基于用户重购行为的产品推荐方法
2023-08-15刘春丽魏雪梅程明月刘业政
耿 杰 刘春丽,2 魏雪梅 程明月 袁 昆,2 李 洋 刘业政,2
1 (合肥工业大学管理学院 合肥 230009)
2 (大数据流通与交易技术国家工程实验室(上海数据交易中心) 上海 201210)
3 (中国科学技术大学大数据学院 合肥 230026)
4 (蒙特克莱尔州立大学商学院 美国新泽西蒙特克莱尔 07043)(gengjie@mail.hfut.edu.cn)
电子商务的发展为消费者提供了更多选择,但也造成了信息过载,消费者需要花费大量时间筛选符合需求的产品.个性化推荐方法通过向消费者提供产品推荐,不仅能降低消费者搜索成本、提高消费者满意度,还能有效提升企业经营效率、增加企业盈利[1].然而现有大多数个性化推荐方法主要研究如何向用户推荐未购买过的新产品,却很少考虑用户重购行为的影响.理论研究表明,消费者对于面临维持重复购买还是转换购买新产品的决策,往往表现出维持重复购买的行动偏好,即维持现状效应[2].因此,考虑用户重购行为对于准确刻画用户偏好、提升产品推荐准确度至关重要.
重复消费现象在消费频次高的快速消费品零售场景下尤为常见.与传统的个性化推荐相比,重复消费推荐面临三大挑战:1)如何准确、可信地刻画用户的重购偏好.虽然已有文献对重购产品推荐进行了探究[3-4],但是对用户重购偏好的刻画层次较为单一,模型设计普遍缺乏可解释性.2)如何可信地描述用户重购偏好的动态变化规律.现有文献主要从数据集中识别用户动态偏好规律,其结果受数据集的限制,泛化性较差,缺乏行为理论层面的可解释性.3)如何把握重复购买和转换购买的时机.用户消费决策时,也会对重复购买的产品感到厌倦从而转向购买新产品[5],因此亟需解决融合重购产品和新产品的混合推荐难题.
针对这3个挑战,本文面向快速消费品零售场景,融合多层次用户偏好信息,构建具有双层注意力机制的用户重购行为模型,并基于消费者信息处理理论,刻画了理论驱动的消费者重购动态偏好,最后融合产品流行度信息进行重购产品和新产品的混合推荐.本模型不仅提升了产品推荐结果的准确性,更从结构和理论2个方面提升了模型可解释性.
在模型构建方面,本文融合注意力机制和指针生成网络,提出了多层信息融合的用户重购行为预测方法,从“产品—购物篮—时间序列”层次准确地刻画用户重购偏好.具体来说,本文首先在产品层面,采用注意力机制学习用户对购物篮中不同产品的重购偏好.接着在购物篮层面,本文融合Transformer编码器和双层LSTM模型对购物篮进行编码,以全面提取用户购物篮偏好的多空间特征.最后在时间序列层面,本文进一步融合指针生成网络[6],利用指针生成网络包含的注意力机制学习时间序列中不同位置购物篮的权重分配,同时进行下一次产品购买的概率预测.本文的分层注意力模型不仅通过融合多层次信息,准确刻画了用户重购偏好,更能通过学习用户对不同产品、不同购物篮的注意力分配,为我们理解下一时刻用户的购买决策提供了可解释性.
针对用户重购偏好动态变化问题,本文采用理论驱动的方式,基于消费者信息处理理论来刻画用户重购偏好的动态变化规律.信息处理理论认为,用户重购偏好分为重购期、拓展期和均衡期3个阶段[7].在重购期,消费者对该类产品不熟悉,需要处理大量候选产品信息来决策,易产生信息过载、消费不确定性较高等问题[7].特别在零售场景,用户不能直接触碰感知产品特征,此时用户倾向于重复购买相同产品,以降低信息处理成本和消费不确定性[8].在拓展期,用户在重购过程中,不断接受外界新的信息,对产品认知和偏好发生变化.此时,用户对重购产品的偏好下降,转而对新产品产生兴趣,发生购买转换行为[2].在均衡期,由于前期探索,用户对同类产品非常熟悉,从而产生过度自信而停止新产品探索[9].该现象在影响不大、用户不愿投入过多精力的快速消费品消费中尤为明显[10].此时,用户倾向于在已购买过的产品中重复选择购买,对产品的重购偏好再次复苏[11].考虑到上述3阶段的偏好演变过程,本文采用S型函数以准确刻画这一动态变化趋势.
最后本文同时考虑重购产品和新产品的混合推荐,并进一步融合产品流行度信息学习用户对产品的动态偏好.用户的购买行为是重复消费与新颖消费的动态混合行为.一方面,受不确定性规避和路径依赖的影响[12],用户倾向于重复购买相同的产品.另一方面,用户也会接受外界环境的新信息,从而对新产品感兴趣.因此,必须同时考虑用户对重购产品和新产品的偏好,进行重购产品和新产品的混合推荐,才能满足用户需求、提高用户满意度.本文认为,产品流行度是影响用户新产品购买行为的关键因素[13].流行的产品更能引起消费者的兴趣和关注,这种外界刺激更能促使消费者做出购买新产品的决策.因此为刻画这一现象,我们在模型中进一步引入产品流行度特征,并利用幂律分布来刻画产品流行度对于用户新颖消费的影响,从而提升产品混合推荐的准确性.
本文的贡献包括4个方面:
1)融合注意力机制和指针网络,提出了多层信息融合的用户重购行为预测方法,从“产品—购物篮—时间序列”层次准确地刻画用户重购偏好,并通过学习用户在不同层次上的偏好差异,提升了用户购买预测的可解释性;
2)采用理论驱动的方式,基于消费者信息处理理论将用户重购行为分为重购期、拓展期和均衡期3个阶段,并利用3个阶段S型曲线刻画用户重购偏好的动态变化规律,提升了理论可解释性和研究泛化性;
3)融合产品流行度信息来学习用户对新产品的偏好程度,并利用幂律分布来刻画产品流行度对于用户新颖消费的影响,进行重购产品和新产品的混合推荐,进一步提升推荐准确性;
4)在真实数据集上的实验结果表明,本文提出的多层信息融合的用户重购行为预测方法能有效捕捉用户购买行为特征,为用户适时推荐符合需求的产品,并且学习出的参数具备较好的可解释性.
1 相关工作
1.1 用户重购动机分析
用户重购行为是用户忠诚度的直接表现,对公司的经营状况和盈利能力产生重大影响.因此,许多学者对重复购买的动机展开了相关研究.例如,从消费者的角度,文献[14]表明消费者在决定是否继续重复购买时会权衡外在利益,如节省时间和金钱,以及内在利益,如享受、时尚参与、新奇等.文献[15]基于消费者导向理论确定了顾客再购意愿的7个动机,包括服务质量、公平性、价值、顾客满意度、过去忠诚度、预期转换成本和品牌偏好.文献[16]分析了游戏公司的购买数据,发现用户的购买间隔时间、购买频率和购买周期等与时间相关的特征是影响再购决策的重要因素.此外,通过分析消费者的重购行为模式,文献[17]认为,用户重购行为取决于互动的近期性和产品的质量,其中近期性是最关键的因素.
