基于数据挖掘的注塑产品质量在线故障检测及预测
2023-08-08陈昱项薇,2龚川
陈 昱 项 薇,2 龚 川
1.宁波大学机械工程与力学学院,宁波,3152112.浙江省零件轧制成形技术研究重点实验室,宁波,315211
0 引言
注塑件生产的高废品率一直是企业面临的普遍问题。注塑过程包含多个子过程,且涉及流体力学、热力学等多个学科[1],这使得最终产品的不合格率远远高于其他机械加工的产品,往往存在5%~10%的残次品。传统质检大多为人工抽检,该方法一方面无法检测所有产品,可能导致大量残次品流入后续加工;另一方面也无法事先预测产品质量,使工厂生产策略的调整具有滞后性,导致企业成本增加[2]。随着工业4.0的导入,智能工厂利用各类传感器采集生产过程中大量有价值的实时数据,为基于数据的智能化生产管控,尤其是产品质量的自动化检测和预测带来了可能性。通过数据挖掘分析,筛选出影响产品质量的关键因素,即可利用生产过程大数据实现人工质检无法完成的全覆盖式质量检测和质量的事前预测,消除传统质量控制的滞后性。
注塑件的质量是产品设计、模具结构、生产材料、工艺参数共同作用的结果[3]。常见的注塑件质量问题包括尺寸精度问题、表面缺陷(熔接痕、气泡、虎皮纹、翘曲等)、内部缺陷。注塑件的冷却收缩会影响尺寸,而尺寸稳定性是影响翘曲的重要因素,所以尺寸精度对注塑成形至关重要[4]。由于注塑过程具有循环性,因此追踪注塑加工过程,对实现注塑件尺寸的自动化诊断具有重要意义。
已有的产品质量在线检测研究主要利用生产数据训练区分产品合格等级的分类器。任黎明等[5]使用深度置信网络建立了各个阶段生产的质量分类规则,并应用Catboost算法进行了在线质量分类。CHEN等[6]利用模内温度和压力传感器提取的数据,开发了一个基于人工神经网络的缺陷在线检测系统来检测产品的尺寸,模型最终的决定系数R2达到91.37%。ABDUL等[7]应用田口方法确定工艺参数对产品尺寸收缩率的影响,并利用人工神经网络模型预测不同工艺参数组合下的收缩率。LI等[8]利用模内传感器收集温度、压力等数据,建立基于模糊逻辑的模型来检测尺寸,并使用田口实验优化工艺参数以提高产品质量。
针对质量预测的研究,曹学晨等[9]通过自回归综合移动平均(autoregressive integrated moving average,ARIMA)模型预测下一产品的工艺特征,构建BP神经网络来建立工艺参数与质量间的关系,用预测的工艺特征来映射质量,并验证了该模型在短期质量预测的可行性。赵圆方[10]提出了基于长短期记忆(long short term memory,LSTM)神经网络的质量预测方法,结合生产中的时序特征,以产品的表面粗糙度与孔径为品质指标进行事前预测,该模型与ARIMA模型和HMM模型的预测结果比较证明了LSTM模型具有充分利用大数据的价值。LEE等[11]提出了一种基于机器学习的产品缺陷检测方法,建立了长短期记忆神经网络,并以前三个周期的数据为输入来预测下一个周期的缺陷,模型在训练后达到了98.9%的准确率和96.8%的召回率。
