Spark平台下的RDD研究与应用
2023-08-21马兆辉赵睿哲温秀梅
马兆辉 赵睿哲 温秀梅,2*
(1.河北建筑工程学院,河北 张家口 075000;2.张家口市大数据技术创新中心,河北 张家口 075000)
0 引 言
Spark基于RDD实现了一体化、多元化的大数据处理体系,强大的计算能力以及高度集成化的特点使得Spark在大数据计算领域具有得天独厚的优势.在Spark出现之前,Hadoop平台下的MapReduce框架是最热门的大数据计算框架,但是MapReduce框架仍暴露出很多缺点,其中最主要的是迭代计算的中间结果会不停写入磁盘,造成了数据复制严重、磁盘开销大等问题.同Spark框架相比,MapReduce框架表达能力有限,不得不借助第三方工具去完成更为复杂的任务.Spark框架是为了解决这些问题而设计的,Spark框架不仅拥有更丰富的函数,可以对更为复杂的海量数据进行快速操作,而且可以将中间结果存入内存,通过RDD之间存在的依赖关系形成DAG图进行转换操作,实现流水线进程,使用户不必再担心底层数据的特性,减少了磁盘的开销,提升了运行速度,提高了容错性,同时还开发出完整的Spark生态系统,减少了开发和维护成本,对大规模数据的处理更加方便快捷,其各个组件可以共同完成绝大部分的数据处理需求和场景.本文针对Spark中最为重要的核心组件之一RDD进行详细介绍,并通过具体实验进行说明.
1 相关知识
1.1 RDD
RDD(Resilient Distributed Dataset)是弹性分布式数据集,是一种抽象的分布式内存概念,是Spark平台中运行计算的基本存储单元[1].RDD具有强大的容错功能,不仅可以并行处理元素,同时还是一个高度抽象的数据结构,包含多个分区.其创建方式主要包括两大类:一类是来自共享文件系统、HDFS、HBase的外部文件系统,另一类则是通过任何数据源提供Hadoop Input Format.
RDD提供了丰富的操作来对集合中的元素进行操作.其支持两种操作类型:Transformations和Actions.Transformations主要是从一个存在的RDD去产生一个新的RDD,而Actions的操作主要是在数据集上计算之后返回给Driver[2].
1)RDD的依赖
在对RDD进行转换操作的过程中,每个操作都会在已有的RDD的基础上产生新的RDD.由于RDD的惰性特性,新的RDD会依赖于原有的RDD,这样RDD之间就会形成相应的依赖关系.
RDD的依赖关系分为两大类,如图1所示.
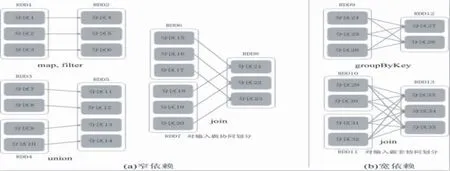
图1 RDD的依赖关系
①窄依赖:是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等都会产生窄依赖;
②宽依赖:是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖[3].
2)RDD之间的转换关系
Spark中最核心的部分就是RDD,RDD是一个不可变、粗粒度的数据集合.在RDD抽象数据模型中提供了丰富的转换操作,然而所有的转换操作都不会实际的执行,这正是由于其惰性特性,因此只会记录操作的步骤,真正的计算发生在RDD的“动作”操作,如图2所示.

