基于Transformer和重要词识别的句子融合方法
2023-08-10谭红叶李飞艳
谭红叶 李飞艳
1(山西大学计算机与信息技术学院 山西 太原 030006)2(山西大学计算智能与中文信息处理教育部重点实验室 山西 太原 030006)
0 引 言
文本生成是指给定文本或非文本输入,输出流畅、连贯且符合要求的文本。句子融合是一种典型的文本到文本的生成任务,旨在为给定的一组相关句子(或一个比较长的句子)生成一个较短的概括性句子,且保留其中的重要信息。句子融合与文本摘要有类似之处,但也有区别。主要区别包括:(1) 输入不同,句子融合的输入为一个或多个句子,而文本摘要的输入为单文档或多文档。一般来说后者输入句子数多于前者,因此后者压缩率大于前者。(2) 目标不同,句子融合侧重于去除相关句子的冗余信息,生成简短的句子,而文本摘要旨在获得概括篇章内容的多个句子。(3) 句子融合可以作为文本摘要的一个中间技术。如:在抽取式摘要中,句子融合可以将其结果作为输入,进一步融合后,得到更为灵活紧凑的摘要。
句子融合的具体示例如图1所示。可以看出,融合句不仅剔除了冗余和不重要的信息,而且生成了原句中未出现过的词。如:示例1中的融合句剔除了原句中“中新网7月21日电”“妻子王洪涛反映”等不重要的短语,同时生成了“网曝”“绥化”和“检方”等新词。从示例2可以看出融合句结构与原句也有不同。

原句1:“中新网7月21日电 据安县人民政府网站消息,2015年7月21日上午,新浪微博出现一则庆安县公安局经刑侦大队副大队长姚永军的妻子王洪涛反映其利用职务之便,贪污受贿、实施家暴的视频。目前已被停职,庆安县人民检察院已介入调查。”标准融合句:“网曝绥化庆安刑侦大队副大队长利用职务之便,贪污受贿、实施家暴,目前已被停职,检方介入调查。”原句2:“人民网:北京11月29日电 今天,记者从中国铁路总公司获悉,自11月30日起,中国铁路客户服务中心12306网站支付宝账户支付服务功能上线试运行,旅客网购火车票新增一种支付方式。”标准融合句:“人民网:12306网站明日起新增支付宝支付服务功能。”
目前,由于句子融合相关的数据集规模小,句子融合方法主要为基于无监督的方法。如,文献[1]中使用了词图方法,从原句复制重要信息片段到融合句。Clarke等[2]提出了一种基于句法树的方法,通过使用整数线性规划将句子压缩任务视为优化问题。但由于上述方法未考虑上下文信息和句子结构,生成的融合句缺乏重要信息或有语法错误。
有监督的文本生成的主流方法是基于神经网络的编码器-解码器框架。在编码器-解码器框架基础上,文献[3]提出Structure-infused复制机制,将原句的重要词和关系复制到摘要句,以确保生成的结果包含原句重要信息。文献[4]提出一种新颖的Focus-attention机制对句子进行编码,并设计了一个独立的显性选择网络管理信息流,来区分并强调原句重要信息。然而,这些方法还不能令人满意,主要表现在生成的文本不包含重要信息,或者用词偏离原句语义。
