一种交通事故风险预测深度学习算法*
2023-08-22于志青
于志青
(河南警察学院交通管理工程系,河南 郑州 450046)
0 引言
交通事故的风险受多种因素影响。在道路系统性风险方面,如长期存在不安全因素(事故多发等)、反复或周期性出现高风险报警、持续处于高风险状态等;在动态偶发性风险方面,如异常天气、速度波动、危险驾驶行为、大车比例过高、流量过大等风险。
交通事故的防控思路从事故事后分析转向多源数据融合分析、由事故隐患点段分析到安全风险研判,实现主动、系统、精准的预防。常用的风险研判模型包括积分模型、综合评价模型、深度学习类模型等,如卷积神经网络模型、随机森林神经网络模型等,属于深度学习模型,也是多元异构数据融合技术。为了充分利用多源数据的特征,提高交通事故风险预测精度,有学者对常用的深度学习模型进行优化,程慧玲将卷积神经网络与随机森林神经网络相结合,提出卷积随机森林神经网络预测模型[1];包杰将卷积神经网络与长短时记忆神经网络结合,提出卷积长短时记忆神经网络预测模型[2];王庆荣等利用时空图卷积神经网络进行预测[3]。
本文利用常用的深度学习算法,构建卷积长短时记忆随机森林神经网络算法,给出基于该算法的道路交通事故风险预测模型,采用互联网上公开的英国UK Car Accident 2005-2015 年交通事故数据进行实验,以获得诱发道路交通事故的重要因素。
1 深度学习算法
主要介绍文章用到的三种深度学习算法:卷积神经网络算法、随机森林神经网络算法、长短期记忆神经网络算法[7-11]。
1.1 卷积神经网络算法
卷积神经网络的基本构成单元为神经元,神经元有三个基本要素构成①一组连结,②求和单元,③激活函数。另外还有设置的阈值,表达如下:
其中,x1,x2,…,xp为输入信号,输入信号与神经元k的连接权重用符号wk1,wk2,…,wkp表示,bk为偏置,激活函数用φ表示,神经元输出用yk表示。
1.2 长短期记忆神经网络算法
其计算过程用上一时刻的隐藏状态输出ht−1和当前时刻输入xt,计算当前时刻t的隐藏状态输出ht,公式如下:
其中,w是输入权重矩阵,u是状态转移权重矩阵,b表示偏置,σ,tanh为激活函数,*代表矩阵运算。
1.3 随机森林网络算法
该算法是集成学习算法,既可以用于分类,也可以用于回归,是对多个决策树以相互独立的方式进行训练,在得到结果时,对于分类问题用投票原则,所有决策树结果中哪一类出现的最多,认为是分类结果。ID3,C4.5和CART是构建随机森林常用的基本方法。随机森林分类效果的评判标准。
样本的Gini系数为:
其中,pi代表类别在样本集S中出现的概率。
用Gini值作为随机森林分类效果的评判标准:
特征xj在节点m点Gini值为Gjm=Gm−Gl−Gr其中,Gm是节点m的Gini值。Gl,Gr分别表示当前节点左子节点、右子节点的Gini值。xj在决策树之中有节点集合M,xj在决策树之中Gini值为:
在随机森林中有n棵树,则xj的Gini值为:
最后还可以做归一化处理。
Gini值越小,说明数据集的纯度越高。
2 卷积长短时记忆随机森林神经网络算法及预测模型
2.1 算法
将卷积神经网络、长短时记忆神经网络、随机森林神经网络结合,构建卷积长短时记忆随机森林神经网络,其基本结构为:基于卷积神经网络,在特征提取时,根据提取对象特性,分别采用卷积神经网络、长短时记忆神经网络作为特征提取器,卷积神经网络的多层全连接与分类器由随机森林神经网络取代。结构图如图1所示。
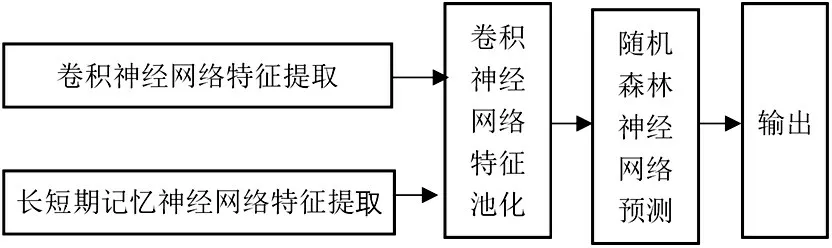
图1 卷积长短时记忆随机森林神经网络结构图
2.2 模型
首先筛选出对交通状态影响较大的20类因素(见表1分类变量)。将这20类变量划分为I、II类变量。

表1 变量分类表
I类变量主要指在研究周期内仅在空间上变化、但是不随时间变化,这类变量通常采集周期较长,故在研究周期内可视为时间常量。II类变量在研究周期内仅随时间变化但不随空间变化,具有周期性和时间依赖性。
对表1 选取的20 个变量可根据时间、空间的变化进行分类。
I 类变量:道路类型、地形条件、道路线型、道路横断面位置、路面情况、路口路段、道路物理隔离、路侧防护设施、事故形态、交通控制方式等。
II类变量:事故时间、天气条件、能见度条件、照明条件、肇事机动车行驶状态、肇事机动车安全状态、肇事机动车、肇事人年龄、肇事机动车驾驶人驾龄、事故原因等。
I 类变量用卷积神经网络提取特征。II 类变量用长短时记忆神经网络提取特征。两类变量特征提取后,经随机森林神经网络分类预测,输出预测值。
