基于双注意力机制的多分支孪生网络目标跟踪
2023-08-25李晓艳王鹏郭嘉李雪孙梦宇
李晓艳,王鹏,郭嘉,李雪,孙梦宇
(西安工业大学 电子信息工程学院,陕西 西安 710021)
近年来,随着人工智能和智能算法处理技术的不断发展和广泛应用,目标跟踪一直备受关注.目标跟踪主要是在目标受到光照变化、遮挡、尺度变换、形变等复杂情况下,仅通过首帧中的目标位置和尺度信息,便可以实时、准确地对后续帧中的目标进行定位和尺度估计.
基于孪生网络的目标跟踪一直是国内外该领域的重点研究方向.Bertinetto等[1]提出基于离线端到端训练的SiamFC算法.Valmadre等[2]提出CF-Net,是在SiamFC的结构上加入可以端到端训练的相关滤波器层.He等[3]提出SA-Siam,构建2个孪生网络框架,一个是语义网络,另一个是外观网络,2种网络互补,提升了目标跟踪的性能.Li等[4]为了应对基于孪生网络的目标跟踪无法有效利用深度网络特征的问题,成功训练了基于ResNet[5]架构的SiamRPN++算法.Wang等[6]提出的SiamMask结合目标跟踪和目标分割2种网络,可以同时完成视频跟踪和分割的任务.为了使跟踪领域的理论结构更加完善,Xu等[7]提出Siam-FC++,在SiamFC的基础上引入分类分支和目标状态估计分支.本文通过加入双注意力机制,新增上一帧模板分支及局部扩大搜索方式,提升了目标跟踪的性能.
1 本文算法
由于SiamRPN++在跟踪过程中不能有效地应对严重遮挡或目标严重形变的问题,使得在跟踪过程中应对遮挡情况的效果不佳,对复杂背景下的目标判别能力不强.针对以上问题,在原有的主干网络上加入双注意力机制,提升跟踪过程的抗干扰能力.增加上一帧模板分支,采用三元组损失用以应对目标严重形变时的情况.在判断目标受到遮挡后,依据目标移动速度进行局部扩大搜索,做到跟踪过程中目标在受到短时完全遮挡后可以重新跟踪到目标.改进后的算法跟踪模型的总体结构如图1所示.
图1中,ECA_GEC_RPN表示添加双注意力机制改进后的RPN模块,经过共同加权融合定位目标后,确定目标位置及尺度.在此过程中会监测跟踪目标的置信度,当置信度低于阈值τ1时,上一帧模板分支对样本及时进行更新,共同加权融合,确保在目标产生较大变化时,对目标的预测保持稳定.当置信度低于阈值τ0时,依据目标的运行速度,对跟踪区域进行局部扩大搜索,直至发现目标.
2 相关工作
2.1 融合双注意力机制
注意力机制能够根据不同特征在分类和回归操作中的贡献程度,为特征的重要通道或空间分配较高的权重,使得整体网络表现出更强的跟踪效果[8].将双注意力机制与RPN区域提议网络相结合,如图2所示.
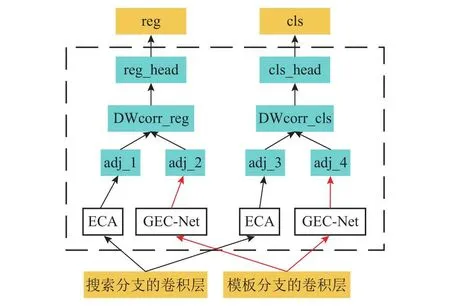
图2 结合双注意力的RPN结构图Fig.2 RPN structure diagram combined with dual attention
ECA[9]结构即是通道注意力模块,用以学习生成不同模板特征的通道相关的权重.为了减少无关图像区域的干扰,提高图像的空间感知性能,搜索图像不直接通过通道注意力机制模块.搜索分支的优化是从网络特性的角度考虑,孪生网络中采用卷积神经网络对目标进行特征提取,但在该方式下提取到的目标特征只是目标的局部特征,没有获取全局上下文特征.为了更好地使用本文特征提取网络中所提取的浅层、中层和深层特征,也为了增强搜索分支的特征提取能力,引入全局上下文注意力机制,提升目标跟踪过程中的泛化能力.
