基于强化学习的多用户聚合帧长度优化方案*
2023-08-17方旭明
邓 邱,方旭明
(西南交通大学,四川 成都 611756)
0 引言
近年来,随着无线技术的飞速发展,无线业务的应用越来越广泛,比如在移动教学、视频会议、虚拟现实(Virtual Reality,VR)和物联网等设备[1]中的应用。由于各种智能设备的不断涌现,移动数据流量呈现爆炸式增长。为了满足流量需求,Wi-Fi 不断地提升传输速率,然而想要进一步突破吞吐量的瓶颈,盲目地提升传输速率并不可行。有研究[2]表明,IEEE 802.11 标准具有理论吞吐量上限和理论延迟下限,当传输速率达到足够高时,仅仅增加传输速率而不减少开销将限制吞吐量的提升。因此,减少开销对于Wi-Fi 网络实现更高的吞吐量是尤为关键的。在IEEE 802.11n 标准中引入了帧聚合技术[3-4],可以较好地解决上述问题。通过该技术,将多个较短的媒体访问控制(Medium Access Control,MAC)帧组合成一个长的MAC 帧进行传输,可减少MAC 层和物理层的帧头开销以及信道访问开销,提高MAC 效率。
单用户传输场景下的帧聚合机制迄今为止已经得到了广泛的研究。文献[5]提出了一种基于802.11n 网络的服务质量(Quality of Service,QoS)保证的帧聚合算法,根据队列指标(例如平均队列长度和链路利用率)并结合有效容量的概念,使用比例积分导数控制器来选择合适的聚合MAC 协议数据单元(Aggregation-MAC Protocol Data Unit,A-MPDU)长度,以提高信道利用率和降低时延。文献[6]针对帧聚合过程中的能耗问题,提出了一种基于在线学习的帧聚合方案,通过ε贪婪策略和模糊逻辑从MPDU 子帧大小集合中找到最优子帧长度,以最大限度地减少网络中的能耗。文献[7]提出了一种基于随机森林方法的帧聚合方案,首先利用Minstrel 速率控制算法确定调制与编码方案(Modulation and Coding Scheme,MCS),再根据网络状态(例如信道利用率、所选MCS 传输成功率等)选择合适的聚合帧长度,以提高网络吞吐量。