图2 RDD的转换关系
3)RDD操作类型
RDD支持两种操作:转换(Transformation)和动作(Action,动作或行动).其中转换操作用于对RDD的创建,是通过操作方法从已经存在的数据集中创建一个新的数据集,动作操作是数据执行部分,主要是指计算数据集里的数据后并将结果返回到Driver.
由于转换操作都具有Lazy特性,即Spark不会立即进行实际的操作,只会记录执行的流程,只有发出Action操作的时候才会真正执行[4].默认情况下,RDD的每个动作在执行的时候,都会将之前的数据重新计算一遍,为了保证计算的高效性以及计算结果的可重用性,在实际计算过程中,根据实际情况,在特定的计算环节上执行persist方法,将计算的中间结果持久化到内存或者磁盘上.如果进行了持久化操作,那么在进行Action操作的时候,就会从内存或者磁盘将已经计算好的数据取出直接用于后续计算,这样节省了计算步骤和时间,同时也提高了整体的计算效率.
4)RDD的弹性特性
RDD之所以被称为弹性数据集,其主要体现在以下几个方面.
①自动将存储在内存和磁盘中的数据切换.RDD是基于内存的,但是当内存“满”的时候,会将一部分数据放到磁盘,前提是持久化级别设置成MEMORY_AND_DISK.
②基于Lineage的高效容错.若计算步骤很多,如果其中某个环节出错,可从指定位置恢复已经计算好的数据,有效避免了重新计算.当然可恢复的前提是在相应位置进行了计算结果数据的持久化.
③Task如果失败会自动进行特定次数的重试.
④Satge如果失败会自动进行特定次数的重试,而且只会计算失败的分区.
⑤检查点和持久化过程.在计算过程中,有的计算相对复杂,若计算链条相对较长或者其结果经常被访问,可以将其结果进行缓存,以便后续直接访问,以此来节省计算时间,提高整体运行速度.
⑥数据调度、DAG调度、Task调度和资源管理无关.Spark集群中任务调度和资源调度是分开的.
⑦数据分区的高度弹性.在计算过程中,当数据分区较小时会降低处理效率,为了提高处理效率,需要将小的分区合并成一个较大分区进行处理;而当数据分区较大时,由于内存大小限制,需要把分区划分成较小的数据分区.可以根据不同的情况设置不同的分区数量和大小,提高或降低并行度[5].
5)RDD运行过程
(1)通过读取集合或来自外部的数据源创建RDD对象;
(2)SparkContext通过RDD的相关操作构建一个DAG作为逻辑执行计划;
(3)DAGScheduler根据ShuffleDenpendency将DAG划分为多个阶段,每个阶段包含多个tasks,之后每个task会被TaskScheduler调度到不同节点的Executor上启动执行.如图3所示.

图3 RDD在Spark中的运行过程
2 RDD的具体实现
使用本地系统创建RDD,在IDEA中实现电商用户页面单跳转化率统计实验和电商热门品类中Top10活跃Session统计实验的具体案例,各软件具体版本如表1所示.

表1 软件及对应版本表
2.1 创建RDD的方式
2.1.1 使用程序中的集合创建RDD
RDD的数据来源可以是程序中的集合,在Spark中可以通过parallelize和makeRDD将集合转化成RDD,SparkContext中的parallelize方法可以指定分区个数.源码如图4所示.

图4 使用程序中的集合创建RDD
2.1.2 使用本地文件系统创建RDD
RDD的数据来源也可以是本地的文件系统,这对于程序中需要进行相对较大的数据量测试是很有必要的.在Spark中可以通过textFile方法来读取本地文件系统创建RDD.源码如图5所示.

图5 使用本地文件创建RDD
2.1.3 使用HDFS创建RDD
HDFS可以作为RDD的数据来源,而且从HDFS上读取数据来创建RDD的方式也是目前Spark生产系统中最常用的方式.源码如图6所示.

图6 使用HDFS创建RDD
2.2 基于Spark的电商用户页面单跳转化率统计实验
页面单跳转化率是指一个用户在一次电商购物过程中访问的页面路径如首页、产品列表页、产品详情页、订单页面、支付页面,首页跳转到产品列表页叫一次单跳,订单页面跳到支付页面也叫一次单跳.单跳转化率就是统计页面点击的概率.根据页面转化率指标的大小,产品经理和运营总监可以分析网站的产品和页面的表现,决定是否需要去优化网站的布局.电商网页页面路径图如图7所示.

