基于流量检测的目标大数据快速检索系统设计
2023-08-27孙妍张俊超薛峪峰
孙妍,张俊超,薛峪峰
(国网青海省电力公司信息通信公司,青海西宁 810008)
随着当前电网规模的不断扩大,其复杂性在不断增加。因此,以信息网络为基础的各种应用也日益增多。找出造成电网异常问题的根源具有较大困难,且未侦测到的电网异常问题会进一步扩散,对电网信息的正常传送造成干扰。因此,对电网的业务进行实时监控与评价并及时发现异常状况,对于提高电网的安全、稳定起到了关键作用。
文献[1]提出的基于簇内乘积量化的检索方法,运用向量量化和乘积量化的方法,表征大规模高维数据,通过计算候选数据集向量与查询向量间的距离,实现目标大数据的检索;文献[2]提出的基于倒排索引的检索方法,通过插入关键字抵消服务器的关键字攻击,同时,引入数据缓存区,结合倒排索引加密算法对关键数据检索结果进行盲计算。但是,这两种方法容易受到未知入侵数据的影响,出现检索效果不佳的问题。
基于以上研究成果,该文设计了新的基于流量检测的目标大数据快速检索系统。
1 系统硬件设计
将流量检测技术引入到系统中,无疑要把查询部分转换成用户程序调用界面。但是其可以独立地产生索引,从而降低了用户对系统的影响,使得系统能够更好地集中在指标上[3]。因此,设计了基于流量检测的目标大数据快速检索系统硬件结构,如图1所示。
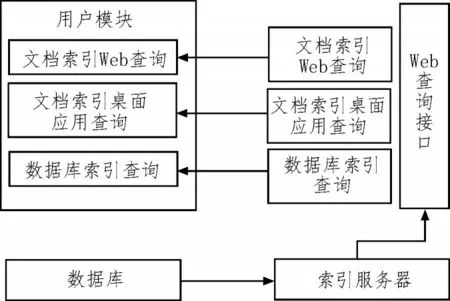
图1 检索系统硬件结构
该系统主要由索引服务器与查询接口两个部分组成。索引服务器是一个独立的系统,可以让用户设定索引类型、索引数据和索引记录[4]。索引伺服器会根据使用者设定的方式,对有关资料进行索引,不会影响其他使用者[5];查询接口可以被视为一种无须改动就能直接嵌入到使用者应用程序中的一种接口,不同的程序界面对于不同的用户来说是不同的,使用者可以做一个索引标志,使得用户能够按照索引标志查询语句,也可以对索引标志进行一些小的改动,并将其嵌入到自己的系统中[6]。
为了使系统应用起来更加方便,系统直接使用XML 驱动系统代替数据库。
1.1 索引服务器
索引服务器一般是一台含有一种逆向索引的服务器,该服务器会建立一个即时索引,并将区块查询与文件ID 相对应。
索引服务器结构如图2 所示。
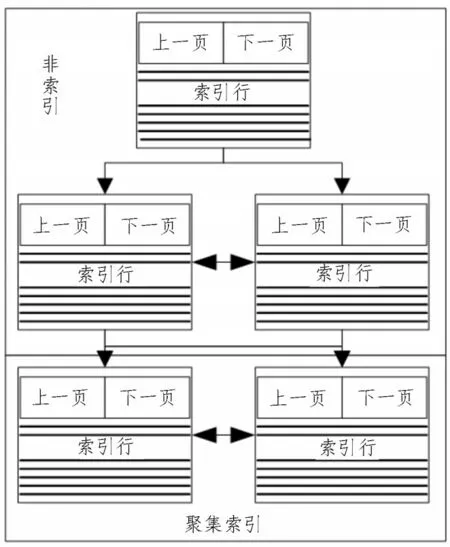
图2 索引服务器结构
