基于PyECharts的爬虫数据可视化研究
2023-08-21李晨昊王剑雄李宗阳
李晨昊 王剑雄 党 然 李宗阳 施 陶
(1.河北建筑工程学院,河北 张家口 075000;2.衡水第三中学,河北 衡水 053099)
0 引 言
处于信息时代,每天都会有各种各样的信息出现,此时快速有效地获取信息对相应工作研究起到了关键的作用.计算机技术的快速发展,人类社会全面受益,小到日常娱乐与生活,大到生存模式与环境得到根本性的改善.对于互联网上众多繁杂的信息,使用网络爬虫可以快速有效地获取这些信息,爬虫最常使用到的语言就是Python语言,Python语言以其简洁的代码和强大的库函数,使得编写爬虫脚本时效率有了很大的提高.本文介绍了一种从相关网站进行爬取疫情信息的方法,并对数据进行可视化的处理与展示,使获取的数据更加直观.
1 相关技术简介
Python语言简介:Python是跨平台、解释型的动态语言,由于它的语法清晰简便并且包含了丰富的标准库以及第三方库,经常被运用到网络爬虫、数据分析、人工智能、Web开发等领域.本文运用了该语言进行网页数据爬取和转化成可视化界面.该语言代码简洁方便阅读,具有很高的代码开发效率.国内外众多企业都用到了Python作为开发语言,如Google公司、国内的知乎、豆瓣等公司都运用了Python技术.
网络爬虫简介:基于Python的网络爬虫技术,首先模拟真实用户向服务器请求页面信息,服务器进行响应,返回请求后的信息结果,获取到服务器响应的页面结果,对该页面进行解析,获取标签信息,根据所需信息对该标签进行筛选操作,然后返回标签体中的内容信息.或者是请求域名解析,返回域名的IP,向IP库API发送请求,返回运营商归属,重复进行以上步骤,进行反复循环的爬取,这样实现自动化的Web爬虫抓取数据,最后对获取到的数据信息进行存储,以供接下来的一个研究和探讨.
PyECharts简介:ECharts(Enterprise Charts)是百度的一个开源数据可视化工具,它是一个使用JavaScript实现的开源可视化库.而PyECharts是一款将Python和ECharts进行结合的一款工具,使用Python调用其API接口就可以生成可视化的图形,成为Python语言编写的程序可以进一步可视化的一个强大工具.
2 网页的基本结构以及网页源代码分析
使用爬虫技术爬取网站的信息,首先要了解被爬取网页的结构,网页的结构简单的分为HTML(超文本标记语言)、CSS、JavaScript.CSS负责页面的结构样式,JS负责页面的交互功能.本文主要针对静态内容进行抓取,即抓取HTML中相应标签中的内容.
本文采用的是谷歌浏览器(Chrome)工具对网站的源代码进行分析,进入到相应的网页,在网页的空白处点击鼠标右键选择检查进行查看,通过对代码进行分析,编写相应的程序,以及相应的URL地址.
3 Python下爬取网站的设计
本文是对腾讯新闻网站疫情实时追踪板块的数据进行爬取.主要使用到了requests、json、pyecharts等库.使用requests库模拟真实用户向服务器发送请求,并且获取到相应的返回信息,json对网页进行解码操作,将网页的json格式解码成为Python格式的data对返回信息进行相应抽取.将抽取到的数据传入到pyecharts库相应的对象中,进行可视化的操作.
被爬取网站的地址为:url='https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5',headers,编写user-agent属性,模拟真实电脑访问url='Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/87.0.4280.88 Safari/537.36’.该属性可以以通过谷歌浏览器F12进行查看本机.通过定义访问网页函数get_url(url,headers),对网页进行访问.随后把得到的数据用Json打开,json.loads()函数解析该数据,并且得到Json里面的“data”数据.具体实现代码如图1所示.

图1 获取“data”数据
循环遍历“data”获取相应的数据,将地址“name”以及相匹配的属性,循环存储的相应的列表中.具体部分实现代码如图2所示.

图2 列表存储数据信息
本文使用Chrome浏览器抓包分析了获取得病人数及相关地区的数据,通过查看网站https://news.qq.com/zt2020/page/feiyan.htm#/的源代码,找到需要爬取数据的相对应的url地址.谷歌浏览器在疫情网页F12进入到检查界面,选择到Network,此时F5刷新网页,即可获得网页服务器反馈的信息.可以看到开发者工具中出现了各种各样的包,本文所需要的数据只需要获取到JS数据包即可,所以需要进行过滤,经过筛选在左侧的信息中找到相应的“Name”,打开此包Headers中的Request URL,即可得到数据的url地址.如图3所示,这是所需信息数据相对应的url地址.