通道注意力ECA模块由平均池化层、全连接层、一维卷积核和激活函数层组成,结构如图3所示.该模块的输入为各个通道的深度特征图Fw×h×d=,其中w、h、d分别为宽、长和通道数,即模板分支不同层次的特征.经过平均池化层降采样缩小输入特征图的规模,减少与空间无关的计算,生成尺度较小的通道特征图Fw′×h′×d′作为第1个全连接层的输入.SE-Net[10]注意力机制模块采用激活函数跨通道降维的方式实现非线性跨通道交互,会造成有效信息的丢失.为了更准确地赋予通道权重,如图3所示,采用无降维的局部跨通道交互策略,利用大小为k的快速一维卷积生成新的全连接层,其中k通过通道数d自适应确定.通过Sigmoid激活,得到各个通道的权重.将生成的权重与输入特征相乘,以此来得到最终的通道注意力特征图通道i的注意力特征图如下:

图3 通道注意力模块结构图Fig.3 Structure diagram of channel attention model
式中:×为矩阵向量的数乘.
k决定交互的覆盖范围,不同的通道数和卷积块可能会有不同的表现.一般认为通道尺寸越大,长交互作用效果越强;通道尺寸越小,短交互作用效果越强.根据这种映射关系,求取k的关系式如下:
由于通道数常为2的整数次幂,用2(γk-b)取代指数次幂,其中γ和q表示常数经验值.对于给定的d,可以自适应确定内核k:
对搜索分支进行优化后,再将改进后的GCNet[11]添加至搜索分支,用于获取非局部信息.主要的工作过程如下:采用1×1卷积Wk和Softmax函数在上下文建模的全局注意力机制中得到自注意力权重;通过特征转换,获取通道依赖性;使用加权,将全局上下文特征聚合到每一个位置的特征上.全局上下文模块工作过程的表达式如下:
式中:X为该网络结构的输入,Z为该网络结构的输出,Np为图像上的所有位置数,为上下文模型, δ(·)为捕获信道依赖关系的特征变换,M(·,·)为融合函数.
改进前、后的全局上下文模型的详细结构如图4所示.如图4(a)所示为未改进的全局上下文模块,如图4(b)所示为改进后的全局上下文模块,模块内的各阶段与3个过程对应.从图4(a)可以看出,全局上下文注意力模块结合了全局注意力模块Wk与SE-NET模块Wv1,由于ECA具有更优的通道注意力性能,将Wv1模块中的LayerNorm操作替换为ECA的快速一维卷积.

图4 全局上下文注意力模块的结构图Fig.4 Structure diagram of global context attention module
搜索分支的特征输入至改进后的全局上下文网络,依次通过主要操作的3个过程.通过3个过程对特征进行转化后,获取到通道依赖性的部分.使用ECA通道注意力机制,既提升了通道注意力机制的性能,又使得网络结构轻量化.全局上下文模型表示如下:
该网络结构属于轻量级模型,全局注意力的应用使得网络能够捕获远程非局部特征.经过全局注意力特征提取后,再转化为通道注意力进行权重赋值,可以有效地提升孪生网络的目标跟踪性能.
2.2 三分支与三元组损失的目标定位
为了提升孪生网络目标跟踪在应对目标形变较大或短时严重遮挡情况下的跟踪性能,如图1所示,添加上一帧模板分支.图中,上层表示模板分支,固定以第1帧z0为模板,输入图像的大小为127×127像素;中间部分是搜索分支,也是后续帧x的输入,输入图像的大小为255×255像素;下层表示上一帧模板分支,当判别目标受到部分遮挡时发生的较大形变后,将遮挡前的定位结果进行裁剪,得到新的模板帧zp,输入图像的大小与第1帧模板分支相同,与搜索分支进行相似性判别后,开展深度特征融合与联合判别.
与双分支不同的是,三分支孪生网络在训练过程中将图像分成3组.第1帧模板分支是随机从一个视频序列中选择一帧,搜索分支中正样本是从当前视频序列中随机选取图像,负样本是从其他视频序列或添加好的目标跟踪数据集中获取.为了防止目标外观变化过大所带来的不利影响,设定两分支中选取的2帧图像之间间隔不超过100帧,上一帧模板的选取与搜索帧的序号有关.为了使得搜索分支的图像与上一帧模板分支图像中的目标外观相差较小,上一帧模板选取的设计条件如下:
式中:#为帧序号;g为帧间隔,取值为较小的正整数;|L|为视频序列的长度,通过该操作可以达到搜索帧与上一模板帧相近的采样效果.