索引服务是Windows 提供的一个支持文件索引的服务,该系统能在不需要使用者介入的前提下,提升计算机网络的检索效率,并能自动进行索引的更新[7]。
索引服务将一组档案中的信息抽取出来,并将其组织起来,这样就可以在Windows Server 2003 的搜寻功能、索引服务查询表或网页浏览器中迅速地撷取到相关信息[8-10]。这一信息可以包含文件中的单词(内容)、文件的特征和参数(属性),比如作者的名字。在索引之后,可以对包含关键词或者属性的文档进行索引。
1.2 Web查询接口
只有通过Web 查询界面才能访问背景数据库的内容,查询接口通常是以html 和超文字标记来显示的,它是一种解释语言。
Web 查询接口结构如图3 所示。
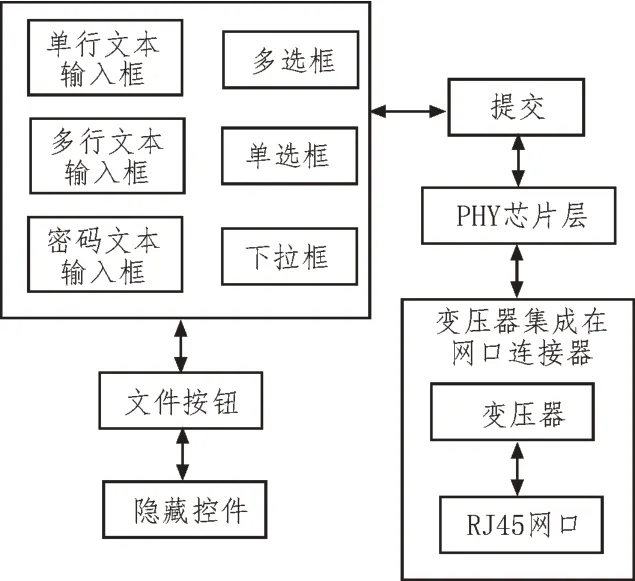
图3 Web查询接口结构
Web 查询接口中的单行文本输入框允许用户输入简单的单行信息;复选框允许用户选择单个或多个选项;单选框是由多个选项组成,且供使用者进行单项选择的框[11-12];下拉框是卷动的单个标记框;多行输入框主要用于输入较长的文本信息;密码输入框用于输入一些保密的信息;文件按钮负责传输文件;隐藏控件允许Web 程序员将数值引入到html表单中,使这些数值与其他空间一起发送回Web 服务器[13]。
1.3 XML驱动系统
XML 的表现功能为从静态业务对象模型(而非UML)中提供了一个良好的描述方法,首先构建一个业务对象静态模型,然后底层的开发者在这种模式下进行软件的开发,而业务逻辑开发者则是根据这种XML 模式和商业逻辑来编写XML 概要[14]。这个操作被抽象成界面“批量操作”,用于执行每一个具体的行为,并向“合作”管理器对象添加一个类的实例,在运行时遍历XML 文档。运行一个节点,向管理程序对象传递“合作”的节点,并将“合作”的返回值和“获取名称”的返回值相比较,找出相应的操作界面,然后再由XML 节点执行相关“操作”[15]。
2 系统软件设计
2.1 基于流量检测的快速分级索引构建
为了获取目标大数据,需筛选出异常数据,而电网数据的异常行为表现为流量的异常,所以提出了基于流量检测的分级索引构建方法。异常数据是通过入侵行为产生的数据,入侵追踪的研究重点是发现入侵路径和IP 地址,实现对异常数据的定位。
在电网稳定运行状态下,在t时间内出现流量异常情况,对于该情况需计算流量采样的时间间隔,及时定位异常数据位置。基于流量检测方法获取的数据缓存区大小决定了采样间隔,该间隔时间就是索引构建的时间[16]。