IEEE 802.11n 之后的标准继续使用帧聚合技术,并对此进行改进升级。IEEE 802.11ac 标准和IEEE 802.11ax 标准分别引入了多用户多输入多输出(Multi-User Multiple-Input Multiple-Output,MUMIMO)技术和OFDMA 技术来支持多用户帧聚合传输。在多用户帧聚合传输机制下,用户的传输时间需保持对齐[8]。由于网络流量异构性强[9],且每个用户的传输速率不同,导致用户的传输时间不同,传输时间较短的用户需要填充比特。在传输的过程中,过多的填充比特会降低信道的利用率,影响系统的吞吐量。因此,设计有效的多用户聚合帧长度优化方案来合理填充比特显得愈发重要。
目前,针对多用户帧聚合传输技术的研究主要基于MU-MIMO 多用户传输机制。文献[10]提出用其他用户的数据来代替填充的比特,以提高传输效率。文献[11]与文献[10]类似,提出用其他用户的数据帧来填补空闲信道时间,设计了两种填充方案,能以非常小的开销收集所需的信息,同时防止填充帧损害原始帧的可解码性。虽然用其他站点的数据来代替填充比特可以提高传输效率,但是这种方法需要修改标准,以允许空间流中有多个目的地,且需更改用户帧结构以及MCS,增加了发送和接收过程的复杂性。文献[12]提出了一种基于802.11ac 网络的多用户传输帧聚合方案,根据站点的数据缓存状态和传输速率,找到最优的多用户聚合帧长度,以最大化传输效率。但是该方案是从所有用户的传输时间中找出一个使当前网络吞吐量最优的传输时间,作为多用户传输时间,这样可能会陷入局部最优。
针对OFDMA 多用户帧聚合传输的研究鲜少,现有研究大多侧重于OFDMA 中资源的优化,比如资源单元(Resource Unit,RU)调度[13]、子载波分配[14]以及接入机制[15]的研究。多用户聚合帧长度优化这一问题在文献中尚未得到深入的探讨,但是多用户帧的填充开销对系统性能的影响不容忽视,是无线局域网中多用户传输的一个重要设计因素。
综上所述,尽管当前已有对多用户帧聚合传输技术的研究,但主要是针对MU-MIMO 多用户传输。由于OFDMA 多用户传输与MU-MIMO 多用户传输在传输机制方面有一定差异,因此针对MUMIMO 多用户帧聚合传输的优化方案不能完全适用于OFDMA 多用户传输。
本文基于802.1ax Wi-Fi 网络,对OFDMA 多用户聚合帧长度优化问题进行了研究,主要贡献如下:
(1)提出了一种基于强化学习的OFDMA 多用户聚合帧长度优化方案,该方案将AP 作为智能体,通过训练和学习,根据站点的缓存状态决策出最佳的多用户聚合帧长度。