跟踪初始化时,获取第1帧图像同时作为第1帧模板和下一帧模板.在跟踪过程中,第1帧模板不发生改变,当跟踪输出的评分一直为较高值时,不进行更新.当目标发生部分遮挡或形态变化时,跟踪输出的评分会低于阈值τ1,此时上一帧模板进行更新,在该过程中,会对上一次的跟踪结果进行裁剪.为了避免较严重遮挡和短时完全遮挡,上一帧模板分支会在高于阈值τ0的情况下进行更新,裁剪过程如下:
式中:wrap(·)为图像的裁剪函数,f(z0,x,zp)∈[τ0,τ1]为三分支孪生网络目标跟踪所得到的响应得分,b-1为选取上一帧的目标跟踪框.
若判断出目标响应得分处于[τ0,τ1],则对跟踪结果进行裁剪,得到上一帧模板帧.将裁剪得到的样本作为上一帧模板帧,更新模板分支中的第1帧图像,更新模板进行加权判决,提高了跟踪的抗遮挡和严重形变的能力.模板更新的过程如图5所示.图中,H表示不断更新的搜索分支;zp表示在固定阈值内对上一帧模板分支进行更新,上一帧模板分支与第1帧模板分支一起加权融合定位目标,可以有效地提升目标跟踪过程中算法在复杂场景下性能的鲁棒性.

图5 模板更新的示意图Fig.5 Schematic diagram of template update
由于在目标形态发生严重变化时,引入了上一帧模板分支,用于对模板分支的图像进行更新,这对网络的训练过程带来了一定的挑战.考虑到样本特征的聚合,在增强目标判别能力的同时,正负样本的特征数量会增加,此时使用传统的交叉熵损失可能提取不到表达深层特征的目标信息.为了准确地区分复杂环境下的前景与背景,不同于双分支孪生网络的训练过程,上一帧模板分支采用判别能力更强的三元组损失进行分类判别.
2.3 局部扩大搜索
目标在运动过程中可能会受到车辆、树木和建筑物的干扰,在行径间被遮挡的情况下目标会在一段时间间隔后再次出现.此时若判别目标丢失后直接启动全局搜索,则会大大增加计算成本.为了防止搜索过多的无效区域,在目标丢失后,采用局部扩大搜索的机制.
将目标的中点(x+w/2,y+h/2)视作目标在图像中表示的位置,其中x、y、w、h分别为预测目标框左上角的横、纵坐标以及框的宽和长.确定中点的优点是可以将目标视为质点,方便确定目标的运动轨迹和运动速度.计算视频中质点的运动速度v通过帧之间质点的移动像素数n及所用时间t计算,即v=n/t可以表示目标的运行速度.为了更好地将速度作为参考量,开展归一化操作,如下所示:
式中:vmax、vmin分别为速度列表中目标运动速度的最大值和最小值,通过归一化操作,将速度的表示量限定在[0,1.0].通过实验可知,扩大搜索的区域是样本分支中目标区域的3~6倍,以此达到有效重检测的效果.构建扩大搜索函数如下:
式中:255为原搜索模板的大小,500为扩大后的最大搜索模板大小.为了不引入过多的干扰量,扩大搜索期间不进行模板更新.
当跟踪的得分小于一定阈值时,可以认为已经丢失目标.此时,根据目标的运行速度进行局部扩大搜索,三分支共同定位增大了目标框的稳定性,减少了漂移情况的发生,目标框的逐步扩大有利于短时完全遮挡后更加高效地跟踪到目标.
3 实验方法和结果
3.1 实验环境及参数设置
本文的实验环境是Intel Xeon(R) Gold 5118 CPU @2.30 GHz*48处理器、NVIDIA Quadro P6000 24 GB专业图形显卡,使用的深度学习框架为Py-Torch1.2.0开发环境,编程语言及版本为python3.6.5.在上述实验环境下,批处理大小batch size设置为64,训练的初始学习率为3×10-2,终止学习率为5×10-4,采用随机梯度下降(SGD)的方式,动量大小设置为0.9,权重衰减率为10-4.
3.2 训练集和测试集
在以下4个训练集上对改进算法进行训练.
