识提供了新思路。
2)选用PSO 对XGBoost 算法参数寻优,选取最优参数组合,模型优化前后的分类准确率分别为87.76%和93.18%,对数损失值分别为0.545 3 和0.462 5,PSO-XGBoost 模型相较于优化前的XGBoost 具有更高的预测精度和更好的稳定性结果,表明PSO 能显著提升XGBoost 模型的分类性能。
3)测试结果表明,将PSO-XGBoost 模型与PSORF 和PSO-SVM 分类学习模型进行对比,测试集在PSO-SVM、PSO-RF、PSO-XGBoost 三类模型的平均判识准确率分别为83.33%、91.67%和91.67%,在多次交叉验证测试评价中,3 类模型的平均判识准确率分别为87.56%、90.63%、93.18%,平均对数损失值分别为0.546 0、0.562 3、0.453 4。对比结果表明PSOXGBoost 模型在分类预测精度和泛化能力方面明显优于其他2 种模型,因此,基于PSO-XGBoost 模型判识矿井突水水源的方法是高效可行的。
