基于CNN 和Transformer 的双路径语音分离*
2023-08-17王钧谕
王钧谕,高 勇
(四川大学,四川 成都 610065)
0 引言
Transformer[1]在现代深度学习中已被广泛使用。合理地应用Transformer 可以在许多自然语言处理(Natural Language Processing,NLP)和语音处理任务中取得优秀的成果,例如机器翻译、语音识别、语音增强、文本分类和许多其他应用程序[2-7]。Transformer 可以对长期依赖关系进行更精确地建模,这一特性使其适用于音频处理,文献[8]已经证明长期建模对语音分离性能有显著影响。另外,卷积在语音处理中也取得了很大的成功[9-11],它通过局部感受域逐层渐进地捕获局部上下文。
然而,基于Transformer 或卷积的模型都有其局限性。一方面,虽然Transformer 擅长建模长序列,但它不太能够提取细粒度的局部特征;另一方面,卷积神经网络以分层方式利用局部信息。通过一个本地窗口学习共享的基于位置的内核,能够捕获边缘和形状等特征。但使用本地连接的一个限制是需要更多的层或参数来捕获全局信息。为了解决这个问题,本文提出了DPCFNet,这是一个将自注意力、卷积和双路径网络相结合的模型。在公开的中文和英文数据集上进行的大量实验表明,相比于单一使用卷积和Transformer 的模型,本文方法实现了更好的分离效果。
1 改进Transformer 和Dense block
Transformer 由编码器和解码器组成[1]。本文选择Transformer 编码器作为基本模块。为避免混淆,本文中对Transformer 的引用是指Transformer 的编码器部分。原始的Transformer 编码器通常包含位置编码、多头自注意和位置前馈网络3 个模块。本文的Transformer 与文献[12]一样,通过在多头自注意力模块后插入深度卷积来对局部上下文信息进行更充分的建模,简称为Conformer。
Conformer 结构示意图如图1 所示。它由几个模块组成,包括前馈模块、多头自注意力模块、卷积模块(ConvModule)和层归一化模块。前馈模块由线性层、swish 激活函数[13]、dropout 和第2 层线性层组成。ConvModule 开始是逐点卷积和GLU 激活函数[14],接着通过具有批量归一化、swish 激活和逐点卷积的一维深度卷积层。多头自注意力模块由自注意力和相对位置编码结合而成,相对位置编码可以使自注意力模块对不同的输入长度进行更好的泛化,所得到的Conformer 块对语音长度的变化具有更强的鲁棒性。本文使用带dropout 的前范数残差单元[15],这有助于训练和正则化更深层次的模型。

图1 Conformer 结构
基于卷积的密集连接块最近在文献[16]中被提出。密集连接块基于特征重用的思想,使给定层的输出在后续层中被重用多次。因为给定层与后续层直接连接,使其可以避免DNNs 中的梯度消失问题。在密集连接块的基础上,本文提出了一个新的用于语音分离的Dense block,它由5 个二维卷积层组成,卷积核大小为(2,3),每个卷积层后添加层归一化和PReLU 非线性激活[17]。给定层的输入由前一层的输出和最开始的输入连接形成。连续层中的输入通道数量分别为C,2C,2C,2C和2C。每次卷积后的输出都有C个通道。本文提出的Dense block 如图2所示,其中,卷积核(X,Y)中的X和Y分别表示输入和输出通道数。与原始密集连接块相比,Dense block 的计算复杂度较低,更适用于实时语音处理。
