基于神经网络的电力通信异常数据识别方法
2023-08-22姜辽
姜 辽
(陕西综合能源集团有限公司,陕西 西安 710000)
1 神经网络选取分析
1.1 DBSCAN
通过对数据的统计,选择具有噪声的基于密度的聚类方法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)[1]。DBSCAN 是根据数据的相似度来判定样本的类别,由于同一类型的资料抽样分布范围非常相近,如果该数据的附近有一个类似样本,那么根据该模型的密度可以将这些样本划分成一个集群。与K-means 方法相比,DBSCAN 无须输入类型K就能找到任何类型的聚类[2]。
DBSCAN 具有以下优势:(1)对于任何形式的密集资料集合都能进行聚类;(2)能够在集群过程中发现离群值,不会对异常值产生影响;(3)聚类的结论没有任何偏差。
DBSCAN 存在以下不足:(1)当采样组的浓度不一致且群组间隔有很大差别时,聚类的品质较差;(2)如果一个样本集的数量很大,则聚类收敛的时间会比较久,此时可以搜索最近邻建立的KD 树或者球树进行规模限制;(3)与常规的聚类相比,调参的精度略高,参数的不同会使最终的聚类结果产生显著差异。
1.2 LSTM
长短时记忆网络(Long Short-Term Memory,LSTM)是循环神经网络(Recurrent Neural Network,RNN)的一种改良,可以很好地解决RNN 算法中存在的渐近衰减问题[3]。LSTM 模型的神经元包括4 个模块,即记忆细胞(Cell)、输入门、遗忘门以及输出门。Cell负责存储留在神经元中的历史信息,输入门负责决定Cell 将接受的输入数据,遗忘门负责控制Cell 中的历史数据丢弃量,输出门负责决定输出的数据[4]。
LSTM 是一种类似于RNN 的逆向传输网络,主要包括以下3 个部分。(1)对各神经元沿正向的输出数值进行运算。(2)对各神经元错误项目的数值进行逆向运算。与RNN 相似,LSTM 错误的逆向传输也包含2 种不同的方法。一种是沿着时间的逆向传输,也就是从t时刻开始推算出各点的错误项;另一种方法是将错误项推广到更高的层次。(3)对各加权的误差率按照各自的错误项目来进行权重计算[5]。
2 基于DBSCAN 和LSTM 的电力通信异常数据检测算法
针对目前的电力通信运行状况,采用DBSCAN与LSTM 来进行异常数据自动辨识。采用DBSCAN 算法对经过分析和基础处理后的数据进行自动分析,然后按相似度进行密度聚类,获得离群数据,即异常数据。LSTM 需要预先通过一系列的数据进行训练和学习,根据所获得的变异规则对权重因子进行校正,使得神经网络处于最佳的记忆状况,从而对异常数据中的特定异常值进行有效判定。使用经过训练的LSTM,将判断为非正常状态的时间序列数据作为其输入,然后对前面n段进行预测。在LSTM 中,将判断为异常的时序数据作为其输入,设定最优输入神经元个数为n、最优输出神经元个数为1,即连续将先前n组的最大值输入到LSTM 中,从而得到下一组的结果。在此基础上,将LSTM 的预报结果设定为一个精确数值,同时设定一个上下浮动的临界点,根据上下浮动的阈值来判定序列数据对应的实测值。如果超过该阈值,则该结果被认为是一个离群点。LSTM 的预测值作为修正值继续往前预测,直至序列数据运行结束。
在密度聚类处理中使用DBSCAN,实际情况下若有特殊的异常值要求或根据评分来选择异常数据点,可使用局部离群因子检测(Local Outlier Factor,LOF)算法替代上述步骤,其余各部分均不变。
3 仿真实验
3.1 实验环境
本试验使用Python 编程语言,集成开发环境(Integrated Development Environment,IDE)为Eclipse Pydev,在此基础上编制程序和算法。Numpy 支持多维数组和矩阵操作,为数组操作提供了许多数学功能,是Python 的一种扩充程序库。Pandas 包含许多类库和某些标准的数据模式,为大规模的数据集处理工作提供了必要工具。Matplotlib 是一个Python 2D 绘图库,提供多种不同的打印和跨媒体交互环境,能够产生高品质的图像。Sciki-learn 是一种用Python 语言来完成的机器学习算法,能够完成一些常见的数据预处理、分类、回归、降维以及模型选择等任务。TensorFlow是一种开放源码的机器学习平台,常用于机器学习和深层神经网络领域。
