基于开集识别的恶意代码家族同源性分析
2023-08-10刘亚倩
刘亚倩
(北京天融信网络安全技术有限公司 北京 100085)
恶意代码的不断增长给安全人员带来极大困扰.但是很多新型的恶意代码都是已有恶意代码的变种,这些代码往往具有内在的关联性、相似性.因此判断未知的恶意代码与已知的恶意代码家族是否具有同源性的关系,可以帮助人们发现大部分的恶意代码,同时可以对与已知家族具有同源性关系的未知恶意代码有更好的了解和判断.
1 相关研究
目前学术界关于恶意代码家族同源性分析已有众多性能良好的识别算法,大致可以分为以下3种思路:
1) 基于相似度计算的恶意代码家族同源性判别方法.将恶意代码家族同源性判别问题转换成计算2个恶意代码之间相似性的问题,相似性越高,则2个恶意代码源自同一个家族的可能性就越大.Cho等人[1]在2014年提出了一种相似度计算系统,可用于检测同一家族的恶意软件变种;陈琪等人[2]在2017年通过生成病毒家族特征库,计算恶意代码与特征库之间的相似度,完成恶意代码的家族判定.
2) 基于聚类方法的恶意代码家族同源性判别方法.通常是利用聚类算法操作相似性值获取待测样本与已知样本之间的同源关系.钱雨村等人[3]在2015年通过计算不同恶意代码之间的相似性度量,然后利用DBSCAN聚类算法将具有相同或相似特征的恶意代码汇聚成不同的恶意代码家族;Giannella等人[4]在2015年提出了基于谱聚类的恶意代码聚类方法;刘凯等人[5]在2019年从恶意代码的API调用图入手,结合图卷积网络(graph convolution network, GCN),设计了恶意代码的相似度计算和家族聚类模型.
然而,基于相似性匹配和聚类算法的思路都需要计算特征之间的相似性,但是当特征类型较多时,需要考虑不同特征的相似性计算问题,导致相似性模型较为复杂,影响同源性结果的判定.并且图相似性计算是一个NP问题,计算复杂度太大,时间成本过高.
3) 目前的研究大多将恶意代码同源性判定问题转换成机器学习算法,尤其是深度学习算法中的多分类问题.Xue等人[6]在2019年提出了一种基于集成学习和多特征的恶意软件同源分析系统,使用卷积神经网络作为基础学习器执行集成学习,从灰度图像、RGB图像和M图像中学习特征,最终获取恶意软件分类结果;乔延臣等人[7]在2019年提出了一种基于汇编指令词向量与卷积神经网络的恶意代码分类方法;Zhu等人[8]在2021年提出一种基于恶意软件可视化的融合全局结构特征和局部细粒度特征的同源性确定方法,将恶意软件字节码图像和操作码图像输入到双分支卷积神经网络中,实现恶意软件家族分类.
然而该方法基于一个假设,即认为数据可分为N种已知的、具有标签的类别,且输入必定属于这N种类别之一.也就是说该方法解决的是恶意代码家族的闭集分类问题.然而真实环境中的恶意代码家族众多,无法收集到所有的家族进行模型训练,实际环境中未知类的家族占大多数,采用闭集识别的方法,无法准确测试真实环境中的恶意代码家族,因此有必要将恶意代码家族同源性分析问题转换成一个开集识别的问题,即能够对已知类别进行正确分类,同时也能识别出未知类别.目前关于此类问题的研究较少.Jia[9]通过调查概述了不同的深度学习技术和开集识别方法,并提出恶意软件分类是一个开集识别问题;陈雁佳[10]结合深度森林和卷积神经网络,提出了一种针对APT恶意软件组织的开集识别模型.但是该方法中提取的静态特征信息不够充分,不足以识别不同的APT组织.
