基于时间生成对抗网络的风电随机场景预测
2023-08-25贾梦瑶王玉玮宋明浩
贾梦瑶,王玉玮,宋明浩
(华北电力大学经济管理系,河北保定 071003)
0 引言
构建以风电等可再生能源为发电主体的新型电力系统是促进能源转型,实现碳达峰、碳中和目标的核心途径。然而,受自然因素影响,风力发电的随机性和波动性较强,其大规模并网会对电力系统的有功功率平衡及频率造成干扰[1-2]。因此,科学的风力发电有功功率短期预测是合理制定电力系统运行调度计划,继而实现系统经济、稳定运行及风电高比例消纳的重要基础与前提。
随着新型电力系统的建设与发展,国内外学者已开展关于可再生能源出力的短期预测研究。从预测方法研究多集中于点预测、区间预测及随机场景预测。点预测是对某因素未来各时段的取值进行单点预测,其方法主要包括数值天气预测法、小波神经网络、最小二乘向量机等[3-5]。相较于点预测,区间预测可输出不确定因素的近似取值范围,在一定程度上刻画随机波动性质。常见的区间预测及其改进方法包括高斯过程方法、深度学习方法等[6-8],其在一定程度上提高了预测精度,但因各因素随机波动性所导致的预测偏差仍然存在。
随机场景预测(也称概率分布预测)是对某因素未来各时段的随机场景进行预测。由于风电等可再生能源出力具有较强的随机性,点预测与区间预测无法全面刻画不确定因素的随机分布规律。随机场景预测通过预测随机场景以克服无法刻画随机分布规律缺陷,对大规模可再生发电系统的日前调度及电力系统的稳定性、可靠性和安全性至关重要[9]。文献[10]基于分位数回归(Quantile Regression,QR)方法预测短期光伏出力随机场景。文献[11]采用QR 方法并结合改进分位数卷积神经网络生成光伏随机场景。文献[12]构建了高斯分位数-核密度估计风电随机场景预测模型,以刻画风电的概率密度。文献[13]运用摆动门算法、模糊c 均值聚类方法得出不同风电功率波动的模式标签,实现短期风电随机场景预测。QR 方法、摆动门算法等概率密度预测方法在一定程度上能够刻画不确定因素的概率分布,但过度依赖大容量样本数据。考虑到数据的有限性,生成对抗网络(Generative Adversarial Networks,GAN)被应用于可再生能源出力的预测。文献[14-15]均通过构建GAN 模型以生成与历史概率分布近似的风电分布,保证了风电随机场景预测的有效性。GAN 方法的引入使得基于小样本预测风电等可再生能源出力成为可能。然而,风电等可再生能源出力均具有显著的时间相关性,传统GAN 方法仍存在预测偏差。
鉴于此,本文提出一种基于时间序列生成对抗网络(Time Generative Adversarial Networks,TimeGAN)的风电随机场景预测模型。首先,基于风电数据特性挖掘潜在时间相关性信息,将风电数据特征分类为静态与时态特征;在此基础上,构建基于TimeGAN的风电概率分布及随机场景预测模型,用以生成与真实概率分布近似的风电随机场景;最后,运用山东省某风电场的实际数据进行算例仿真模拟,通过降维可视化方法、模型预测效果对比分析,验证所提TimeGAN 模型的有效性和实际应用价值。
1 风电数据特性分析
风电受气候、风速等影响较大,因此其具有显著的时间相关性[16]。根据TimeGAN 模型原理,将风电影响因素分为静态特征和时间特征2 个维度。
1)静态特征维度。各季节风电出力平均值不随时间波动,因此,风电出力平均值属于风电数据的静态特征范畴。即:
式中:为风电平均值;PWT,t为风电历史值;I为历史场景数,i∈{1,2,…,I}表示风电历史场景中单个历史场景的索引(1 个场景即1 个日风电时序列);t(t=1,…,24)为时间索引。
2)时间特征维度。各季节风电出力误差值(风电实时出力与风电出力平均值之差)属于风电数据的时间特征范畴。风电实时出力随时间的波动变化具有季节性、周期性等特点。即:
式中:δt为风电出力误差。
本文以风电静态特征和时间特征为基础,运用TimeGAN 模型分别挖掘风电总体分布与时间逐步依赖分布,风电的静态特征、时间特征见图1。
2 时间生成对抗网络原理
基于1 节风电数据特性分析,本文将数据特征划分为风电出力的静态和时间特征2 种。
设向量S=[S1,…,Sα],表示有α个风电静态特征;向量X=[X1,…,Xβ]表示有β个风电时间特征。ℑ 和ℵ分别为风电静态和时间特征的向量空间。1组(S,X1:T)具有某种风电联合分布p,T为其时间序列的长度。令n∈{1,2,…,N},表示风电训练数据中单个样本的索引,则训练数据集表示为。真实风电出力时间数据服从的分布定义为p(Sn,Xn,1:T),模型训练后生成时间数据服从的分布定义为
式中:D为分布间距离。
TimeGAN 模型由自编码网络(嵌入函数和恢复函数)与生成对抗网络(生成器和判别器)联合训练,使得模型同时实现分布特征学习、静态与时间特征生成及交替训练[18]。其模型结构如图2 所示。

图2 模型架构、各部分功能和联系Fig.2 Model structure,functions and connections of each part
2.1 嵌入函数和复现函数
嵌入和复现函数用于获得风电特征和潜在空间之间的映射,并对风电数据特征降维,在低维特征空间中学习风电数据的潜在时间特征。设HS和HX为与风电特征空间ℑ 和ℵ相对应的潜在向量空间,那么嵌入函数将其静态和时间特征转换为隐含空间编码hS,即:h1:T=e(S,X1:T)。
式中:eℑ:ℑ →HS为风电静态特征的嵌入网络;eℵ:HS×HX×ℵ→HX为风电时间特征的递归嵌入网络。与嵌入网络相反,复现函数将风电静态和时间特征重建为,即:
式中:γℑ:HS→ℑ 和γℵ:HX→ℵ分别为风电静态和时间特征的复现网络。
作为风电特征和潜在空间之间的可逆映射,其嵌入和恢复函数能够根据原始数据S,X1:T的低维形 式hSh1:T精确地重建。因此,风电TimeGAN 模型第1 个目标函数为重建损失,即:
式中:ΓR为模型的重建损失,即风电静态时间特征原始数据与重建数据之间欧式长度的期望。
2.2 生成器和判别器
生成器不是直接在风电特征空间中合成输出,而是首先输出到嵌入空间中。设ZS和ZX为向量空间,在该向量空间上定义已知分布,并且将随机向量作为输入生成HS和HX。则生成函数采用风电静态和时间随机向量组来生成潜在编码,即:
式中:gℑ:zS→HS和gℵ:HS×HX×ZX→HX分别为风电静态和时间特征的生成网络。
由于随机变量zS遵循随机过程并可以从分布中采样,因此本文使用高斯分布和维纳过程采样风电数据。判别器在潜在空间中操作,生成函数接收风电静态和时间编码,输出分类结果
判别网络对抗损失最大化以提高正确判别输入的风电数据类别准确性[20],即:
式中:ΓU为对抗损失分别为风电静态、时间原始和生成数据的判别结果。
仅依靠判别器的对抗性反馈可能不足以激励生成器捕获数据中的逐步依赖条件分布。因此,TimeGAN 模型通过最大监督损失ΓC以约束生成网络,使风电分布之间的差异进一步降低,即:
其中,根据随机梯度下降的标准,gℵ(hS,ht-1,zt)用1 个样本zt近似估计
图3 描述了模型训练的机制。其中θe,θr,θg,θd分别为嵌入、恢复、生成器和鉴别器网络的参数。训练过程采用Adam 优化器更新网络参数[21],学习率取0.000 1,最大训练次数设为η。首先,使用反向传播算法计算嵌入、复现、生成器和判别器网络中各参数的梯度即。接着,使用Adam 优化器更新嵌入,复现、生成器和判别器网络的参数。

图3 TimeGAN 模型训练的机制Fig.3 Mechanism of TimeGAN model training
3 预测流程设计
3.1 TimeGAN模型预测实现流程
TimeGAN 模型预测的主要流程为:(1)收集整理风电机组设备容量、数量及风速数据;(2)设置模型参数,将训练样本输入TimeGAN 模型进行训练;(3)模型基于所提训练,以最小化重构、有监督和无监督损失为目标,深度学习风电时间特性并预测随机场景。基于TimeGAN 模型的风电预测实现流程如图4 所示。
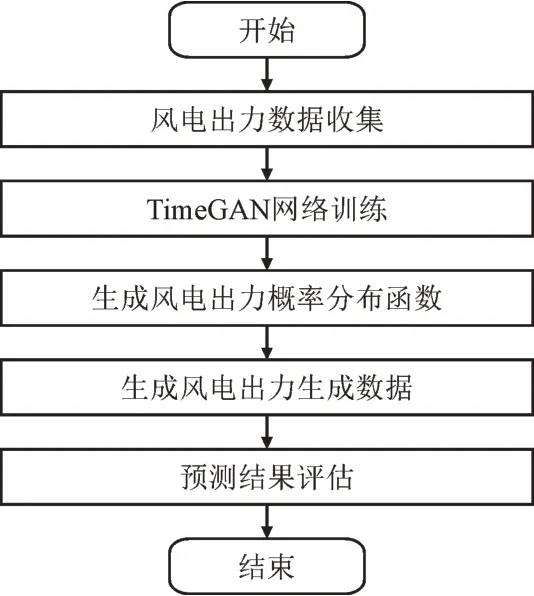
图4 基于TimeGAN模型的风电预测实现流程Fig.4 Implementation process of wind power output prediction based on TimeGAN model
3.2 模型有效性检验
本文运用TimeGAN 模型对风电日运行随机场景(概率分布)进行预测。因此,与传统的点、区间预测效果刻画指标不同,本文构造了能够定量刻画分布及分布之间差异的指标。这些指标能够更全面准确地评估预测结果,为大规模风电等可再生发电系统的日前调度决策提供更有效的参考依据。
1)分布刻画指标。为了定量刻画模型的预测能力,本文运用了随机场景概率分布的矩信息构建指标,对比分析不同模型的预测能力。
式中:,E分别为样本随机场景和各模型生成随机场景的期望。ε为相对期望指标,表征生成随机场景的期望与样本期望的差异性。ε越小,生成随机场景的期望与样本期望的差异越小,模型学习随机分布的能力越强,预测精度越高。
2)分布距离指标。为了直观且定量地对比模型预测能力,本文引入KL(Kullback-Leibler Divergence)距离概念,以衡量相同空间里的样本场景和生成随机场景概率分布的差异情况。
式中:τ为生成分布与样本分布P之间的差异,计算得到的τ值越小,与P2 个分布差异越小,模型预测精度越高。
4 算例仿真
4.1 训练数据处理及评估指标设计
实验风电场的样本数据集来自山东省某风电场,共收集到365 组(8 760 个时间节点)风电历史数据,如图5 所示。分别将风电历史数据代入式(1)和式(2)计算得到其平均值及误差,并作为静态和时间特征训练样本。

图5 风电历史数据Fig.5 Historical data of wind power
本文计及风电的时间相关性,将样本数据按照季节分为4 组,分别运用TimeGAN,连续循环神经网络生成对抗网络(Continuous Recurrent Neural Network Generative Adversarial Network,C-RNNGAN)和循环条件生成网络(Recurrent Conditional GAN,RCGAN)模型进行训练得到生成数据。其中,TimeGAN 模型主要由门控循环神经单元(Gated Recurrent Units,GRU)组成[22],其结构详细设置见表1、表2[23]。其中,dim 为神经元个数,其最大训练次数η设为8 000。C-RNN-GAN,RCGAN 模型结构参照文献[24-25]。