卷积长短期记忆随机森林神经网络算法的道路交通事故风险预测模型的输出值在0 到1 之间。若输出值越接近0,表明该情况下发生交通事故的风险越低,反之极有可能发生交通事故。
3 卷积长短时记忆随机森林神经网络交通事故风险预测
基于卷积长短时记忆随机森林神经网络交通事故风险预测模型,采用公开的英国UK Car Accident 2005-2015 年交通事故数据,结合某省2019-2020 年道路交通事故数据统计指标,以及参考资料[4-6],筛选出诱发交通事故的20个因素变量,其数据经处理后作为卷积神经网络、长短时记忆神经网络提取特征的输入数据,其分类及赋值如表1所示。
⑴I类变量
经过卷积神经网络的2 层处理,即1 层卷积层、采样层,2层卷积层、采用层,输出
对于公式⑴,需要在各层更新权重和偏置,卷积层的权重和偏置更新方式为:
设J 为目标函数,则
其中,wl为权重,bl为偏置。
yl=φ(ul),其中l代表网络的第l层。
将ul、yl表达式代入式⑽、式⑾得:
其中,φ'(ul)表示激活函数的导数。
其中,∙为Hadamard乘积。
这里取l=2,激活函数为Relu函数,表达式为:
目标函数J为:
其中,yi为样本网络输出值,ti为样本值,也称为均方差损失函数。
⑵II类变量
构建2 层长短时记忆神经网络,提取II 类变量特征,输出为,对权值和偏置更新过程,重点讨论隐藏状态的权值更新,其他状态的权值和偏置更新可作相应的推导[8],因为隐藏状态的权值与梯度消失爆炸直接相关,也就是式⑵中的u,其他变量及函数如式⑶~式⑺。根据文献[9],有
其中,L为目标函数,在这里取L均方差损失函数。在t=2时,有
经过两种特征提取算法得到特征值,经过融合计算,其输出值为:
利用CART 构建决策树,与套袋法结合构建随机森林,用Gini(公式⑻)作为评判标准,其构建过程如下:
⑴在样本集合N中有放回的每次取1 个样本,共抽取N1次,用N1个样本训练生成一个决策树。
⑵若每个样本有M个特征,在构建决策树时,只从这M个特征中选取m个特征,在分类问题时,可取m为预测特征总数的平方根。
⑶构建CART决策树,以m为基础。
⑷采用套袋法进行随机抽取并投票输出。
关于随机森林中决策树的数量及随机森林内部各子树随机选择属性的个数,随机森林软件包中均有相应设置。
采用随机森林网络算法,对融合后特征值y(t式⑾)重塑成适合作为随机森林算法分类器输入的大小,构成其分类器。最终输出值为一个概率值,越接近1,说明此种情况发生交通事故的概率越大,越接近0,说明此种情况发生交通事故的概率越小。
4 仿真实验
搭建适合TensorFlow2框架keras运行的软硬件环境,选用PyCharm 开发平台,采用Python3.5开发语言,利用英国UK Car Accident 2005-2015 年交通事故数据,并作相应的处理,作为实验训练数据和测试数据,分别为70%,30%,得到诱发交通事故的显著因素为:行驶时段、行驶地理位置、道路形状、行驶速度、物理设施完备程度等。
卷积长短时记忆随机森林神经网络预测交通事故,因对影响交通事故的变量区分了时空特性,因此,该算法对变量的特征提取比用单一的卷积神经网络提取变量特征更加全面,可准确捕获时间和空间两个维度的变量特征,减少了特征损失度。在分类预测时没有采用卷积神经网络的分类和连接层进行输出,而是采用随机森林网络进行分类预测,在随机森林网络输入时,对提取的特征进行融合计算,比用卷积神经网络分类预测有更高的精度。
5 结束语
道路交通事故风险预测数据是道路交通科学管理决策的重要参考依据,诱发道路交通事故的因素有多种,这些因素有的具有时间特性,有的具有空间特性,有的具有时间空间特性,如何利用深度学习算法较全面提取这些诱因的特征并进行预测,是道路交通安全领域研究的课题。本文提出卷积长短时记忆随机森林神经网络算法模型,对诱发道路交通事故的因素,根据其时间特性、空间特性,分别采用卷积神经网络、长短时记忆神经网络算法进行特征提取,充分考虑因素变量的特征,使特征提取更全面、更贴近实际。利用随机森林神经网络算法进行预测,充分发挥了其准确性高、在测试集上表现良好、抗噪声能力强、非线性分类模型等优点。利用英国UK Car Accident 2005-2015 年交通事故数据,结合某省2019-2020 年道路交通事故数据的统计指标,选择20个具有时间性或空间性可能诱发交通事故的因素进行特征提取并预测,得到诱发交通事故的主要因素。进一步的研究,还可以对卷积长短时记忆随机森林神经网络算法模型评估,以及与其他深度学习算法模型在预测道路交通事故风险方面做深入比较。另外,在诱发交通事故变量的选择上,对既有时间性又有空间性的变量也可做深入探讨。