本文基于N-Gram滑动窗口和Doc2vec[11]句嵌入方法将恶意代码的反汇编文件转换成灰度图像,利用卷积神经网络模型MobileNet[12]提取图像特征,将深度学习的开集识别模型Open Long-tailed Recognition[13]引入到恶意代码家族同源性分析的问题中,能够实现真实世界中恶意代码家族的开集识别分类,并且对于已知类别和未知类别家族的恶意代码识别准确率都较高.
2 理论基础
2.1 Doc2vec方法
Doc2vec方法(也称paragraph vector,sentence embeddings)是一种无监督算法,能从变长的文本(句子、段落或文档)中学习得到固定长度的向量表示,是Word2vec[14]方法的拓展,不同之处是在输入层增添了一个句子向量.Doc2vec方法能够克服词袋模型中忽略文本的词序和没有语义的缺点.
Doc2vec有2种训练方式,本文选用的是PV-DM(distributed memory model of paragraph vectors)模型,如图1所示.该方法与Word2vec中的CBOW(continuous bag of words)模型不同点在于通过矩阵D额外的段落分段被安置到单个向量中.在此模型中,该向量及另外3个语境向量的拼接或者平均结果被用于预测第4个词.该段落向量表示上下文缺失的信息.
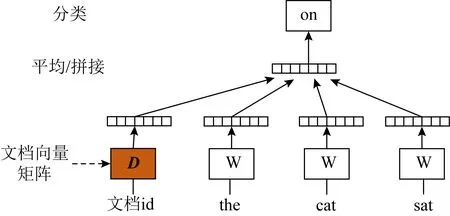
图1 PV-DM模型
Tran等人[15]在2017 年提出的基于自然语言处理与API的恶意代码分类方法中,使用N-Gram,Doc2vec等自然语言处理方法将API 调用序列转换成向量,进而实现恶意代码家族分类.
2.2 Open Long-tailed Recognition模型
Open Long-tailed Recognition是Liu等人[13]在2019年提出的基于深度学习的、在开放世界中识别图像类数据的开集识别算法模型.该算法将图像映射到特征空间,使得视觉概念之间可以基于学习到的度量相互关联,并且这种度量既认可了封闭世界分类又承认了开放世界的新颖性.该方法在ImageNet,Places,MS1M数据集上的实验效果均优于目前最先进的技术.
Open Long-tailed Recognition模型包括Dynamic Meta-Embedding,Modulated Attention,Cosine Classifier这3个部分.
Dynamic Meta-Embedding部分是在卷积神经网络模型输出的特征基础上加入视觉记忆特征.可以平衡大样本类和小样本类数据之间的特征信息.具体特征表示为
(1)
其中vdirect为原始特征,vmemory为视觉记忆特征,γ为测量输入的直接特征到判别质心之间的最小距离,在区分已知类别和开放集类别方面起着重要作用.e代表一种轻量级的网络.
Modulated Attention部分的添加是为了区分大样本类和小样本类.在卷积神经网络输出的特征基础上加入Modulated注意力.具体表现为
fatt=f+MA(f)⊗SA(f),
(2)
其中f是卷积神经网络模型输出的原始特征,SA(·)是自注意力操作,MA(·)是具有softmax归一化的条件注意力函数.这种Modulated注意力可以插入卷积神经网络的任何特征层,在这里只修改最后一个特征层.
Cosine Classifier部分用于接收Dynamic Meta-Embedding和Modulated Attention部分修改后的新的特征数据,最终输入到softmax中输出属于各已知类别的概率,根据设定的阈值判别出未知类别样本.
3 恶意代码家族开集识别模型技术
3.1 恶意代码家族开集识别模型整体架构
本文提供了一种基于开集识别的恶意代码家族同源性分析技术,通过将图像领域中的基于深度学习的开集识别方法引入到恶意代码家族同源分析的研究中,以期解决现有恶意代码家族同源分析研究领域中开集识别方法研究不足和识别准确率低、性能较差的问题.