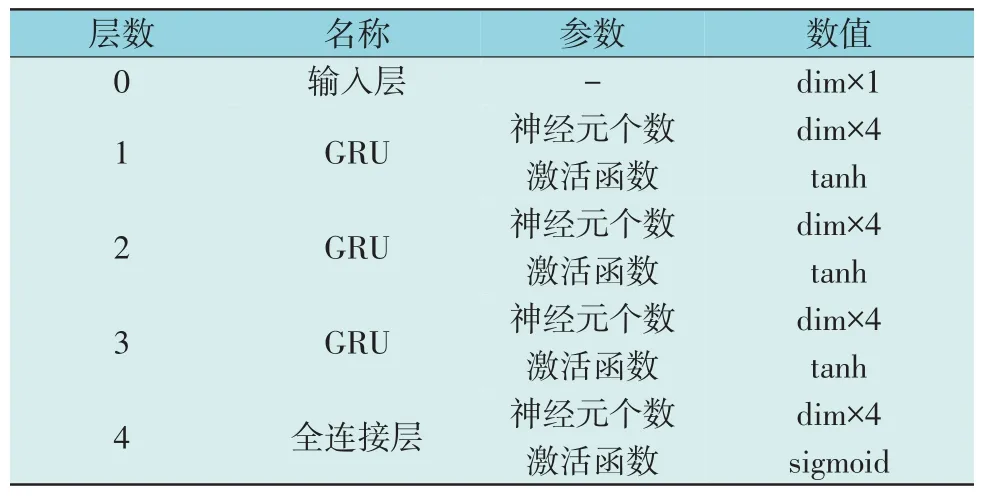
表1 嵌入网络、恢复网络、生成网络结构Table 1 Structures of embedding network,recovering network,generating network

表2 判别网络结构Table 2 Discriminating network structure
4.2 预测效果验证及方法比较
4.2.1 预测效果评估及验证
基于TimeGAN 模型输出风电预测随机场景,本文在样本数据集和生成数据集上,用可视化降维方法t-Distributed Stochasitc Neighbor Embedding(t-SNE),定性分析TimeGAN 模型生成的样本在二维空间中的分布与原始样本分布的相似性。t-SNE是一种非线性降维方法,在保留数据的全局和局部结构的前提下,将高维数据集映射到二维或三维空间中,主要用于验证无监督学习算法的有效性及实现可视化[26]。
在t-SNE 图中,可以根据高维数据点在低维空间中的位置解释生成分布和真实分布的相似性及差异性。t-SNE 图中生成数据点和真实数据点分别表示生成和真实数据的二维空间映射值,如果在t-SNE 图中2 种点靠得很近,那么相应数据在原始空间中也很相似,模型生成数据的分布与真实分布接近。相反,如果2 种数据点在t-SNE 图中相距很远,那么相应数据在原始高维空间中也具有差异性,模型生成随机场景的分布与真实分布不接近。图6 为本文预测得到的t-SNE 图。

图6 TimeGAN模型t-SNE分析结果Fig.6 Results of t-SNE analysis of TimeGAN model
图6 中,真实数据点和生成数据点分别表示运用TimeGAN 模型分别训练春、夏、秋、冬4 季的风电样本随机分布后生成分布和真实分布在二维空间中的映射值。图6 中真实数据点和生成数据点均靠得很近,春、夏、秋、冬4 季中,模型生成随机场景分布与真实分布均非常接近,具有一定适用性。
4.2.2 预测方法比较
本文选取原理类似的C-RNN-GAN 模型和RCGAN 模型与TimeGAN 模型进行对比。向TimeGAN,C-RNN-GAN,RCGAN 模型分别输入各季节的风电出力训练样本得到生成数据,并输出预测风电出力的随机场景(及概率分布),最后计算得到生成数据分布的矩信息(包括期望值和标准差)和生成数据分布与样本数据分布之间的KL 距离,并代入式(14)和式(15),得到结果如图7 所示。

图7 各模型相对期望指标和KL距离结果Fig.7 Results of relative expected indicators and KL distance for each model
由图7 可知,与RCGAN 模型和C-RNN-GAN模型相比,TimeGAN 模型在春、夏、秋、冬4 季的相对期望指标和KL 距离均最小,即TimeGAN 模型生成随机场景的矩信息与样本随机场景矩信息最相似,且生成随机场景分布与样本随机场景数据分布之间的KL 距离均最小。