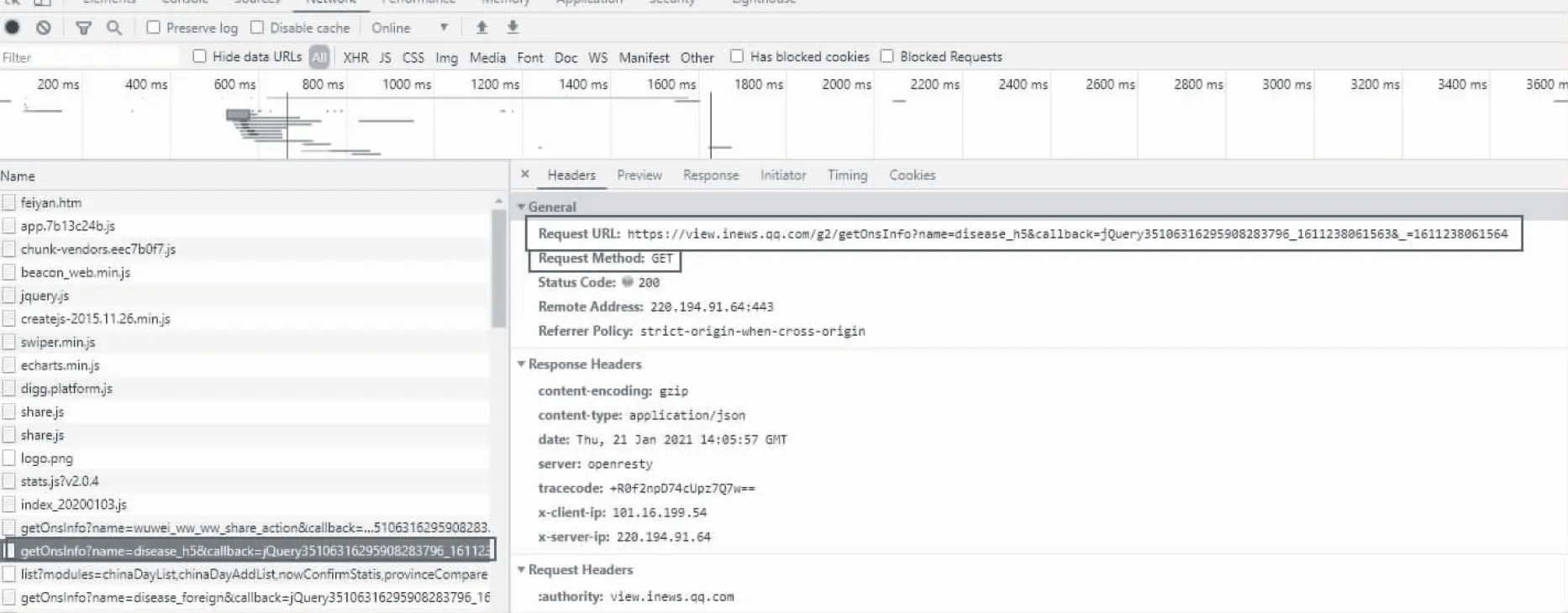
图3 相应的url地址
通过Console查找到此文件对应的路径,可看到相对应的信息,这里面正是我们需要爬取的信息,和上面所获取的url地址对应的信息相对应.详细信息如图4所示.