如果设缓冲区域的长度为L,则在t时间内缓冲区域内数据不满的概率可表示为:
式中,i表示数据统计结果;l表示单位记录长度,q表示用户请求后平均到达率;n表示连接个数。
对于整个缓冲区域的缓冲速度,可表示为:
在该情况下,计算采样间隔,公式为:
依据式(3)可得到采样间隔,即基于流量检测的索引构建时间。
若将某一时期的指数进行分类,则可在查询过程中直接获得各个阶段的资料,节约了许多查询与评价的时间。这样,就可以随时有效地获得索引信息,而不用过分扩充索引,也就不会发生索引大小过度膨胀的现象。基于此,构建了基于时间域的倒排索引,如图4 所示。
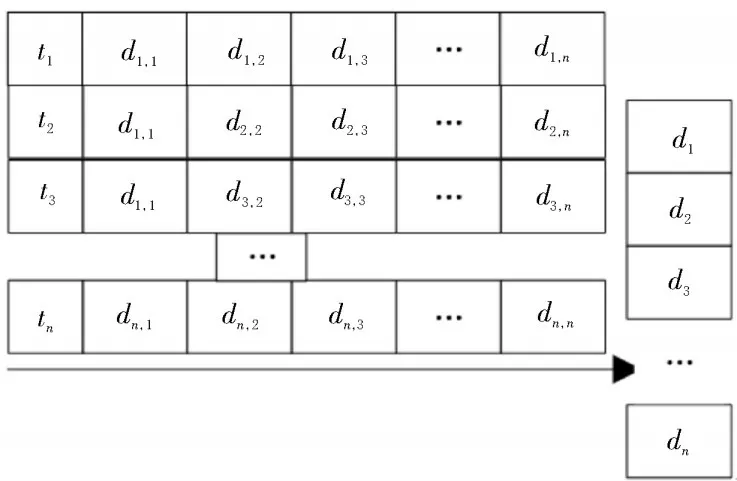
图4 基于时间域的倒排索引结构
由图4 可知,在对一段时间的文件进行查询时,根据特定的检索模式,采用常见的查询技术,获得一份原始的文件清单。然后将两个表合并,使第一个表的次序保留,从而获得与该时间段内有关的文件。
为了缩短分级索引构建时间,将采样间隔划分为m个子时间段t1,t2,…tm,动态统计规则应用到所有的子时间段中,获取m个统计结果,由此形成了流量的时域变化关系。对于子时间段的划分,应遵循:
1)当t1=t2=…=tm时,每个子时间段的统计结果是一致的。
2)统计过程中存在如下公式:
2.2 快速检索流程设计
索引检索模块对大量的题库进行目标大数据检索,其操作步骤如下:
步骤一:通过建立索引结构,检索指标相关信息;
步骤二:分析用户界面反馈的数据,并确定检索条件,传递检索任务;
步骤三:使用弹性搜索分布式连接器获取服务链接,并利用索引库进行再次索引;
步骤四:利用资料库连接器与资料库通信,摘取资料库的暂存表,依使用者的要求找到批号,利用SQL 进行资料库的查询,最终取得文字的结果;
步骤五:在建立大量题库的目标大数据索引时,每一栏的名字都要有一个索引。利用索引名进行文字检索,可以有效地提高检索的效率。
3 实验
对文献[1]提出的基于簇内乘积量化的检索方法、文献[2]提出的基于倒排索引的检索方法和该文设计的基于流量检测的目标大数据快速检索系统进行对比测试实验,对比不同方法的检索精准。
3.1 实验数据集
从国网青海信通公司2021 年营业管理数据库中提取与发改委、住建厅、房产局进行信息交互的数据,该数据集大小为15.5 GB。
