面向亚热带丘陵区小流域土壤有机碳空间预测的四种模型构建及性能比较
2023-08-12王志远汤哲周萍赖佳鑫戴玉婷周林王玉婷陈港明姜雨辰郭晓彬吴金水
王志远,汤哲,周萍,赖佳鑫,戴玉婷,周林,王玉婷,陈港明,姜雨辰,郭晓彬,吴金水
(1. 中南大学计算机学院,湖南 长沙 410083;2. 中国科学院亚热带农业生态研究所,亚热带农业生态过程重点实验室,长沙农业环境观测研究站,湖南 长沙 410125;3. 北京邮电大学计算机学院,北京 100876)
土壤有机碳(SOC)含量是衡量生态系统生产力和生态服务功能的关键指标,在提升土壤肥力与农业可持续利用以及减缓全球气候变化方面至关重要。土壤有机碳的精准预测有助于精确评估区域乃至国家尺度土壤碳库储量,从而助力区域碳中和目标的实现,具有突出的科学意义[1]。
计算机模拟是预测土壤有机碳含量变化与分布的关键手段,国际上建立了诸多土壤有机碳过程模拟模型(Roth-C、CENTURY、DNDC等)。由于SOC含量与诸多环境因素密切相关,对土壤条件、空间分辨率、气候、水文、植被、地形地貌等环境条件的变化十分敏感[2],而现有的过程模型模拟主要涉及到碳输入量、部分气候和土壤属性(如粘粒含量)等参数,对其他环境变量的关注较小,导致不同区域和生态系统的过程模拟存在较大的不确定性,区域应用存在局限性[3]。
机器学习在处理数据方面具有固有的优势,在SOC预测中具有很强的泛化性,也比传统的数字化测绘方法更加敏感,可以较好地模拟SOC和环境协变量之间复杂的、非线性的关系,提升区域SOC含量预测的准确性[4-6]。并且在样本数并不丰富的情况下,机器学习模型仍然表现出很强的适用性[7]。比如Emadi等[6]使用不同机器学习模型对伊朗东北部SOC含量预测的研究表明,机器学习模型在SOC预测中具有很强的适用性。Khaledian和Miller[8]总结了近几年来关于SOC的机器学习方面的研究认为,人工神经网络(ANN)在预测SOC含量方面具有强有力的表现,但是随机森林(RF)比ANN更快,其结果也趋于更好的鲁棒性,并且RF和立体派模型(Cubist)克服了ANN对小数据集敏感和完全是黑箱模型的弱点。由此可见,基于机器学习模型提高SOC空间模拟精度的研究已具备一定基础,但是在小流域尺度上如何对复杂地形地貌条件下的SOC含量开展精确预测仍然存在较大挑战。
亚热带丘陵区地形变化复杂,相关地形地貌和土壤环境的空间异质性很大,目前已有基于传统机器学习模型(如RF、支持向量机回归SVR)预测复杂地形地貌区SOC含量的少量研究,且不同机器学习模型的表现具有明显的差异性[9-10]。而关于极端梯度提升算法(XGBoost)和轻量级梯度提升机(LightGBM)对亚热带丘陵地貌区SOC的预测性能尚未有过尝试。由于XGBoost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,从而大大提升算法的效率。