从企业服务的角度,文献[18]指出,在线产品价格、产品质量、客户服务、交货时间、付款方式和支付安全等因素决定了客户的重复购买意愿.文献[19]则指出,对于不同的客户群体,产品促销和自由退货政策可以增加客户在市场增长的不同阶段的回购行为.文献[20]分析了影响用户回购意图的因素,包含客户支持、消费者对产品的期望、准时交货、订单跟踪和产品的可用性等.此外,文献[21]发现店铺价格印象对顾客重购意愿有积极影响,价格水平则起到调节作用.文献[22]的工作也进一步分析了价格促销对重复购买激励的影响.文献[23]指出,电子服务质量会对客户满意度和重购意愿产生影响,而价格虽不影响顾客满意度,但会影响重购意愿.
1.2 重复购买推荐
序列推荐作为推荐系统的重要任务,受到广泛研究和关注.早期研究提出基于马尔可夫链的序列推荐方法[24-25],以有效捕获序列项目间的一阶依赖关系.后来卷积神经网络(CNN)和循环神经网络(RNN)被应用于序列推荐,以进一步捕捉序列间的高阶依赖关系.例如文献[26]提出了一个基于CNN的生成模型NextItRec来模拟用户的长期偏好.文献[27]提出的一种基于RNN的动态循环购物篮推荐模型DREAM,不仅学习用户的动态表示,还捕捉了购物篮间的全局顺序特征.近年来,注意力机制和图神经网络等方法也被用于序列推荐.例如文献[28]基于带注意力机制的图神经网络和长短期记忆网络,提出了一种结合用户长短期兴趣与事件影响力的序列推荐模型.文献[29]提出了可以准确建模会话中用户意图的SHARE模型,通过为每个会话构建超图注意力层,灵活地聚合上下文信息来推断用户的整体意图和当前兴趣.文献[30]提出了一种基于图表示学习的会话感知推荐模型GESP,并在构建物品关系依赖图的基础上利用BiLSTM进行特征抽象来更好地捕获用户兴趣变化.
虽然通用的序列推荐方法研究较为丰富,但是绝大多数方法都忽略了用户重购行为的影响,考虑用户重购行为的产品推荐方法相对较少.已有重购推荐方法主要从时间层面(时间变化、短期依赖、周期性等)、用户层面(动态偏好和静态偏好、长期偏好和短期偏好)和产品层面(新产品的探索和重复产品的保留)开展了一定研究.
1)时间层面.鉴于时间动态变化在重复消费建模中的重要作用,文献[4]提出了一种将Hawkes过程引入协同过滤的新模型,该模型能够明确处理2个特定产品的时间动态性,即短期效应和长期效应.文献[31]通过分析真实世界中人们的行为序列,发现人类重复行为呈现3种时间模式,分别是时间变化、短期依赖和周期性.这3种模式可以分别由高斯混合分布、指数衰减函数和威布尔分布模拟.基于此,该研究将用户行为建模为一个基于3因素时间变化强度的多元时间点过程,将模拟的3种时间模式分布融合到Hawkes过程中.总体来看,已有文献虽然探索了用户在单个产品使用周期内的动态偏好机制,但它们普遍假设产品使用周期结束时用户会再度恢复之前对它的兴趣,从而忽略了用户重购偏好随重购次数变化的动态影响.
2)用户偏好层面.文献[32]区分用户的动态偏好和静态偏好,提出了一种基于用户行为特征的、考虑时间敏感性的个性化成对排名TS-PPR模型来进行重购产品推荐.TS-PPR通过学习从可观测空间中的行为特征到潜在空间中的偏好特征的映射,将时间上的用户-产品交互行为分解,并将用户的静态和动态偏好纳入推荐中.文献[33]认为用户的需求可以分为长期需求和短期需求,提出了一种新的自注意力连续时间推荐模型CTRec来捕捉用户需求的变化.具体地,CTRec利用卷积神经网络捕捉短期需求,使用自注意力机制从用户的周期性购买间隔中捕捉长期需求.总体来看,已有文献虽然建模用户对产品的动态需求,但未考虑产品重购与换购的概率问题.
3)产品层面.文献[34]同时考虑了新产品探索和重复产品保留问题,提出了RepeatNet模型,将重复探索机制集成到神经网络的编码器-解码器中.具体地,RepeatNet包含2个推荐解码器,即重复推荐解码器和探索推荐解码器,可以结合2种模式的切换概率和每个物品的推荐概率来确定物品的推荐得分.考虑到用户购买的产品之间存在多种关联,还有研究从产品组合层面进行下一篮子重购产品的推荐,分析不同产品间的依赖关系、购买频率、时间趋势等对重购行为产生的影响[35-36].例如,文献[37]针对电商平台场景,探索了用户回购周期中产品间相关性等关键模式,并基于这些模式提出了一种新的超网络架构模型,以实现下一篮子重购产品的推荐.文献[38]从购买频率的视角,重点关注了每个用户对产品的个性化偏好和购买频率相似性,提出了一种基于个性化产品频率信息的下一篮子推荐方法.文献[39]提出了下一篮重购产品推荐的ReCANet模型.该模型基于用户购买记录中的相邻两次重购间的购物篮间隔数量来挖掘用户购买的近期性以及用户相似性、物品相似性等重购行为模式进而进行产品推荐.总体来看,已有文献主要基于产品基本属性和产品间的依赖关系对用户重购偏好进行建模,普遍忽略了用户重购偏好动态变化和上下文场景变化的影响.
综上所述,现有研究多从时间序列、用户或产品的某一维度出发,少有同时优化3个维度信息的重复购买推荐模型,且普遍忽略了用户重购动态偏好和上下文场景变化的影响.鉴于此,本文基于注意力机制和指针生成网络,对产品特征、用户偏好和时间序列模式3个维度进行优化和建模.具体地,本文采用注意力机制建模产品间的关系,基于信息处理理论构建S型的用户重购动态偏好,融合LSTM模型和指针生成网络对重购行为的时间序列模式进行高度提取,并考虑产品流行度信息进行重购产品和新产品的混合推荐,从而进一步提升了模型的准确性和可信性.
2 方法描述
2.1 基本定义
本文要解决的问题是在已知用户购买历史记录以及用户下一时刻要购买的产品类别的条件下,为用户进行产品推荐,以满足用户需求,其中,被推荐的产品可能是用户购买过的产品也可能是新的产品.另外由于用户实际可能会同时购买多个产品,在此情况下,我们考虑将用户同时购买的产品视作一个购物篮,进一步学习产品间关系和用户偏好.
问题具体定义为:U表示所有用户,C表示特定产品类别.对于每一个用户u∈U,收集他的历史重复购买C产品类别的记录.每条记录都包含了用户信息(用户ID、重复购买次数等)、产品信息(产品ID、产品价格、产品折扣、购买数量)和时间信息(购买时间).本文将基于这些记录信息,为用户推荐用户下次可能购买的产品i,其中i∈C.
2.2 用户重购偏好分析
基于信息处理理论,我们认为用户对同一产品的消费偏好随时间推移通常会经历3个阶段,即重购期、拓展期和均衡期.在重购期,由于消费者对该类产品不熟悉,需要处理大量候选产品信息来决策,易产生信息过载,购买不确定性风险较高.在此期间,用户倾向于重复购买相同产品,一方面以降低信息处理成本和消费不确定性,另一面以满足自身的探索欲以期发现该产品更多特点与功能.在拓展期,用户不断接受外界新的信息,对产品认知和偏好发生变化.此时,用户对新产品产生兴趣,对重购产品的偏好降低,用户可能减少对重购产品的消费,发生购买转换行为.在均衡期,用户经过前期探索,对该类产品非常熟悉,从而产生过度自信而停止新产品探索.该现象在单位价值不高、用户不愿投入过多精力的快速消费品消费中尤为明显.此时,用户倾向于在已购买过的产品中重复选择购买,对产品的重购偏好再次复苏.
