基于LightGBM 的南阳市西部地区山洪灾害风险评价
2023-08-28范桂英高贤君占杨英邓莉婷
范桂英,汤 军,高贤君,占杨英,邓莉婷
(长江大学地球科学学院,湖北 武汉 430100)
0 引 言
山洪灾害是最具毁灭性的自然灾害之一,具有流速快、持续时间短和水位上涨快的特点[1]。据统计,1949-2015 年,全国共发生了53 000 余次山洪灾害[2],给人类生命财产和社会经济带来了巨大的灾害和损失。此外,研究表明,气温上升和人类活动将进一步加剧山洪暴发[3],因此,做出准确的山洪灾害风险评价,探究山洪灾害分布特征,总结山洪防治经验,制定相应的防洪管理措施对我国正在进行的山洪防治工作至关重要[4]。
山洪灾害风险评价是指综合多种影响因子,评估山洪发生的风险概率。针对山洪灾害风险评价,国内外学者开展了大量的研究。例如,Jiang[5]等使用综合变量模糊集方法构建了山洪灾害风险评价指标体系;王英[6]筛选了地形、气象、水文等各种指标,并采用层次分析法(Analytic Hierarchy Process,AHP)和熵权法获得了研究区域的山洪风险图。受到主观因素的干扰,预测的实际准确度很难达到应用要求[7]。此外,包括物理模型和水文模型等在内的许多类型的模型,已被广泛用于模拟山洪事件,例如,刘晓冉[8]等利用水动力淹没模型来绘制山洪灾害风险区划图;Naiji[9]等提出了河道洪水区的二维水动力耦合模型,并进一步绘制了洪水风险图。而这些模型存在各种不确定性[10]且需要高度准确的长期水文、地形和气象数据,同时这些数据都很难获取。因此迫切需要其他的方法和技术克服传统山洪灾害风险评价方法的缺点。
随着新的计算技术和高性能计算模型的进步,机器学习(Machine Learning,ML)模型在山洪灾害风险评价中得到了广泛应用,为准确评价山洪灾害风险提供了有利的条件。多项研究表明,ML 模型可以处理复杂输入数据且输出结果精度较高,显著克服了评估山洪风险的常用方法(如AHP)的缺点[11]。常见的ML 技术包括逻辑回归(Logistic Regression,LR)[12],支持向量机(Support Vector Machine,SVM)[13]、决策树(Decision Tree,DT)[14],随机森林(Random Forest,RF)[15]和神经网络(K-Neares Neighbor,KNN)[16]等。