在公开的Moore 数据集上验证电力通信异常数据检测算法。利用pandas 包中的describe 函数和info 函数来初始观测实验数据,从而确定该数据的大体分配和该离散数值的尺寸分配。其中,info 函数主要介绍数据集各列的数据类型,明确数据是否为空值及内存占用情况;describe 函数主要介绍数据集各列的数据统计情况,包括最大值、最小值、标准偏差等。将一天中基本为0 的采样数据剔除,以确保资料的完整。将所有数据中的缺失值进行均值填充,全部用Float格式的字符串进行处理,以确保其正确性。对资料进行Shape 处理,使资料的维数一致,确保以后的模式能够平稳运行。将时间序列的数据按一定的时间长短分割,并加以存储,从而为LSTM 的训练提供一定的资料。
3.2 实验分析
3.2.1 DBSCAN 实验分析
通过DBSCAN 聚类寻找异常点,一般都具有聚类特征。实验中随机抽取资料,并对实验随机获取的数据进行测试,得到聚类结果如图1 所示。
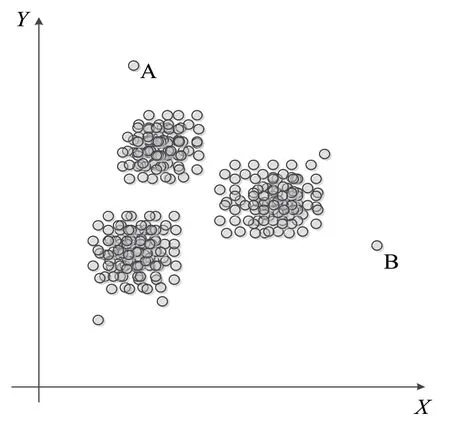
图1 数据聚类效果
聚类的效果主要取决于半径的选择,如果半径过小,则会出现很多不能聚集的离群点;如果半径过大,则会导致分散的区域大量聚集在一起。实际使用过程中,使用者可以依据实际需求选择符合要求的参量,从而得到合适的聚类分区。通过对上述各种参量的聚类结果进行比较,当需要将局部稠度点聚集为若干个集群时,设置最小包含点数阈值(MinPts),通过调节半径的取值使其变小,根据上述要求生成数量众多的簇,但随之而来的是数目众多的散乱离群点。为了解决离群点问题,可以采用二次聚集的方法来降低群体数量,并将这些离散的个体按一定的比例分布到特定的群体。当需要较大的集群时,可以将半径的数值设置较大,从而产生小的集群和小的孤立点。
3.2.2 LSTM 实验分析
根据试验资料的特点,选取经过DBSCAN 模式辨识的异常离群点,作为异常数据。对于每个异常数据包含的时间点序列数据,连续选取前10 个数据点作为LSTM 网络的输入,即将输入的时间序列长度设置为10,将输入维设置为1,将隐含层中的细胞个数设置为8。激活函数为sigmoid 函数,输出的激活函数为tanh 函数。根据LSTM 前向计算和反向传播算法,需要初始化一系列矩阵和向量。这些矩阵和向量有2类用途,一类用于保存模型参数,另一类用于保存各种中间计算结果,以便反向传播算法使用,其中包括各个权重对应的梯度。
通过前向传播Forward 方法实现长短期记忆LSTM 的前向传播计算,通过反向传播Backward 方法实现长短期记忆LSTM 的反向传播计算。值得一提的是,与Backword 相关的内部状态变量事实上是在调用Backward 方法后才开展初始化工作。如果长短期记忆LSTM 只是用于推理工作,那么就不需要初始化这些相关变量,能够提高算法整体性能,节省大量内存。
利用LSTM 算法进行离群值预测,结果如图2所示。

图2 预测结果
由图2 可知,该方法的预测精度随迭代次数的增加而不断提高,损耗值相反,整体逐渐趋于稳定,获得了良好的标定结果。
4 结 论
智能电网是传统电网智能化的产物,集成了电力系统中的电力流、信息流以及业务流。其目标在于优化能源资源的配置,满足居民用电需求,确保电力供应的安全、可靠,降低运营成本,促进节能减排,推动国民经济的发展。通过对电力通信网中的业务进行识别和分类,提升网络中业务的可视化程度,为网络资源调配提供参考。传统方式难以有效处理电力系统产生的大量数据,采用基于聚类的方法进行自动划分。电网数据一般都具有很强的时序性规律,通过将DBSCAN 算法与LSTM 模型相结合的方式来高效检测电网数据异常问题,符合电网运行规律。