为了解决上述问题,本文采用Transformer架构,利用多头注意力机制学习文本的长距离依赖关系,并结合重要词识别模块进行句子融合。该方法主要包括两个模块:重要词识别模块与句子融合模块。其中,重要词识别模块利用BiLSTM-CRF序列标注模型识别原句重要词;句子融合模块将重要词与原句输入Transformer框架,利用BERT进行语义表示,并在全连接层引入基于原句和词表获得的向量作为先验知识生成融合句。该模型通过重要词识别模块加强了模型对重要词的理解与关注,并且通过引入先验知识,确保融合过程中包含更多原句中的词,使得结果与原句语义一致。此外,本文还基于NLPCC2017会议上的单文档摘要评测数据集,利用相似度计算方法获得了一定规模的汉语句子融合数据集(大约包含35 000多个样例)来训练模型。相关实验表明,本文所提模型性能明显优于基线系统。
1 相关工作
关于句子融合。由于可获得的句子融合数据集规模较小,因此大多数研究都使用无监督的方法。如:文献[7]提出了简单的词图方法,从不同的输入语句中复制片段并将它们连接起来形成最终句子。在此基础上,研究者尝试使用多种策略(如关键短语重新排名)改善词图方法[5-7]。为了改善融合后句子的语法合理性及新词包含率,文献[11]通过无监督手段引入语义一致的句子对来训练神经网络模型,具体思想为:首先利用词图方法产生粗粒度压缩文本B,然后用较短的同义词替换压缩文本中的词产生新句子C,最后利用所获得的语义一致的句子对(B,C)训练神经网络模型。
关于文本生成。现有的主流文本生成方法主要采用基于序列到序列(Seq2seq)的基本框架。在此基础上,一些研究者通过使用注意力机制来选择重要词,如:文献[15]在基于Attention的Seq2seq生成模型中引入VAE结构,将句子固定结构特征作为潜在向量并采用VAE作为生成框架来解决推理生成问题。也有研究者引入复制机制来获取句子重要信息,如:Song等[3]采用结构注入复制机制将原句重要词和依赖关系复制到目标句子。随着BERT的出现,研究者尝试在Seq2seq框架上引入BERT获得了更好的系统性能。如:Liu等[10]在目标数据集上调整预训练的BERT获得文档的输入表示,并与Transformer解码器相结合完成生成任务,获得了比之前模型更好的性能。然而,基于Transformer的方法仍存在一些局限,如:生成的融合句未包括原句重要信息,或者偏离原句内容。
关于相关数据集。目前关于句子融合的大规模数据集较少,且多为英文数据集。较早的句子融合数据集来自于Newsblaster摘要系统的新闻报道并由人标注产生,共包含3 000个样例[11]。文献[12]从Thomson-Reuters新闻专线中使用基于Bigram计数重叠的简单贪婪方法来对齐句子,构建了融合句-摘要句对形式数据集(约300个样例)。文献[13]为了探索有监督的句子融合方法,通过制定一些规则从摘要任务数据集构造了1 858个样例。James等[2]在大规模新闻语料Gigaword上,通过提取每篇文章的第一句和标题并经过数据清理,来获得句子和标题对作为句子融合的训练语料。
2 方 法