1)COCO数据集:共20 GB,主要从复杂的日常场景中截取,图像包括328 000个视频和2 500 000个标签数据.每幅图像平均包含的目标数较多,因此该数据集常用作目标跟踪算法训练的数据集,可以有效地增强跟踪过程中的判别能力.
2)ImageNet-DET数据集,使用49 GB,该数据集已标记图像中所有类别的边界框.类别是根据不同的因素选择的,例如对象比例、图像混乱程度、对象实例的平均数量等.
3)ImageNet-VID数据集:约86 GB,数据集包含3 862个片段用于训练,每个片段包括56~458帧图像.在跟踪算法训练时,可以有效地提供目标在运动时的变化情况.
4)YOUTUBEBB数据集:共400 GB,含23个类别,共500万个手动注释的目标、紧密贴合对象边界的边界框,精度高于95%.由于孪生网络的目标跟踪算法训练过程主要是训练得到目标运动过程中的变化情况,因此需要大量且丰富的数据集对其进行训练.
为了证明所提算法的有效性,在OTB100[12]数据集上分别选取若干具有挑战的图像序列进行测试,对算法进行定性与定量分析.定性分析是指对不同算法在相同视频序列下的实际跟踪效果进行对比评判,定量分析是指选取中心位置误差、重叠率、成功率和精确度4个指标评价跟踪结果.
3.3 定性分析与讨论
为了对比所提算法,将所提算法称为DSiam-RPNMEG++,将仅加入双注意力机制后的算法称为SiamRPNMEG++,将原算法称为SiamRPNM++算法,选取跟踪效果较优的DaSiamRPN算法与上述3种算法进行实验对比.
如表1所示为选取的跟踪视频序列,在该视频序列下分别对4种算法进行定性及定量分析.这些视频序列以完全遮挡属性为主,每个视频序列还包含了其他属性.在测试中不只考虑算法在遮挡时的表现,也能够体现算法在其他属性下的性能表现.

表1 跟踪视频序列及属性Tab.1 Tracking video sequence and attributes
如图6所示为4种算法在4个序列上的定性分析结果.

图6 定性分析结果图Fig.6 Results of qualitative analysis
如图6(a)所示,在Suv序列中,运动目标高速移动,且受到严重遮挡.第476帧时,采用4种算法都可以准确地跟踪目标.第551帧时,DaSiam-RPN发生目标框漂移.第618帧时,目标被遮挡部分所占的比重极大,只有DSiamRPNMEG++算法可以跟踪目标.第688帧时,只有DSiamRPNMEG++算法与SiamRPNMEG++算法可以准确地跟踪运动目标,其他算法均没有及时地跟踪重新出现后的目标.
在图6 (b)的Skating1序列中,光照变化、平面外翻转及遮挡情况较严重.第27帧时,目标状态不具有挑战性.第162帧时,目标发生遮挡,利用提出的DSiamRPNMEG++算法可以准确地跟踪到目标, SiamRPNMEG++算法、DaSiamRPN算法及SiamRPNM++算法中的目标跟踪框均开始有漂移的趋势.第191帧与第241帧时,SiamRPNM++算法与DaSiamRPN算法均无法跟踪到目标.
在图6 (c)的Girl2序列中,目标受到相似物体的完全遮挡.第10帧时,利用4种算法都可以跟踪到目标.第112帧时,遮挡物出现,目标不处于视野中,SiamRPNM++发生轻微漂移,10帧之后行人不再对目标形成遮挡,只有DSiamRPNMEG++算法逐步扩大搜索,跟踪到了目标,其他算法都形成了漂移.第172帧时,利用SiamRPNMEG++、SiamRPNM++及DaSiamRPN算法无法跟踪到目标.
在图6(d)的Ironman中,目标受到低光照、快速移动、旋转、遮挡等恶劣环境的影响.第21帧时,利用4种算法均可以跟踪目标.第29帧时,DaSiamRPN发生目标框漂移,利用其他算法均可以跟踪目标,但SiamRPNMEG++的尺度判别略微大于目标.第114帧与第142帧时,SiamRPNM++的目标跟踪框随着DaSiamRPN发生了漂移,脱离了目标,而利用DSiamRPNMEG++算法可以准确地跟踪目标.
3.4 定量分析与讨论
3.4.1 中心位置误差测评 中心位置误差的计算公式如下:
式中:C为由算法计算得到的目标中心位置,C′为数据集中由人工标定的实际目标中心位置.中心位置误差越小,算法越好.