上述两类研究均是针对工艺参数与质量的关联,没有考虑利用高频传感器获取生产过程数据,无法识别注塑生产中的工况变化,且特征选择策略较为简单。此外,上述研究没对两类质量诊断任务进行集成。实际上,产品质量的在线检测与事前预测关系紧密,质量的事前预测基于在线检测任务的完成,两者成递进关系。
本文在注塑产品尺寸精度的在线检测与预测中引入重要生产阶段采集的实时数据,结合注塑机设定工艺参数数据形成特征集,对该数据集依次采用包裹法、嵌入法、关联规则挖掘(APRIORI)进行三段式特征选择以获得重要特征集。然后基于重要特征构建LightGBM(light gradient boosting machine)分类器来完成产品质量等级的在线检测任务;随后,训练时序预测模型卷积神经网络-长短期记忆网络(CNN-LSTM)来预测重要特征的未来趋势,并结合上述分类器完成产品质量等级的事前预测任务。
1 工件质量诊断的特征工程
要实现产品质量的诊断,首先要确定一个可以表征质量的特征集来映射产品的质量状况。本节按生产阶段将高频特征转化为模次级的统计值,并将其与注塑机状态数据结合成特征集,通过多个机器学习分类模型对特征进行重要度排序,再采用最大信息系数(maximal information coefficient,MIC)衡量重要特征之间的相关性,并以此为依据衡量各特征的关联性,最后采用APRIORI挖掘出与产品质量关系最密切的特征。
1.1 多阶段分析的特征集构建
完整的注塑过程涉及注射、冷却、保压等多个阶段,且各阶段对产品的最终质量都有很大的影响。注塑机配置的传感器按一定的频率采集各阶段的温度、压力等工艺参数的实时值。注塑机状态数据集和质量标签数据集中的数据均按模次记录,即每一个产品对应一个样本。为使工艺参数数据集的粒度与上述两个数据集一致,需要提取工艺参数的统计值(峰值、均值、方差)。合并统计值与注塑机状态数据可以获得更全面的加工过程信息。
1.2 关键特征的选择
特征选择是为了降低数据维度、缩短计算时间、提高算法的预测性能。特征选择可采用过滤法、包裹法和嵌入法。大多数文献采用包裹法中的启发式搜索,即让模型寻找最适合的特征,该方法简单易执行,但结果依赖分类器自身性能,且选择特征的过程缺乏解释性。
本文针对工业数据高维的特点,采用以特征权重为启发式信息的向后搜索算法,挖掘预选特征子集,实现特征降维。为增强预选特征子集的普适性,采用多个向后搜索模型(梯度提升树、随机森林、极度随机树)同时计算各个特征的重要度,并取平均值,得到第i个特征的综合重要度
(1)