周超[17]等通过KNN、RF、AdaBoost(Adaptive Boosting)3 种算法分析江西省山洪灾害风险,结果表明AdaBoost 方法的预测精度高于KNN 和RF 两种方法,且具有更合理的评价结果;Ma[18]等利用XGBoost和SVM 两种算法对江西省山洪灾害进行评价,结果表明XGBoost有更好的评价精度;王倩丽[19]等利用RF 算法分析林州市山洪灾害风险,结果表明RF有着良好的预测精度。
一系列研究表明,不同研究区的山洪发育条件不同,所适用的山洪灾害风险评价模型也不同。LightGBM 模型是一种新兴的优秀集成学习算法,可以在不降低预测准确率的同时,大大加快预测速度,并降低了内存消耗。其被广泛应用于航班起飞延误预测[20]、音频场景分类系统[21]和企业财务风险预测[22]等领域,同时取得了较好的评价结果。然而,LightGBM 在山洪灾害风险评价领域相对较新,尚未得到广泛研究。因此,本文构建了基于LightGBM 算法的山洪灾害风险评价模型,并与RF 和XGBoost两种模型进行比较分析,寻找最佳性能模型,最后利用最佳模型绘制南阳市西部地区山洪灾害风险评价图,借此对其山洪灾害分布特征进行探究,分析山洪灾害成因,为南阳市山洪灾害防御管理规划工作提供科学依据。
1 研究区概况与数据预处理
1.1 研究区概况
南阳市海拔为72.2~2 212.5 m,三面环山,北靠伏牛山,东临桐柏山,西部为中、低山和丘陵,地形呈明显的环状和阶梯状特征。本研究选择南阳市的西部地区作为研究区域(见图1),具体涉及到了南阳市西峡县,内乡县及淅川县。研究区域地形复杂,山高沟多,满足山洪发生的基本孕灾条件[23]。年降水量703.6~1 173.4 mm,河流较多,小气候多变,导致降雨时空分布不均,河道比降大,汇流形成快,从而山洪灾害频发,造成严重的人员伤亡和经济损失。

图1 研究区地理位置与山洪点分布Fig.1 Geographic location and flash flood point distribution in the study area
1.2 数据预处理
1.2.1 指标选取及数据库建立
史培军教授在其所提出的灾害系统论中表示,灾害是致灾因子、孕灾环境和承灾体三者作用下的综合产物[24]。准确评价山洪灾害风险必须合理地选取山洪风险指标[25],本文基于文献综述和以往有关研究工作的基础及数据资料的可获得性,从致灾因子、孕灾环境和承灾体3 个方面,选取了年最大3 h 降水量均值、年最大24 h 降水量均值、年平均降水量、高程、坡度、距离河流距离、地形湿度指数、土壤湿度、土地利用类型、人口密度、GDP和农田生产潜力12项风险指标。