以购买牛奶为例,在重购期,用户初次购买某品牌牛奶后,若认为其品质较好,则很可能会进行重复购买,以满足个人需要;在拓展期,由于多次重购而产生厌倦心理、新的替代品出现等原因,用户对该品牌牛奶的偏好会降低,这时会尝试购买其他牛奶类产品;在均衡期,用户对牛奶类产品较为熟悉,停止尝试和探索,转而在购买过的产品中重复购买,此时用户对原品牌牛奶的兴趣将再度上升.
进一步,我们在实验数据集上,使用数据分析和回归分析方法对上述理论假设进行验证,相关结论有效支持了用户重购偏好的S型变化趋势,详见3.2节.因此,本文定义了S型公式来刻画这种重购偏好趋势:
其中 α,β,δ 是可学习的参数,λ1,λ2是超参数,α,λ1越大,曲线的第1个峰值就越高,低谷值就越低.β越大,曲线的低谷值就越低,再次上升的速度就越慢.λ2越大,曲线的第2个峰值就越高.q是时刻t用户u购买产品i的次数,f′(q|u,t,i)是f(q|u,t,i)的导函数.F(q|u,t,i)是f′(q|u,t,i)和f(q|u,t,i)的合成函数,表示时刻t用户u对产品i的重购偏好.该式(1)(2)可生成如图1所示的曲线,其曲线函数可以基于不同的超参数刻画具有不同峰值和低谷值的趋势.
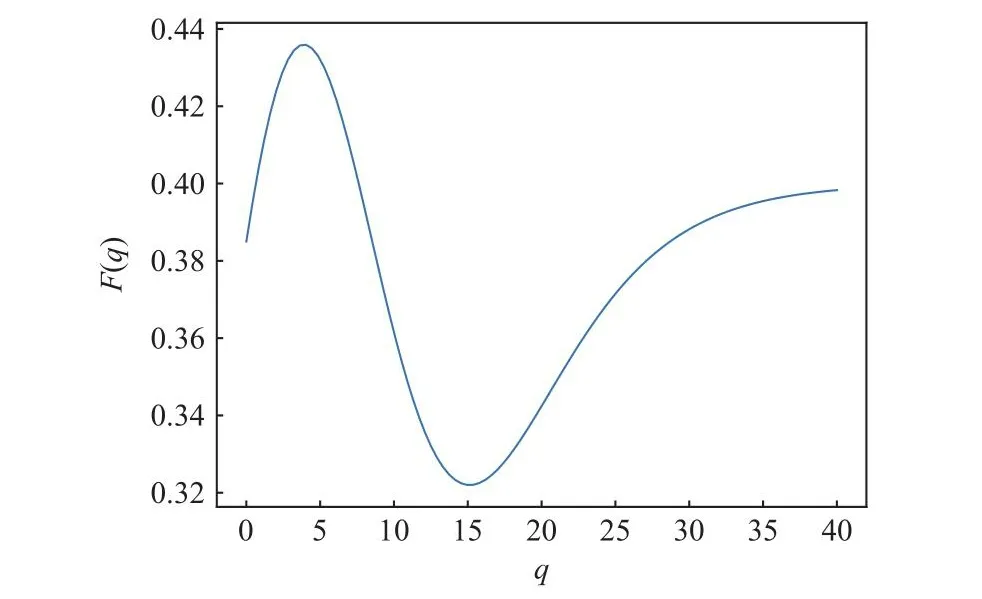
Fig.1 Trend of user’s repurchase preference varies with the number of repurchase图1 用户重购偏好随重购数量变化的趋势
2.3 用户新颖消费偏好分析
虽然用户倾向于对特定的产品表现出“忠诚度”,但这并不意味着他们每次访问店铺都会购买这些产品.因而除了考虑用户本身的动态偏好变化外,本文将所有产品的流行度作为上下文场景的约束条件,不同时间段下不同产品的流行度反映了产品的更迭与替换.例如,当用户对于重复购买的产品产生厌倦时,可能会选择购买流行度更高的产品.本文首先定义了产品的流行度,其次采取了对数幂律分布对其处理以更好地对模型进行训练.相关公式为:
其中,λ和γ是超参数,n是用户的总数,△t表示距离时刻t的天数.B(i)表示购物篮B中 产品i的总数量,表示距离当前时刻t范围内产品i的总销量.表示进行对数幂律分布处理后的结果.
2.4 多层信息融合的重购推荐方法
本节将详细介绍提出的重购推荐方法,整体结构如图2所示.该方法从下向上主要包含“产品—购物篮—时间序列”层次的内容:基于重购特征的产品编码;考虑产品流行度的购物篮编码;考虑时序特征的重购推荐.
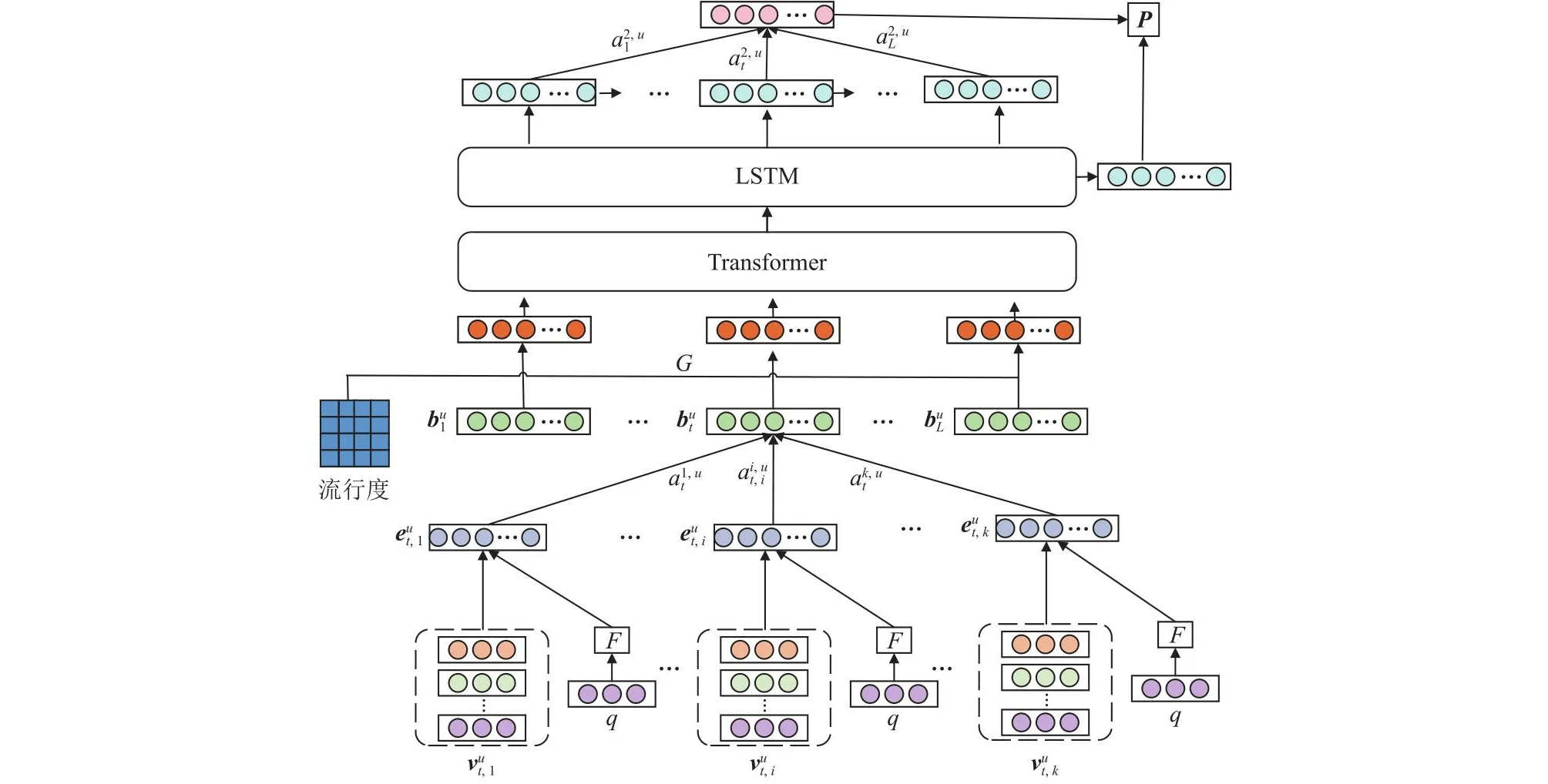
Fig.2 Repurchase recommendation method based on multi-level information fusion图2 基于多层信息融合的重购推荐方法
2.4.1 基于重购特征的产品编码
该模块的目的是整合产品属性和用户重购行为特征,将注意力机制得到产品的初始表征用于后续阶段的产品推荐.