2.1 任务定义
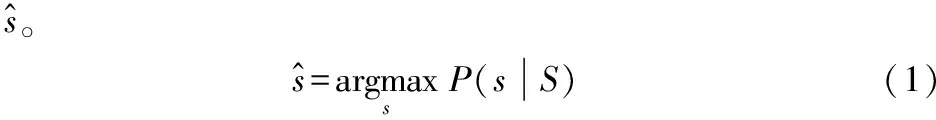
本文提出了一种基于Transformer和重要词识别的句子融合方法。该方法的模型总体架构如图2所示,主要包括句子重要词识别和句子融合两个模块。其中,重要词识别模块利用BiLSTM-CRF序列标注模型识别原句重要词;句子融合模块将重要词与原句作为Transformer框架的输入,利用BERT进行语义表示,并在全连接层引入基于原句和词表获得的向量作为先验知识生成融合句。
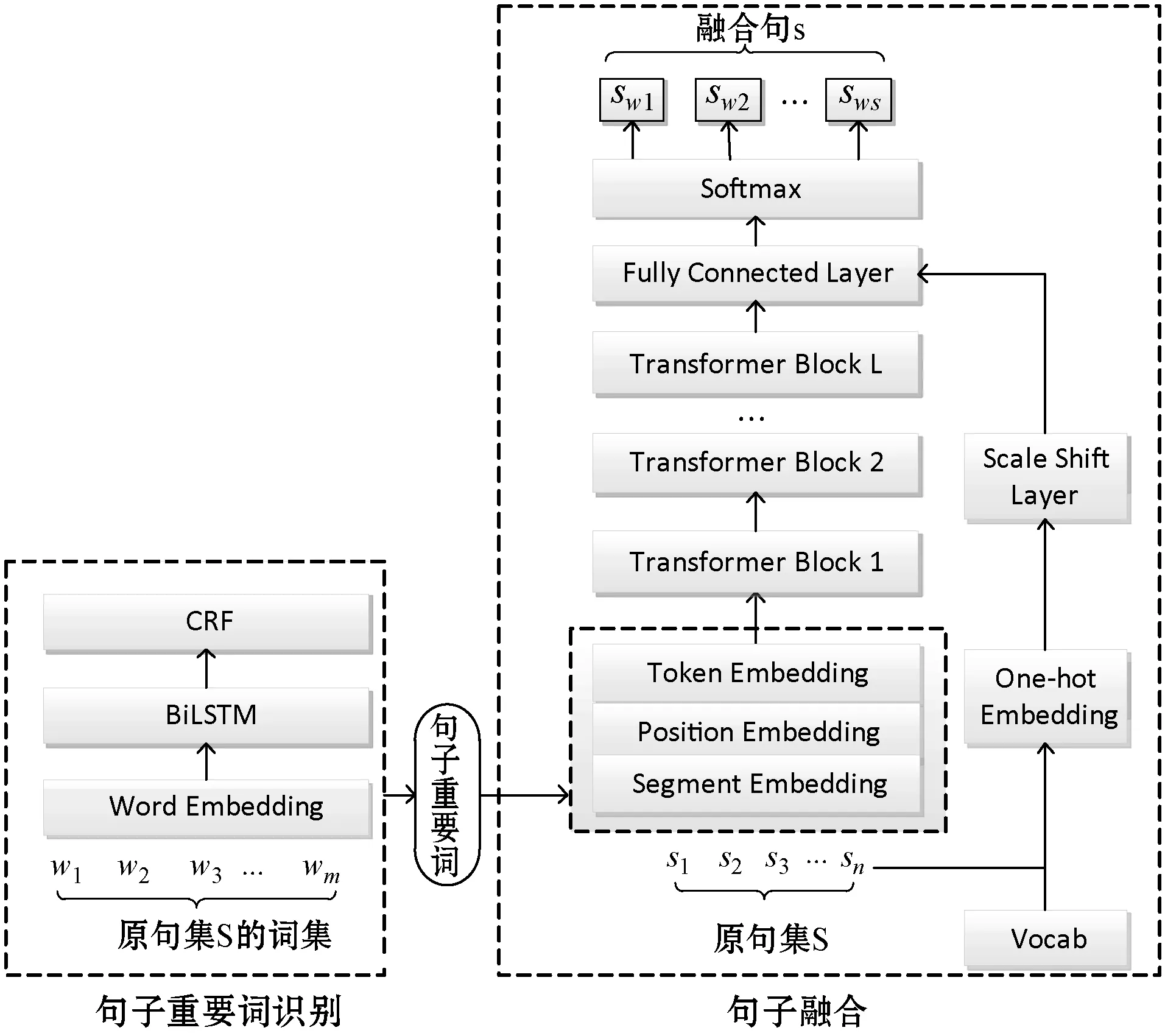
图2 本文的句子融合模型框架
2.2 句子重要词识别
为了使模型更好地捕捉原句重要信息,本文引入句子重要词的相关概念,并基于BiLSTM-CRF模型进行句子重要词的识别。
句子重要词是反映句子重要语义信息的词,具体识别时以同时出现在原句与融合句中的实词(主要指:名词、动词和形容词)为判别依据。
本文将句子重要词识别任务看作序列标注问题,并通过式(2)来刻画。
式中:W={w1,w2,…,wm}为输入句子的词序列,T*={t1,t2,…,tm}为输出的最优标注序列。其中的标记为1、0。1代表该词为重要词,反之则为0。
具体采用BiLSTM-CRF模型来识别,具体如图2左部的模块。该模型包括表示层、BiLSTM层和CRF层。其中,表示层将句子中的每个词表示为词向量;BiLSTM层负责将词向量作为输入对句子建模,同时更好地捕捉长距离依赖关系;CRF层为标签预测添加一些约束来保证预测标签的准确性,并输出句子中每个词的标签得分以获得最优标签序列的概率。
2.3 句子融合
句子融合模块采用Transformer框架(Dong等[14])实现编码与解码。该模块首先对输入句子集利用BERT获得字的上下文语义表示H0={xw1,xw2,…,xwn}(n为输入字序列的长度)。具体操作时,在输入序列的首部添加[CLS]标记,在每个句子末尾添加[SEP]标记。然后,将BERT语义表示(Token Embedding)与位置嵌入(Position Embedding)、段嵌入(Segment Embedding)拼接形成输入的向量表示。其中,段嵌入用来标识原句和融合句,0对应原句,1对应融合句。
需要注意的是,本文使用的掩码矩阵允许原句的字从前后两个方向计算注意力值,而融合句的字只能对([MASK])及之前的字,以及原句的字计算注意力值。

式中:s和t为训练参数。
2.4 损失函数
对于重要词识别任务和句子融合任务,使用交叉熵函数作为句子融合模型训练的损失函数,其计算式为:
式中:y表示真实结果;y′表示模型预测结果。
3 实验与结果分析
3.1 数据集
如本文第1节所述,目前已公开的句子融合数据集主要为英文数据集,但规模都较小。对于中文来说,几乎没有公开的句子融合数据集。