综上所述,TimeGAN 模型在各评价指标比其他模型更优,相比于其他模型,春、夏、秋、冬4 季中,TimeGAN 模型学习风电数据整体分布和时间逐步依赖分布的能力均有所提高,与定性分析t-SNE 的结论一致,表明TimeGAN 模型在风电时间数据潜在信息学习方面有更高的效率,在时间预测问题上有更好的精度。
4.3 模型学习能力分析
本文的最大训练次数是在训练TimeGAN 模型时设定的允许模型进行参数更新的最大训练次数η。参数η的选择对于模型的学习过程和预测精度都具有重要影响。最大训练次数的大小决定了模型能够学习到样本分布信息的全面程度,从而直接影响其预测的精度。因此,在TimeGAN 模型中其他嵌入网络、恢复网络、生成网络和判别网络结构和网络间参数设置不变的前提下,为反映模型的学习能力,改变最大训练次数参数,研究分析最大训练次数对生成概率分布与样本概率分布间的KL 距离的影响,具体结果见图8。
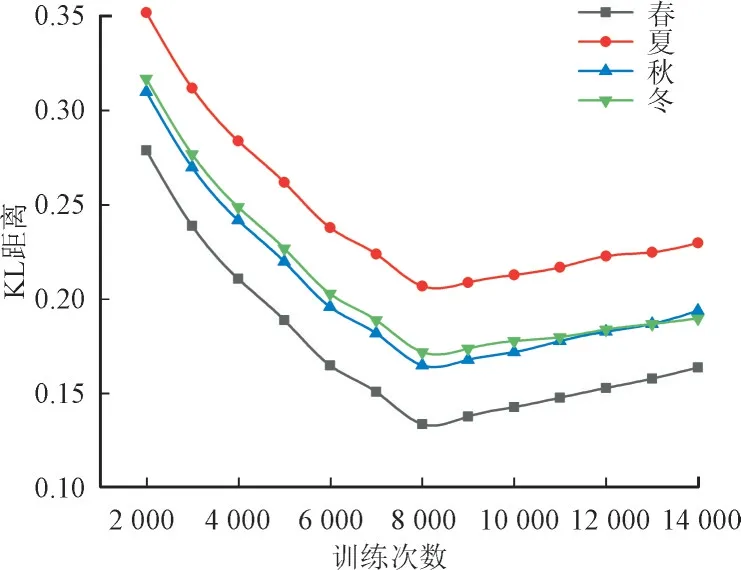
图8 TimeGAN模型不同最大训练次数下的KL距离结果Fig.8 KL distance results of TimeGAN model under different maximum training times
由图8 可知,各个季节中,当最大训练次数η为8000 时,生成概率分布与样本概率分布间的KL距离最短,TimeGAN 模型学习样本分布能力最强,预测精度最高。在各个季节中,当η<8 000 时,η越小生成概率分布与样本概率分布间的KL 距离越大,这是因为当最大训练次数较小时,模型在有限的迭代次数内可能无法充分学习到样本数据中的复杂模式和分布特征。这可能导致模型在预测过程中缺乏对数据分布的全面理解,从而限制了其预测的准确性和鲁棒性。在各个季节中,当η>8 000时,η取值离8 000 越远,生成概率分布与样本概率分布间的KL 距离增大,这是由于将最大训练次数设置得过大,模型会过度记忆训练数据中的细节和噪音,而无法从中提取出真正的潜在模式和规律,即模型可能会在训练数据上过拟合,导致对新样本的预测效果下降。
最大训练次数对于TimeGAN 模型学习样本分布信息的全面程度和模型预测精度具有重要影响,确定最大训练次数需要在训练过程中进行权衡和调整。本文确定最大训练次数η为8 000,使得模型能够在有限的迭代次数内充分学习到数据的分布信息,同时避免过拟合的问题,模型对数据的理解和预测的准确性较高,从而更好地应用于实际场景中的时间序列数据分析和生成任务。
5 结论
鉴于风电的随机性和时间相关性,提出一种基于时间生成对抗网络的风电随机场景预测模型。通过算例仿真得到主要结论如下:
1)基于可视化降维方法t-SNE 定性分析TimeGAN 模型预测效果,验证了生成数据分布与真实数据分布较为接近,表明所提模型预测的风电场景依概率分布接近于样本数据,具有较高的适用性。
2)通过构建指标定量对比TimeGAN 模型与RCGAN 和C-RNN-GAN 模型,结果表明TimeGAN模型生成随机场景的矩信息与样本矩信息最相似,且KL 距离最短,说明TimeGAN 模型学习随机场景分布能力最强,具有最高的预测精度。
本文提出的TimeGAN 模型通过全面学习样本历史变化规律,能够有效克服风电出力的内在间歇性和波动性,使风电出力短期预测更加准确,风电场可以更准确把握未来一段时间内风力资源的分布情况,有助于减少弃风,从而确保风电大规模并网后电力系统运行的稳定性、可靠性和安全性。