LightGBM模型则采用了直方图算法将遍历样本转变为遍历直方图,极大的降低了时间复杂度,同时也降低了内存消耗。因此很有必要对XGBoost和LightGBM模型预测复杂地形地貌区SOC含量的性能进行评价。基于此,本研究以亚热带丘陵区一个具有复杂地形地貌特征的小流域为对象,结合地形、气候、植被等环境变量的输入,以传统的非集成机器学习模型SVR与传统的RF模型作为对比,分析XGBoost和LightGBM模型对土壤表层(0~20 cm)SOC含量预测的可能性,评估不同机器学习模型在亚热带丘陵小流域SOC预测中的性能差异,以期为复杂地形地貌区SOC含量的精确预测提供理论基础。
1 材料与方法
1.1 研究区域概况
研究区位于湖南省长沙县金井镇(112°56′~113°30′E、27°55′~28°40′N),面积约134.40 km2,其中耕地面积为23.13 km2。地貌类型以丘陵为主,海拔介于56~440 m。研究区域属亚热带季风气候;多年平均气温17.2 ℃;年平均降水量1360 mm。金井镇境内河道属湘江水系,有金井河流经境内。土壤类型主要为花岗岩和板页岩风化物发育的红壤和水稻土。土地利用类型以水田和林地为主,林地主要以马尾松、杉木等人工林和灌木、草丛群落为主,常绿阔叶林的覆盖率相对较低。
1.2 土壤样品采集与分析
于2009年8月根据流域内地形分布情况,按各高程段样点大致均匀、随机取样的原则布置采样点(图1)。每个样点以GPS定位点为中心,5 m为半径的样方取样,采用土钻随机采集5~8个表层土样(0~20 cm),混匀作为一个土样,共采集601个土壤样品。所有土样置于室内通风处自然风干,并剔除石子、植物根系等。风干土样过0.25 mm筛后供SOC含量的测定。具体的土壤采样与分析方法详见刘欢瑶等[11]的研究。
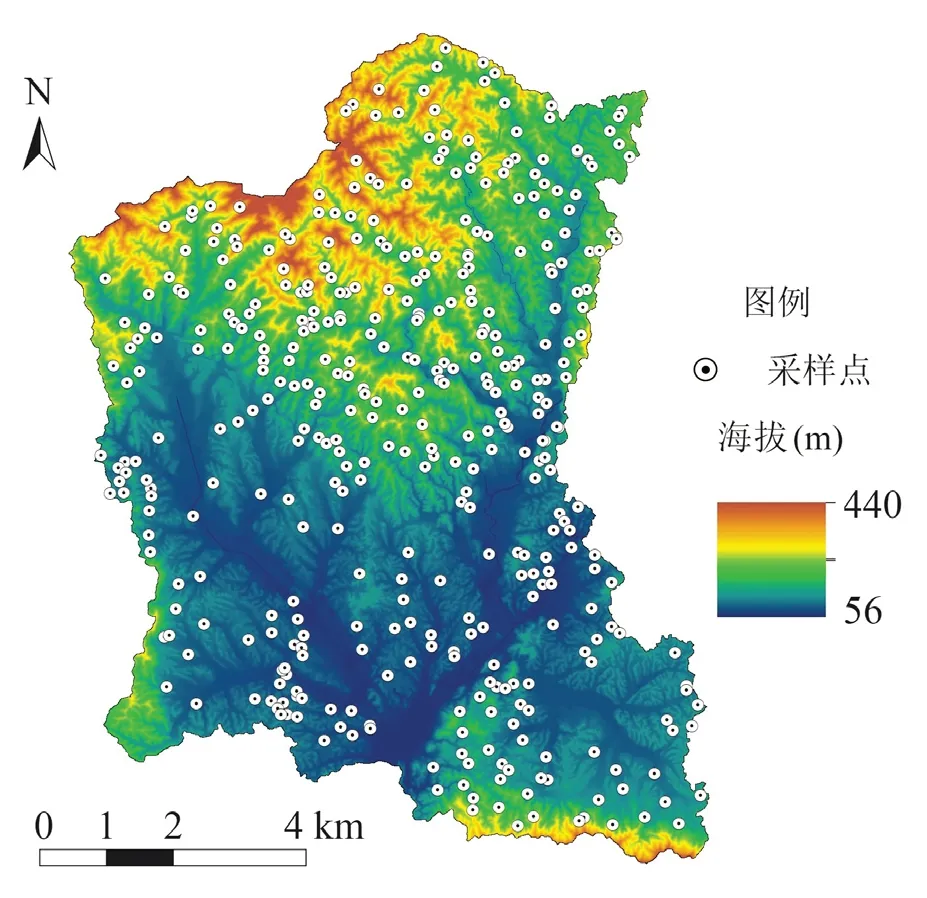
图1 研究区域与采样点分布Fig. 1 Study area and distribution of sampling points
1.3 环境变量的选择与提取
本研究选取地形、气候和植被三类环境变量作为模型输入参数。地形变量包括海拔、坡度、地形湿度指数等。由于气温随海拔和坡度坡向的改变呈现较大的差异,而降雨量在流域内差异不大,因此本研究将气温作为气候变量纳入环境变量指标。植被变量包括归一化植被指数,相对植被指数等。所有环境变量的提取来源于从中国科学院地理科学与资源研究所(https://www.resdc.cn/Default.aspx)下载的数据和从美国地质调查局(https://earthexplorer.usgs.gov)下载的landsat 5卫星图像数据。除气温的精度是100 m外,其他环境变量的精度都是30 m。使用ArcGis 10.8对气温变量进行重采样至30 m。除了相对植被指数(RVI)外,所有下载的环境变量数据经ArcGis 10.8处理后,采用近邻抽样法提取到样点所在位置的变量。Hengl等[12]的研究描述了所有环境变量的提取方法。具体环境变量的使用情况与介绍见表1。