恶意代码家族开集识别模型主要包括2个部分:恶意代码灰度图生成技术和恶意代码家族开集识别模型.整体架构如图2所示.恶意代码灰度图生成技术通过2-Gram滑动窗口和Doc2vec句嵌入方法将恶意代码转换成相应的灰度图像.恶意代码家族开集识别模型部分利用卷积神经网络模型MobileNet和图像领域中的开集识别模型Open Long-tailed Recognition获取恶意代码家族的开集分类结果.
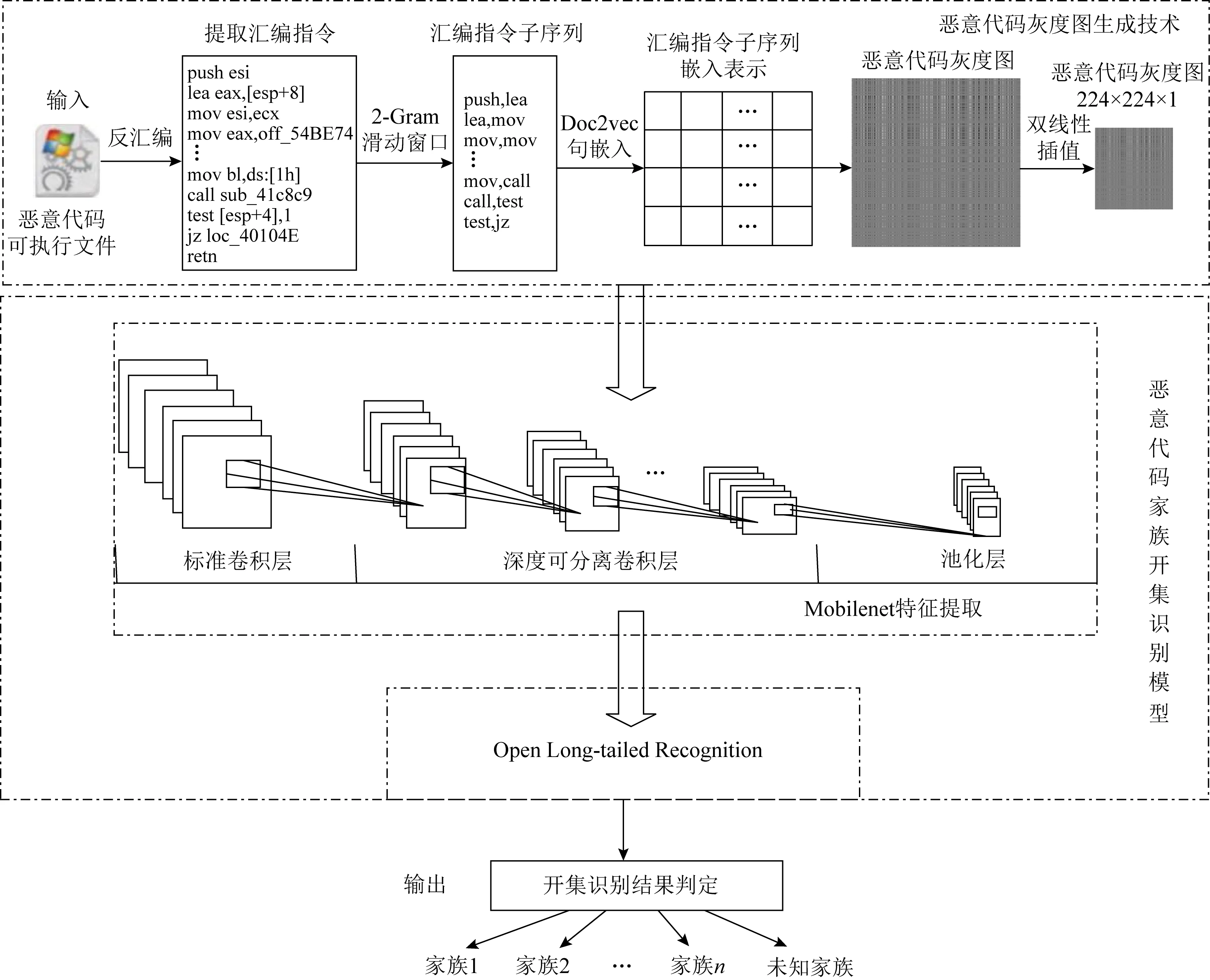
图2 恶意代码家族开集识别模型整体架构
3.2 恶意代码灰度图生成技术
本文在文献[7]的基础上采用2-Gram滑动窗口和Doc2vec句嵌入相结合的方法实现恶意代码的可视化.其中,opcodeN-Gram在恶意代码分类研究[16-18]中已被证明是非常有效的特征.文献[7]的方法仅提取单一的汇编指令作为特征空间的特征维度,难以完全代表汇编指令前后间关系的信息,不能反映汇编指令序列相对完整的意义.事实上,汇编指令序列中各个指令前后之间具有密切的关联,因此,本文将汇编指令子序列作为特征,能够更加充分地提取汇编指令序列的信息.