1)产品嵌入表征.首先将每个产品i的ID表示为one-hot向量.其次,将产品价格、折扣、数量进行全连接映射处理.最后,考虑到用户可能会同时购买多个产品,将用户同时购买的多个产品看作一个购物篮.那么,用户u在时刻t购买的同类产品组成的购物篮可以表示为一个初始表征其中包含产品ID的one-hot编码,以及产品价格、折扣与数量、购买时间的嵌入表示.本文使用k表示购物篮中特定类别产品的最大长度,对于长度小于k的购物篮,进行了零向量填充.
2)重购效应.基于信息处理理论,用户重购偏好随时间变化会经历重购期、拓展期和均衡期3个阶段,因此用户重购动态偏好是复杂的S型曲线,这一现象也在本文所使用的数据集上得到验证.为了突出用户u在时刻t对产品i的重购偏好,我们利用式(5)对产品i进行了重购偏好提取,具体为:
其中q表示用户u在第t个购物篮之前已经重复购买产品i的次数.F(q|u,t,i)则是重购次数q的效应函数,通过该函数,可以获得用户u在时刻t对于产品i的重复偏好度.表 示在产品基本属性表征的基础上融合了用户u在时刻t对产品i的重复偏好表征.由于用户在不同时刻购买的产品不同,且重购的次数也不同,因而通过序列编码以及重购效应映射,可以在产品层面捕获用户在不同时刻的重购偏好变化.
3)考虑到用户对同时购买的多种产品具有不同的偏好程度,使用注意力层来学习同一购物篮中不同产品的权重,公式为:
2.4.2 考虑产品流行度的购物篮编码
该模块的目的是融合产品流行度信息,进一步捕获用户对产品的动态偏好,并利用Transformer编码器进一步优化购物篮表征.引入Transformer编码器一方面可以更好地捕获购物篮序列间的关联关系和特征交互以提高模型的泛化能力,另一方面还可以减轻输入序列中的信息噪声以增加模型的鲁棒性.
1)流行度效应.考虑到产品流行度影响消费者的购买行为,本文将当前时刻各个产品最近30天内的流行度作为推荐下一产品的上下文场景约束条件,因而基于式(3)(4),利用式(8)对购物篮的潜在表示进行约束.具体公式为:
其中M表示C类产品的总数.WG表示对流行度G(t,i)进行线性变换的权重矩阵,则是融合流行度效应后的购物篮表征.
2)Transformer编码器.本文使用具有多头注意力机制的Transformer Encoder对输入序列中的购物篮表征进一步进行编码.Transformer Encoder由多个具有相同结构的子模块组成,每个子模块都由3个网络层组成:
①多头注意力机制.该机制允许模型在输入购物篮表征序列bu′时,对不同位置之间的依赖关系进行建模.它将输入序列bu′分别映射到多个注意力头,每个头都可以学习到一种不同的关注权重分布.这样,模型可以从多个角度同时关注输入序列bu′的不同部分,提取丰富的特征信息.具体来说,给定购物篮输入序列bu′,那么利用可学习的权重矩阵W∈Rd×dq,qWk∈Rd×dk,Wv∈Rd×dv, 多头自注意力机制可以将bu′映射到不同的子空间,公式为:
②归一化层.它对上层的输出Hu进行归一化,使得模型在不同层之间更容易进行信息传递和学习.这一层包含了2个操作:一个是将输入的数据和多头注意力层结果相加,以减少信息的损失和防止梯度消失等;另一个则是对同一层网络的输出进行标准化处理,以加快收敛,公式为:
③前馈神经网络层.该前馈神经网络层包含2个线性变换和1个非线性激活函数,用于对上层输出进行非线性变换和特征提取.具体操作可表示为:
除了这3层操作外,Transformer Encoder还为每一步的输入添加了位置编码特征,对序列中不同位置的进行建模,使得模型能够区分和关注不同位置的元素.最后得到了Transformer编码表征,其中Pou是bu′序列中各个购物篮在序列中所处的位置编码.
2.4.3 考虑时序特征的重购推荐
为了更好地捕获购物篮序列间的依赖关系,本文将Transformer编码器输出的表征Hu,d进一步输入到一个双层单向的LSTM网络以提取用户在不同时间的隐状态表征并保留最后一个购物篮的隐状态输出表征st,公式为:
由于我们使用的是滑动窗口生成的样本数据,Hu,d∈RL×db表示的是通过Transformer融合了相对位置编码的购物篮序列表征.其中L是序列长度,即购物篮的数量,db表示每一个购物篮表征的嵌入维度.为了进一步提取用户随时间动态变化的购物篮表征,我们利用式(14)得到了新的序列表征Hu,s∈RL×dl,其中dl表示经过LSTM处理后的每一个购物篮的表征嵌入维度.Hu,s是从购物篮层面对用户在不同时刻的偏好变化的进一步挖掘.
鉴于顾客可能会重复购买先前购买过的产品,以及考虑到指针生成网络的复制机制可以使模型能准确地复制先前购买过的产品,而不仅仅是生成新的产品预测结果[6].因而,本研究借鉴了指针生成网络的最后一个时间步操作以预测顾客下一时刻购买重复产品或新颖产品的决策.此外,具有注意力机制的指针生成网络可以明确指示出预测出的重复结果来源于输入序列中的哪一个购物篮,这将有助于增加预测结果的可信性.具体操作为:
其中向量V,Va,Vb,WH,Ws,WH*,Ws*和标量batt,bitem,b′,bgen都是可学习的参数.σ是sigmoid函数.表示当前序列中第t个购物篮的注意力权重.pu表示所有产品可能被消费者购买的概率分布.pgen表示用户即将选择消费新产品还是重复产品的概率.