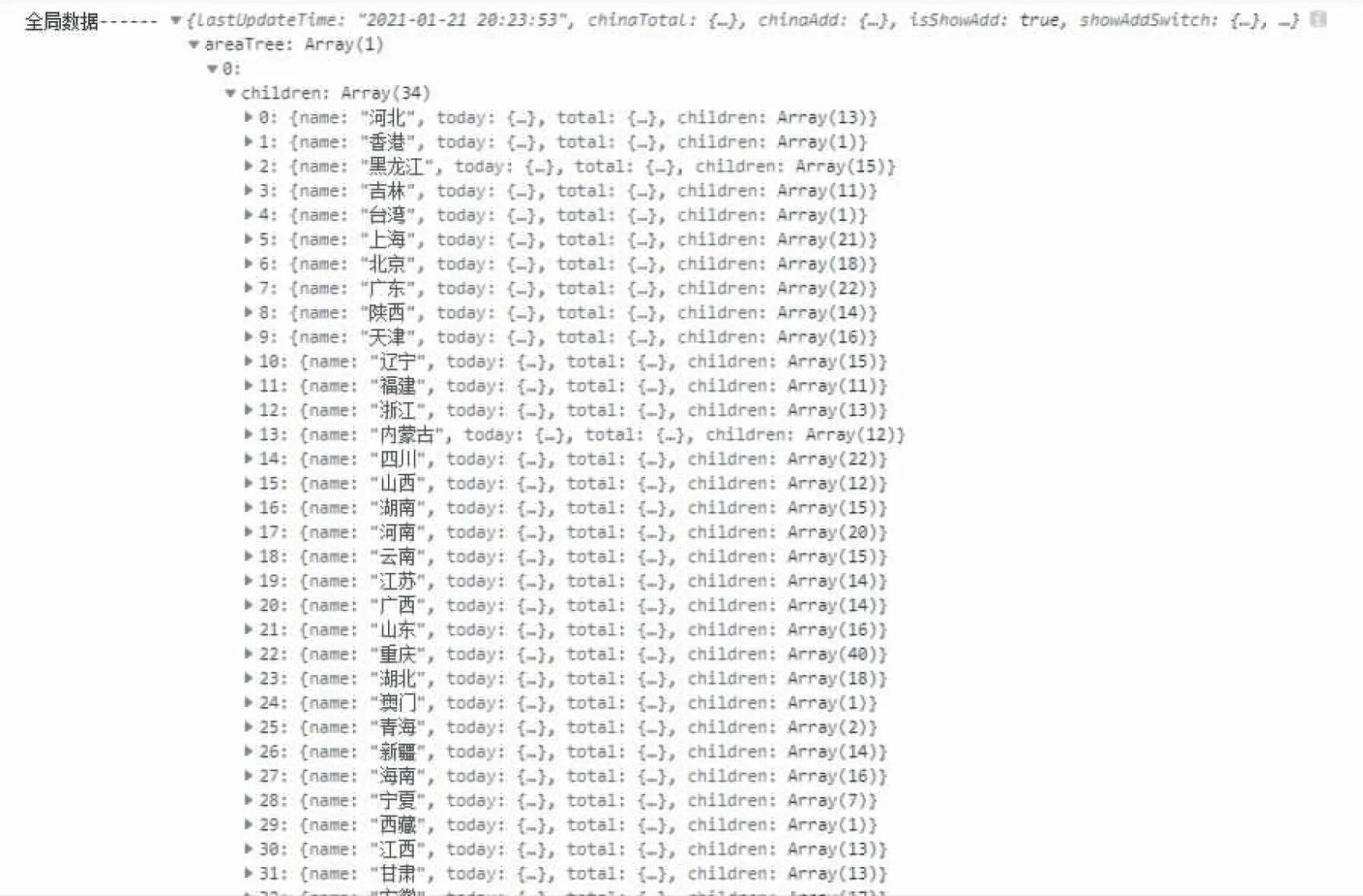
图4 网页Console信息
打开这个url地址,显示出相对应的数据的信息界面,如图5所示,这就是需要获取的病例人数及地区的数据,通过JSON数据呈现,并且当前主流的网站都采用这样的模式进行开发.页面的结构信息如图6所示.接下来就分析包中数据的参数,“name”表示的是地区以及“确诊”、“疑似”、“死亡”的信息,“grade”表示的是风险等级,那么只要获取到相应的数据即可.

图5 网页请求情况

图6 url网页结构
4 爬取到数据的展示
通过调用可视化工具PyECharts相应的API接口,创建Geo( )对象,设置图像的高、宽的像素大小,分别对四种信息,以及相应省份信息的数据进行传入,最后生成网页,geo.set_global_opts()函数设置html网页的展示效果、背景颜色、网页中的文字信息等展示内容.c.render(path=r'ncov-2019.html')生成html文件.将上述数据可视化的进行展示,部分详细代码如图7所示.

图7 可视化工具生成界面
可视化界面如图8所示.界面可展现出“确诊人数”、“疑似人数”、“死亡人数”、“治愈人数”通过不同的颜色相应的在中国版图上进行展示,会根据人数的数量呈现出一个颜色的渐变.左上角展示出该信息更新的时间,供使用者得知该数据的一个时效性.