本文中恶意代码灰度图生成技术的架构如图3所示.具体步骤为:1)将恶意代码反汇编得到.asm文件,从中提取.text或.CODE程序段的全部汇编指令序列;2)基于2-Gram滑动窗口方法切分指令序列,得到汇编指令子序列,将恶意代码转换成由汇编指令子序列作为句子组成的文档;3)利用Doc2vec句嵌入模型计算每篇文档上所有汇编指令子序列的句向量,同时统计训练集中的关键汇编指令子序列列表,并将列表维度设为T;4)按照列表顺序和指令子序列向量将每篇文档转换成T×T维的矩阵,如果文档中有不存在于关键汇编指令子序列中的指令序列,则以T维的0向量代替;5)将每个样本矩阵进行归一化处理和尺度变换,转换成灰度图像,其中,矩阵中的最小值对应黑色像素,最大值对应白色像素;6)利用双线性插值方法将图像大小修改成224×224×1.

图3 恶意代码灰度图生成技术
其中,关键汇编指令子序列列表根据汇编指令子序列的频率区间获取.该方法能够避免频率过小、某些子序列仅代表特殊样本而频率过高、特征区分度不够的问题.方法如下:
首先,获取汇编指令子序列ci在所有训练样本m中出现的频率.然后,根据实际情况选用频率区间对汇编指令子序列进行筛选,将频率值超过阈值上界或下界的子序列去掉,最终筛选关键汇编指令子序列列表作为特征空间,维度为T.其中,频率计算方法如下:
令Ni表示训练样本集包含子序列ci的文件总数,Ni也可以认为是ci在数据集中的频率(与出现总次数不同,因为ci有可能在1个文件中重复出现),则
(3)

3.3 恶意代码家族开集识别模型
恶意代码家族开集识别模型基于卷积神经网络模型MobileNet和图像领域中的开集识别模型Open Long-tailed Recognition构建,如图4所示.其中,MobileNet模型由标准卷积层、深度可分离卷积层(depthwise separable convolution)、平均池化层(average pooling)、全连接层(fully connected layer)和softmax层组成.