从图7的4个中心位置误差结果可知,与SiamRPNM++算法模型相比,DSiamRPNMEG++算法的中心位置误差都降低.相较于SiamRPNMEG++算法,Suv序列误差降低了2.6个像素点,Skating1的中心误差减少了0.39个像素点,Girl2序列中由于SiamRPNMEG++算法不具备应对短时完全遮挡的原因表现最明显,减少了30.15个像素点,Ironman序列减少了2.34个像素点.4个序列中心位置误差相较于原算法平均降低了28.97个像素点.

图7 中心位置误差结果的曲线图Fig.7 Curve chart of center position error results
3.4.2 重叠率测评 重叠率的计算公式如下:
式中:S¯ 为由算法计算得到的目标覆盖范围,S为数据集中由人工标定的实际目标覆盖范围.重叠率越高,算法越好.
从图8可知,利用DSiamRPNMEG++算法所得的重叠率表现最优,4个视频序列均有提升,相较于SiamRPNM++算法,本文算法的重叠率平均提升了14.5%,说明三分支模板更新的孪生网络目标跟踪,可以有效地提高目标在复杂环境下的跟踪性能.为了说明本文算法在遮挡属性下的有效性,在OTB100数据集上选取10个复杂环境下的严重遮挡与短时完全遮挡序列,测试结果如表2所示.表中,lavg为平均中心位置误差,Oavg为平均重叠率.
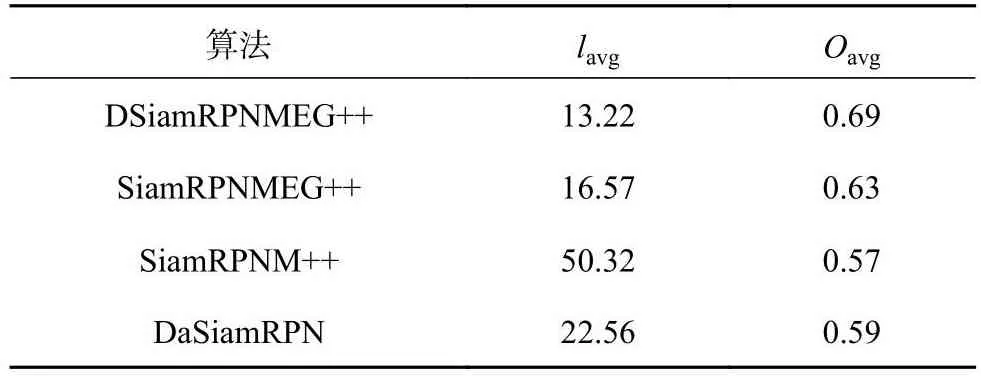
表2 10个跟踪视频序列下的平均中心位置误差与重叠率Tab.2 Average center position error and overlap rate for 10 tracking video sequences

图8 重叠率结果曲线图Fig.8 Overlap rate result curve
从表2可知,在具有严重遮挡与短时完全遮挡属性的视频序列上进行测试,改进后的DSiamRPNMEG++的平均中心位置误差较改进前的Siam-RPNM++降低了37.1个像素点,平均重叠率提升了12%,证明本文算法在跟踪结果上有一定的提升.
3.4.3 成功率 成功率指的是所有视频序列中重叠率大于特定阈值的帧数占总帧数的比例.所得的结果越高,跟踪效果越好.成功率的计算公式如下:
式中:Ts为跟踪重叠率大于特定阈值的帧数,T为跟踪视频的总帧数.
3.4.4 精确度 精确度指的是所有视频序列中,中心位置误差小于固定阈值的帧数占总帧数的比例.精确度的计算公式如下:
式中:Tp为跟踪误差小于跟踪阈值的帧数,T为跟踪视频的总帧数.
为了更好地表现本文算法的跟踪性能,在OTB100整体数据集上开展实验,分别得到成功率和精确度结果曲线图,如图9所示为实验结果.

图9 OTB100数据集下的成功率和精确度结果曲线图Fig.9 Curve of success rate and precision results under OTB100 data set
从图9(a)、(b)可知,在OTB100数据集上,DSiamRPNMEG++算法在所测试的4种算法上取得了最优成绩.相较于SiamRPNM++算法,DSiam-RPNMEG++算法在成功率上提升了2.4%,在精确度上提升了1.6%,提升效果显著;相较于Siam-RPNMEG++算法,成功率提升比较明显,提升了1.4%,精确度提升了0.4%.