那么下一次不同产品被消费的概率p(x)为
其中,p(x)表示最终预测的所有产品对应的概率分布,既包含用户已消费过的产品,又包含用户未消费过的产品.如果产品i没有出现在历史购物篮记录中,则最后,模型多标签分类损失函数的计算公式为:
其中y和p(x) 都是向量,y表示在所有产品中顾客下次购买产品对应的标签.yj和p(xj)表示y和p(x)向量中的第j个值,M表示所有产品ID的数量,即C类产品的总数.
3 实 验
3.1 数据集
为了证明模型性能,本文在真实的数据集Dunnhumby上进行了一系列实验.Dunnhumby数据由一家全球领先的消费者科学公司提供的,其中包含了全球2 500个家庭在2年内的购买数据.本文分别提取出其中包含面包类和牛奶类产品的子数据集,数据统计结果如表1所示.为消除噪音数据的影响,在预处理阶段删除了购买记录少于15条或购买间隔超过100天的客户.最后在面包数据集中筛选出了1 394名顾客购买1 497个产品的消费记录以及在牛奶类数据中筛选出了1 629名顾客购买1 440个产品的消费记录.
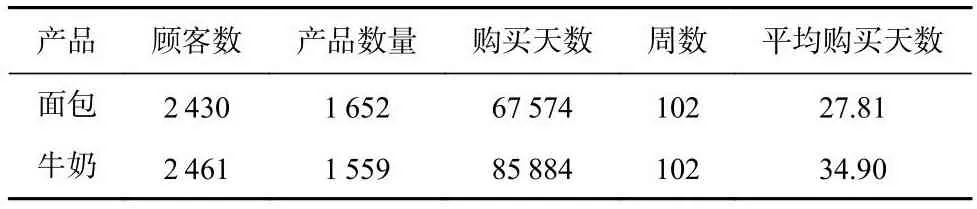
Table 1 Data statistics表1 数据统计
本文采用滑动窗口的策略以获取更多样本.举例来说,给定客户长度为N的购物篮序列,滑动窗口大小设为L,获得N-L+1条购物序列作为样本.对于每一条样本,将前L-1个样本作为训练集,第L个样本作为测试集.此外,使用 PyTorch 实现了所提出的模型,并将其部署在具有 12 GB 内存的 Titan RTX 上.设置学习率 η=0.001,批量大小为 256.
3.2 用户重购动态偏好的实证分析
本文基于信息处理理论,采用S型非线性函数来刻画用户重购偏好的动态变化规律.本文采用数据分析和回归分析方法来验证S型重购动态偏好假设的可靠性.首先从购买牛奶或面包数据集中中随机抽取一些用户,观测这些用户的重购行为随着时间的变化趋势.如图3所示,用户重购偏好的动态变化规律较为复杂,近似S型曲线.
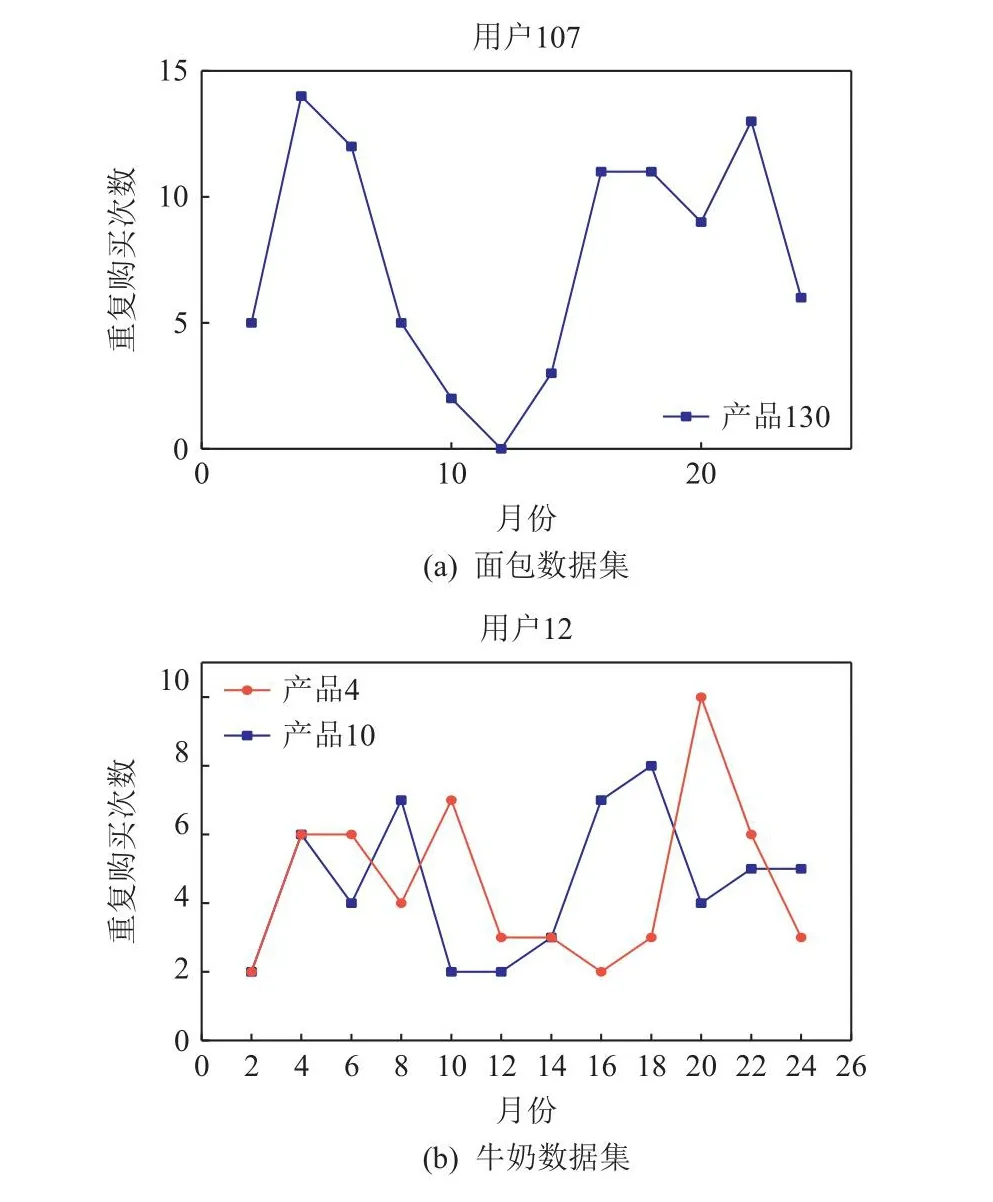
Fig.3 The change of repurchase quantity over time图3 重购数量随时间变化图
本文进一步采用回归分析方法对用户重购偏好的动态变化趋势进行分析.本文在面包类和牛奶类数据集的基础上,构建了“用户-天数”层面的面板数据.本文回归分析时,剔除了没有明显重购偏好的用户,即最大重购次数少于5的用户.
因变量为虚拟变量Repurchase,即用户当天是否重购产品.具体地,如果用户当天重购产品,Repurchase取值为1,本文将每个用户购买次数最多的产品作为重购产品;反之如果用户当天转换购买其他新产品,则Repurchase取值为0.