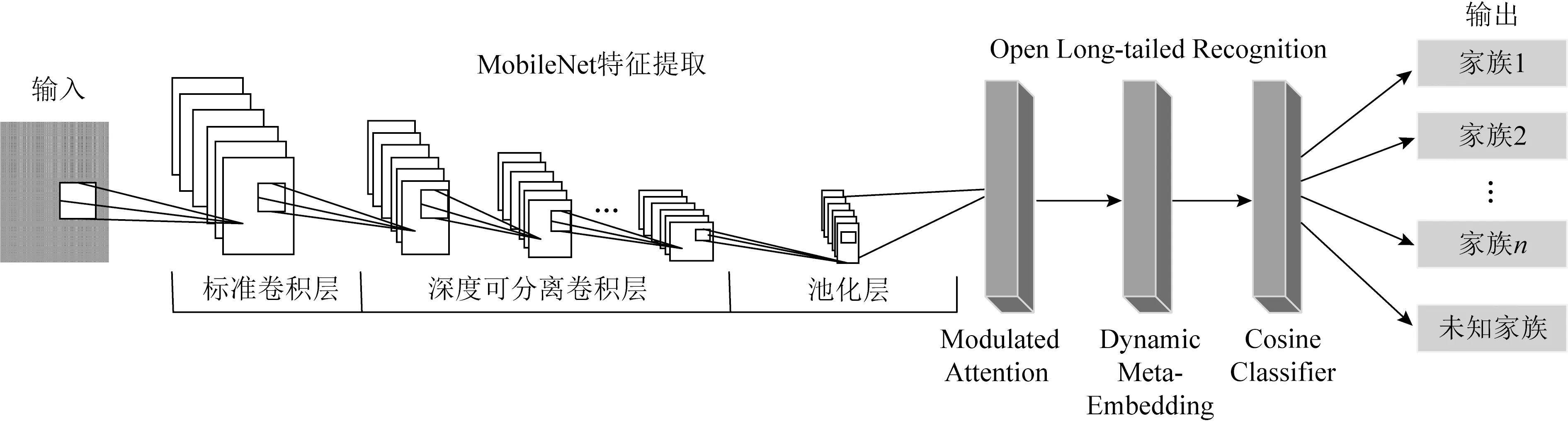
图4 恶意代码家族开集识别模型
恶意代码家族开集识别模型部分将3.2节中获取的224×224维的训练样本集中每个灰度图像逐一输入到初始卷积神经网络模型MobileNet中训练.其中,原始模型的输入通道为3通道,而灰度图像属于单通道,因此将模型修改为单通道输入.通过不断调整网络模型的参数,使分类准确率达到预先设定阈值,结束训练.提取MobileNet模型中全连接层的输入作为特征数据,数据维度为1024.将其输入到Open Long-tailed Recognition模型中训练,基于Dynamic Meta-Embedding部分和Modulated Attention部分,对特征进行修改,包括添加视觉记忆特征和Modulated注意力机制,从而获取新的特征数据.将该数据输入到Cosine Classifier部分中,构建初始的开集识别模型.
利用测试集样本,包括已知类别家族和未知类别家族对初始的开集识别模型进行测试和参数调整.预先设定开集分类阈值,如果未知类别的分类准确率低于预设阈值,则调整Open Long-tailed Recognition模型相关参数,直至未知类别准确率达到所述阈值,得到最终的恶意代码家族开集识别模型.
关于测试集样本开集识别结果输出,Cosine Classifier部分会输出它属于各已知家族的分类概率[p1,p2,…,pc],假设其中最大的概率值为pi,设定的开集分类阈值为0.8,如果pi≥0.8,则该待测恶意代码属于第i类已知恶意代码家族;反之,待测恶意代码属于未知恶意代码家族.
4 实验分析
4.1 实验数据
本文实验选用已知家族类别样本作为训练集,选用已知家族类别和未知家族类别样本共同作为测试集.
训练集和已知家族类别的测试集来源于2015 Kaggle微软恶意软件分类挑战赛[19].该数据集包含9 类恶意代码家族,每个恶意代码去除PE 头,分别包含2 个文件:反编译得到的.asm文件和十六进制表示的.bytes文件,本文只采用.asm文件.原样本共有10868个,但是有些反汇编样本没有操作码序列,去除这类样本后共剩余10725个样本.该数据家族详情如表1所示.
