基于BIRCH 算法的配电网设备多源数据融合存储技术研究
2023-08-19姜英涵
张 军,陈 霄,何 育,张 旺,姜英涵
(1.国网江苏省电力有限公司,江苏 南京 210000;2.国网江苏省电力有限公司经济技术研究院,江苏 南京 210000;3.国网经济技术研究院有限公司,北京 100000)
近几年,全球不可再生能源含量加速减少,加之工业、贸易等多个行业的迅速崛起,导致对电能的需求逐渐攀升[1-2]。为满足电能需求,我国不断扩大电网建设规模。而对于电网而言,配电网是关键部分之一,其能够起到输电网与用户之间的“桥梁”作用。配电网在输电网接收电能,通过配电设备将电能合理分配至用户,其由架空线路、杆塔、电缆、配电电压器、无功补偿器、隔离开关及附属设施等构成,在电网中承担着分配电能的关键功效。
配电网设备在长期运行过程中会受到电、热、负荷与自然环境等因素的影响,导致设备出现磨损、腐蚀及老化等现象,进而致使设备性能与可靠性下降。此外,长期在高温度与高电压的环境下工作,配电网设备绝缘材料性能也会随之出现一定程度的变化,导致绝缘性能下降甚至消失。为了保障配电网的顺利运行,国内外相关学者对配电网设备数据存储模型做了研究,并取得了一定的研究成果。文献[3]提出一种多机构分布式数据存储网络设计,其将相同存储节点的数据集合至一个简单的网络模型中,并融合多机构分布式数据存储网络,设计该模型的代码框架,以此得到配电网设备数据存储模型。文献[4]提出配电网剩余供电能力实用模型,通过RSC(Residual Supply Capacity)模型改进配电网供电数据模型,并考虑网络重构,进而提出适用于分段开关的剩余供电能力模型。
上述方法能够及时对设备运行状态进行了解,力争最快速度地维修或更换配电网设备,避免安全事故的发生。但随着配电网规模的扩大及设备复杂程度的提升,配电网设备数据呈现海量化特性,这就对配电网设备数据存储提出了更高的要求。智能配电网环境下,设备运行数据量剧增,远超出传统配电网设备数据存储模型的范畴,为此该文提出了一种新的配电网设备数据存储模型。对电网设备数据进行预处理,并引入CMCH(Copies Multiple Consistent Hashing)算法对配电网设备多源数据进行并行关联处理,实现同类型数据的归类融合;再通过BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)算法计算各配电网设备并行关联数据库的质心;且利用证据理论完成各数据库代表性信息的组合,从而实现配电网设备多源数据的融合。同时通过Hadoop 分布式平台构建配电网设备数据存储模型的整体架构,并利用Hbase 数据管理实现电网数据的关联融合、管理与查询。通过海量信息处理降低配电网设备数据存储的压力,以满足现今智能配电网设备数据的存储需求,且保障配电网及电力系统正常、稳定及可靠地运行,进而为用户提供更加优质的电能供给。
1 配电网设备数据存储模型
构建配电网设备数据存储模型,首先需要搭建配电网设备数据存储架构。基于Hadoop 分布式平台及Hbase 数据处理方案对设备数据进行有效的管理;针对设备多源数据,先利用CMCH 算法过滤无用信息,再通过设置组建和标记对多源数据进行关联输出,并对多源数据进行融合处理,以此提升配电网设备海量数据的存储性能。
1.1 配电网设备数据存储架构搭建
为满足现今智能配电网设备数据存储需求,基于Hadoop 分布式平台搭建配电网设备数据存储模型架构,如图1 所示。