(2)所提方案适用于下行和上行OFDMA 传输。因为无论是上行还是下行传输,都由AP 进行集中调度,AP 能够获得上、下行需要传输的数据信息[8],并以此来决策多用户聚合帧长度。
(3)以上行传输场景为例进行问题建模,并通过仿真验证了所提方案能够减少帧聚合传输过程中的填充比特,增加传输的有效负载,提升了系统吞吐量和信道利用率。
1 系统模型与问题建模
1.1 网络模型
在本文中,帧聚合传输考虑上行传输场景,基于集中式网络拓扑结构。如图1 所示,系统中有一个AP 和n个站点(Station,STA),n个STA 均与AP 相关联,由AP 调度STA 的传输。AP 采用缓冲状态报告轮询(Buffer Status Report Poll,BSRP)的方式调度上行多用户帧聚合传输,周期性地向STA发送触发帧来收集缓存信息,根据缓存信息为STA分配RU 进行数据传输。

图1 一个AP 和多个STA 组成的网络拓扑
假设系统中STA 的集合表示为SSTA={STA1,STA2,…,STAn},忽略干扰,则STAi与AP 之间的信噪比(Signal to Noise Ratio,SNR)可表示为:
式中:PTX为STA 的发送功率,GTX和GRX分别为站点天线的发送增益和AP 天线的接收增益,PL为路径传输损耗,路损模型使用标准中的802.11 传输模型[16],为环境中的噪声功率。
根据香农公式可以计算出STAi在给定RU 下的最大传输速率:
式中:B为RU 的带宽。
1.2 问题建模
基于OFDMA 多用户帧聚合传输的过程如图2所示,为了保证多用户传输时间对齐,需要对传输时间较短的站点进行额外的比特填充,而多用户聚合帧长度的设置决定了填充比特的数量。若采取聚合帧长度L1所对应的传输时间,那么所有站点都需要填充比特,这样会降低系统吞吐量。若采取聚合帧长度L2所对应的传输时间,那么所有站点传输的有效负载大大减少,也会降低系统吞吐量。因此,本文的目标是设计出合理的方案来对多用户聚合帧长度进行优化,以此最大化系统吞吐量,提高信道利用率。
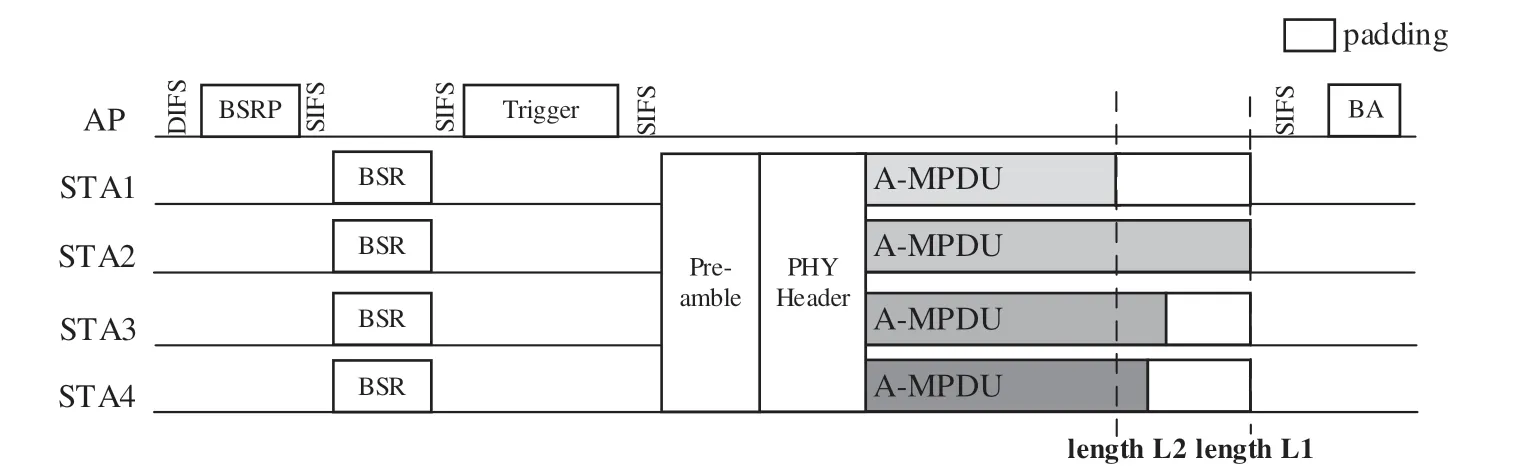
图2 OFDMA 多用户帧聚合传输过程[8]
将STAi的缓存队列记为li,对应的传输时间为li/vi,i=1,2,…,n,vi为STAi的实际传输速率。假设多用户聚合帧长度设置为L,那么多用户聚合帧传输时间为:
式中:vave为n个STA 的平均速率。