自变量Time为购买时间,用户第1天购买面包或牛奶产品时取值为1,第2天购买面包或牛奶产品时取值为2,依次类推.为了检验用户重购偏好的S型演变规律,本文还设置了购买时间的平方项(Time2)和立方项(Time3).本文重点关注变量Time3的系数,如果Time3系数显著为正,则说明用户重购偏好概率随时间呈S型变化趋势.
为了控制产品层面因素的影响,本文控制了产品价格(Price)、产品折扣(Discount)这2个变量.为了控制用户层面因素的影响,本文在回归模型中加入了用户固定效应.本文采用Logit模型进行回归,具体模型为:
回归结果如表2所示,在面包和牛奶2个数据集上,Time3的系数均为正,且在1%显著性水平下显著.表2结果说明用户重购偏好随时间呈S型变化,充分验证了本文用户重购动态偏好假设的可信性.
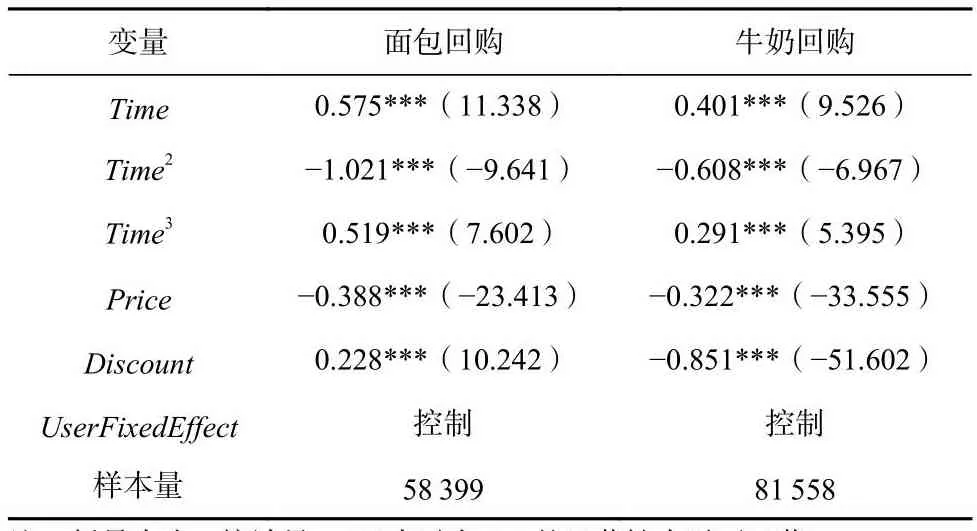
Table 2 Regression Analysis of User Repurchase Preference Trend表2 用户重购偏好趋势的回归分析
3.3 评估指标
为分析不同模型的表现,本文采用了3种广泛使用的评估指标Recall、Precision、NDCG对模型进行评估.
其中,TP表示模型预测结果与真实标签相同,且都为正类的数量.FN表示模型预测结果与真实标签不同,把真实的正类样本预测为反类的数量.FP表示模型预测结果与真实标签不同,把真实的反类样本预测为正类的数量.另外NDCG是DCG归一化的结果,IDCG则是理想排序下的折损累加值,即在推荐列表中按照真实标签的相关性得分进行理想排序后的DCG值.DCG和IDCG的计算公式分别为:
其中,relj为当前第j个位置的相关性得分,如果当前第j个位置的项目与用户的兴趣相关则relj=1,否则relj= 0.J是推荐列表的大小,REL表示真实标签的列表的前J个产品个数.在DCG中,relj是推荐列表中当前位置的相关性得分;而在IDCG中,relj是真实标签中当前位置的相关性得分.
3.4 对比算法
本文将所提出的方法与5个推荐算法在面包和牛奶2个数据集上进行对比.
1)Pop.Pop是一种简单且常用的推荐算法,它的基本思想是按产品的流行度将热门产品推荐给用户.
2)SHARE[29].SHARE是一种基于超图网络结构的推荐算法,利用用户历史会话信息,建立超图结构来描述用户行为,并通过超图注意力机制学习购物篮表示.
3)DREAM[27].DREAM是采用一种门控机制,可以动态地调整循环神经网络中权重的推荐算法.该算法不仅能够识别长期的购物行为趋势,还能够识别短期的购物行为演变.
4)RecaNet[39].RecaNet是一种在神经网络中融入了重复-探索机制的推荐算法.该算法可以通过2个并行的神经网络模块进行训练:一个用于预测用户可能购买的新产品,另一个用于预测用户可能再次重复购买的产品.
5)CLEA[40].CLEA是一种基于对比学习的推荐算法.该算法通过对比学习的方式,可以学习出对篮子中商品之间相似性的表示,从而减少噪声的影响.
3.5 实验结果及分析
本文根据常用设置,为每个用户选择top@5个产品进行产品推荐,即根据模型学习到的用户偏好,筛选出最符合用户偏好的5个产品作为推荐结果,并在此基础上与用户的真实购买产品进行对比,以评估模型的推荐效果.不同模型在数据集上的实验结果如表3和表4所示.