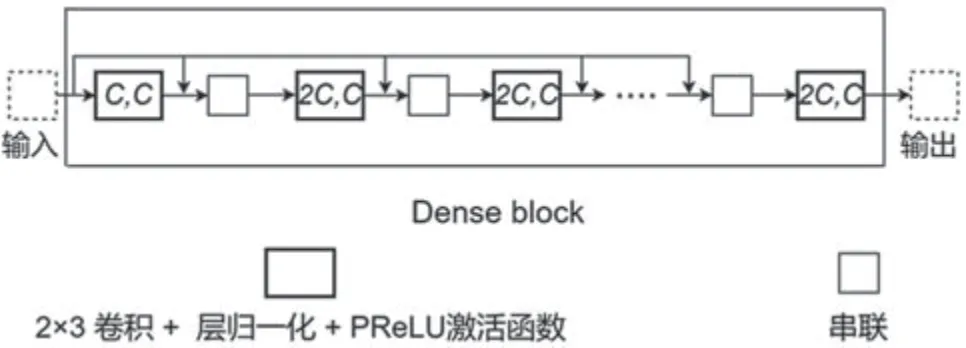
图2 提出的Dense block 结构
2 本文提出的DPCFNet
本文提出的DPCFNet 结构如图3 所示,它由编码器、分离层和解码器组成。首先,使用编码器将混合波形转换为中间特征空间中的相应特征。然后将特征输入到分离层,为每个源构造掩码。最后,通过对掩码特征的转换,实现源波形的重构。
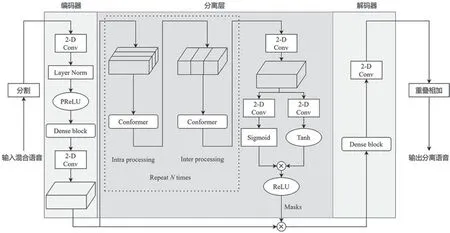
图3 DPCFNet 的结构框架
2.1 分割和重叠相加
分割阶段拆分原始混合语音x∈R1×L,L为输入混合语音的长度,帧长为F,跳跃步长为H。然后将所有帧进行堆叠,形成一个三维张量X∈R1×K×F,K表示所给的帧数,其计算式为:
采用重叠叠加法作为分割的逆运算,用于恢复分离波形。
2.2 编码器
编码器使用两个卷积层,其中第1 层使用大小为(1,1)的卷积滤波器将通道数量增加到64 个,第2 层使用大小为(1,3)的滤波器将帧大小的尺寸减半,步幅为(1,2),两个卷积层之间添加包含5 个膨胀卷积层的Dense block。所有卷积层之后进行层归一化和PReLU 非线性激活。编码器的输入为混合语音分割后得到的X∈R1×K×F,输出为高维混合特征I∈R64×K×F/2。
2.3 分离层
分离层由双路径Conformer(Dual-path Conformer,DPCF)和掩码模块共同构成。编码器的输出I被传递给N个DPCF,如图3 所示,每个DPCF 由1个Intra-Conformer 块 和1 个Inter-Conformer 块 组成,其中Intra-Conformer 块学习局部信息,Inter-Conformer 块学习全局信息。Intra-Conformer 块首先对输入特征的局部进行独立建模,作用于I的第2维,Intra-Conformer 的公式如下:
然后使用Inter-Conformer 块汇总所有Intra-Conformer 块的输出信息,以学习语音信号的全局信息,作用于I的最后一个维度,Inter-Conformer的公式如下:
掩码网络利用DPCF 的输出特征获取掩码进行分离。通过第2 个二维卷积,DPCF 的输出沿通道维数按分离源的个数加倍,以匹配输出分离语音。然后经过两路二维卷积和非线性运算,将输出相乘后经过ReLU 激活函数,得到掩码。最终的掩码编码器特征是通过掩码和编码器输出之间的逐元素乘法获得的。
2.4 解码器
解码器由一个(1,1)卷积层和一个Dense block组成,其中Dense block 与编码器中的相同。分离层输出的特征通过Dense block 重构为分离语音特征。然后采用卷积核大小为(1,1)的二维卷积滤波器将分离语音特征的通道维数恢复为1,最后通过重叠相加法得到最终语音波形。
3 实验与结果分析
3.1 实验配置
为了证明本文所提出的语音分离网络对不同语种具有普适性,使用了英文数据集和中文数据集进行了评估,其中英文数据集来源于WSJ0 数据语料库[18],中文数据集基于DiDiSpeech 中文语音数据库[19]创建。
实验所使用的英文数据集是从WSJ0 数据语料库中随机选择不同说话者的语音进行混合,混合信号的信噪比(Signal-Noise Ratio,SNR)在-5 dB至5d B 之间随机生成,其中训练集为10 000 条语音,测试集和验证集各为1 000 条语音。为了保证实验的一致性,将数据集的采样率统一降采样至8 kHz。