假设有k个STA 的传输时间小于多用户帧聚合传输时间,那么这类STA 需要额外填充比特,据此系统吞吐量可以表示为:
式中:tcost为多用户传输机制开销;tdifs为分布式帧间隔持续时间;tsifs为短帧帧间隔持续时间;tbsrp和tbsr分别为缓存区状态报告轮询触发帧和缓存区状态报告的持续时间;ttf,tpre,thead和tba分别为触发帧、前导码、聚合帧帧头和块确认应答帧的传输时间。
因此,优化问题可以表示为:
式中:Lmin为最小多用户聚合帧长度;Lmax为最大多用户聚合帧长度。
2 基于强化学习的聚合帧长度优化方案
上述OFDMA 多用户帧聚合传输场景下的帧长优化问题实际上是一个动态调优问题,而动态未知环境下的优化问题可以被建模成马尔可夫决策过程(Markov Decision Process,MDP)。Q learning 算法可以有效解决MDP 问题。然而OFDMA 多用户传输过程较为复杂,且具有较大的状态和动作空间,简单的Q learning 算法难以解决。深度Q 网络(Deep Q-Network,DQN)算法在Q learning 算法的基础上引入了神经网络,来拟合Q 表,可以很好地解决此类复杂问题。因此,本文提出了利用DQN 算法来优化OFDMA 多用户聚合帧长度。
2.1 强化学习三要素定义
在强化学习中,智能体根据环境的状态选择动作并且执行,环境根据智能体的动作进行状态转移,并给智能体一个奖励或者惩罚。强化学习的三要素包括状态空间、动作空间和奖励函数。对于本文所考虑的OFDMA 多用户场景,将AP 作为智能体,状态空间、动作空间和奖励函数定义如下:
状态空间S:st∈S,S=[s1,s2,…,st],st=[l1,l2,…,ln],表示在t时刻n个STA 的缓存数据长度。AP 可以通过BSRP 帧向STA 发出请求,STA 通过缓存状态报告(Buffer Status Report,BSR)向AP 反馈缓存数据信息。
动作空间A:at∈A,A=[a1,a2,…,at],对于当前状态st,智能体可以根据决策策略采取动作at。at为可选的聚合帧长度L,范围为[a,b],以步长δbyte 进行离散化。
奖励函数r:r(st,at)表示在当前状态st下选择动作at得到的即时奖励。在前面的优化问题中,本文的研究目标是最大化系统吞吐量。因此,定义即时奖励为t时刻的系统吞吐量,并将其归一化,表达式如下:
式中:Th为式(5)中给出的含义;Thmax为网络预期的最大吞吐量。
2.2 多用户聚合帧长度优化策略
在t时刻,智能体通过观察状态st,按照策略π选择相应的动作at,作用于环境,环境反馈给智能体一个即时奖励r(st,at),然后转移到下一个状态。st+1智能体的目标是学习策略π,使其获得的长期累积折扣奖励最大化,表达式如下:
式中:γ∈[0,1]是折扣率。当γ接近于0 时,表明智能体更在意短期回报;反之,当γ接近于1 时,长期回报变得更加重要。因此,在选择γ值时,应根据系统特性进行调整,来确保γ在合理的范围内。
策略π是将当前状态映射至动作的概率分布。状态st的状态值函数表示智能体在遵循策略π时一个状态的值,表达式如下:
状态-动作值函数则表示智能体在遵循策略π时,在状态st下采取某个动作的好坏程度,表达式如下:
Bellman 方程常用于求解MDP 问题,其核心思想是寻找最优状态值函数,即所有状态值函数中的最大值函数,表达式如下:
对于V*(s),一个状态的最优值等于在该状态下采取的所有动作所产生的状态-动作值函数中的最大值,表达式如下:
因此,可以通过寻找最优状态-动作值函数来寻找最优策略π*。在Q learning 算法中,更新Q值Q(st,at)[17]的公式为:
式中:α为学习率。
Q learning 算法使用一张Q 表来存储Q 值,在DQN 算法中,使用神经网络来近似Q 表输出Q 值,即Q(st,at;θ)≈Q(st,at)。本文使用的DQN 算法模型如图3 所示,为了提高网络训练的收敛性和稳定性,DQN 引入了目标网络和经验回放策略。通过梯度下降来更新θ值,损失函数表达如下:

图3 DQN 算法模型

式中:Q_target为Q的目标值;θ'为目标网络的权重。
本文提出的多用户聚合帧长度优化算法流程如下:
3 仿真结果及分析
本节通过MATLAB 仿真对所提出的基于DQN算法的聚合帧长度优化方案的性能进行验证。
3.1 仿真场景及参数设置
仿真场景设置为单AP 多STA 场景,STA 在AP周围随机分布。仿真采用IEEE 802.11ax 标准中基于OFDMA 的上行多用户传输机制,由AP 调度STA 进行传输。信道带宽设置为20 MHz,聚合帧采用A-MPDU 传输方式。具体参数如表1 所示。
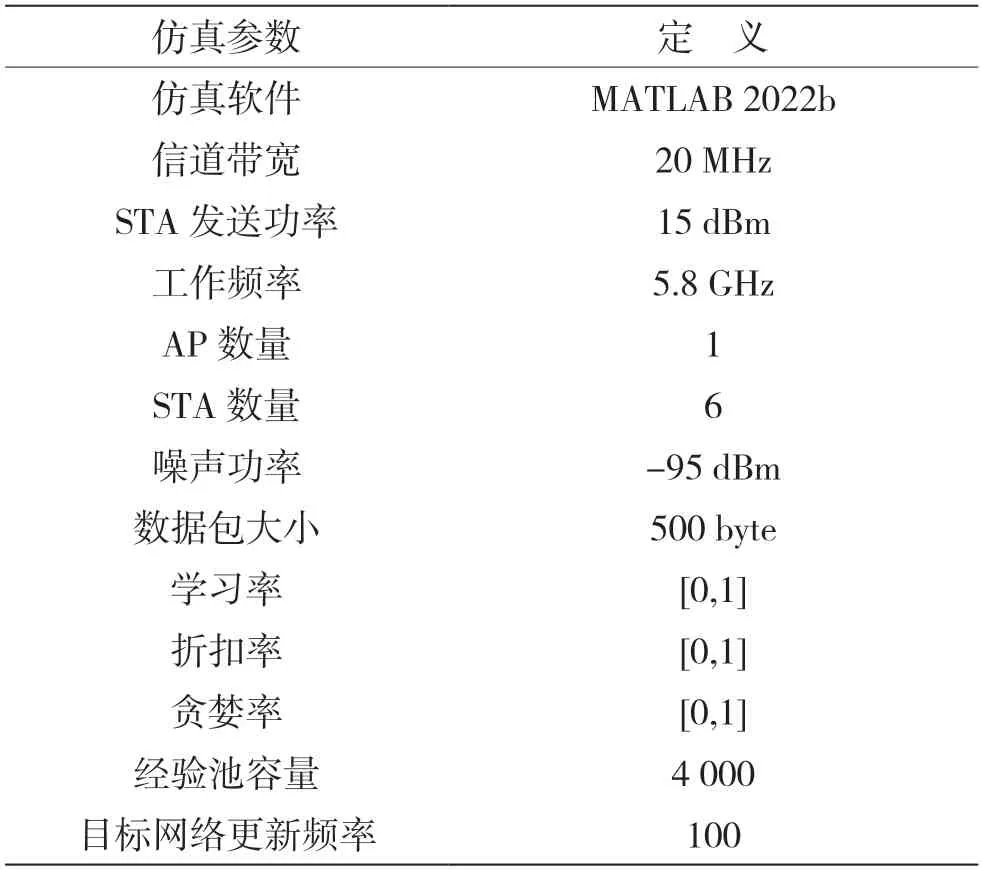