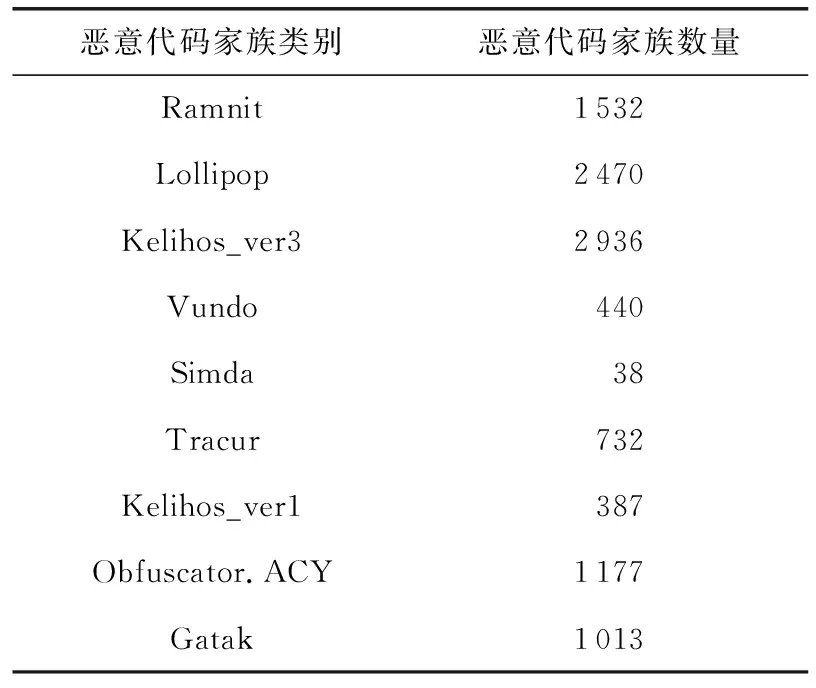
表1 已知类别家族与样本数量
实验数据的未知家族类别样本来源于已收集的恶意代码家族库,该数据共包含9个家族,每个家族有300个样本,全部样本作为测试集使用.该数据家族详情如表2所示.

表2 未知类别家族与样本数量
为了与传统的分类模型进行对比,在对比模型的训练集中加入其他类别数据.该数据包括不属于已知类别和未知类别家族数据的18个家族、704个样本.该数据家族详情如表3所示:

表3 其他类别家族与样本数量
4.2 对比实验
4.2.1 实验说明
目前关于恶意代码家族同源性分析的研究多为传统的闭集分类思路,而关于恶意代码家族开集识别方法的研究较少,为了验证本文模型在恶意代码家族开集分类识别任务上的有效性和优越性,将本文模型与对比模型1、对比模型2进行比较,对比实验流程如图5所示.
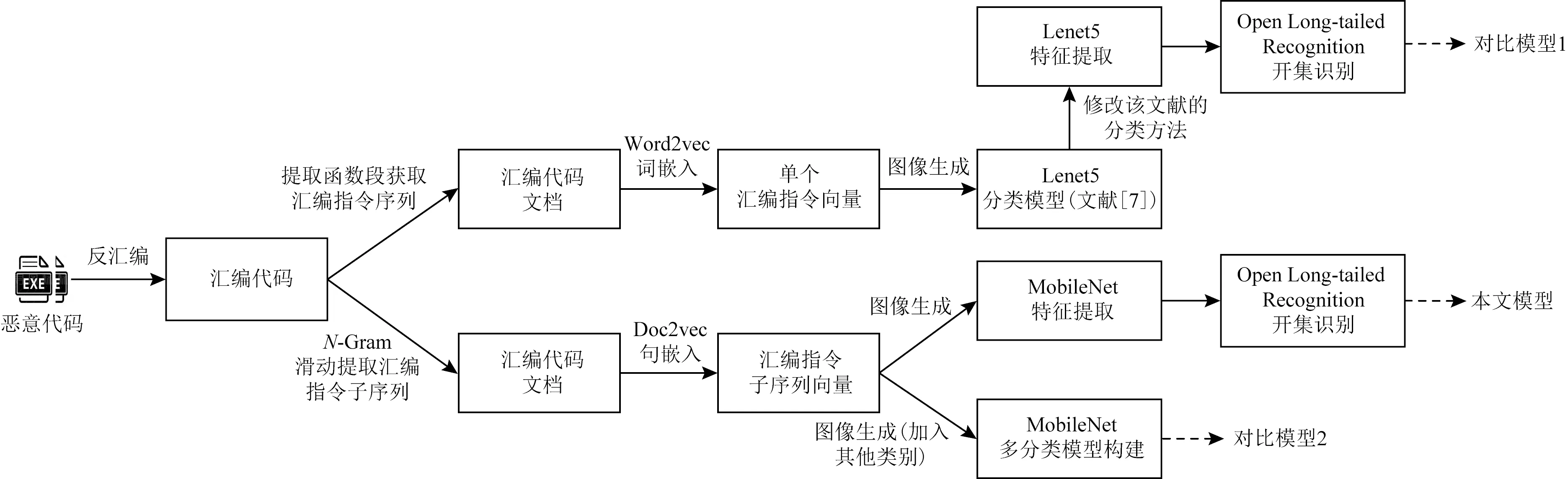
图5 模型对比实验