利用ArcGIS10.2 对每个风险指标数据进行重采样处理,得到尺度一致的栅格单元,各指标数据来源见表1。
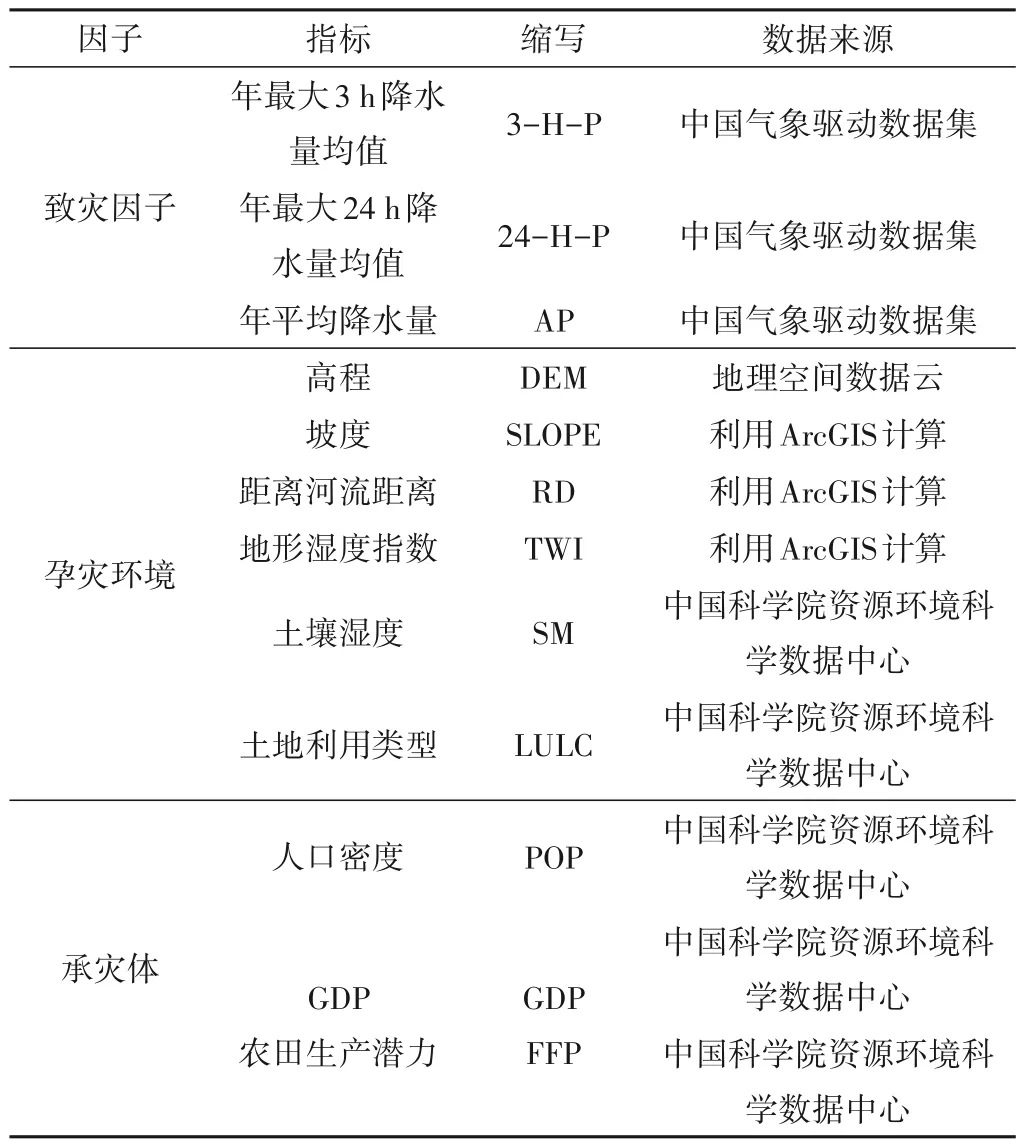
表1 数据来源Tab.1 Data sources
1.2.2 历史山洪灾害点数据库建立
根据《河南省2010-2017年山洪灾害防治项目》调查资料统计得到历史山洪灾害点数据,分布如图1 所示。为保证山洪灾害风险评价模型的可靠性,所选样本必须具有代表性。在距离山洪点100 m 外随机生成相同数量的非山洪点,使整个样本数据具有平衡性。采集山洪点以及非山洪点处各个指标的属性值。研究选用山洪点415 处,非山洪点415 处,共830 组正负样本。
2 研究方法
山洪灾害风险评价流程见图2。主要分为以下几个步骤:①相关数据的收集、确定山洪风险指标以及山洪灾害数据库的建立;②从整体样本中选取70%作为训练样本,30%作为测试样本;③模型的建立训练以及超参数优化;④3 种模型评价比较;⑤绘制山洪灾害风险评价图并进行分析验证。主要操作平台基于ArcGIS和Jupyter,编程语言为Python。
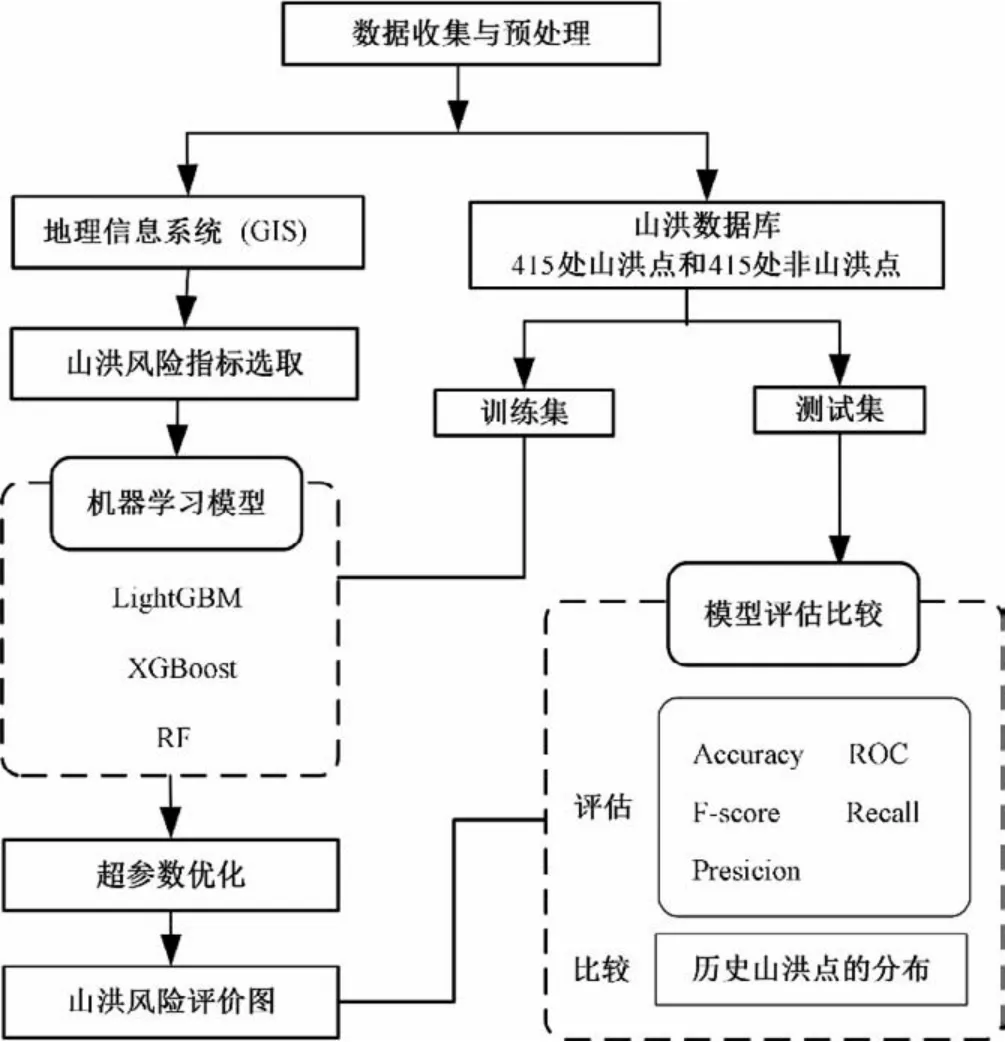
图2 山洪灾害风险评价流程图Fig.2 Flow chart of flash flood disaster risk assessment
2.1 机器学习模型
2.1.1 轻量级梯度提升算法(LightGBM)
LightGBM 是Microsoft 开发的梯度增强决策树(Gradient Boosting Decision Tree,GBDT)算法的变体。随着数据量的几何级增长,GBDT面临着准确度和处理时间的问题,此时LightGBM算法被提出,LightGBM 算法可用于分类和回归任务,在不降低预测准确率的同时,它大大加快预测速度,并降低内存消耗[26]。在降低训练数据方面,LightGBM 算法采用了Leaf-Wise 生长策略。Leaf-Wise 生长策略相对于传统的Level-Wise 生长策略来说,是一种更为高效的策略,从所有当前叶中找到具有最大分裂增益的叶,然后进行分裂,如此循环,如图3 所示。同Level-Wise 生长策略相比,在分裂次数相同的情况下,Leaf-Wise 生长策略可以降低更多的误差,获得更好的精确度。