表1 仿真参数设置
为了准确体现本文所提方案对网络吞吐量性能的提升,在仿真中对所提方案与3 种基线方案进行了比较,这3 种基线方案具体如下文所述。
(1)基线方案1:将多用户聚合帧传输过程中最长的用户传输时间设置为多用户传输时间,记为最大(Max)聚合方案。
(2)基线方案2:将多用户聚合帧传输过程中最短的用户传输时间设置为多用户传输时间,记为最小(Min)聚合方案。
(3)基线方案3:随机选择一个用户的传输时间,将其设置为多用户传输时间,记为随机(Random)聚合方案。
3.2 仿真结果分析
图4 给出了所提算法累积奖励收敛曲线。在算法初期,累积奖励较低,智能体通过不断地探索和训练,掌握了环境状态和动作之间的映射,能够做出更优的动作选择,累积奖励不断增加,最终达到收敛。
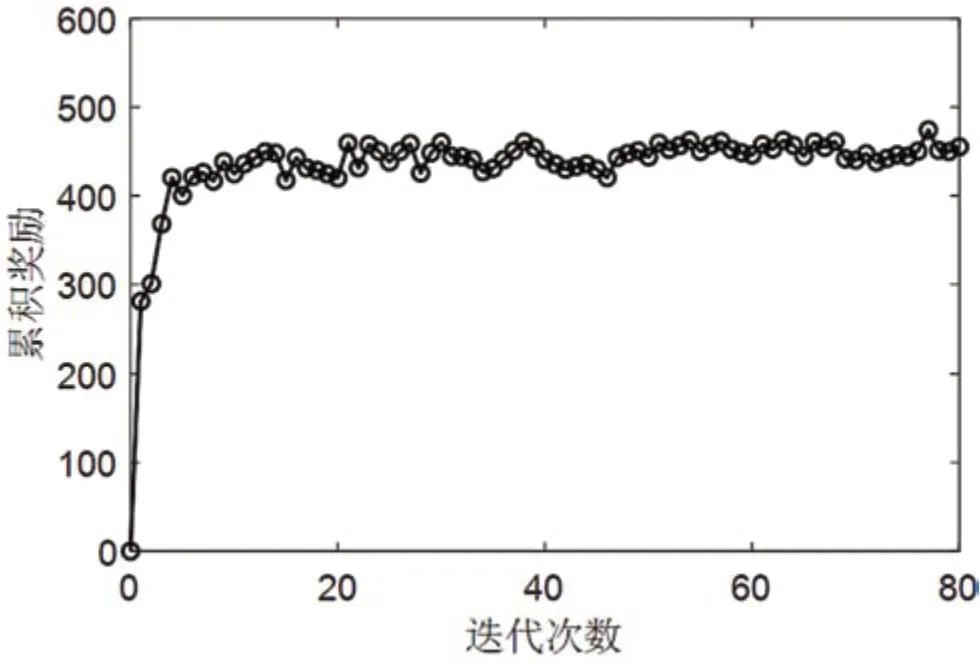
图4 累积奖励收敛曲线
图5 给出了不同学习参数对系统吞吐量的影响。图5(a)表示,设置ε=0.2,α=0.5,γ=0.2 时,系统吞吐量相对较大。在这种情况下,α值降低对于吞吐量的影响较小,但是α值增大,吞吐量却大大降低。图5(b)表示,设置ε=0.5,α=0.5 时,改变γ的值,系统吞吐量的变化较小。图5(c)表示,对于ε=0.8,α=0.5,设置γ=0.8 时,系统吞吐量得到显著提升。因此,在设置ε,α和γ的值时,应根据系统特性不断调整,以使算法具有较好的性能提升效果。

图5 吞吐量与学习参数的关系
图6 和图7 分别给出了4 种方案下不同STA 的吞吐量以及系统吞吐量。从图6 可以看出,基于DQN 算法的聚合方案能够有效提升每个STA 的吞吐量。
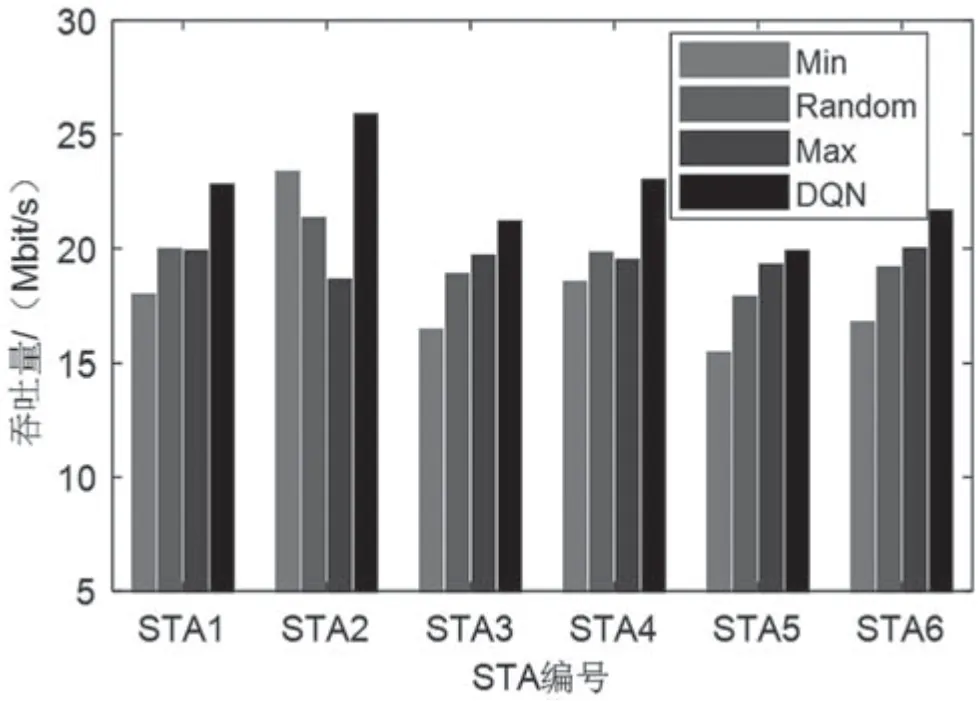
图6 STA 吞吐量
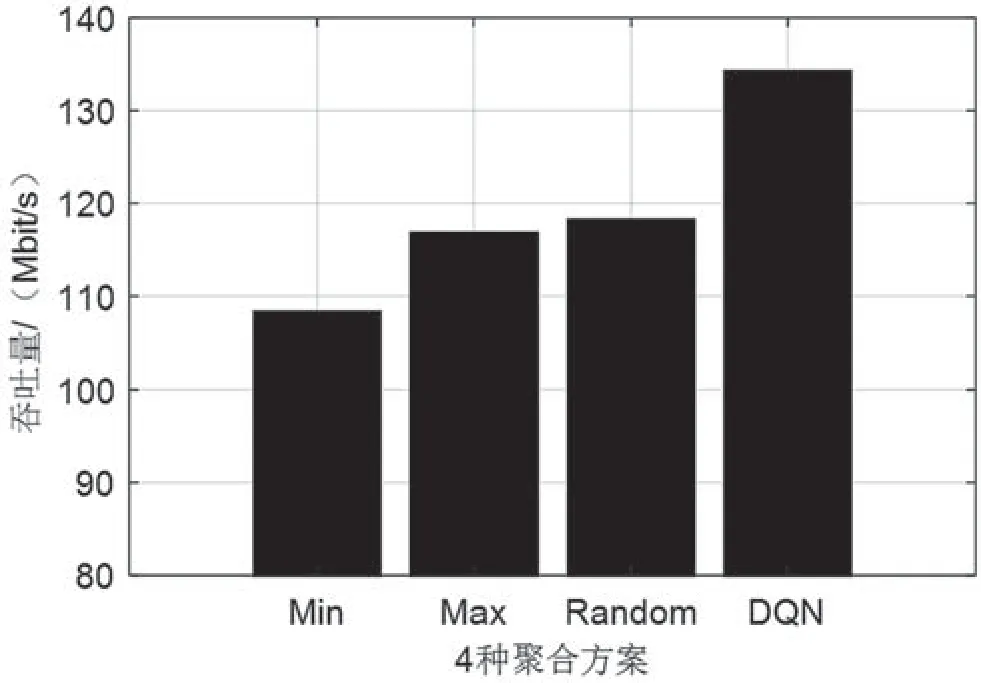
图7 系统吞吐量
从图7 可以看出,Min 聚合方案吞吐量最低,而DQN 聚合方案吞吐量最高,其次是Max 和Random 聚合方案。主要是因为Min 聚合方案将最短的用户传输时间作为多用户传输时间,大大减少了每次传输过程中的有效负载,增加了协议开销在聚合帧传输时间中的占比,从而降低系统吞吐量。Max 和Random 聚合方案相较于Min 聚合方案,能够减少协议开销在整个聚合帧传输时间中的占比,然而不可避免地会带来一定程度的比特填充,从而降低系统吞吐量。而基于DQN 算法的聚合方案,可以根据站点的数据缓存情况,自适应地调整聚合帧长度,从而减少填充比特,增加传输过程中的有效负载,提升系统性能。