本文基于NLPCC2017会议的中文单文档摘要评测任务数据集构建了句子融合数据集。该评测数据集共包含52 000个篇章-摘要形式的样例,且摘要中包含一些原文没有出现的词。其中的篇章为今日头条中文新闻文本,涉及的主题有体育、食品、娱乐、政治、科技、金融等。在该数据集的基础上,我们按照如下方法构建了句子融合数据集和句子重要词识别的数据集。
句子融合数据集。对于每个篇章-摘要样例,首先按标点符号将摘要句切分为短句,然后用两个句子中的共现词数与句子长度之和的比值来度量其相似度,其计算式为:
式中:WSi表示第i个句子的词集合;wk表示词;|Si|表示第i个句子的长度。
然后,选择原文最相似的句子构成该摘要句的待融合句子集,从而形成原句-融合句(摘要句)形式的样例。通过去重、剔除词重叠率小于0.45的样例,最终得到35 488条数据。其中,训练集31 488条,验证集2 000条,测试集2 000条。
本文从新词率、原词率和压缩率等方面对句子融合测试集进行了分析。其中,新词率指融合句中新词(未出现在原句的词)在原句的占比;原词率指融合句中的原词(出现在原句的词)在原句的占比;压缩率指融合句长度与原句长度之比。具体结果如表1所示,从原词率、新词率、压缩率可以看出融合过程中,部分原词被保留,大部分冗余信息被删除,同时包含未在原句出现的词,表明句子融合任务不是简单地去除冗余信息,还需要生成一些新的词语。

表1 句子融合测试集相关分析
句子重要词识别数据集。在句子融合数据集上,通过对比原句与融合句中重叠的实词自动标注获得重要词数据集。具体过程为:如果原句中的实词出现在融合句中,则标注为1,否则为0。训练集、验证集和测试集的比例与句子融合数据集相同。
3.2 实验设置与评价指标
对于句子重要词识别,模型参数设置为:词向量维度为300,隐藏层数为3,隐藏层单元个数为200,词的最大长度为4,批次大小为32,学习率为0.015,训练1 000轮,优化函数为Adam。
对于句子融合,为了节省计算量,对词表进行精简,词表规模|V|=13 584。模型其他参数设置为:字向量维度为768,隐藏状态大小为768,具有12个注意力头。根据对数据集的分析,句子长度都比较短,故将文本输入的最大长设为256,输出的最大长度设为110。批处理大小为16,学习率设为1e-5,训练100轮,优化函数为Adam。
重要词识别评价指标。利用精确率、召回率和F1值来评价重要词识别情况。
句子融合评价指标。对模型生成的融合句,使用ROUGE-L、ROUGE-2、ROUGE-1和BLEU指标进行自动评估。ROUGRE-L是通过计算标准融合句和生成的融合句之间的最大公共子序列的统计量,来评价生成的融合句所含的信息量。BLEU通过统计生成的融合句与标准的融合句之间的匹配片段的个数,来评价生成的融合句的合理性与流畅性。
3.3 句子融合的基线系统
由于句子融合是很多生成式摘要系统的重要子任务,所以本文采用性能比较好的摘要生成系统作为对比基线系统。
(1) DRGD模型[9]。该模型面向摘要生成基于深度GRU递归模型学习目标摘要中隐含的结构信息,同时采用VAE作为生成框架来解决推理生成问题,以提高摘要质量。
