基于自然语言处理方法的产业政策内容解析研究
2023-08-26戴一成张康林
戴一成 张康林


关键词:产业政策;预训练语言模型;自然语言处理;关键要素
0 引言
政府产业政策是国家出于规范市场环境、推动产业发展目的而颁布的制度与做出的安排,科学合理地落实产业政策可以促进企业发展,提高国家经济竞争力和改善全民生活。為了给企业提供更好的发展环境,助力企业产业结构升级,国家各部门、各省市近年来出台大量针对不同行业的产业政策。但这些政策在实际落地过程中存在一定困难,一是企业获取政策信息途径较为传统,主要是通过政策宣讲会和行业交流;二是政策传递不够及时,导致企业对于政策的知晓和运用出现明显“时差”;三是政策获取完整度有限,企业对于政策理解存在碎片化,难以做到应知尽知、知其善用。因此企业需要花费大量时间精力跟踪产业政策的发布,多源异构的海量政策信息导致企业难以快速从产业政策中查找并定位与自身行业相关的奖励内容,这些问题给企业有效获取政策奖励造成了困扰。
目前,部分学者研究集中于运用自然语言处理方法对政策文件信息进行提取与分析。Altaweel等人[1]在生态扰动的政策响应研究中,应用自然语言处理主题建模方法对美国甲虫暴发事件有关的政府文件进行了内容分析。孔希希等人[2]在货币政策研究中引入自然语言处理方法,分别采用绝对概率和条件概率方法,分析了56篇货币政策报告,研究认为运用自然语言处理方法对经济政策信息进行提取分析,有利于指导经济发展。魏宇等人[3]利用自然语言处理方法对旅游交通政策进行量化分析,研究验证了该方法适用于对分散化政策类情报信息进行分析。靳晓东等人[4]搜集了1995~2021年间股权质押相关的政策文本,采用自然语言处理技术和网络分析方法从四个发展阶段研究政策的核心主题,并通过各阶段主题词共现网络特点研究政策体系的演变特征。关海山等人[5]基于BERT模型与规则处理相结合的方法对税收优惠政策进行法规表示、关键信息提取和可视化查询,使纳税人可以快速找到相关税收优惠信息,实验结果表明,自然语言处理方法可以有效缓解税收优惠信息过多问题。
通过以上梳理可知,已有研究运用自然语言处理方法集中于对政策文件的主题研究与文本分析,对于关键要素抽取的探索较少,同时目前提出的政策文件关键信息抽取模型较为单一、泛化性低。针对上述问题,本文提出一种基于规则模型、文本分类模型与预训练语言模型相结合的自然语言处理方法,实现对产业政策文件内容进行自动化解析和关键要素抽取,并对结果进行可视化展示,使企业可以快速准确定位所需的政策奖励内容与条件。
1 研究数据与方法
1.1 数据来源
本文数据来源于31个省份的二级行政区划政府官方网站,在其官方网站的“政策文件”板块以“政策”为关键词,进行全时段搜索相关政策文件,对查找到的每一篇政策文件还需进一步筛选,筛选规则如下:一是政策文件内容是完整的,有标题和子标题;二是政策文件包含不同奖励对应不同奖励条件的内容;三是政策文件内容主要针对扶持企业产业发展和转型升级。经上述规则确认后,即可下载文件,最终共收集产业政策文件175篇,初步形成所需的产业政策文件库。
1.2 研究方法
1.2.1 规则模型
规则模型目前在人工智能和其他业务领域都有着广泛应用,虽然算法模型通常比规则模型精确性和鲁棒性更好,能够处理复杂非线性关系和连续变量,但规则模型通常比算法模型更简单直观,可解释性强,能够处理异常值和存在相关性的特征。因此,在实际应用中,根据不同场景和需求选择合适的算法模型和规则模型进行结合使用,可以提高模型的性能和可靠性。
规则模型的构建需要在一份高质量训练数据基础上,逐条归纳,每学到一条规则,就将该规则覆盖的样本从训练集中取出,然后用剩下的样本训练出另一组规则,最终以准确率为阈值,将总结出来的所有规则模型组成规则集,伪代码如下:
本文结合正则表达式和逻辑表达式,针对政策文件的内容结构,制定多个规则模型,对有关政策文件信息进行提取。
1.2.2 文本分类模型
文本分类模型是一种用于将文本数据分配到不同类别的机器学习方法。根据使用的技术,文本分类模型可以分为传统机器学习模型和深度学习模型。传统机器学习模型主要基于词袋、N-gram、TF-IDF等特征表示方法,以及贝叶斯、SVM、随机森林、KNN等分类算法。深度学习模型主要基于神经网络结构,如textCNN、FastText、RNN、LSTM、HAN 等,以及注意力机制、胶囊网络、图神经网络等扩展技术。本文将基于词袋模型Word2vec结合集成模型LightGBM对政策文件内容进行分割与预测。