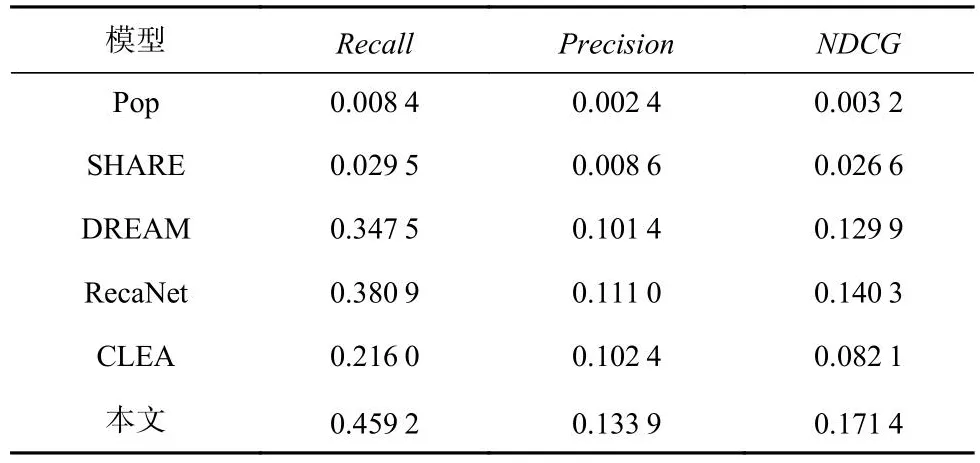
Table 3 Experimental Results on Bread Dataset表3 面包数据集的实验结果
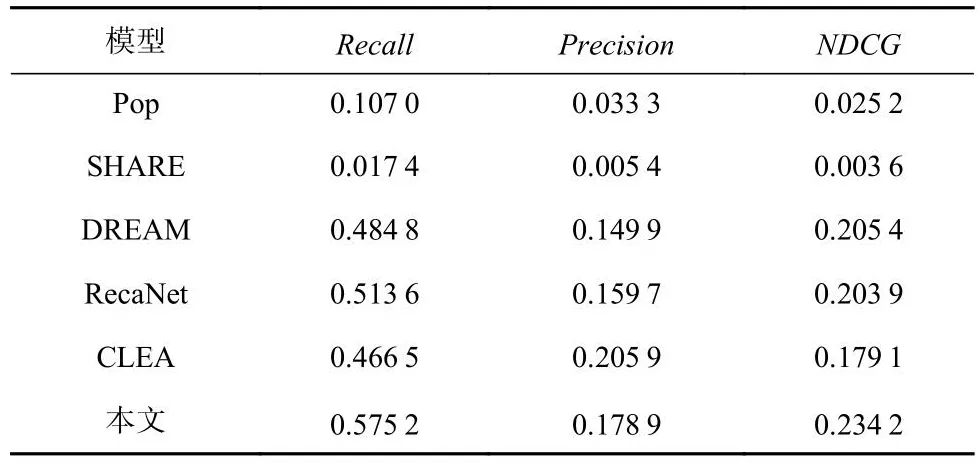
Table 4 Experimental Results on Milk Dataset表4 牛奶数据集的实验结果
由表3和表4中可以看出,本文所提出的模型在整体上优于其它对比算法,在Recall评估指标上的优势更加明显.在所有的指标中,Pop表现较差,其原因是Pop仅根据产品流行度进行推荐,忽略了用户的个人偏好信息,而用户的购买行为,尤其是重购行为,与个人偏好密切相关.SHARE通过建立超图结构,能有效识别购物篮内不同产品之间的关系,提高购物篮表征效果,但在用户重购行为分析与下一产品推荐方面效果较差,原因可能是SHARE更关注于同一篮子中产品关系的学习,忽略了用户重购行为中表现出的序列相关性.用户的重购行为具有一定的周期变化,忽略这一特性可能会造成不理想的推荐结果.DREAM考虑了用户不同购物篮之间的序列关系,通过对用户历史购物篮之间的相关性进行分析来得到动态的用户偏好.但是,DREAM在进行购物序列分析时同样忽略了用户重购行为周期性,仅利用RNN对历史购物篮序列进行特征学习和聚合,并将其作为用户偏好表征,因此,在本文的推荐任务中其效果劣于本文的模型.CLEA采用对比学习的方法识别出用户历史购物中更能代表用户偏好的产品信息,降低不相干产品的影响,进而提高下一产品的推荐效果.其能有效识别不同产品之间的关联,但无法识别用户重购行为中表现出的序列特征.与其他对比方法相比,RecaNet明确对用户的重复消费行为进行建模,利用LSTM学习用户购买行为模式,与SHARE、DREAM方法相比,RecaNet的效果提升证明了考虑用户重购行为规律对于下一产品推荐任务的重要性.本文在用户购买模式分析方面,采用了“S型曲线”对用户重购行为进行更为精确地描述,同时利用了Transformer和自注意力机制提高对用户偏好的学习效果;在产品特征学习方面,还引入了产品流行度特征,以识别用户对于新产品的偏好,因此,得到了更为优越的推荐效果.
通过图4将2个数据集的结果合并和可视化,发现考虑用户重购行为的RecaNet算法和本文方法在3个指标上的整体评估表现均优于其他基线方法,在一定程度展示了考虑用户重购行为在提升推荐准确性方面的重要作用.
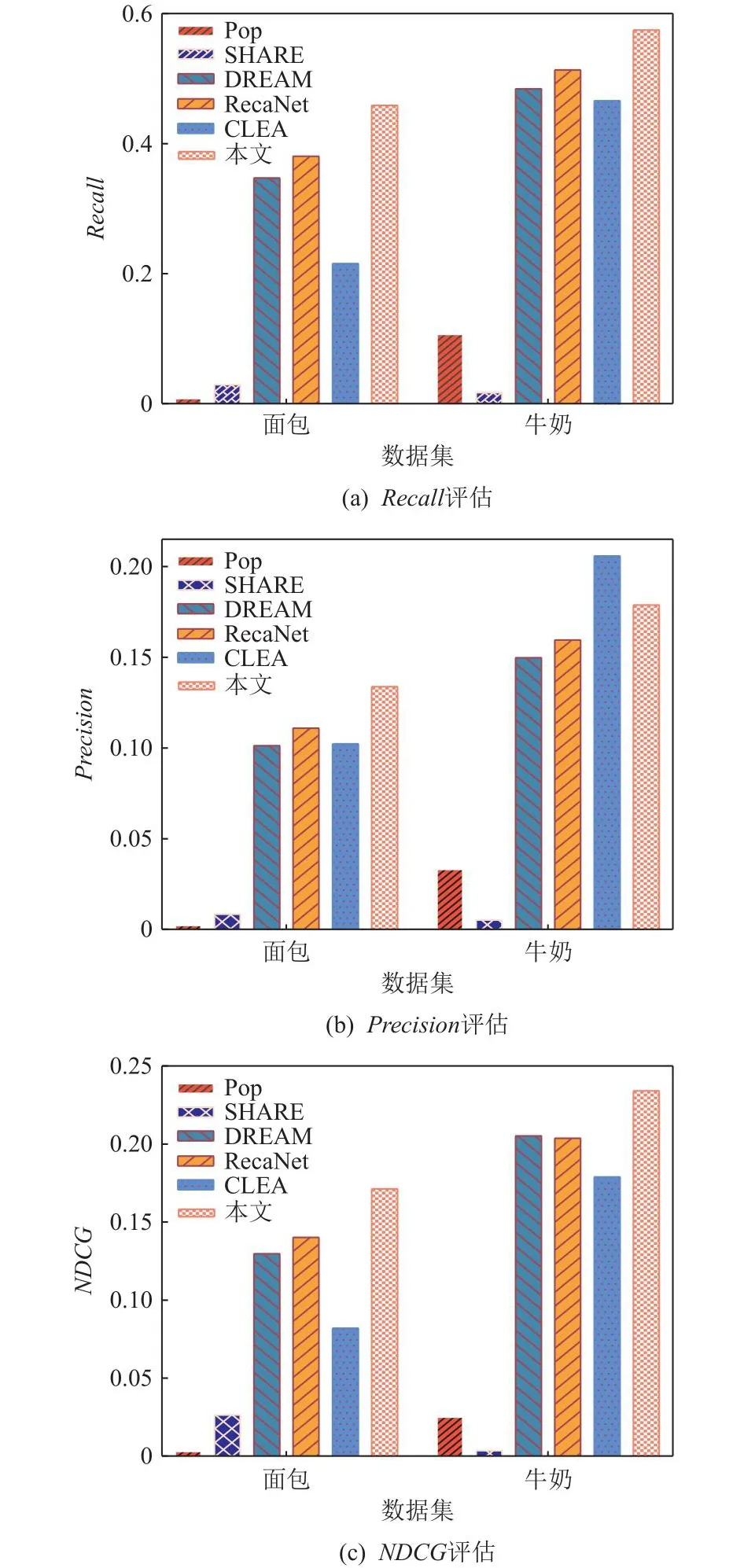
Fig.4 Comparison of our proposed method and other baseline methods图4 本文方法与其它基准方法的对比
3.6 参数敏感性分析
本节将分析超参数对所提出模型性能的影响.我们采用了网格搜索以寻求最优参数,重点讨论用户嵌入维度大小和滑动窗口大小对模型Recall表现的影响.
1)依次从8,16,32,64,128,256这些数值中选取一个值来改变用户嵌入维度大小,本文方法的预测表现如图5(a) 所示.从图5(a)中可以看出,Recall在2个数据集中表现出不同的趋势.具体来说,在面包数据集上,用户嵌入维度取值较大时,模型的Recall表现越好,而在牛奶数据集上则呈现相反趋势.因此,将用户嵌入维度大小在面包数据集上设置为128,在牛奶数据集上设置为8.