文献[7]的传统分类方法仅适用于闭集分类,不能识别未知类别.为了验证本文模型在恶意代码灰度图生成技术和卷积神经网络特征提取上的优越性,在文献[7]分类方法基础上加入Open Long-tailed Recognition模型构建开集识别模型作为对比模型1.为了验证本文模型在恶意代码开集识别方法应用上的有效性,在本文模型数据可视化为灰度图像的基础上加入其他类别数据,构建多分类模型作为对比模型2,参照传统的方法在多分类模型中设定其他类别,从而达到使其能够识别未知类别家族的目的.
实验采用以下评估度量指标评估恶意代码家族的识别效果,包括用于验证识别未知家族和已知家族能力的Accuracy值,以及验证已知家族分类的准确率Accuracy、查准率Precision、召回率Recall和F1-score.
4.2.2 对比结果分析
本实验中,本文模型、对比模型1和对比模型2选取的实验数据详情如表4所示.其中,对比模型2与本文模型和对比模型1的区别是在训练集中加入了其他类别数据.
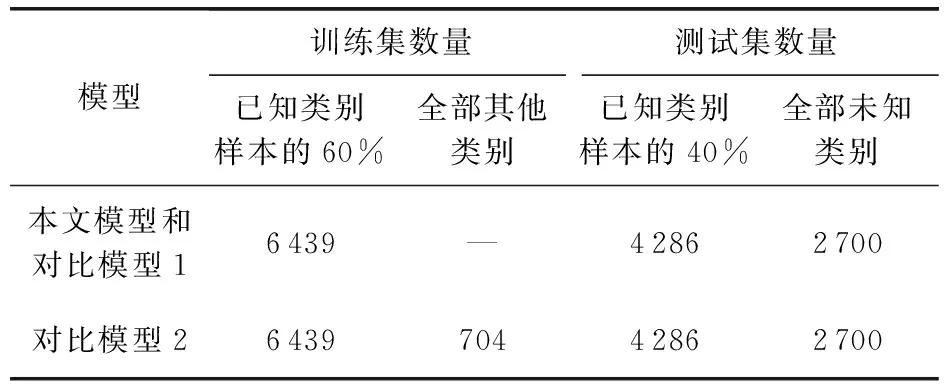
表4 模型对比实验数据
本文模型与对比模型1、对比模型2在上述数据集上的综合测试结果如表5所示.其中0~8表示9个已知类别家族,9~17表示9个未知类别家族.对比结果采用Accuracy值.