式中,m为向后搜索模型的数量;Ii,j为第j个模型计算出的第i个特征的重要度。
按综合重要度进行特征排序,将筛选出的重要特征组成一个预选的特征子集。
将冗余度作为特征之间相关性的评价指标,删去冗余特征,进一步减少特征、提高模型效率。本文引入MIC来判断不同特征之间的关联性。MIC的主要思想是将2个变量置于网格覆盖的二维散点图中,通过统计各个散点落在子格内的频率来计算2个变量的相关系数。计算预选特征子集中各个特征间的最大信息系数:
(2)
(3)
式中,p(x,y)为x、y的联合密度;p(x)、p(y)分别为x、y的边缘密度;a、b为分格数;B一般取数据总量的6次方。
采用APRIORI确定剩余特征与产品质量之间的关联性。生成频繁项集和关联规则后,对挖掘出的关联规则进行统计,识别出与产品质量关联最强的特征条件,并形成最终的特征集。这部分的总流程如图1所示。
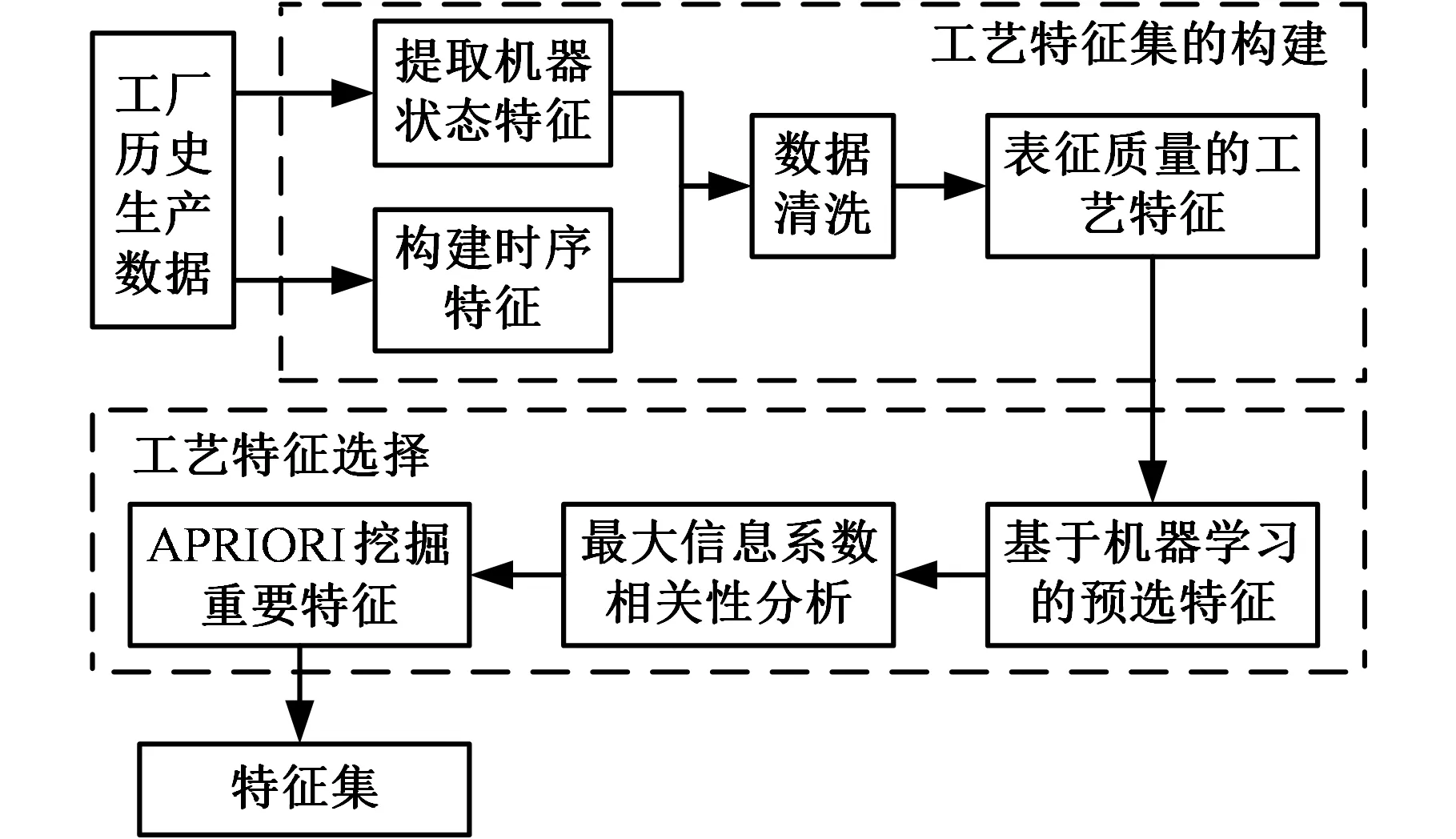
图1 质量诊断特征工程的流程
2 工件质量的诊断
本文将注塑件质量的诊断分为两大任务:①在线检测产品质量,即利用工艺特征的具体数值映射产品的质量等级;②预测产品质量,将时序模型的预测值作为上述分类器的输入,完成对产品质量等级的事前预测。
2.1 工件质量的在线检测
LightGBM是一种实现GBDT(gradient boosting decision tree)算法的框架,具有两大优势:①算法利用单边梯度采样删除小梯度样本,采用遍历直方图来减少内存的占用;②模型采用互斥特征捆绑及最大化分裂增益的方式提高计算效率、减小误差。LightGBM模型可以实现数据的并行处理。将工艺特征作为输入,将产品质量标签作为输出,可以完成产品质量的在线检测。
2.2 关键特征与质量的预测
企业的产品质检通常安排在生产流程的最末道工序,通过人工检查来剔除不合格品,进而调整生产策略、工艺参数。这种方式具有滞后性,属于事后控制。采集的数据是基于模次频率的时间序列,预测工艺特征的趋势以初步预判未来的生产工况,进而指导后续生产中的产品质量控制工作。ARIMA模型是常见的时间序列预测模型,但处理非线性问题的性能一般。XGBoost、LSTM常用于时间序列数据的预测,且能处理非线性问题。LSTM具有遗忘门、输入门和输出门,在训练过程中会自动保留重要信息,并遗忘部分非关键信息,能避免序列过长造成的梯度消失。实际的注塑生产过程复杂,各类潜在因素的变化都会影响工艺特征的走向,导致预测精度下降,限制了LSTM在复杂问题中的应用。
传统的CNN网络由卷积层(convolutional layer)、池化层(pooling layer)、全连接层及输出层组成,其中,卷积层与池化层交替设置。本文将CNN与LSTM集成,利用CNN提取时间序列的局部特征,并将其作为LSTM的输入,这不但可以缩短训练时间,还能有效提高预测的精度[12]。CNN-LSTM模型的结构如图2所示。产品质量等级在线检测和事前预测任务的流程如图3所示。