图1 配电网设备数据存储模型架构
由图可知,配电网设备数据存储模型架构中,利用可扩展采集模块获取配电网设备数据,并将全部数据上传至Hadoop 云计算模块;再利用Hbase 对设备数据进行有效管理与查询;同时,通过数据分析与存储模块对设备数据进行预处理、并行关联及融合;最终,对设备数据进行分布式存储。
1.2 配电网设备海量数据处理
依据上述搭建的配电网设备数据存储模型架构,获取配电网设备海量数据[5]。设备数据获取过程中,受电力干扰、恶劣环境、设备自身脆弱性等多种因素的影响,设备数据中存在海量的干扰、重复数据等。因此,为降低设备数据存储压力,需对配电网设备海量数据加以处理。
1.2.1 配电网设备多源数据并行关联
配电网设备数据包含设备标识、数据采集时间、环境微气象数据等,为方便设备数据的存储与读取,对设备多源数据实现并行关联,构建关系数据库[6]。
基于CMCH 算法并行关联配电网设备多源数据,具体流程如图2 所示。
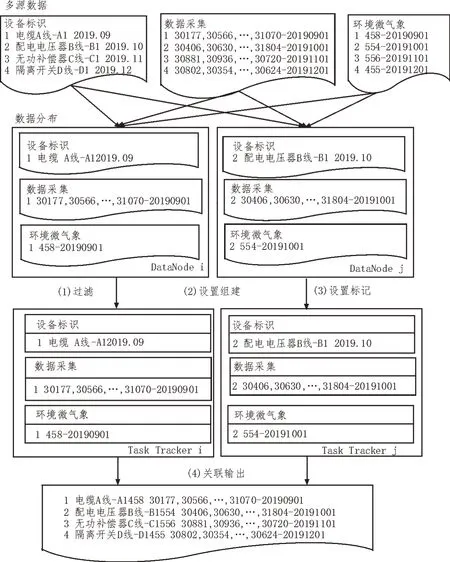
图2 并行关联设备多源数据流程
依据图2 所示流程,以电缆、配电电压器、无功补偿器与隔离开关等设备为例,展示配电网设备海量数据并行关联流程[7]。配电网设备并行关联数据库主要包含设备标识文件表、数据采集时间文件表与环境微气象数据文件表三部分,具体如表1-3所示。