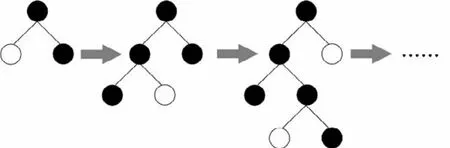
图3 Leaf-Wise原理Fig.3 The Leaf-Wise principle
2.1.2 随机森林算法(RF)和梯度提升树算法(XGBoost)
RF 是一种简单且广泛使用的多元分类器[27],它使用集成技术在不同的数据集上使用多数投票或对最终结果进行平均来将多个决策树分类器相互匹配。这有助于减少过度拟合的问题并提高预测性能[28]。设某随机森林由h1(x),h2(x),…,hk(x)共k棵决策树构成,对于样本的任意两个特征变量X和Y,其边缘函数[29]公式如下:
式中:I()表示转换函数;Y和j分别为随机森林判定的正负类别;avk()表示求均值;ma(X,Y)的值与特征提取效果成正比。
XGBoost 是一种旨在提高性能和速度可扩展的树提升方法[30]。它不是对独立的树求平均值,而是通过迭代的方式将多个决策树模型组合在一起,在考虑模型精度的同时,通过添加正则化项抑制模型过拟合,利用最小的损失函数来训练模型的预测能力,最后形成结构更优、精度更高的分类模型。该模型的目标函数公式如下:
式中:i表示第i个样本;yi表示真实值;表示预测值;l(yi,)表示训练损失函数;Ω(fk)表示正则化项。
2.2 模型精度评价方法
一般来说,在构建机器学习模型时,评估其性能是必不可少的一步。接收器工作曲线(Receiver Operating Curve,ROC)是地理空间分析中广泛使用和接受的技术,用于确定模型的有效性[31]。ROC曲线下方的面积(Area Under Curve,AUC)代表模型的准确性,曲线下面积越大,模型评价灾害发生的能力越强[32]。
用于评估模型性能的还包括精度、准确度、召回率和Fscore等其他常见的评价指标。精确度(Precision)表示准确预测的阳性数据占全部被预测为阳性数据的百分比,值越高,分类器越好,但高精度并不意味着算法更好;召回率(Recall),也称为灵敏度,主要表示准确预测的阳性样本数量相对于实际阳性样本数量的比例。准确度(Accuracy)定义为准确预测的样本数量占全部预测数据的百分比,也是分类算法中最常见的性能指标;F1-score是对召回率和精确度的加权平均分数,是一个综合评价指标,范围从0 到1,解释了最差到最好的表现。各指标计算公式如下:
式中:TP(真正)表示正确归类为山洪点的数量;TN(真负)表示正确归类为非山洪点的数量;FP(假正)表示错误归类为山洪点的数量;FN(假负)表示错误归类为非山洪点的数量;P是山洪点总数;N是非山洪点总数。