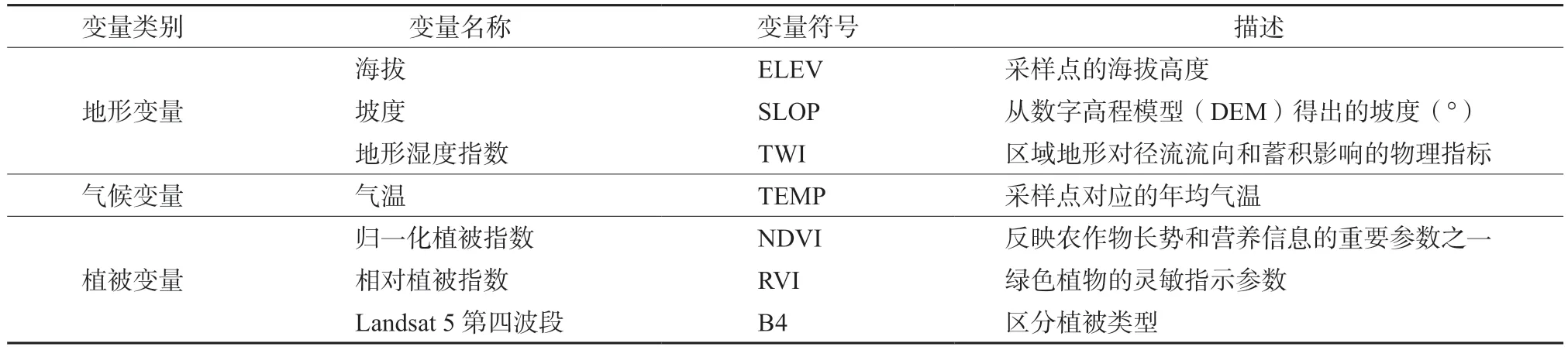
表1 样本变量特征表述Table 1 Description of sample variable characteristics
RVI最早由Jordan[13]提出,其计算方法为:
式中:NIR为红外波段值,RED为红色波段值。
1.4 机器学习模型
本研究采用XGBoost和lightGBM两种机器学习模型进行SOC预测,并与传统的RF模型和SVR非集成学习模型进行对比。所有模型均基于python3.7实现,其中RF和SVR模型来自于sklearn包,XGBoost模型来自于xgboost包,LightGBM模型自于lightgbm包。
RF是基于决策树的机器学习算法[14],常用于回归分析问题。该模型是由多个决策树组成的集成学习模型,通过对每个决策树的预测结果进行平均或加权平均来得出最终的预测结果。随机森林回归在构建每个决策树时,会随机选择一部分训练样本和一部分特征进行训练,以此来避免决策树的过拟合问题,提高模型的泛化能力。
SVR是一种基于统计学习理论的回归分析方法,通过寻找最优超平面,将数据映射到高维空间中进行非线性回归预测。SVR的核心思想是通过寻找最优超平面来最小化预测误差。在SVR中,最优超平面是指能够将预测值与真实值之间的误差最小化的超平面[15]。
XGBoost是一种基于决策树的梯度提升(GBDT)算法[16-17],GBDT在训练新的基学习器时只使用了损失函数的一阶导数,而XGBoost则对损失函数进行二阶泰勒展开,同时使用损失函数的一阶导数和二阶导数,此外,XGBoost还在损失函数中加入了正则项来控制模型的复杂度,有利于防止过拟合。XGboost可以自动处理缺失值、自动调整每个弱学习器的参数、自动调整每个弱学习器的深度,以便模型更好地拟合数据。
LightGBM是一种基于决策树的高效算法,是一种梯度提升机(GBM)的改进版本,用于提高机器学习算法的准确性和效率[18]。LightGBM的工作原理如下:使用基于树的算法来构建模型,并使用梯度提升算法来优化模型的准确性。LightGBM支持并行训练,可以更快地构建模型;支持自动调整参数,可以自动调整模型的参数,以获得更好的性能;支持多种数据类型,可以处理稀疏数据以及类别特征。
1.5 数据集切分
在进行实验之前,对601个样本进行了处理,剔除掉无效样本和异常值,最后剩下401个样本点作为输入。为了评估不同模型对SOC预测的适用性,基于sklearn软件包将数据集随机分为训练集(80%)和测试集(20%)。每个模型都用训练数据进行拟合,用实验数据进行验证。每个模型的训练数据集都采用10倍的交叉验证。