表1 设备标识文件表
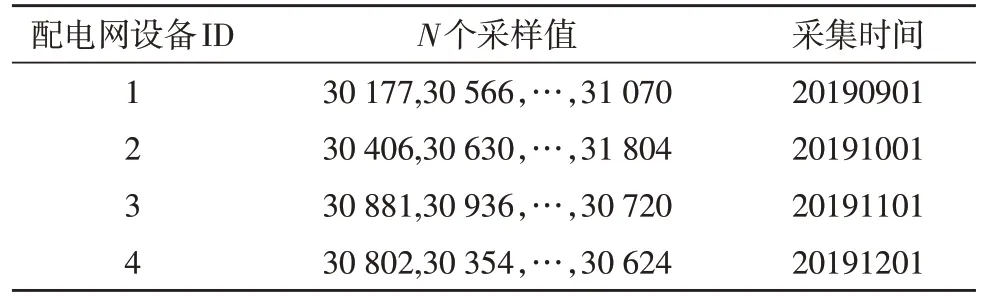
表2 数据采集时间文件表

表3 环境微气象数据文件表
将上述3 个文件表数据进行并行关联,以降低设备数据存储的文件数量,获得设备数据并行关联结果如表4 所示。
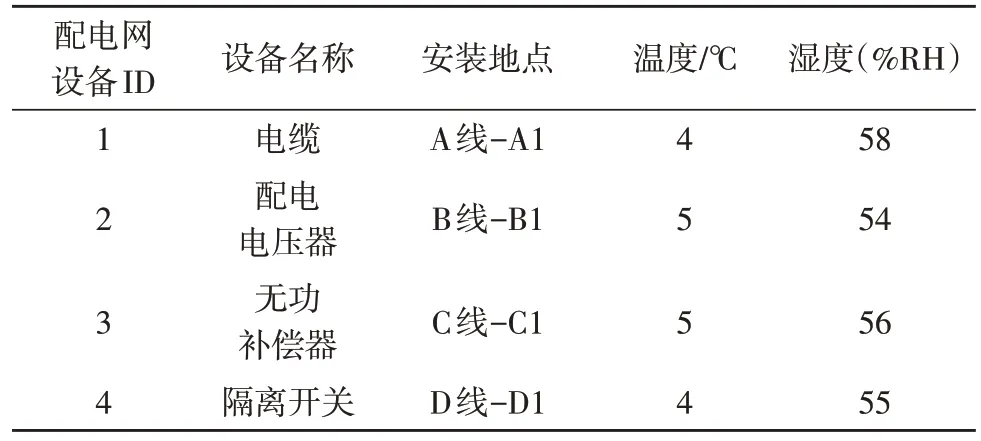
表4 设备数据并行关联结果
1.2.2 配电网设备多源数据融合
根据上述配电网设备多源数据并行关联结果,利用BIRCH 算法对设备多源数据进行融合处理。BIRCH 算法计算出各配电网设备并行关联数据库的质心。并以此为代表,利用模糊隶属度函数对融合目标涉及的质心信息与属性的基本概率进行赋值,形成各数据库的代表性信息[8]。最后,利用证据理论完成各数据库代表性信息的组合,实现配电网设备多源数据的融合[9]。基于BIRCH 算法的配电网设备多源数据融合主要步骤如下。
步骤1:依据采集配电网设备多源数据的特征[10],确定融合目标涉及全部属性,记为A1,A2,…,An;
步骤2:依据步骤1 确定的融合目标属性A1,A2,…,An,结合配电网设备多源数据规模及特征来确定BIRCH 算法的分支因子B与阈值T,并设置分支因子与阈值初始值分别为B=10 与T=1;
步骤3:加载上节生成的配电网设备并行关联数据库,将其记为C1,C2,…,Cr;
步骤4:计算配电网设备并行关联数据库C1,C2,…,Cr的质心信息,记为Q1,Q2,…,Qr;
步骤5:根据实际配电网设备数据存储需求[11-12],明确辨识框架为Θ:{H1,H2,…,Hk} ;
步骤6:构建模糊模型标记,依据Θ:{H1,H2,…,Hk}的样本数据,针对样本数据的某个属性Ai,确定该属性下的最小值、最大值及平均值,并以此为基础构建一个三角形模糊数[13],描述命题Hj,其所对应的隶属函数为,i=1,2,…,n;j=1,2,…,k。
步骤7:针对属性Ai,计算每个配电网设备并行关联数据库的平均方差,以此为基础,将实际采集设备数据扩展为能够表示的三角模糊数,从而获取观测函数,记为gAi(x);
步骤8:计算采集设备数据与模糊模型标记间的似然度,即观测函数gAi(x)与模糊模型标记曲线相交部分纵坐标最大值,记为
步骤10:针对步骤4 得到的质心信息,基于选定的属性A1,A2,…,An,重复步骤6-9,生成每个质心信息所对应的n条证据;
步骤11:依据证据理论组合公式,并融合步骤10 获得的n条证据,构成反映配电网设备并行关联数据库Ci对融合目标支持程度的合成证据cmj(Hj);
步骤12:计算cmj(Hj)的权重数值,计算公式为:
步骤13:依据证据理论组合公式与权重数据,融合处理步骤11 合成证据cmj(Hj),获取最终配电网设备多源数据融合结果。
对基于BIRCH 算法的配电网设备多源数据融合方法进行算法计算代价分析,算法时间复杂度O(n)的计算公式为:
式中,ni为算法迭代总次数,为每次迭代中基本操作执行次数。由此得到算法计算代价分析,如图3 所示。
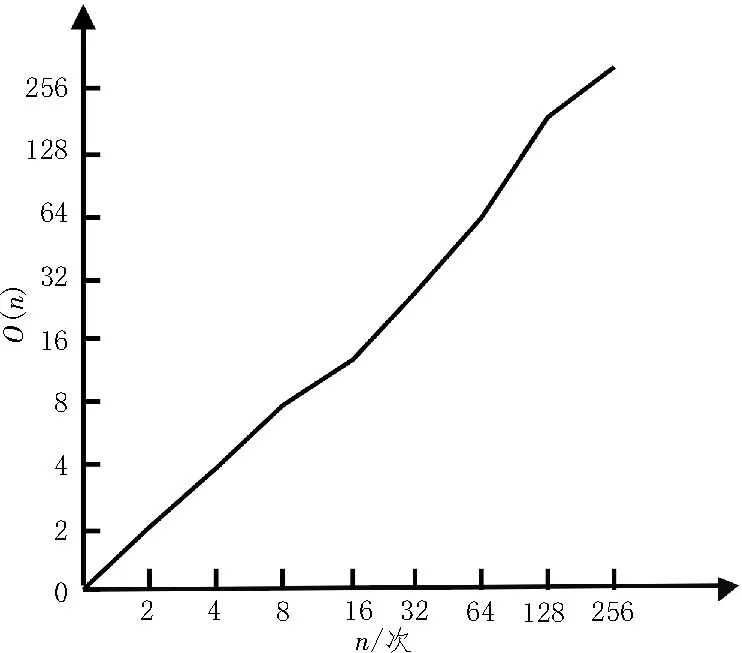
图3 算法计算代价分析
由图可知,随着迭代次数的增加,时间复杂度数值增长的趋势也逐步变大。这表明算法基本操作所执行的次数较多,可行性较好。
1.3 配电网设备数据存储
以上述获取配电网设备海量数据处理结果为基础,在Hadoop 分布式平台上采用一致性哈希算法(consistent Hashing)来存储配电网设备数据,并实现其数据存储模型的运行。
一致性哈希算法的基本思想为:依据数据关联性,应用该算法将关联数据映射并存储在相同节点上,进而实现设备数据的存储[14]。此种设备数据存储模型在数据查询时,极大地减少了Map 节点与Reduce 节点间的通信开销,从而提升了模型的整体存储性能。
基于一致性哈希算法[15]的配电网设备数据存储流程描述如下:
步骤1:加载配电网设备海量数据融合结果,通过配置文件定义数据副本数量;
步骤2:计算Hadoop 分布式平台各个数据节点的哈希值,并依据规则将其配置到一个0~232的哈希环区间上,再应用MD5 散列算法(Message Digest Algorithm 5)形成128 bit 散列值,并选取其中的32 bit作为哈希值;
步骤3:依据配电网设备数据采集时间属性、关联数据属性计算设备数据的哈希值,并将其依次映射到哈希环上;
步骤4:依据步骤2-3 获取的数据节点及数据哈希值确定设备数据的存储位置,并按照逆时针方向将设备数据映射至最小距离的数据节点上;
步骤5:若设备数据存储节点出现失效或异常等现象,此时需将失效或异常数据节点上的设备数据进行重新映射与分布,直至设备数据全部存储结束。
基于上述过程,构建配电网设备数据存储模型,如图4 所示。