2.3 参数优化方法
参数优化可以对模型的评价能力产生显著影响[33]。为了进一步保证模型精度,本研究使用网格搜索方法和k折交叉验证法探索了大范围的参数值。每个模型的最佳参数值见表2,对于表2中未包含的参数,使用Scikit-Learn库设置的默认值。

表2 RF、LightGBM、XGBoost模型的最优参数Tab.2 Optimal parameters for the RF、LightGBM、XGBoost models
3 实验结果分析
3.1 模型精确度分析
将测试集数据导入训练好的RF、XGBoost和LightGBM 模型进行检验,计算各项评价指标值,结果见图4。ROC曲线图(见图5)表明,LightGBM 模型获得的AUC值最高(94.12%),其次是XGBoost(93.23%),最后是RF(93.02%)。
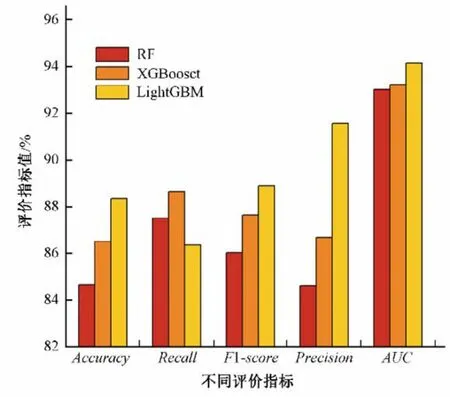
图4 各模型评价指标Fig.4 Model evaluation index

图5 ROC曲线Fig.5 ROC curve
显然,所有3个模型都可以在一定程度上正确评估山洪,但能力不同。LightGBM 模型比其他两种模型具有更好的性能。同时,LightGBM 显示出最精确的分类性能,其Accuracy为88.34%,Precision为91.57%;其次是XGBoost,其Accuracy为86.50%,Precision为86.67%;最后是RF,其Accuracy为84.66%,Precision为84.62%。获得的结果显示,LightGBM 在模型精度和处理时间方面均优于其他两种模型。接下来将基于最优模型LightGBM进行山洪灾害风险评价。
3.2 基于LightGBM 的山洪灾害风险评价与应用
3.2.1 风险指标重要性分析
不同的指标对山洪灾害的发生有着不同程度的影响,探究各指标重要性可以更深入的了解山洪的空间分布规律。本文引入LightGBM-SHAP(Shapley Additive Explanations)特征重要性计算方法,分析不同风险指标对山洪灾害的影响程度。简单的来说,LightGBM-SHAP 是将各个风险指标在整体样本上的Shapley绝对值取平均值作为该指标的重要性值。值越大,特征贡献度越大,表明该指标对山洪灾害的影响程度越大[34]。