1.6 模型参数调整与模型评估
模型的超参数优化采用RandomSearch[19],在超参数的组合空间中进行随机采样和搜索,其搜索能力取决于设定的采样次数(n_iter参数)。RandomSearch的搜索过程如下:对于搜索范围为分布的超参数,按照给定的分布随机采样;对于搜索范围为列表的超参数,在给定的列表中以中等概率采样;如果给定的搜索范围为全部列表,则不放回采样n_iter次数。
模型评估采用决定系数(R2)、平均绝对误差(MAE)、均方根误差(RMSE)和林氏一致性相关系数(Lin’s Concordance Correlation Coefficient,LCCC)四个指标来确定模型的模拟性能。R2反应了因变量的波动有多少百分比能被自变量的波动所描述,R2接近1表示模型完美,即100%的变异被模型解释,大于0.75时表示良好预测,0.50~0.75之间表示可接受的预测,小于0.50表示不可接受的预测[20]。MAE可以避免正负误差相加出现相互抵消的问题,因而可以准确反映预测误差的大小。MAE值越接近0,说明模型的预测能力越好。RMSE可以评价数据的变化程度,RMSE值越接近0,说明模型的预测能力越好。LCCC结合了精度和偏差两个度量。LCCC的取值在(-1, +1)之间,+1表示完全一致,大于0.9表示接近完全一致,0.8~0.9之间表示实质性一致,0.65~0.8之间表示中等一致,小于0.65表示差一致[21]。四个指标的计算方法为:
式中:n表示样本量,ai为第i个样本的SOC含量预测值,bi是第i个样本的SOC含量实测值,k是所有n个样本预测值的平均值,h是所有n个样本实测值的平均值,θa和θb分别是n个样本预测值和实测值的变异系数,r是实测值和预测值之间的皮尔逊相关系数。
2 结果与分析
2.1 土壤有机碳数据集统计特征
根据实测的SOC数据分析显示,SOC含量变化范围介于1.47~39.37 g/kg,平均值为12.27 g/kg,标准差为6.62 g/kg。偏度为0.99,峰度为1.57(表2),整体分布近似于正态分布,适合训练机器学习模型。SOC的变异系数为54%,属于中等变异性类。由于研究区域地形多变,区域植被呈现一定的垂直分布特点,此外土地利用方式也存在差异,导致样本点的SOC变异系数偏高。
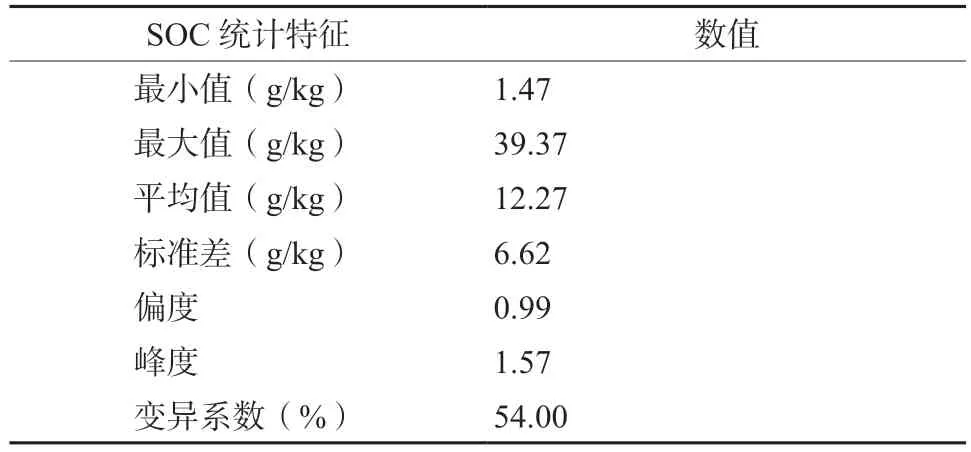
表2 土壤有机碳实测数据样本集统计特征Table 2 Statistical characteristics of the sample set of SOC measurement data
2.2 模型的评价与比较分析