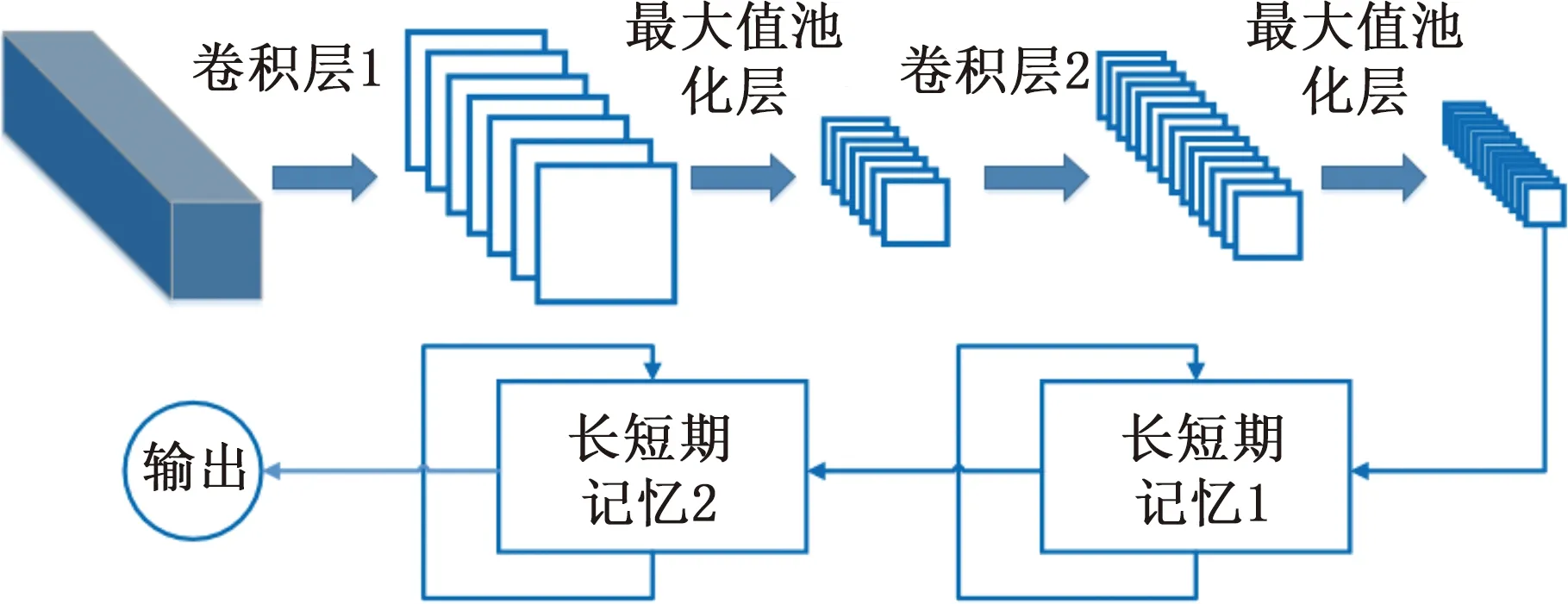
图2 CNN-LSTM的模型结构

图3 产品质量诊断流程
3 算例分析
本文所用数据来自第四届工业大数据竞赛,包括三类数据:①包含冷却时间、保压时间、水循环时间、开模中点、切换位置等特征的注塑机状态数据(每模次记录一组特征);②22个传感器采集的温度、压力、位置的实时值;③每个注塑件的三个尺寸。
3.1 注塑件工艺特征的构建与选择
完整的注塑生产中,注射、保压、冷却、开模这4个阶段对产品的最终质量影响最大。为保障数据集粒度的一致性,将粒度统一为模次级,将这4个阶段各传感器采集数据的统计值(均值、标准差、最大值、最小值、中位数)作为第一个数据集(传感器模次统计数据集)。删除注塑机状态数据集中的单一值及存在大量缺失值的特征,构建第二个数据集(注塑机状态数据集)。最后,根据产品的极限尺寸,将每模次产品的质量分为三类:尺寸均在公差范围内的为合格品(0类);某个尺寸超过公差上限且没有低于公差下限的可返修类产品为一级缺陷品(1类);存在任意尺寸小于公差下限的为二级缺陷品(2类)。按上述分类规则确定第三个数据集(缺陷级别数据集)。合并上述3个数据集并进行数据清洗,余下12 100个样本。特征提取后,特征集中含有480个特征,其中,注塑机状态特征数量为40,高频数据转化的特征有440个。数据集蕴含大量与注塑件质量不相关或冗余的信息,它们会增加计算量和成本,并影响产品质量诊断结果的准确性。为提高预测效率和准确性,需充分挖掘特征信息,从众多特征中识别出代表质量状况的关键特征,具体步骤如下:
(1)选择梯度提升树、随机森林、极度随机树对每个特征的重要度进行评估和排序,并选出每个模型确定的20个最重要特征。将3组特征(共60个)合并,并消去其中的重复特征,形成了一个含有45个特征的预选特征集。
(2)通过特征可视化发现许多特征存在较强的相关性,采用MIC进行特征相关性分析。本文将衡量阈值设置为0.85,即2个特征的MIC值超过0.85时,删除综合重要度较低的特征以减少冗余,重复该操作直至余下特征间的MIC值均小于0.85。操作后选择的特征子集如表1所示。

表1 选择的特征子集
(3)为使选择的特征具有更好的解释性,采用关联规则挖掘分析特征与产品质量的关系。为避免过拟合采样产生大量的非真实数据,对样本进行欠拟合采样即删去多数类的部分样本,使各类样本的数量相同。K-means算法可以将连续的特征数据离散为APRIORI能处理的布尔型变量。本研究使用K-means算法将每个特征分为4个簇,每一簇表示为一种特征条件。