当受到遮挡和目标发生形变时,在OTB100数据集下的总体成功率如图10所示.
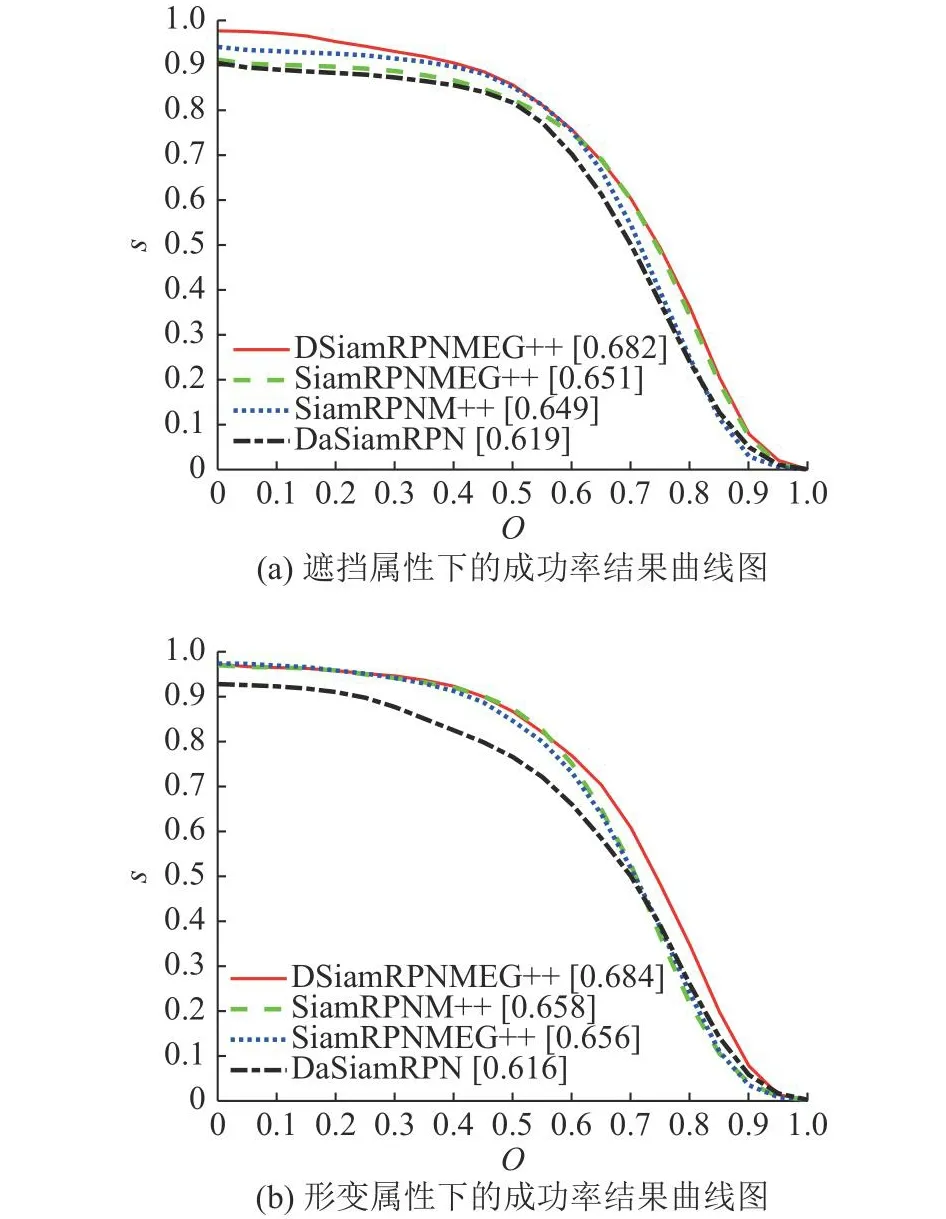
图10 OTB100数据集下包含遮挡和形变属性序列下的总体成功率结果曲线图Fig.10 Overall success rate result curve under OTB100 dataset including occlusion and deformation attributes
当受到遮挡和目标发生形变时,在OTB100数据集下的总体精确度如图11所示.