图8 和图9 分别给出了4 种方案下不同STA 的填充比特数量以及系统填充比特数量。从图8 可以看出,基于DQN 算法的聚合方案能够有效减少每个STA 的填充比特数量。
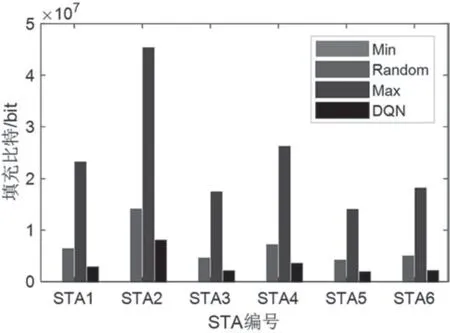
图8 STA 填充比特数量

图9 系统填充比特数量
从图9 可以看出,由于Max 聚合方案将最长的用户传输时间作为多用户传输时间,导致填充比特数量最多,Min 聚合方案将最短的用户传输时间作为多用户传输时间,基本没有填充比特,Random和DQN 聚合方案有一定程度的比特填充,但是DQN 聚合方案填充相对较少。因此,结合系统吞吐量与填充比特数量,可以看出DQN 聚合方案对于系统性能的提升是优于其他三种方案的。
图10 给出了4 种方案下的系统频谱效率。从图中可以看出,基于DQN 算法的聚合方案的频谱效率较高。这是因为其可以根据各个站点的数据缓存情况,动态地找出最优的聚合帧长度,从而减少填充比特,提高系统频谱效率。其他3 种聚合方案的系统频谱效率相对较低,这是因为过多地填充比特或者减少传输有效负载,会导致带宽资源的浪费。
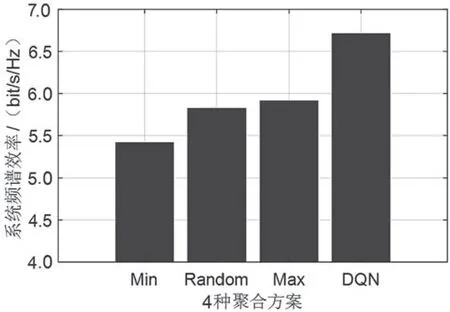
图10 系统频谱效率
4 结语
本文基于OFDMA 传输过程,对多用户聚合帧长度优化问题进行了研究。首先给出了多用户帧聚合传输过程的系统模型并建立了优化问题,其次设计了基于深度强化学习框架的聚合帧长度优化方案,最后通过MATLAB 进行仿真。仿真结果表明,本文所提出的方案能够根据站点的数据缓存情况自适应选择聚合帧长度,减少填充比特,增加有效传输负载,降低协议开销在聚合帧传输时间中的占比,从而提升系统吞吐量和频谱效率。
然而本文的研究还存在一些局限:一是在仿真过程中,只搭建了上行传输场景,从而只验证了该方案对于上行传输系统性能提升的有效性和适用性;二是并未分析算法的复杂性,只验证了算法对于系统性能的提升。在接下来的研究工作中,会从以下两个方面进行完善:一是通过仿真验证所提方案对于下行传输系统性能提升的有效性和适用性;二是在不同的仿真场景下,对于系统性能的提升以及算法的复杂性,与其他优化算法进行对比分析。