本文将最小支持度设为0.15,将支持度大于0.15的事务集作为频繁项集。然后进行规则挖掘,将最小置信度设为0.95,获得了1904条满足最小置信度要求的强关联规则(2条关于合格产品的规则、528条关于一级缺陷的规则、355条关于二级缺陷的规则)。从这些规则中找出与产品质量关联的因素(特征条件),并统计出现次数。F1、F3的特征条件出现的次数明显小于其余特征,即它们对质量的影响不大。最后采用注射阶段的模内压力1均值、开模阶段的回水温度中位数、保压阶段的模内温度2的中位数和峰值、注射阶段的公模温度2均值构成最终的特征集。
3.2 注塑件质量分类模型的构建
使用构建的数据集进行多分类模型的训练。不同特征参数的数量级相差较大会影响模型的训练,为此,首先对特征进行标准化:
(4)
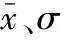
随机提取482个样本组成测试集,将剩余的11 618个样本按7∶3随机划分为训练集和验证集。由于该数据集中产品的合格率约为90%,存在严重的样本不平衡问题,因此采用过拟合采样(SMOTE)生成少数类样本。选择了人工神经网络(ANN)、XGBoost、LightGBM、随机森林(random forest)算法进行质量分类。本研究为三分类问题,选用准确率A、查准率P、召回率R、f1分数的宏平均F1来评价多分类模型,它们的计算公式如下:
(5)
(6)
(7)
(8)
式中,m为类别数;tp,i为类别i正确预测为正例的样本数;tn,i为类别i正确预测为负例的样本数;fp,i为类别i错误预测为正例的样本数;fn,i为类别i错误预测为负例的样本数。
本文将A、P、R、F1作为模型的评价指标。使用训练集数据对各模型进行训练,并用验证集的数据和网格搜索的方式确定各模型中的超参数。调参的目的在于提高模型对不合格品的分类精度,防止不合格工件流入后续加工,同时不过于牺牲模型对合格品的分类精度。LightGBM模型需要确定最大叶子节点数(num_leaves)、最大深度(min_child_samples)、基学习器数(n_estimators)、学习率(learning_rate)等参数,调整后,模型参数的值如表2所示。

表2 LightGBM的调参结果
采用调参后的模型对测试集进行分类,以A和F1为评价指标。由表3可以看出,测试集的结果略好于验证集,但相差不大,证明了LightGBM模型的鲁棒性。利用验证集对另外3个模型进行超参数调整,确定模型的最优结构。

表3 LightGBM在验证集与测试集上的分类精度
为验证本文特征选择法的优越性,使用GBDT获取另一组重要特征,将2组特征作为各分类模型的输入进行训练,并在验证集上完成调参。分类器在测试集上的分类结果如表4所示,可以看出,4个分类器以本文提出的特征选择法确定的特征集为模型输入,产品质量分类的准确率A及f1分数的宏平均F1增大,证明了本文提出的特征选择法的优越性。