(2) Struct+2Way+Relation模型[3]。该模型在基于BiLSTM框架的摘要系统中引入Structure-Infused复制机制,将重要词和句法依赖关系从原句复制到摘要句,提升了系统性能。
(3) UNILM模型[14]。该模型是融合了自然语言理解和自然语言生成能力的Transformer统一框架,其核心是通过特殊的Attention Mask来实现不同的语言模型。
本文没有专门与文献[10]中所提基于Transformer架构的模型进行对比是因为本文实验是在基于Transformer框架的UNILM上进行改进,已包含该框架的对比结果。
根据相应文献来源找到对应模型代码,将实验数据换为本文实验所用数据,实验其他设置与原论文保持一致。
本文系统基于UNILM模型结合任务特点进行了改进,实现了较好的实验结果。
3.4 结果分析
3.4.1句子融合结果分析
句子融合的具体实验结果如表2所示。
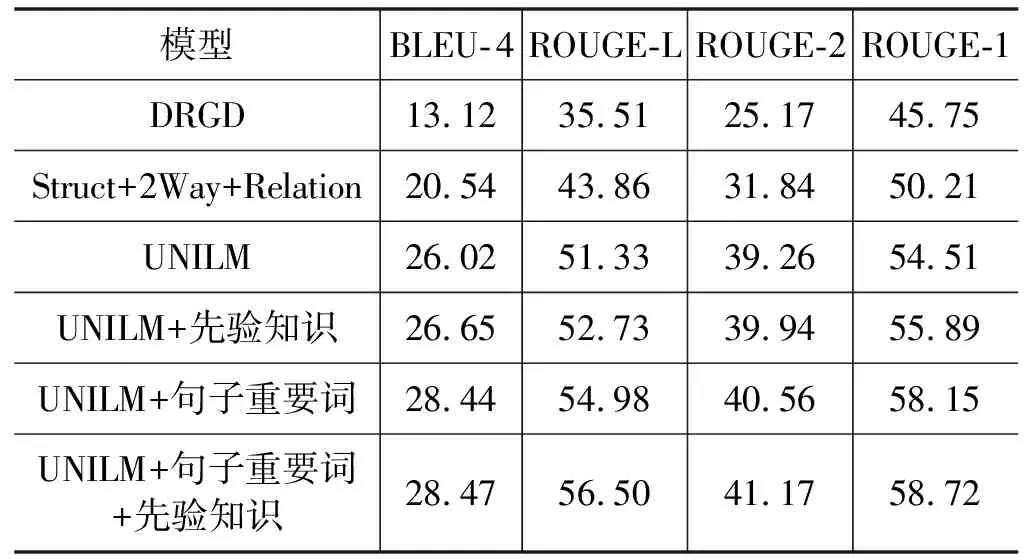
表2 句子融合结果(%)
从表2可以看出,本文所提方法同其他方法相比获得了最好性能。当“UNILM”模型中同时加入先验知识以及句子重要词时,BLEU-4值提升了约2%,ROUGE-L值提升了约5%,ROUGE-2、ROUGE-1也有明显提升,而且加入句子重要词提升效果比加入先验知识更明显,表明如果模型可以正确识别句子的重要信息,就可以得到更准确、流畅的结果。当模型中仅加入先验知识时,BLEU-4、ROUGE-L、ROUGE-2和ROUGE-1也有改进,表明先验知识的引入在一定程度上可以提升句子融合的质量。此外,还发现“UNILM”模型比“DRGD”模型、“Struct+2Way+Relation”模型的效果要好,表明“UNILM”模型拥有更强大的学习能力。
本文从实验结果中随机抽取了100条数据进行分析,部分数据如图3所示。

原句1:“中新网7月21日电据安县人民政府网站消息,2015年7月21日上午,新浪微博出现一则庆安县公安局经刑侦大队副大队长姚永军的妻子王洪涛反映其利用职务之便,贪污受贿、实施家暴的视频。目前已被停职,庆安县人民检察院已介入调查。”标准融合句:“网曝绥化庆安刑侦大队副大队长利用职务之便,贪污受贿、实施家暴,目前已被停职,检方介入调查。”UNILM:“安庆庆安县公安局经刑侦大队副大队长姚永军妻子王洪涛被举报,其妻子王洪涛已被刑拘,检方已介入调查。”UNILM+先验知识:“庆安县公安局经刑侦大队长妻子王洪涛贪污受贿、实施家暴,目前,庆安县检察院已介入调查。”UNILM+先验知识+句子重要词:“庆安刑侦大队副大队长利用职务之便,贪污受贿、实施家暴,目前已被介入调查。”原句2:“人民网:北京11月29日电(记者孝金波)今天,记者从中国铁路总公司获悉,自11月30日起,中国铁路客户服务中心12306网站支付宝账户支付服务功能上线试运行,旅客网购火车票新增一种支付方式。”标准融合句:“人民网:12306网站明日起新增支付宝支付服务功能。”UNILM:“铁路客户服务中心12306网站支付宝账户支付服务功能上线试运行,旅客网购火车票新增一种支付方式。”