基于RBF 神经网络的电力信息网络安全态势辨识研究
2023-08-19覃岩岩郭舒扬方雪琴
覃岩岩,郭舒扬,方雪琴
(1.海南电网有限责任公司信息通信分公司,海南 海口 570000;2.南方电网海南数字电网研究院有限公司,海南 海口 570000)
电力信息网络数量庞大,如果受到攻击则会对网络造成影响,因此,研究网络安全态势感知技术尤为重要。电力信息网络安全态势辨识赋予了网络实时监测、电力信息保密、网络威胁决策等多个使命,实现了网络的共享化与智能化、网络与现实的融合。
目前,相关领域学者对其进行了研究,文献[1]通过蜂群算法优化神经网络,实现了电力信息网络安全态势辨识。文献[2]预先构建评估指标体系,采用灰色关联分析法对指标的权重进行了计算,实现网络安全态势的评估。上述方法虽然能够有效实现电力信息系统网络安全态势辨识,但辨识误差较大、时间较长。针对上述问题,研究了基于RBF 神经网络的电力信息网络安全态势辨识方法。
1 RBF神经网络模型构建
RBF 神经网络的结构一般由一个基础层与两个高级层构成,三者相辅相成共同作用,才能保证神经网络的正常运行。而其中起到主导作用的是隐藏层[3],该层不仅可以对数据进行分析研究,还能够对不完整数据进行优化。通过建立函数的方式,确定安全态势的辨识研究,其函数可表示为f(x)=e-t2,其中,e表示神经网络权重,t表示指数,而这几个层面具体表现为:
基础层:主要是由大量的神经节点构成,数量由R表示,而初始输入的支持向量为C;
隐藏层:其中的节点数量是受到限制的[4],通常为S个,在函数的约束下循环迭代计算,直到样本达到第i个为止,而获得的输出数据为qi=(ci-C)bi,式中,ci代表特征节点的长度,bi代表节点的宽度;
终端层:最后的终端层中含有的神经元为K个,当移动的数据到达该节点时,就可以得到的公式为:,其中,wk代表经过函数计算过的对称节点,dk为神经元网络处理后得到的节点峰值。
RBF 神经网络的辨识方式主要是建造一个多维空间,利用空间的映射性,从而获取电力系统中未被识别的保密信息,最后输出的结果即映射数据。
2 RBF神经网络模型预训练
当前网络的运行状态是辨识电力信息的前提,通过建立一个基础的辨识系统来推测出神经网络的模型,根据系统的指示来进行计算,而决定模型的主要条件就是神经节点的自身控制与聚类[5]。文中基于这一特征,提出了一种新的聚类控制方法,不但能够准确地限制节点的经过[6],还能实时调整节点与数据之间的平衡性,具体步骤如下:
第一步:假设输入的数据集合为X=(x1,x2,…,xN),与节点共同的序列集合为A(L),存在一个存储器B(L),其中,L代表所有安全态势样本的种类,可以将节点与数据保存起来。