表4 各模型在两种情况下的分类精度
图4所示为各个模型在测试集上分类后的混淆矩阵,可以看出,各模型对缺陷1、2的分类精度较高,对合格品(0类)的分类精度相对较低。工厂一般希望提高对不合格品的检测能力,防止缺陷产品进入后续加工,避免产生不必要的生产成本。

(a)LightGBM (b)Random forest
4个模型的各项分类评价指标如表5所示,可以看出,LightGBM优于其他模型,在测试集上的综合分类精都最高,其中,其召回率R达到了0.891,f1分数的宏平均F1为0.552。

表5 各模型的分类精度
3.3 注塑件质量的事前分类预测
在产品质量的事前预测开始前,先从数据集中剔除上述在线检测任务中的测试集,再按8∶2的比例将剩余的数据划分为训练集、验证集。采用特征的60个历史值来预测下一模次的值。预测模型采用带卷积的长短期记忆网络(CNN-LSTM),并训练LSTM和XGboost用于预测精度比较。所有模型均为单输出,需要为每个特征建立一个预测模型。为评估时序预测模型的预测精度,将均方误差(MSE)作为评价指标。
模型训练完成后,采用验证集调整模型的参数,调整后的CNN-LSTM模型结构如表6所示,其中,n为样本数。

表6 CNN-LSTM的模型结构
然后对测试集样本进行预测,首先根据模次号提取测试集中各个特征前60步的特征值,并将其作为CNN-LSTM模型的输入,得到482组预测值。各时序模型的预测误差如表7所示,可以看出,CNN-LSTM预测值的均方误差最小,预测最准确。最终,将特征的预测值作为LightGBM分类器的输入即可对产品质量进行事前预测。

表7 不同模型对各特征预测的均方误差
为有足够的时间应对可能出现的不合格品,预测未来5个模次产品的质量,首先预测每个特征未来5个模次的具体值,然后将其输入到分类器,实现多步预测。预测结果与在线检测结果如表8所示,可以看出,事前预测的分类精度略低于在线检测,且预测精度随时间的延长而下降,但精度下降不快,仍可判断未生产注塑件的质量,因此将事后处理转化为事前预防,给予工厂更多时间来应对不合格产品的出现。

表8 产品质量检测与预测的分类精度
4 结论
(1)将传感器收集到的模内温度、压力、位移等数据转化为按生产阶段划分的统计值,构建了一组可以表征工况变化的特征,并将其与注塑机状态特征合并,形成总特征集。
(2)采用多个向后搜索算法预选特征子集,并利用最大信息系数评估该特征子集中各元素的相关性,减少特征集的冗余。采用APRIORI分析剩余特征与产品质量的关系,确定与产品质量关联性最高的特征,提高质量诊断系统的效率。
(3)训练LightGBM模型对产品质量进行在线检测以完成质量分级;采用带卷积的长短期记忆网络等时序模型对重要特征的未来趋势进行预测,并结合分类器完成了产品质量的多步事前预测。