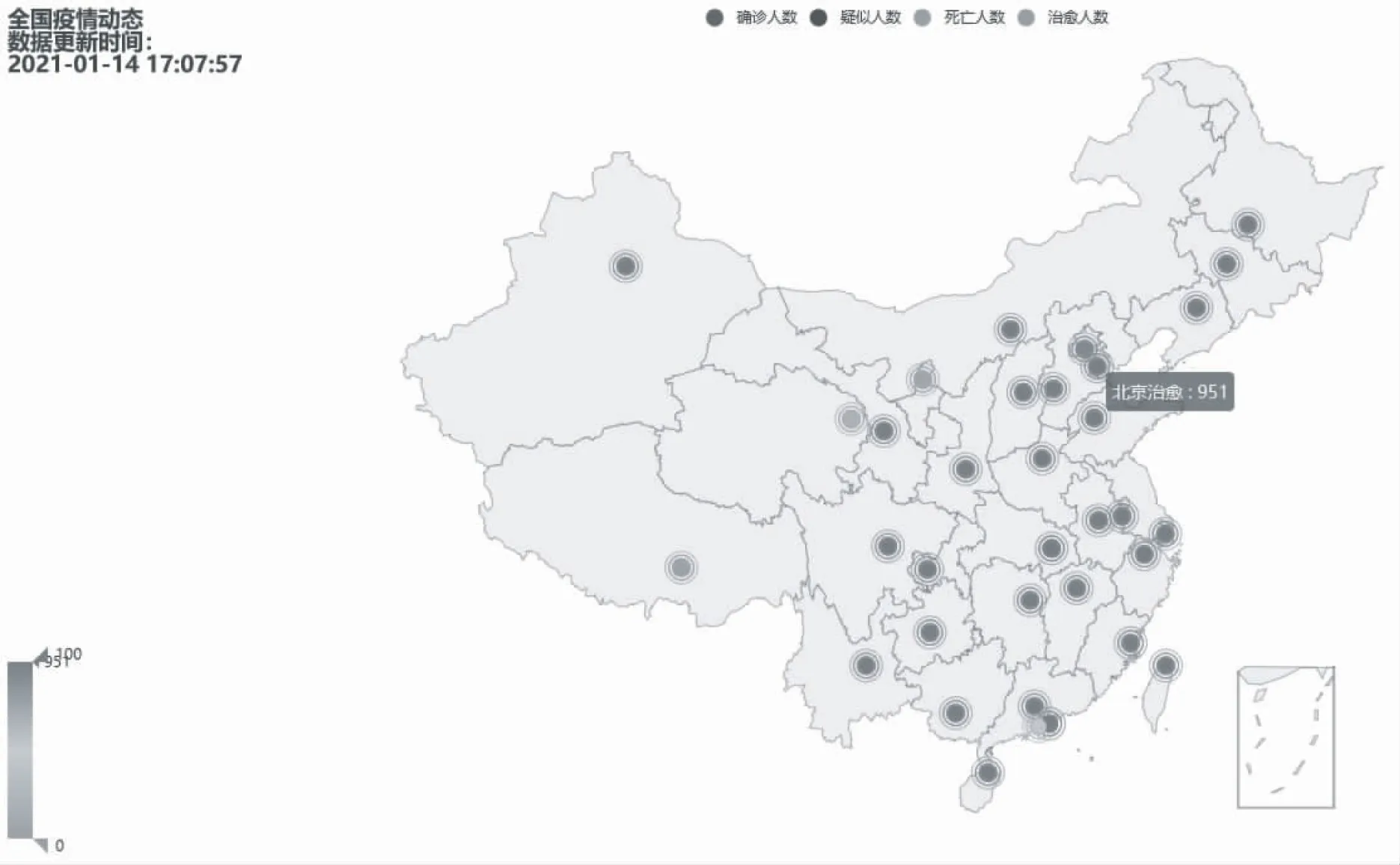
图8 可视化地图展示界面
5 结 论
通过对本文的算法进行研究与分析,实现了腾讯新闻网疫情数据的爬取与采集设计,使用Chrome进行了抓包分析,对动态页面关键数据进行抓取,借助了PyCharm工具进行了源代码的编写,通过使用PyECharts,以地图的形式直观地展示了当前的数据.通过本文的研究与设计,对时下万众关注的疫情信息,能够及时抽取各种碎片化的数据,并进行整理与直观的图形化显示,对整个疫情状态进行了很好的展示,为后续抗疫的规划与分析奠定了基础.本研究设计的优点是开发周期短、代码简洁、易于后期维护.在后续的研究中,可以进一步凝练爬虫算法的性能,以便提高数据爬虫的准确性与缩短爬虫的时间,同时增加更多的功能模块,如各种需求的可视化展示.针对当前疫情肆虐的形势,本文所研究的内容有较高的实用性和时效性.