第二步:抛开初始的安全态势样本,之后的每一个输入的样本都可以作为聚类中心,计算得出样本的排列顺序后A就可以在其中选取最佳的样本xi,然后在A(1)=xi与B(1)=xi的条件下,确定公式:
其中,d1代表以样本为中心的圆形直径,N代表数量,xi与xj代表数据样本。
第三步:将不符合条件的采样点[7]统一划分到一个类别,然后根据自身到聚类中心的距离使A(1)=A(1)+xi,B(1)=B(1)+1,若r>d2,r代表半径,就视为分类失败,不用理会。
第四步:将上述经过处理后的安全态势样本作为一个独立的个体,循环往复地执行以上三步,直到使B(L)<M,其中,M代表储存器的阈值[8-9],对剩余的样本进行统一,为L个。
第五步:最后利用聚类中心来获取传输的数据信息,则公式为:
式中,ci代表特征节点的长度,A(i)代表种类,B(i)代表容器的体积,此时,聚类已经完成。
3 隐含层节点数优化
RBF 神经网络在对隐藏的数据进行挖掘时会产生很多其他的数据垃圾,包括不必要的节点集合,因此为了实现模型优化问题[10],可以利用计算,避免影响操作的数据出现,步骤如下:
1)基于节点的层层递增,多余的节点会不断变多,可用公式表示为:
其中,h代表层数。
RBF 神经网络的处理中心就是其中的隐藏层[11],假设支持向量机为n,那么第i层获得的节点集合为:
式中,gi(X,ci)是神经网络函数,一般可以转化为高级函数,即:
其中,σi代表隐藏层的面积。
而经过叠加计算后的聚合公式为:
其中,wij代表相邻神经元之间的聚合加权值,j为层数。经过神经网络的加权后[12],模型得到的节点为:
其中,wo代表初始样本权值,k代表排列序号,L代表数量。那么得到的时间序列公式为:
假设两组样本用(x1,y1)和(x2,y2)表示,二者在隐含层之间的关系为:
式中,μ代表向量,且范围在(0,1)之间,σ1代表初始隐含层,δmax代表节点到聚类中心的最大距离。而不可避免出现的误差[13]公式为:
其中,T(k) 代表理想节点输出,ε代表理想参数,δi=max{γδmax,δmin},γ∈(0,1),γ代表常数。当误差与初始节点最小时,就可以看作已经形成了固定的隐含层模式,且可随意设置输出向量,则有:
而剩余没用的节点就可以按照其重要程度进行处理,首先获得剩余节点的隐含层位置[14],然后找出网络中安全态势最大的数据中心,统一对节点进行处理,公式为:
最后,经过多次迭代计算,在阈值的范围内使节点的数量最少,直到可以忽略不计为止。
假设经过训练后的时间序列为x1,x2,x3,…,xN,输入到神经网络后得到的安全态势聚类矩阵为:
其中,e代表序列在空间中的维度,而样本中携带的误差会根据计算的叠加处于不断减少当中,就可以在一定程度上节省时间,那么决定误差的参数公式为:
式中,λ代表误差参数,利用样本的加权值来对隐藏节点进行优化,公式为:
其中,W代表平均权值,η代表误差出现的概率,realj代表实际输出的样本。
基于上述过程对RBF 神经网络优化处理,为网络安全态势辨识提供基础。
4 网络安全态势辨识实现
网络安全态势的辨识是在隐藏节点挖掘与网络数据分类之后进行的,其数据来源都是截取一个时间段的所有态势数据,然后输入到RBF 神经网络系统中,通过其中三层的过滤与处理之后,对输出的网络安全态势数据进行辨识,过程如图1 所示。
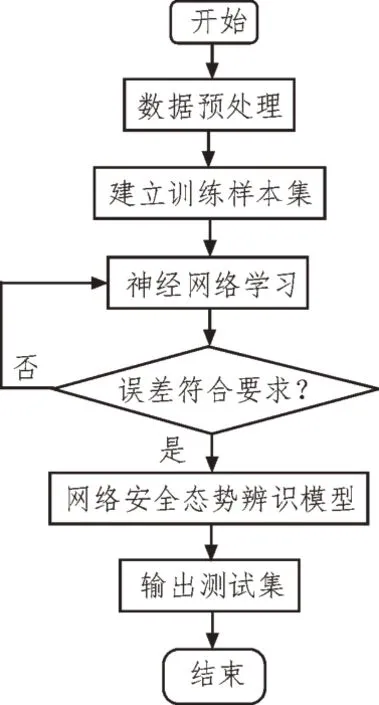
图1 网络安全态势辨识流程
神经网络模型主要与节点的数量、特征、隐藏函数与支持向量机的变化有关,而为了使聚类更迅速、计算更加准确,可以在蚁群算法的基础上改进神经网络模型,使其发挥出最大的效果[15-16]。假设存在两个任意态势样本,二者之间的距离受聚类快慢的影响,表达式为:
其中,d代表两个数据之间的距离。
格式化不需要的安全态势数据,可有:
两个样本会成为聚类中心的概率公式为:
当概率大于零时,就表明两个样本可以同时成为聚类中心,反之,则不能。
经过上述处理后,将相同类别数据聚类到同一个类中,以此实现电力信息网络安全态势辨识。
5 实验分析
为了验证所提方法的有效性,进行仿真实验,采用KDD Cup 数据集进行实验,该数据集中包含较多的入侵数据集,并对具体的网络行为进行了标注。在实验过程中,模拟攻击机对网络发起攻击,然后采用所提方法、文献[1]方法和文献[2]方法进行对比。
5.1 网络安全态势值辨识误差对比
分析所提方法与其他两种方法的辨识误差,对比结果如图2 所示。
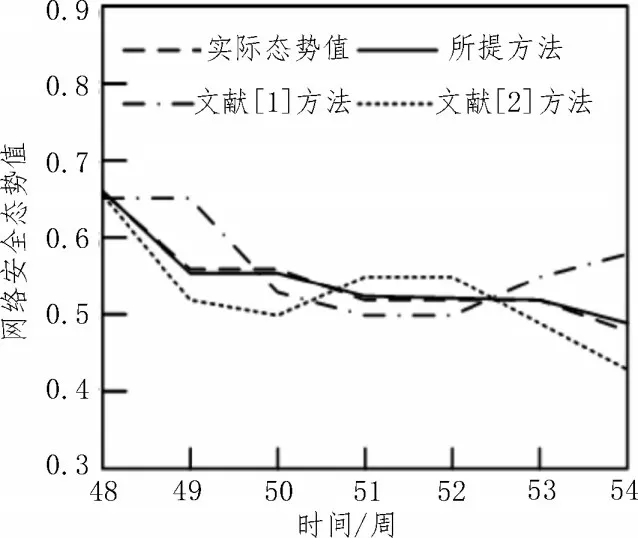
图2 不同方法的辨识误差对比结果
分析图2 可知,所提方法得到的辨识值与真实值基本能够保持一致,其辨识误差较低。而其他两种方法与态势值具有一定的差距,虽然在某些时间段内误差较小,但是依据整体曲线来看误差较大。
5.2 网络安全态势值辨识时间对比
分析所提方法与其他两种方法的辨识时间,对比结果如图3 所示。
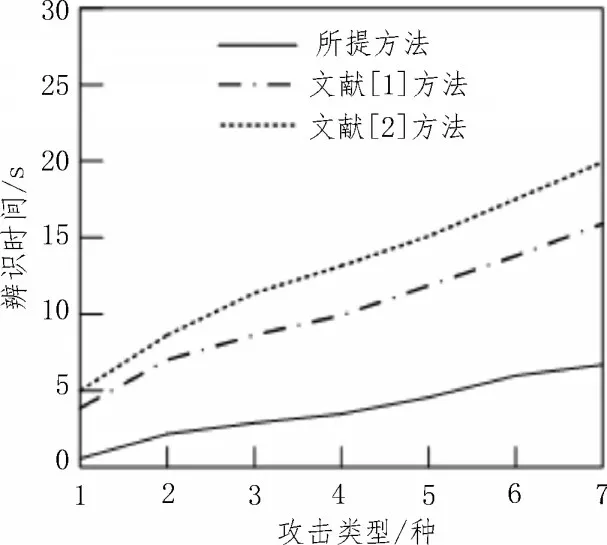
图3 不同方法的辨识时间对比结果
分析图3 可知,随着攻击类型种类的增加,不同方法的辨识时间随之增大。当攻击类型为t种时,文献[1]方法的辨识时间为16 s,文献[2]方法的辨识时间为20 s,而所提方法的辨识时间仅为7 s。由此可知,所提方法可以在短时间内实现网络安全态势的辨识。针对不同攻击类型,所提方法均低于其他两种方法的辨识时间[17-18]。
6 结束语
该文研究主要基于RBF 神经网络模型对电力信息网络安全态势数据进行辨识,该方法不仅具有较短的辨识时间,还降低了辨识误差。但由于网络安全的不确定性,会出现些许不足,还需要进一步完善。