UNILM+先验知识:“自11月30日起,中国铁路客户服务中心12306网站支付宝账户支付功能上线试运行,新增一种支付方式。”UNILM+先验知识+句子重要词:“12306网站新增支付宝支付服务功能。”原句3:“中新网4月27日电:据外媒报道,《星期日泰晤士报》27日发布年度富豪榜,出生在乌克兰的布拉瓦特尼克成为英国首富。伊丽莎白女王的财富增长1 000万英镑至3.4亿英镑,但却首次跌出了该国的富豪前300强。”标准融合句:“英国公布年度富豪榜:乌克兰裔商人131亿英镑居首,女王3.4亿英镑,首次跌出前300。”UNILM:“英国发布年度富豪榜,出生在乌克兰的布拉瓦特尼克成为英国首富,但首次跌出该国富豪前300强。”UNILM+先验知识:“英国首富布拉瓦特尼克成英国首富,伊丽莎白女王财富增长1000万英镑至3.4亿英镑,但首次跌出该国富豪前300强。”UNILM+先验知识+句子重要词:“英国富豪榜:乌克兰女王成英国首富,女王财富3.4亿英镑,但首次跌出前300强。”
从结果的整体上看,加入先验知识和句子重要词识别两个模块后,在一定程度上改善了融合句子的准确性和流畅性。例如,在示例1中,“UNILM+先验知识”模型输出句子中有更多的词来源于原句;“UNILM+句子重要词+先验知识”模型比“UNILM+先验知识”模型更准确地识别到了原句重要信息,输出的句子更接近于标准融合句。
然而,模型的输出还存一些局限。如示例3中,由于句子中出现多个实体词:“出生在乌克兰的布拉瓦特尼克”和“伊丽莎白女王”,本文模型输出了错误的实体匹配结构,导致融合的句子质量变差。所以,对于出现多个同类实体的情况,还需要进一步进行研究和改进。
3.4.2句子重要词识别
原句重要词识别实验结果如表3所示。
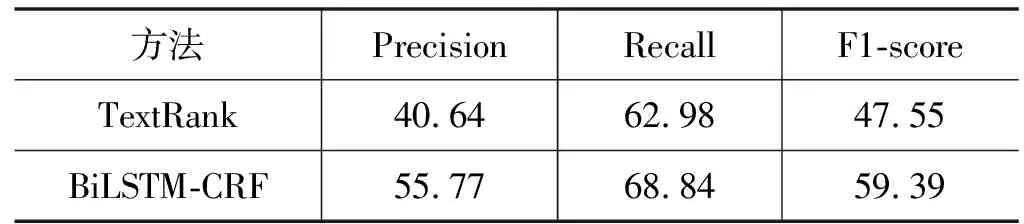
表3 句子重要词识别结果(%)
实验结果显示BiLSTM-CRF模型识别的精确度更高。本文在采用TextRank算法时,在句子中过滤掉停用词,只保留指定词性的词,迭代得到每个词的权重,根据原句子和融合句子的原词率(见表1),本文选取前N(N=m×2/5,其中m为句子的长度)个权重较大的句子重要词。在此过程中,并未考虑句子结构信息,导致标注了部分不重要的词。对于BiLSTM-CRF模型,其考虑了句法信息,以及融合句与原句子的交互信息。从结果数据看,该模型结果虽有提升,但还不理想。所以,提升句子重要词的预测能力将是下一步研究重点。
4 结 语
为了解决句子融合后存在重要信息缺失、语义偏离原句等问题,本文提出了一种基于Transformer和重要词识别的句子融合方法。该方法主要分为两个模块:句子重要词识别模块负责识别原句的重要信息;句子融合模块基于原句重要信息和先验知识生成融合句。实验结果表明,模型取得了较好效果。
然而模型还存在一些局限,如:未能准确获取句子中的实体匹配关系导致融合结果不够好;词语特征构建不充分引起句子重要词识别还不够理想。未来,我们将加强句子重要信息的识别与句子语义关系分析,进一步提升句子融合效果。