对SVR、RF、XGBoost和LightGBM四种机器学习算法预测亚热带丘陵区小流域SOC的性能进行统计分析,根据R2、MAE、RMSE和LCCC四个指标的比较,结果显示,RF模型的预测误差相对最低,其MAE值和RMSE值分别为3.323和4.464,且R2值为最高(0.540),LCCC值(0.672)仅次于XGBoost(表3),具有相对最优的模型预测效果,其原因为RF采用自助采样法和随机特征选择的方式生成多棵决策树,以此来降低方差,防止过拟合,提高泛化能力。XGBoost是一种基于树的集成学习算法,通过优化的损失函数和正则化技术来提高模型的泛化能力。在本研究中,XGBoost模型亦能较好地模拟SOC分布,其预测误差MAE值(3.416)和RMSE值(4.523)略高于RF模型,R2值略低(0.528),但是LCCC值(0.676)却为最高。排在第三位的LightGBM模型的预测误差值略高于XGBoost,模拟精度略低。而SVR模型具有相对最高的预测误差,MAE值和RMSE值分别达到3.698和4.982,且R2值(0.427)和LCCC值(0.537)为最低,低于模型预测精度的最低可接受值(0.50),模型表现最差,究其原因为SVR算法对数据的线性可分性要求比较高,如果数据集中存在复杂的非线性关系,SVR算法的拟合度可能会降低。

表3 四种机器学习模型的精度对比Table 3 Comparison of prediction accuracy of four machine learning models
2.3 环境变量的相对重要性分析
图2给出了RF、XGBoost和LightGBM三种模型的环境变量特征重要性分布(SVR未给出,所使用的sklearn包不提供SVR显示特征重要性的功能)。由于RF、XGBoost和LightGBM采用不同的方法评估环境变量重要性,可能会导致不同环境变量的重要性呈现一定的差异。RF算法采用随机特征选择的方式生成多棵决策树,每棵决策树只使用部分特征进行划分,通过计算每个环境变量在所有决策树中出现的次数来评估其重要性。在RF模型中,各环境变量的重要性从高到低分别为海拔(30.49%)、气温(21.93%)、坡度(13.97%),植被指数(12.64%)、landsat 5第四波段(10.01%)、相对植被指数(6.89%)和地形湿度指数(4.07%)。XGBoost则是通过计算每个环境变量在每棵树中的分裂贡献度来评估特征的重要性。分裂贡献度是指每个环境变量在树的每个分裂点上的增益值之和。在本研究中,XGBoost模型环境变量重要性分布与RF相同,各变量重要性占比从高到低分别为海拔(32.84%)、气温(22.11%)、坡度(18.99%)、植被指数(11.00%)、landsat 5第四波段(8.83%)、相对植被指数(3.51%)和地形湿度指数(2.71%)。LightGBM的环境变量重要性计算则是通过计算每个环境变量在每个叶子节点上的样本数来评估特征的重要性。因此LightGBM的环境变量特征重要性分布与RF和XGBoost存在较大差异,从高到低分别为海拔(20.61%)、地形湿度指数(16.36%)、植被指数(14.89%)、坡度(13.83%)、landsat 5第四波段(12.50%)、温度(11.30%)和相对植被指数(10.51%)。上述结果显示,所选几类环境变量中以海拔对三种模型的预测最为重要,说明在亚热带丘陵地区海拔对模型预测SOC含量的高低起显著作用。