通过计算,获得的指标重要性评价(见图6)表明:DEM、SLOPE、AP 的特征贡献度最大,超过了40%,地势较低的地方,在强降雨影响下,很容易积水引发山洪;3-H-P、FFP、SM、TWI、GDP、24-H-P 和POP 的特征贡献度次之,特征贡献度都超过了20%或者接近20%,结合卫星影像图发现农田生产潜力大的区域更容易发生山洪,这些区域人类活动频繁,降低了植被覆盖率,土壤的渗水能力差,有利于山洪发育;LULC 和RD 的特征贡献度最低,但也达到了10%。结果显示12个指标的特征贡献度都较高,说明所选取的12个指标均被确认为重要。即对最终的山洪风险起着一定作用。影响程度从大到小依次为:SLOPE>DEM>AP>3-H-P>FFP>SM>TWI>GDP>24-H-P>POP>LULC>RD。

图6 指标重要性评价图Fig.6 Index importance evaluation chart
3.2.2 风险评价结果分析验证
基于上述模型性能指标,最后选择LightGBM模型来评价南阳市西部地区山洪灾害风险。将整个研究区的各指标数据输入到LightGBM 模型中,计算得到山洪风险概率值,作为山洪风险评价结果,最后进行山洪灾害风险区划。在综合考虑南阳市西部地区的情况下,选择自然间断法作为主要分类方法,并绘制得到山洪灾害风险评价图(见图7)。山洪灾害风险值分为五类:极低风险区、低风险区、中风险区、高风险区和极高风险区。

图7 山洪灾害风险评价图Fig.7 Flash flood disaster risk assessment map
分析图7可知,研究区风险评价结果与实地调查结果一致,其山洪灾害整体分布比较广泛。极低风险区和低风险区分别占总面积的37%和24%,中风险区占总面积的18%,较高风险区和高风险区约占总面积的21%。通过分析山洪高风险区域,发现其主要分布在山脉附近、河流的周边最低处以及植被覆盖度较低的区域,这些区域满足山洪发生的高程、坡度等基本条件[35]。并且相对于其他区域年平均降水量、年最大3 h 降水量均值、年最大24 h降水量均值、和农田生产潜力都较大。
为了验证LightGBM模型的山洪风险评价结果的合理性,将山洪灾害风险评价图和历史山洪点进行叠加,统计分析山洪灾害风险评价图的各分区面积与山洪点数量(见表3)。从表3 中可以看出,面积仅占研究区总面积9.26%的极高风险区内山洪数占山洪总数高达77.11%,说明LightGBM 算法对研究区山洪灾害风险评价结果较满意,可以为南阳市的山洪灾害防治提高指导。