图7 电商网页页面路径图
2.2.1 实验分析
实验数据采集自电商的用户行为数据,共包括有180570条数据,其中每一条主要包含用户的4种行为:搜索、点击、下单和支付.实验数据如图8所示.
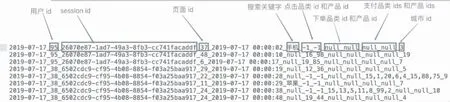
图8 电商用户行为数据
数据中每一行表示用户的一个行为数据,采用“_”分割字段,如果搜索关键字是null即表示无效搜索;如果品类id和产品id为-1即表示为无效点击;用户可同时下单多个产品,即品类id和产品id可为多个,多个数据之间采用“,”进行分割,若不是下单行为即用null表示;用户也可同时支付多个产品,与下单行为类似,若不是支付行为即用null表示.
实验过程首先对数据进行处理,将每一行的数据分割开,读取到规定的页面后,通过reduceByKey转换算子和countByKey行动算子统计出来每个页面的访问次数和每个用户的页面单跳跳转路径并按时间升序排序,然后过滤出单跳跳转目标相同的路径并统计次数,最后计算单跳转化率.实验过程如图9所示.
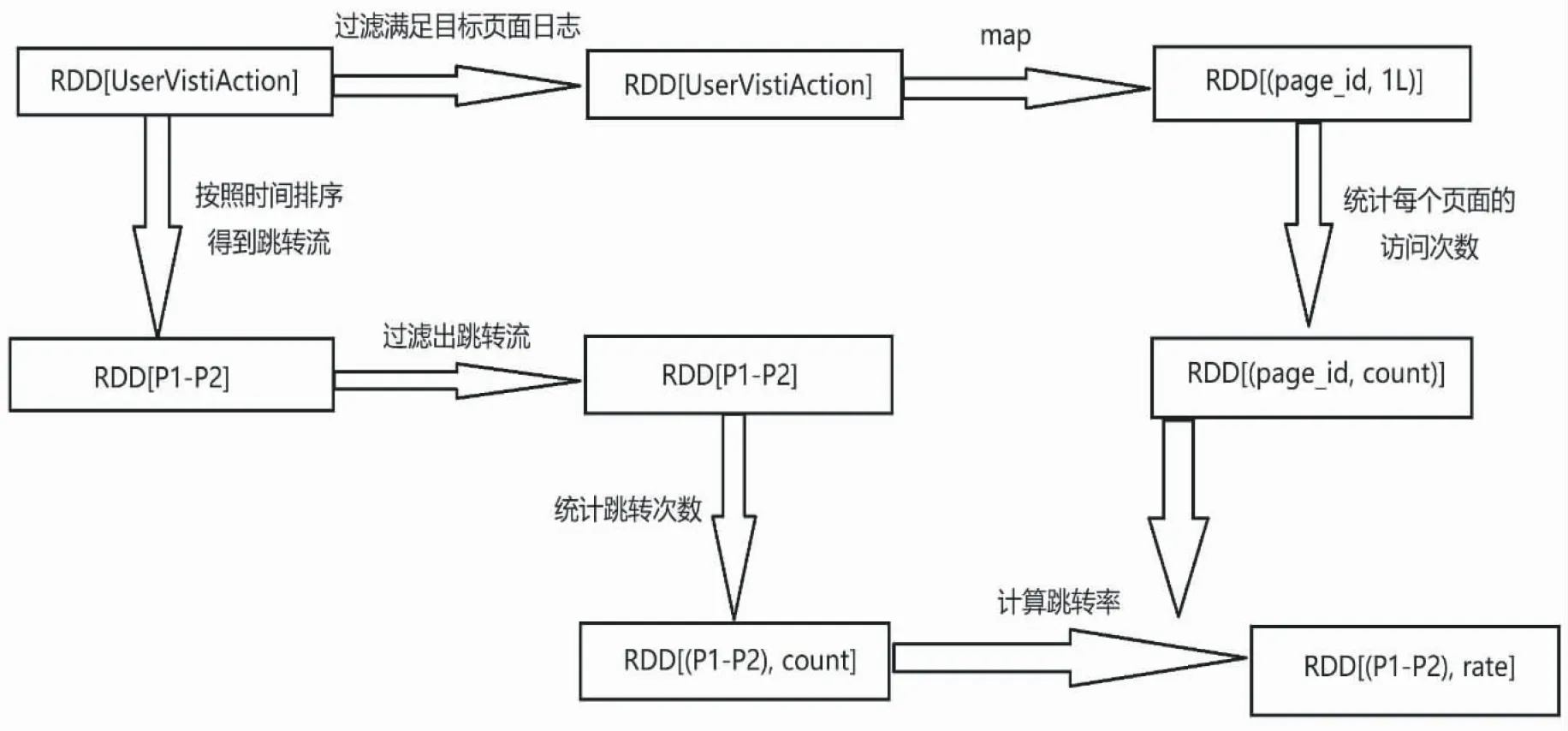
图9 实验流程图
2.2.2 实验结果
实验数据中共有49个页面,页面id由1到49,本文实验结果选取id从1到20的页面转化率进行展示.实验结果如图10所示,每一行数据由单跳跳转路径和单跳转化率构成.
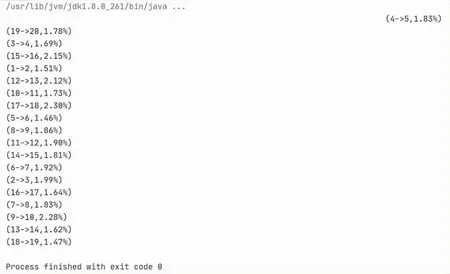
图10 页面单跳转化率实验结果图
2.3 基于Spark的电商热门品类中Top10活跃Session统计实验
品类是指产品的分类,部分电商品类可分为多级,此实验中品类为一级,实验按照每个品类的点击、下单、支付的数量来统计出各个品类的数量,并选出数量排名前10的品类作为热门品类.对于排名前10的品类,分别获取每个品类点击次数排名前10的SessionId,这个功能可以看到,某个用户群体最感兴趣的品类以及各个品类中最典型的用户的Session的行为.
2.3.1 实验分析
实验数据仍使用电商的用户行为数据.
实验过程首先分别统计每个品类点击的次数、下单的次数和支付的次数,通过遍历全部日志数据,根据品类id和操作类型分别累加各个品类的数量,遍历完成之后就得到了每个品类id和操作类型的数量,按照点击下单支付的顺序来排序,得到Top10热门品类.过程如图11所示.