图2 环境变量在三种模型预测SOC中的相对重要性Fig. 2 Relative importance of environmental variables for SOC prediction by three models
通过对上述7种环境变量按表1归类为地形变量、气候变量和植被变量三类。在RF模型中,上述三类变量的重要性占比分别为48.53%、21.93%和29.60%。在XGBoost模型中,各变量的重要性占比分别为54.54%、22.11%和23.34%。而在LightGBM中,地形、气候和植被变量的重要性占比分别为50.8%、11.3%和37.99%。三种模型地形变量类别的重要性均以地形排在第一位。此外,RF和XGBoost在变量类别的重要性分布上表现一致。而LightGBM呈现出一定的差异性,其植被变量的重要性明显偏高,比RF高出8.39个百分点,比XGBoost高出14.65个百分点,而气候变量的重要性分别比RF低10.63个百分点,比XGBoost低10.81个百分点。
2.4 土壤有机碳空间分布的预测模拟
通过RF、SVR、XGBoost和LightGBM四种机器学习方法预测的SOC含量范围分别为5.35~21.72 g/kg、5.31~19.18 g/kg、3.57~20.42 g/kg和6.08~22.09 g/kg(图3)。尽管不同模型的总体分布特征相似,但SOC含量的高低却有较为明显的差异。其中LightGBM模型预测的SOC含量最低值和最高值均高于其他模型,而XGBoost模型预测的SOC含量最低值在所有模型中为最低。
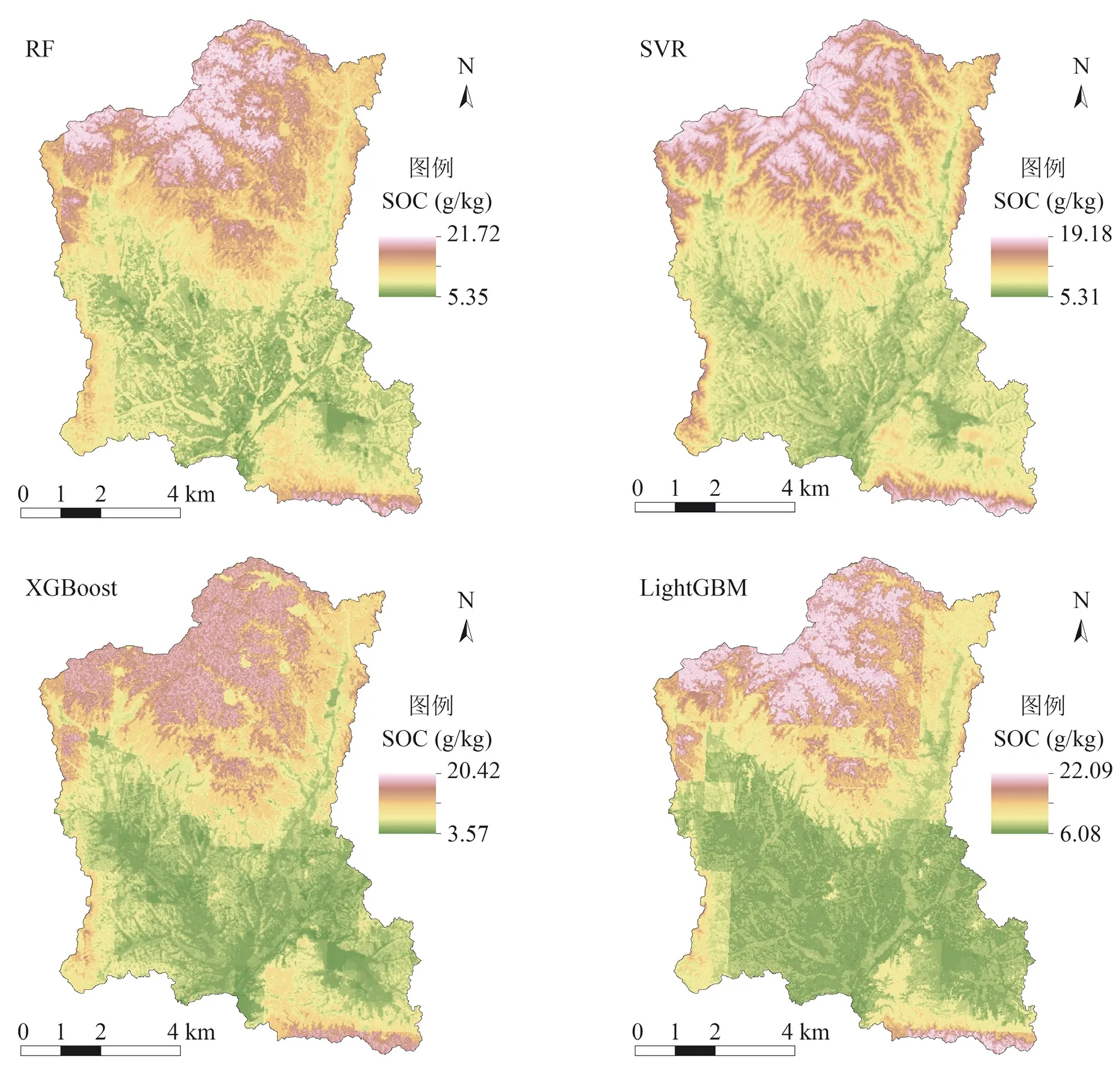
图3 四种机器学习模型的SOC的空间预测结果Fig. 3 Spatial prediction of SOC by four machine learning models
将四种模型预测的SOC含量通过ArcGIS 10.8制图后显示,SOC空间分布呈现出相同的规律,即北部大部分区域、西南方边缘区域和东南方的边缘区域SOC含量高,中部SOC含量普遍偏低。SVR模型预测的东南部和西南部的SOC含量值明显高于其他模型的预测值。SOC含量高低的空间分布与海拔的高低分布具有一致性(图1、图3),再次证明了海拔对于SOC含量的预测起显著作用,即在地貌复杂多变且耕地较少的区域,地形及其相关环境变量对SOC的空间分布具有重要影响。
3 讨论