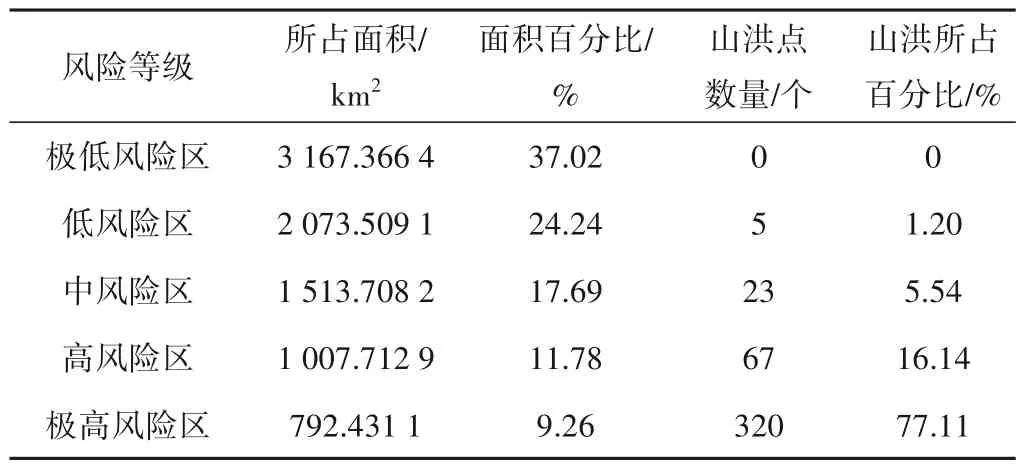
表3 山洪风险评价区划统计Tab.3 Statistics of flash flood risk assessment and zoning
3.2.3 多尺度山洪灾害风险评价
为了更好地应用所提出的方法,为研究区灾害防治提供更为具体的指导,使用ArcGIS软件中的分位数方法来进一步获得乡镇级山洪灾害风险评价图[36](见图8)。其中需要重点关注的是人口较多的紫金街道,白羽街道,龙城街道和商圣街道,这4个乡镇位于灌河附近且地势较低且强降雨次数较多,极其容易发生山洪。此外还需关注耕地面积占比较多的王店镇、灌涨镇、老城镇、金河镇、毛堂乡、寺湾镇和滔河乡,通过核查发现,这些乡镇地形起伏度大,人们开垦了大陆的耕地,植被覆盖率低,导致土壤渗水能力较差,降雨集中时更容易发生洪水。因此可以针对这些区域重点制定灾害预防措施,制定资源分配的优先级,最大程度上减少山洪灾害损失。

图8 乡镇级山洪灾害风险评价图Fig.8 flash flood disaster risk assessment map at the township level
4 结 语
山洪灾害是最具破坏性的自然灾害之一,近年来,机器学习技术已成为评估山洪灾害风险评价的有力工具。本研究采用3种机器学习方法来评价南阳市西部地区的山洪风险。结果表明:
(1)LightGBM 模型的评价结果更符合南阳市西部实际的山洪发育情况,从时间成本、训练难度、稳定度以及精确度考虑,LightGBM 良好的泛化能力更适合山洪风险评价这类非线性且需要重点解决的灾害问题。
(2)通过LightGBM-SHAP 方法获得特征贡献值来评价12个指标的重要性,对研究区山洪的影响程度从大到小依次为:坡度>高程>年平均降雨量>年最大3 h降水量均值>农田生产潜力>土壤湿度>地形湿度指数>GDP>年最大24 h降水量均值>人口密度>土地利用类型>距离河流距离。
(3)研究区山洪风险评价图表明高风险和较高风险区占总面积的21%。且主要分布在山脉附近、河流的周边最低处以及植被覆盖度较低的区域。建议高度重视人类耕地对植被覆盖率的影响,此系列人为活动一定程度上增加了山洪发生概率。
研究尚未探究集成模型在山洪灾害风险评价的应用,可以在未来研究中探索其他基础模型的各种组合,通过利用不同模型的优势来最小化其弱点,以寻求更好的模型性能,获得更合理的山洪灾害风险评价图。