图11 Top10热门品类实验过程图
过滤出热门品类Top10的日志,将热门品类Top10的数据类型转换为RDD[(categoryId,sessionId),1],并统计数量,将数据类型转换为RDD[(categoryId,sessionId),count],统计出每个品类中Session的数量,接下来对每个品类中的Session数量进行排序,并取出前10.实验过程如图12所示.

图12 Top10活跃Session实验流程图
2.3.2 实验结果
Top10热门品类实验结果图如图13所示,结果图中10个结果为Top10热门品类,每一行由品类id、点击量、下单量、支付量组成包装类,再按照点击量的顺序降序来排序.
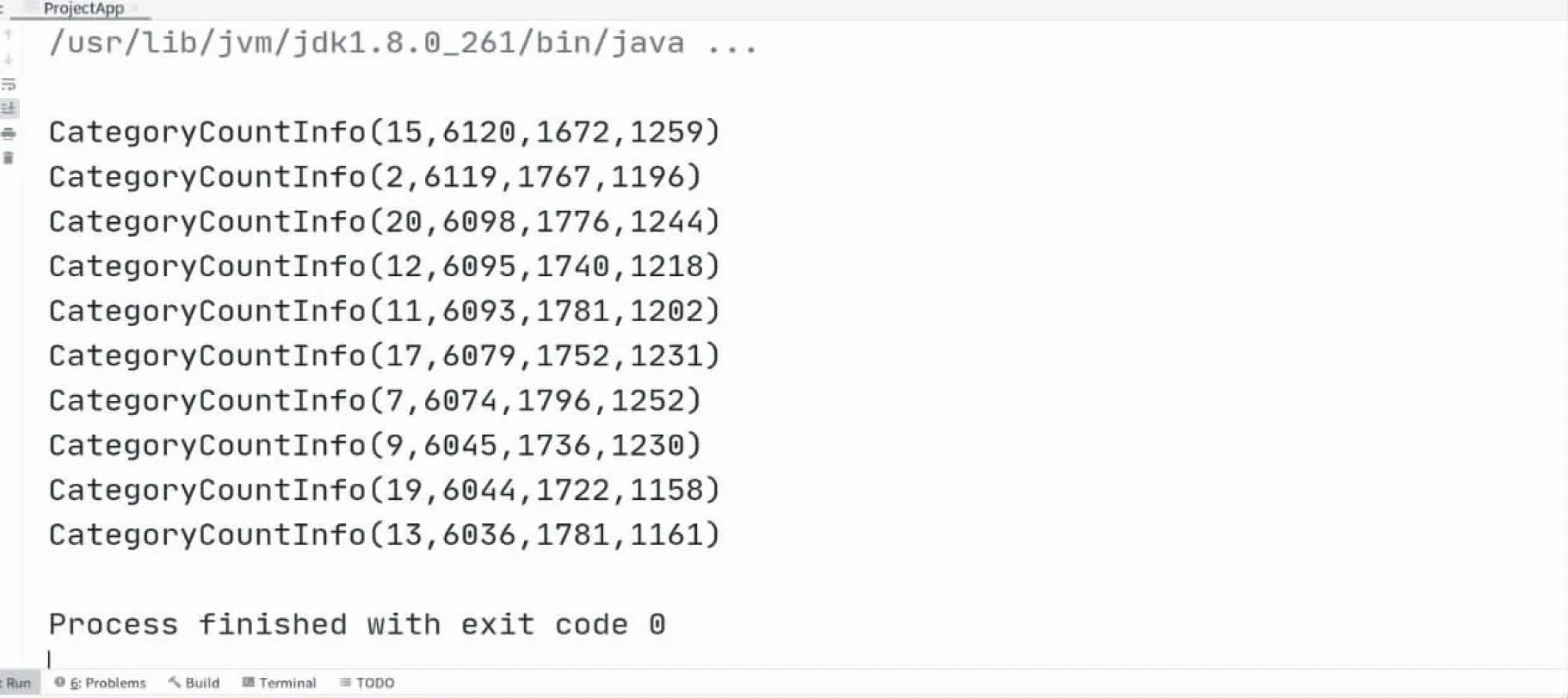
图13 Top10热门品类实验结果图
Top10活跃Session实验结果图如图14所示,每一行数据由Top10热门品类的品类ID和一个List组成,List中包含10个SessionInfo包装类,包装类中包含点击数最高的SessionId和点击数,并根据SessionInfo中的点击数降序排序.