本研究中几种模型模拟SOC含量的预测精度存在一定的差异(表3)。RF、LightGBM和XGBoost均表现出较好的适用性,以RF模型的性能相对最好,其预测SOC含量的R2(0.540)亦略高于LightGBM和XGBoost模型,而SVR模型并不适用于亚热带丘陵区复杂地形的SOC含量预测。就四种模型对比而言,RF可以作为亚热带丘陵区景观单元SOC含量预测的最佳适用模型。但是,Fathololoumi等[22]应用RF和Cubist模型对伊朗北部复杂地形山区SOC 等土壤属性的预测表明,不同预测模型的预测精度存在差异,相比于RF模型,Cubist模型非平坦区域拥有更高的模拟精度,表现出较好的适用性。Emadi等[6]对伊朗北部山地SOC的模拟结果表明,深度神经网络模型相较于其他模型(SVR、人工神经网络、RF和XGBoost)更具有优势。这与本文的研究结果存在差异。原因可能是不同区域土壤性质与其他主导SOC空间分布的环境因素相差太大,故数据集的特征会产生较大偏差。由此可见,不同区域SOC模拟的最适模型也存在差异,在开展SOC模拟预测时,应根据特定的区域环境特点筛选合适的模拟模型以提升SOC空间模拟的精度。未来可以尝试更多模型或进行模型融合,以探究适合更为广泛区域尺度的SOC模拟模型。
就同一模型的模拟精度而言,本研究中RF模型预测SOC含量的R2值高于Zeraatpisheh等[23]在伊朗南部半干旱地区达拉布平原农业用地使用237个样本结合RF算法进行SOC含量预测的R2值(0.29),也略高于Yang等[24]使用49个样本点作为训练集对中国安徽省某地区农田SOC含量进行RF预测的R2值(0.51)。其原因可能跟本研究的土壤采样密度较高,模型预测的样本量较多有关。较高的样本量条件下模型能得到更加充分的训练,因此具有相对较高的模拟精度。尽管本研究所用SOC的样本数较已有研究稍多,但在数量上仍然不足。如Malone等[25]所述,机器学习模型预测SOC含量的一个主要误差来源是样本数据的稀少,因此可将样本数不足归为本研究机器学习模型预测SOC含量的高不确定性的主要原因。此外,此前的研究已经证明高精度的环境变量数据对于土壤属性预测的有效性[26],但从已有的小流域尺度的研究来看,高精度的环境变量数据的应用缺乏关注。本研究也缺乏更高精度的环境变量数据,这也是模型精度不高的另一个原因。后续可以考虑扩大样本数量与范围,提高环境变量的分辨率(目前使用的一般是30 m ×30 m或100 m × 100 m的分辨率),探寻更好的样本降噪方法,使机器学习模型具有更充分的训练空间,可能会进一步提升机器学习模型对于复杂地形区土壤有机碳的预测精度。