Word2vec是一种自然语言处理技术,它使用神经网络模型来生成词向量,即将每个词表示为一个数值向量,而文本通过预处理、分词、停用词过滤等操作后,可以通过一个词语列表表示,再对每个词语对应的词向量进行求和平均获取一个向量矩阵,即可用来表示该文本的语义信息。该模型包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要包括CBOW和Skip-gram模型,CBOW模型是通过词的上下文预测词,Skip-gram模型是通过词预测上下文,两种模型的原理如图1所示。
LightGBM是一个基于树的梯度提升框架,其因训练速度快、内存占用低、高准确率以及支持并行、分布式和GPU学习等特点,被广泛应用于大规模数据处理。相较于XGBoost模型,LightGBM在三个方面进行了优化,包括使用直方图算法减少候选分裂点的数量、使用基于梯度的单边采样算法减少样本数量以及使用互斥特征捆绑算法减少特征数量,不仅提升了样本质量还降低了模型复杂度。
1.2.3 预训练语言模型
预训练语言模型作为自然语言处理领域的核心技术之一,通过使用大量数据先训练一个通用模型,然后运用此模型来解决特定任务,即使在少样本甚至零样本的情况下,也可以获得不错的效果。预训练模型可以提高模型性能,节省训练时间,并且适应低资源场景,常见的预训练模型有Transformer、BERT、DALL-E等,其中OpenAI发布的GPT-4和Google发布的Bard都是基于Transformer预训练模型生成。本文将采用基于Transformer模型衍生出来的BERT模型,构建政策文件关键要素提取模型。相比Transformer 模型,BERT模型包含更多的Transformer block以及具有更大维度的隐藏层输出向量。此外,BERT模型还使用了双向编码器,因此在文本内容的提取效果上更符合实际需求。
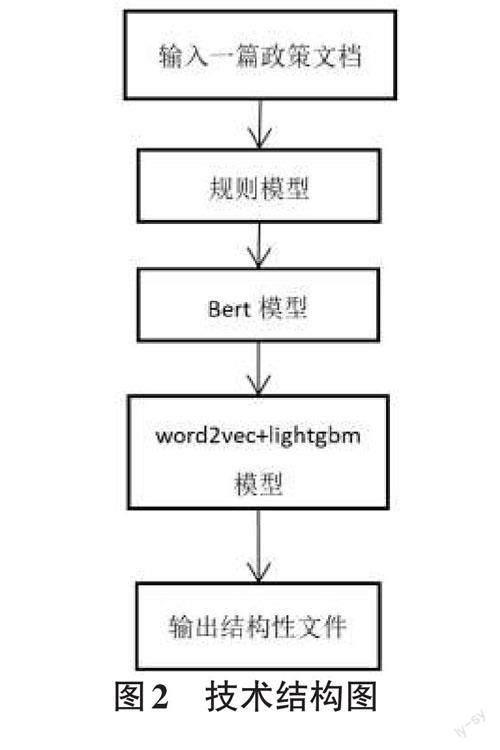
综上所述,技术结构图如图2所示。
2 研究设计
2.1 构建四项内容提取模型
通过对政策文件内容结构的了解,本文制定一系列规则模型,能够准确输出“总政策名称”“子政策名称”“子政策支持项”“子政策支持项内容”4项内容。
具体方法如下:
第一是总政策名称提取,从图3可以看到,总政策名称存在于该文件中的前三行,通过‘《》符号进行概括,更加精准存在于“关于”和“政策”关键词之间,就可以根据上述三个条件制定逻辑和正则表达式进行提取。
第二是子政策名稱提取,在图3中分别是“一、推进现代农业发展”“二、加快数字农业建设”“三、推进农业‘双强行动”“四、加快现代种业发展”“五、鼓励农业主体争优创先”,他们之间存在的共性是以“一、二、”这种格式存在于文章某个段落中,段落长度不会太长且关键词分别是“推进、加快、鼓励”,那么就可以根据上述三个条件制定逻辑和正则表达式进行提取。
第三是子政策支持项名称的提取,由于图3 展示的文件不存在子政策支持项,但由于需求,需要使用前一项的内容进行填充,那么该政策文件的子政策支持项名称与子政策名称相同。
第四是子政策支持项内容提取,由于子政策支持项内容都是存在于子政策支持项名称后面,所以只要定位出子政策支持项名称的位置,再根据段落信息即可定位子政策支持项内容的位置,即‘1.2.3.后面的段落文本为每一个子政策支持项对应的子政策支持项内容。
经过上述一系列的逻辑和规则,即可提取出该政策文件对应的四项内容,当输入一个政策文件后,通过规则模型输出规则结果进行展示,在175 篇测试文档中提取出四项内容的准确率为88.75%。
经过查看大量产业政策文件,根据四项内容存在的位置以及关键信息,总结出如表1所示的正则表达式进行关键要素抽取。
2.2 构建文本分类模型
为了将“子政策支持项内容”中的“子政策奖励条件”以及对应的“子政策奖励”准确分类,需构建文本分类模型。
首先,基于收集到的175篇产业政策文件,使用人工对每一篇政策文件中存在的奖励条件和奖励进行标注,由于构建的文本分类模型是以一个短文本为单位进行分类预测的,即通过逗号、句号和分号将一大段文本内容分割成一个个短句再进行使用,而对于奖励条件和奖励在一个短句中的文本,先将其标注为奖励,后续将针对文本再一次构建对应的分割模型将其分割,样本样例如表2所示。