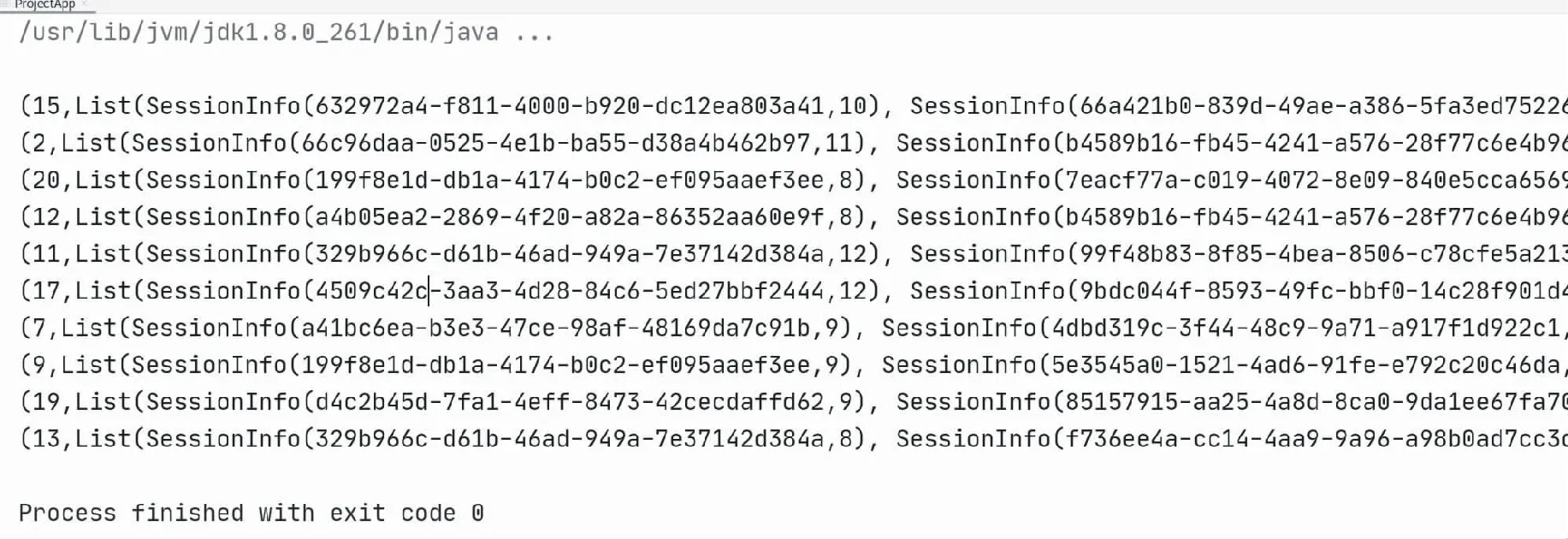
图14 Top10活跃Session实验结果图
3 结 语
Spark不仅含有Hadoop平台下MapReduce框架所具备的优点,也很好地解决了MapReduce中存在的一些问题,同时在功能上为更好的适应现代大数据环境做了延伸和扩展,使其在操作更简洁方便的前提下执行速度提高了近百倍.其中,RDD是作为Spark技术中数据操作的基本单位.本文主要论述了RDD的属性、RDD之间的依赖、常见的转换关系、操作类型、弹性特性和运行原理,创建RDD的几种常见的方式以及电商用户页面单跳转化率统计实验和电商热门品类中Top10活跃Session统计实验实现.Spark不仅可以支持Scala、Java、Python等多种语言编程,还支持DataFrame、DataSet等多种数据类型,而且提供了一个完整而强大的生态系统,其中有SQL查询、流式计算、机器学习和图计算组件,这些组件可以应用在一个程序中,完成更加复杂的需求.在现代大数据环境下,为了更好解决实际生活中的复杂问题,充分理解并掌握RDD的运行可以让Spark的运行节省大量的数据处理时间,从而有效地优化数据处理过程,提高整个过程的效率.