此外,所选几种模型环境变量的相对重要性也存在差异。XGBoost模型中环境变量的相对重要性分布与RF相似。但是LightGBM与RF和XGBoost模型在环境变量的特征重要性排序上差异较大,表现为植被变量高于上述二者10%左右且气候变量低10%左右。尽管如此,三种模型均以地形(主要为海拔)作为解释模型拟合度的最重要的环境变量。这可能跟亚热带丘陵区地形地貌复杂有关,地形相较于其他环境变量具有更高的空间异质性。因此,几种机器学习模型预测的SOC含量的空间分布格局相似(图3),均以高海拔的北部、东南部和西南部地区的SOC含量较高,该区域植被覆盖密集,土壤相对肥沃,植被的固土能力强,不易发生养分流失,另外林木茂密为动物们提供了很好的栖息所,生物多样性高,枯枝落叶和动物粪便尸体等均贡献于土地肥力。张厚喜等[27]和钟兆全[28]分别运用不同模型预测福建省SOC含量,发现高程是影响SOC含量的重要因子,且SOC含量随海拔的升高而增加。即在地貌复杂多变且耕地较少的区域,地形及其相关环境变量往往对SOC的空间分布有关键性的影响。而在小流域尺度内,没有了降雨这一气候因素的作用,地形地貌对于SOC的空间分布的影响更为突出。Zeraatpisheh等[29]对沙漠地区SOC的模拟研究显示,海拔和地形湿度指数均是预测沙漠地区SOC含量的重要参数,而本研究结果显示地形湿度指数对亚热带丘陵区SOC的模型预测贡献不大。John等[7]的研究显示,在滨海平原区,地形对于机器学习模型的SOC预测贡献不大,而土壤理化性质是最重要的环境变量,因为在平原区海拔几乎没有差异,海拔对于模型学习的过程贡献不高。因此,可以针对不同研究区域的主导环境变量特点选取模型的重要环境参数。
本研究所选的亚热带丘陵区典型小流域,不仅具有复杂的地形地貌特点,也受到强烈的人类活动影响。但是在环境变量的选取方面仅选择了容易获取的地形变量、气候变量、植被变量参与模型构建并预测SOC含量,并未加入人类活动对SOC含量的影响。有研究表明农业活动(如轮作、灌溉、施肥等)对SOC尤其是土壤表层SOC含量产生重要影响,从而可能影响气候等自然环境变量与SOC的关系[30-31]。除此之外,有研究报道土地利用、土壤母质、土壤养分指标等也与SOC关系密切[32-33]。因此,未来应寻找更多与SOC相关性强的辅助变量以及能代表人类活动的替代因子作为模型输入参数,从而提升模型的泛化性能和鲁棒性。后续研究可以扩展环境预测因子(如土壤理化性质和人类活动),并涵盖更为广泛区域的土壤类型,提高机器学习模型的预测精度与广泛适应性,实现更高精度和更大区域尺度的SOC含量的预测。
4 结论
在具有复杂地形的亚热带丘陵地区,RF、LightGBM和XGBoost模型均能较为有效地预测SOC含量,以随机森林的模拟性能相对较优,可以应用于亚热带丘陵区的SOC空间分布预测研究。而SVR模型的模拟精度最低,不适用于亚热带丘陵区SOC的空间预测研究。在环境变量重要性上,几种模型均以地形(主要为海拔)作为SOC空间分布预测的最重要的影响因子,其余环境变量的重要性在不同模型之间存在较大差异。几种模型预测的SOC含量结果具有相似的空间分布格局和显著的空间异质性,总体表现为北部、西南方边缘区域和东南方边缘区域的高海拔区SOC含量高于中部低海拔区。