中文数据集基于DiDiSpeech 中文语音数据库[18]创建,数据集包括500 个说话者,每个说话者约有100 个WAV 格式的语音,每个语音时长为3~6 s,原始采样率为48 kHz,在数据预处理时将其降采样至8 kHz。从DiDiSpeech 数据集中随机选择两条不同语音样本生成混合语音,在-2.5 dB 至2.5 dB 之间均匀采样各种信噪比。生成的混合数据集包含训练、验证和测试集中的5 000 个、800 个和800 个话语。
语音分离的目标是提高语音信号的清晰度。为了更好地评估本文提出的模型,实验采用排列不变 训 练(utterance-level Permutation Invariant Training,uPIT)[20]来训练所提出的模型,以最大化尺度不变信噪比(Scale-Invariant Singal-Noise Ratio,SI-SNR)[9]。
在分割和重叠相加阶段,每个帧的大小为512个样本(64 ms)、重叠256 个样本(32 ms)。分离层设置双路径ConformerN为5 个,每个Conformer块包含4 个注意力头。
在训练阶段,将周期epoch 设置为100,使用Adam[21]作为优化器。训练停止的标准是在连续10个epoch 的验证集上损失函数(SI-SNR)没有下降。初始学习率为0.001,每两个epoch 衰减0.98。
3.2 实验结果分析
为了更好地衡量本文提出的DPCFNet 的分离性能,使用SI-SNR 和信号失真比(Signal-distortion ratio,SDR)作为评价指标,这两个指标经常用于各种语音分离系统。
首先将本文模型与几种基线模型在英文数据集上进行得分比较。实验结果如表1 所示,本文模型在SI-SNR 和SDR 指标上分别达到了18.2 dB 和18.6 dB,两者得分均优于所有基线模型。结果表明,本文所提出的模型在保持尺寸最小的情况下,仍然能够获得更好的语音质量。

表1 在英文数据集上与其他模型的SI-SNR、SDR 和模型大小的比较
为了证明DPCFNet 模型具有通用性,本文在中文数据集上进行了相关实验,并以两个经典的语音分离模型Conv-Tasnet[10]和DPTNet[6]作为基线模型。表2 列出了DPCFNet 和两个基线模型的平均SI-SNR 和SDR 得分。结果表明,本文提出的将Transformer 和卷积相结合的模型DPCFNet 仍然明显优于基线模型。这说明本文方法具有通用性,并进一步证明了该方法的有效性。

表2 在中文数据集上与其他模型的比较
为了验证Dense block 相对于原始密集连接块具有更低的计算复杂度,本文设计了两个模型,分别由10 个Dense block(模型1)和10 个密集连接块(模型2)组成。通过在Intel(R) Core(TM) i9-12900KF CPU 上处理一条4 s 的中文语音,并进行100 次实验取平均值,得到计算时间。从表3 的结果中可以发现,相较于原始密集连接块,Dense block 的参数数量减少了18%,计算时间缩短了24%。

表3 模型大小和计算时间的比较
4 结语
本文提出了一种基于双路径Conformer 和Dense block 的神经网络,用于端到端多说话人单耳语音分离,该网络能充分地提取长序列语音的局部和全局上下文信息。在英文和中文数据集上的两个实验证明了所提出模型的有效性和通用性。此外,与其他现有模型相比,本文提出的模型在性能更好的情况下具有更少的可训练参数。在未来的工作中,可以考虑扩展这种机制以进行实时处理。