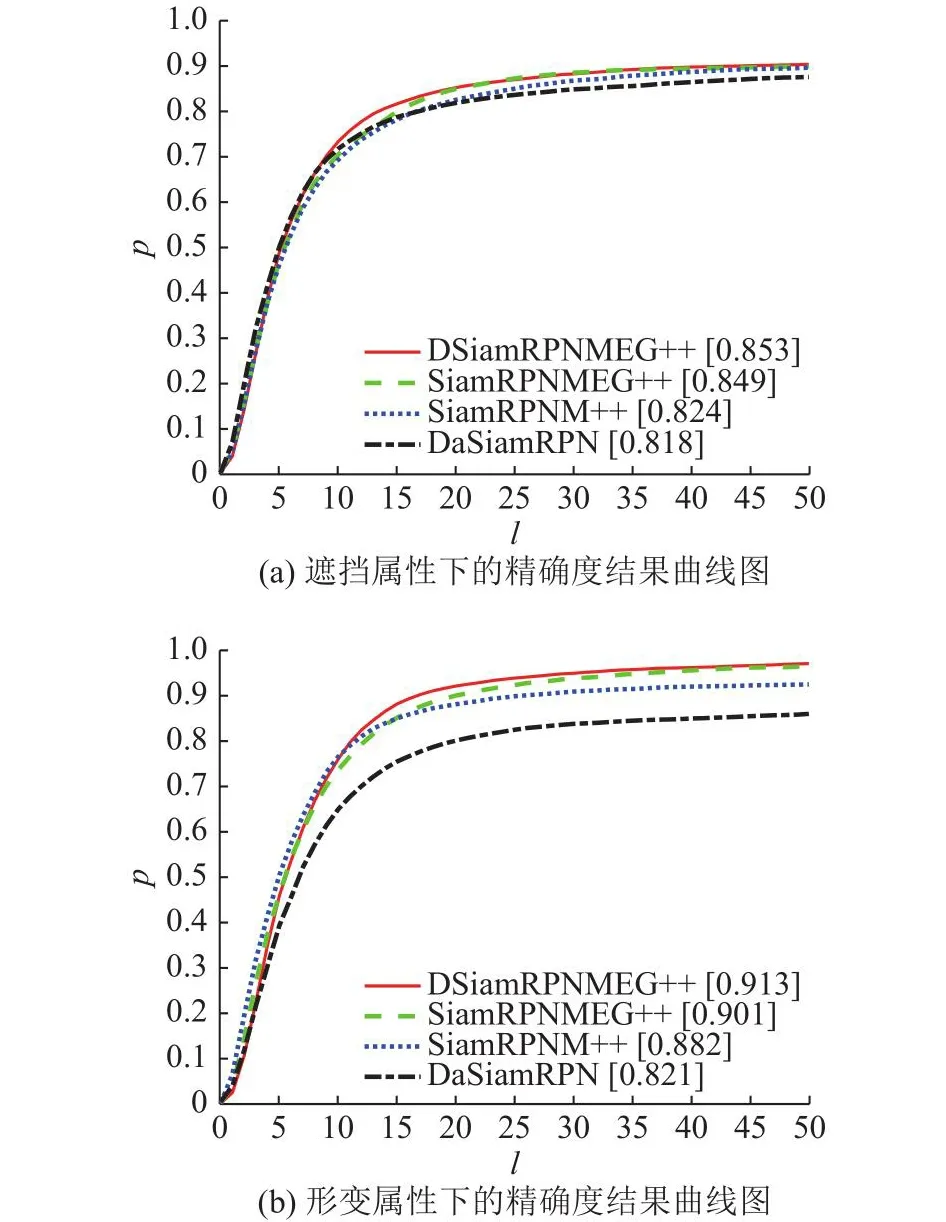
图11 OTB100数据集下包含遮挡和形变属性序列下的总体精确度结果曲线图Fig.11 Overall precision result curve under OTB100 dataset including occlusion and deformation attributes
4 结 语
本文针对目标跟踪受到遮挡的问题,通过提出加入双注意力机制,新增上一帧模板分支及局部扩大搜索策略来提升目标跟踪性能.在目标跟踪领域,解决长时场景下目标受到遮挡时跟踪性能下降的问题是未来需要突破的方向.