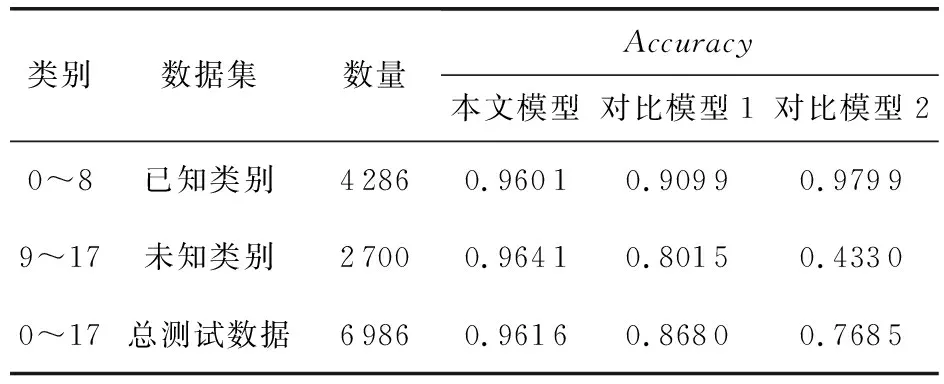
表5 已知类别和未知类别家族的对比实验结果
本文模型在总测试数据、已知类别家族、未知类别家族上的Accuracy都大于对比模型1,并且都大于95%.表明本文模型在已知类别和未知类别家族上的识别效果都较好,且都优于对比模型1.对比模型2在未知类别上的Accuracy仅为43.30%,说明对比模型2并不能对真实世界中的未知类别进行有效识别,并且真实世界中往往未知类别家族数据占大多数,因此对比模型2无法直接应用于识别真实世界中的恶意代码家族.
针对已知类别家族,模型除了基于Accuracy值进行评估外,还采用Precision,Recall,F1-score这3个指标进行评估.通常情况下,在多分类问题中,这3个指标可以使用3种不同的平均计算方法,分别是macro avg,micro avg,weighted avg.考虑到不同恶意代码家族数据之间存在类别不平衡问题,本文采用weighted avg方法进行评估.结果如表6所示.可以看出本文模型在已知类别家族上的各项指标都优于对比模型1,与对比模型2相差无几.

表6 已知类别家族的开集识别结果
从整体来看,对比模型2虽然在已知类别家族上有较好的实验效果,但是在未知类别家族上识别效果极差,因此该方法不能对真实世界中的恶意代码家族进行识别.对比模型1无论在已知类别家族和未知类别家族上的识别效果都低于本文模型,说明本文模型在恶意代码灰度图生成技术和卷积神经网络MobileNet特征提取方法上优于对比模型1.
传统分类模型在加入开集识别模型后,即未知类别的加入一定会对已知类别家族的识别产生影响,即会有未知类别被错误地识别为已知家族类别,已知类别被错误地识别为未知家族类别.从整体实验结果来看,本文模型能够实现未知类别样本的识别,同时对于已知类别家族能够保持较好的识别效果,因此本文模型能够实现真实世界中恶意代码家族的有效识别.
5 结 语
针对传统的恶意代码家族分类方法为闭集分类,仅能识别已知类别恶意代码家族、无法识别真实世界中的未知类别家族的问题,本文提出了一种恶意代码家族的开集识别方法,将图像领域的开集识别方法引入到恶意代码家族分类问题中.实验结果表明,在已知类别和未知类别家族上都取得了较好的识别效果.因此,本文模型能够对真实世界中的恶意代码家族进行有效识别.对比模型2表明传统分类模型加入其他类别后,虽然对于已知类别有较好的识别效果,但是仍然无法有效识别真实环境中的未知类别家族.
本文利用N-Gram和Doc2vec句嵌入方法将恶意代码可执行文件转换为相对应的灰度图像,该方法相较于对比模型1采用单一汇编指令和词嵌入方法转换成的图像更能反映汇编指令序列前后指令之间密切的关联信息.实验结果表明,本文模型在已知类别和未知类别恶意代码家族上的识别效果都优于对比模型1.
虽然本文工作能够识别真实世界中未知类别的恶意代码家族,并且在已知类别和未知类别上的识别准确率较高,但仍存在一些问题需要解决.本文验证了该模型的可行性,但是训练所用的数据相对于真实世界中的恶意代码家族数量较少,今后将在更多的数据上讨论本文方法的有效性.