整理出人工标注好的文本,计算出奖励条件和奖励文本个数后,以接近1∶1∶1的比例,收集部分非奖励条件和非奖励文本,构建了一个包含4 023条样本的数据集。通过对文本分类模型有关调研,本文选择词袋模型结合机器学习集成模型方法,在速度和准确率上都具有较高的优势,使用样本集在Word2vec+light?gbm模型上进行运行发现其准确率较高,达到87.1%。
由于子政策支持项内容存在于多条奖励条件以及奖励内容的对应关系,为了提高两者关联准确性,对于输入的一段文本内容,首先通过分号和句号对文本内容进行分割,再通过逗号一一分割上述分割结果,将分割短句输入模型进行分类预测,即可成功获取奖励条件和奖励内容的对应关系。
2.3 构建子政策奖励条件和子政策奖励分割模型
由于存在子政策奖励条件和子政策奖励内容都在一个短文本中的样本,为了便于企业更加直观地理解奖励条件与内容,需要针对文本构建子政策奖励条件和子政策奖励分割模型,将一条短文本中的子政策奖励条件和子政策奖励内容分割开来,然后进行指定位置保存,整个分割保存逻辑如表3所示。
首先在构建子政策奖励条件和子政策奖励文本分类模型时,对于人工标注的样本,规定将子政策奖励条件和子政策奖励内容都在一个短文本中的样本打上属于子政策奖励的标签,最终对于这样的文本分类结果将会是无奖励条件内容且只存在奖励内容。
从175篇政策文件中发现了此类型样本共存在249条,每一条文本内容都可以通过一个名词实体将子政策奖励条件和子政策奖励进行分割开来,所以构建Bert模型进行命名实体识别,将短文本中的名词实体识别出来后,即可定位分割位置,获取分开的子政策奖励条件内容和子政策奖励内容,标注样例如表4 所示。第一步是人工对249条短文本进行奖励对象的实体标注,由于样本数据量并不多,在命名实体识别任务中,预训练模型transformer在小样本数据量上也能够取得很好的效果,所以将标注好的样本放在transformer模型进行训练、验证和测试,经过调试,训练好的模型在该任务上的准确率为83.75%。
最终将子政策奖励条件和子政策奖励内容都在一个短文本中的待分割样本放入上述训练好的模型中,识别出奖励对象,然后以识别出的奖励对象文本为分割位置,即可将上述短文本中的子政策奖励条件和子政策奖励分割开来,并最终将分割开来的文本填充并替换子政策奖励条件和子政策奖励。
3 研究结果分析
3.1 输出json 文件
通过上述步骤成功获取“总政策名称”“子政策名称”“子政策支持项”“子政策支持项内容”“子政策奖励条件”“ 子政策奖励”共6 项内容,并形成了dataframe结构,由于这6项内容存在对应关系,而json 的树结构能够将提取的信息更直观地展示出来,所以设计一个将dataframe结构转换为json结构的模块,最终内容形式如图4所示。
3.2 构建政策解析可视化平台
为了便于企业优化每一步模型结果,提高下一步模型输出准确率,需构建一个政策解析可视化平台,如图5所示。
该平台支持用户批量上传docx、doc两种政策文件类型,上传的文件将在下方形成对应的文件列表,每一个文件支持6大功能。第一是可以查看原文;第二是政策分层,可以使用“总政策名称”“子政策名称”“子政策支持项”“子政策支持项内容”四列内容提取模型,将这四列内容从非结构化文件中提取出来;第三是可以查看政策分层的结果,如图6所示,可以让用户对政策分层的结果进行修改优化,提升政策分层结果的准确率;第四是对上述结果形成的json文件提供下载接口,通过json文件可查看“子政策奖励条件”“子政策奖励”两项内容;第五是提供对文件删除的功能;第六是用户可以将解析结果不满意的文件上传到待优化文件数据库中,后期可以定期查看这类型文件,进而优化解析模型。
4 研究结论
本文通过构建规则模型、文本分类模型与预训练语言模型结合的自然语言处理方法,对175篇产业政策文件进行结构化自动解析研究,同时对解析结果进行可视化展示,验证了规则模型融合文本分类模型与预训练语言模型在产业政策文件解析研究中的适用性,完成了由非结构化产业政策文件内容到结构化产业政策关键要素数据模式的转换。同时,本文研究开发了产业政策文件关键要素可视化展示平台,企业不仅可以通过该平台人工矫正模型结果,还可以查询与自身行业相关的奖励政策,改善企业的经营环境。
最后,本文仅运用自然语言处理技术对产业政策文件的“总政策名称”“子政策名称”“子政策支持项”“子政策支持项内容”“子政策奖励条件”以及“子政策奖励”进行了提取研究,而对于奖励条件更精准的企业定位还未做分析,未来可针对奖励条件的定位标签,进行更多拓展性的研究,为相关政策研究人员以及企业提供更多便利。