图4 配电网设备数据存储模型
通过上述过程实现了配电网设备数据存储模型的运行,为配电网设备故障预防提供了精准的数据支撑,且保证了配电网稳定运行[16]。
2 实验结果与分析
为证实构建模型与传统模型的性能差异,采用Matlab 软件设计仿真对比实验,具体实验过程如下。
2.1 Hadoop分布式平台搭建
仿真实验Hadoop 分布式平台包含一个主控节点,19 个数据节点,共计20 个节点的集群。其中,主控节点与数据节点配置相同,具体配置数据如表5所示。

表5 主控节点与数据节点配置表
依据表5 数据搭建Hadoop 分布式平台,示意图如图5 所示。

图5 Hadoop分布式平台示意图
2.2 实验数据集准备
为验证构建模型的存储性能,选取了不同大小的实验数据集,其规格如表6 所示。

表6 实验数据集
如表4 所示,csv 表示的是文本格式文件;dat 表示的是二进制文件。
2.3 数据分析
依据上述所搭建的Hadoop 分布式平台,选取实验数据集并进行仿真对比实验。通过数据上传速率与数据压缩比来反映模型性能,实验结果分析过程如下[17]。
2.3.1 数据上传速率分析
通过仿真实验获取数据的上传速率,如表7所示。

表7 数据上传速率数据表
从表7 中可以看出,构建模型数据上传速率范围为3 011~3 498 kB/s,传统模型数据上传速率范围为2 413~3 012 kB/s。通过对比发现,构建模型的数据上传速率远高于传统模型。
2.3.2 数据压缩比分析
通过仿真实验获取压缩比数据,如表8 所示。

表8 数据压缩比数据表
如表8 中数据显示,构建模型数据压缩比范围为4.258~4.784,传统模型数据压缩比范围为3.010~3.945。通过对比发现,构建模型的数据压缩比远高于传统模型。上述实验结果表明,与传统模型相比,该文构建模型的数据上传速率较高、数据压缩比更大,验证了该模型设备数据存储性能更优。
2.4 实例验证
选取某省市内8家供电公司管辖的配电网,来对基于海量信息处理的配电网设备数据存储模型进行实证研究。统计选取2019年10-12月8家供电公司的电力数据共1 000 MB,包括正常运行信息500 MB、停电检修信息300 MB 及装置故障信息200 MB,对1 000 MB 电力数据进行分类整理,得到数据存储结果如表9 所示[18]。

表9 数据存储结果
分析表9 可知,采用所构建的模型对电力数据的分类结果与实际数据一致,而传统模型的数据分类结果与实际值差别较大。通过实证分析可知,所设计模型的数据分类存储效果较好,能够实现配电网设备数据的准确存储。
3 结束语
为提升智能配电网设备数据的存储效率及安全性,此研究构建配电网设备数据存储模型,并将海量信息处理引入至该存储模型中,实现数据的安全存储。实验结果表明,应用所设计的模型后,极大地提升了模型的数据上传速率与数据压缩比,节省了海量的存储空间,并有效提升了电网数据的存储性能,从而为配电网设备数据存储提供了新的手段支撑。