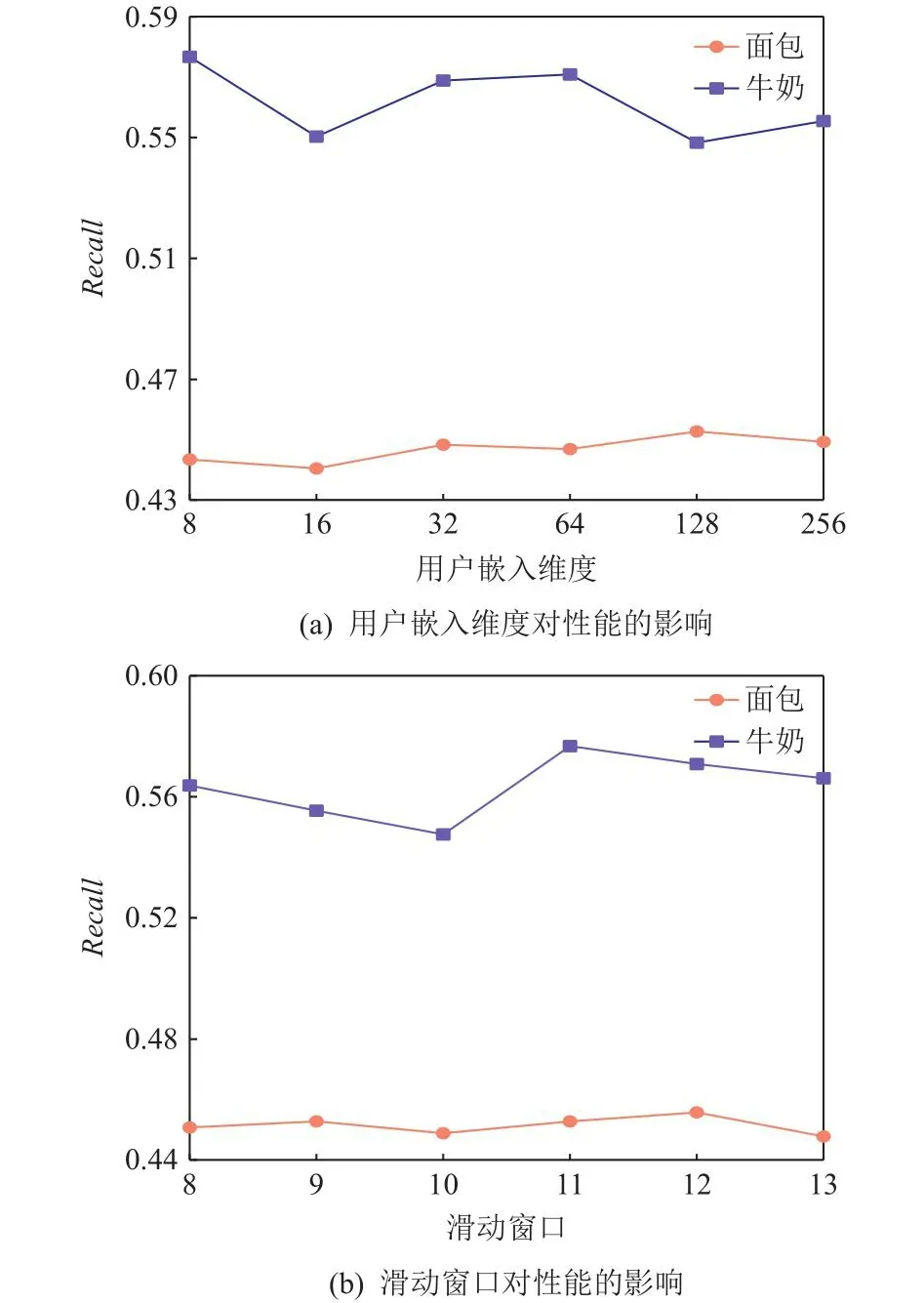
Fig.5 Parameter performance variation diagram图5 参数性能变化图
2)设置滑动窗口的大小介于8~13.本文方法在Recall上的结果如图5(b)所示.观察可知,当滑动窗口大小介于11~13时,本文方法的评估表现都相对较好.结合其它指标的表现,分别设置面包数据集和牛奶数据集上的滑动窗口大小为13和11.
3.7 可解释性分析
本文提出了具有双层注意力机制的用户重购行为推荐方法,下面将对本文方法学习出的注意力权重进行分析,以进一步阐述模型的可解释性.从面包和牛奶数据集中分别选取一个用户在某一天的购买记录,并对其购买产品的注意力权重进行可视化展示,如图6所示.图6中的横坐标表示“已重购次数-产品ID”,如“2-117”表示该用户已购买2次ID为117的产品.纵坐标为注意力权重,是模型为每个产品分配的注意力值,颜色越深表示权重越大,即该产品对后续预测的重要性越大.通过图6可以发现,本文方法对重购次数较高的产品分配了较高的权重,这说明用户重购行为在产品推荐中起到重要作用,也为模型预测结果提供了可解释性的依据.
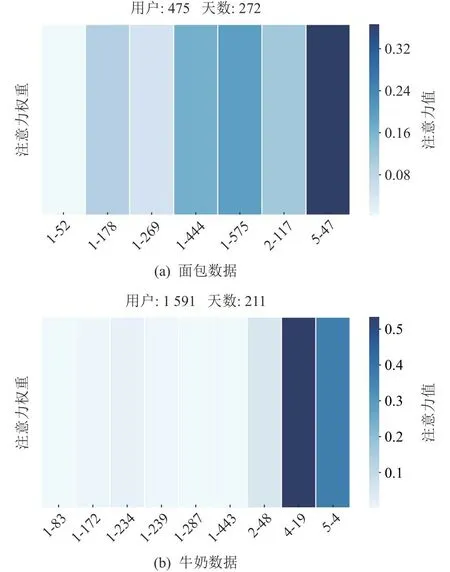
Fig.6 Attention weight heat map图6 注意力权重热力图
4 结 论
本文针对在线快速消费品零售场景,提出了一种基于用户重购行为的产品推荐方法.所提方法具有3方面的特点:1)融合多层次用户偏好信息,提出具有双层注意力机制的用户重购行为推荐方法,进行重购产品和新颖产品的混合推荐;2)基于信息处理理论,采用S型曲线拟合用户重购偏好的动态趋势,准确刻画用户对特定产品的重购兴趣;3)在用户新兴趣的识别方面,利用嵌入方法捕捉当前时刻各个产品的流行度趋势,对上下文场景进行了一定的约束.本文的研究为充分识别用户消费行为规律,提高产品推荐效果提供了参考和借鉴,同时,利用多层注意力机制和消费者信息处理理论,增强了模型在结构和理论上的可解释性以及推荐结果的可信性.
但本文的研究仍然存在一定的局限性,如尚未充分探索产品的价格折扣如何影响用户的重购行为,以及尚未分析不同类型用户的重购行为差异,而在真实的消费环境中这些因素都将影响用户的消费行为;此外同类产品间也存在一定的竞争关系,对这些影响因素的探讨将在后续的工作中进行.
作者贡献声明:耿杰和刘春丽提出算法思路和实验方案并定义实验和撰写论文;魏雪梅、程明月负责完成实验并撰写论文;袁昆、李洋、刘业政提出指导意见并修改论文.