由于数据集中的每篇文档均具有一定时间维度,因此使用的数据集不具有时间信息。为此,对文档进行了如下处理:针对每篇文档产生的随机数,将其随机分布在一年的365 天时间范围内,由此视为一年内信息交互产生的数据量。
3.2 实验指标
1)索引构建时间
以检索源IP 地址、目的IP 地址、端口、协议ID、输入协议为指标,分析索引构建时间。
2)检索速度
对目标大数据来说,索引数据越多,所构建的索引数据大小与全部数据大小之比,也就是膨胀系数越大,说明检索速度也就越快。如果没有为所有目标大数据创建索引的检索,则膨胀系数为0;如果索引数据与全部数据量一样大,则膨胀系数为1。
索引膨胀系数公式,可表示为:
式中,H表示索引数据大小;G表示全部数据大小。
3.3 实验结果与分析
3.3.1 索引构建时间
三种方法的索引构建时间对比结果如表1所示。
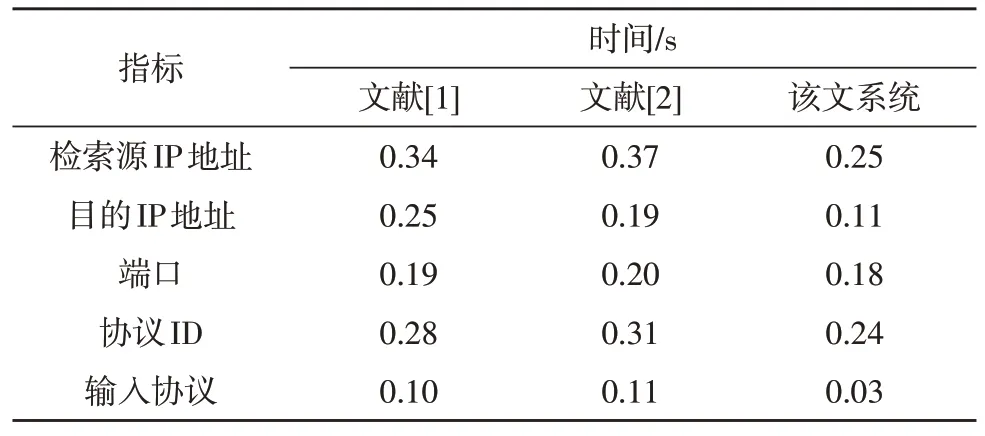
表1 三种方法的索引构建时间对比
由表1 可知,使用该文基于流量检测的目标大数据快速检索系统,各项指标索引构建时间最短;使用文献[1]检索方法,在目的IP 地址指标下,与流量检测方法索引构建时间相差最大,最大为0.14 s;使用文献[2]检索方法,在检索源IP 地址指标时,与流量检测方法索引构建时间相差最大,最大为0.12 s。由此可知,使用基于流量检测的目标大数据快速检索系统具有较短的索引构建时间。
3.3.2 检索速度
三种方法检索速度对比结果如图5 所示。
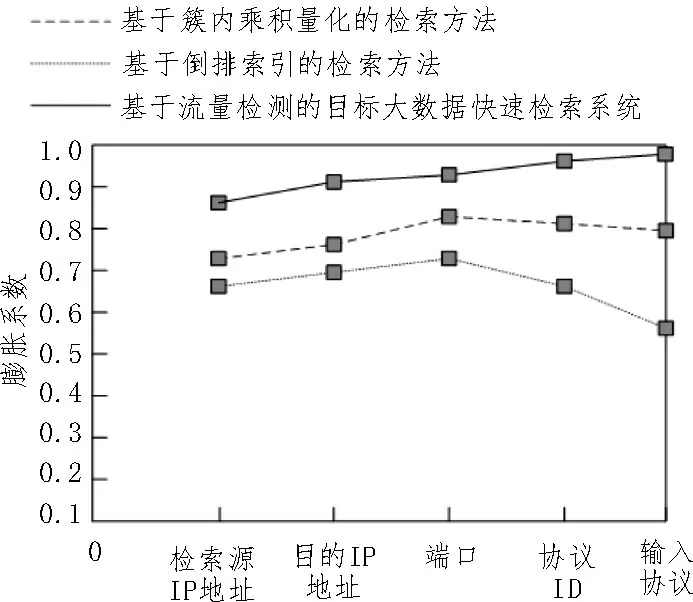
图5 三种方法检索速度对比
由图5 可知,使用基于簇内乘积量化的检索方法,检索端口指标的膨胀系数最大,可达到0.82,检索源IP 地址指标的膨胀系数最小,最小值为0.74;使用基于倒排索引的检索方法,检索端口指标的膨胀系数最大,可达到0.72,检索输入协议指标的膨胀系数最小,最小值为0.57;使用基于流量检测的目标大数据快速检索系统,检索输入协议指标的膨胀系数最大,可达到0.99,检索源IP 地址指标的膨胀系数最小,最小值为0.86,具有快速检索效果[17]。
4 结束语
该文设计的基于流量检测的目标大数据快速检索系统,能够对通信过程中大量的数据快速建立信息索引标志,实现用户输入的快速响应。对于未知的数据库,用户能够根据开发的插件,灵活检索相关数据。
但是,所设计的系统仍存在需要进一步思考和探讨的问题:在目标大数据的分类处理领域,目前还没有涉及相关的特征抽取,这表明在该领域中可以利用分词技术进行改进。
