深度学习在IP网络优化中的应用
2023-08-04曾汉徐晓青钱刘熠辉武娟
曾汉 徐晓青 钱刘熠辉 武娟
(中国电信股份有限公司研究院,广州 510000)
0 引言
云网融合的不断推进和VR/AR等新业务的不断涌现,使得IP网络更加复杂。新需求引发的大量流量和数据中心的不断涌现,改变了传统网络的流量分布。复杂动态的流量分布需要结合相关人工智能技术来实现更精准的预测和更合理的调度。此外,随着软件定义网络(Software Defined Network,SDN)的广泛应用,复杂的网络业务流量需求给现有的网络路由算法提出了更大的挑战。为了满足多样化的服务需求,不少基于机器学习的路由优化算法被提出,然而该算法的研究方向主要在于其合理性和收敛性,相对缺乏在真实场景下训练和部署的研究[1]。同时,随着5G的发展,通信与人工智能将进一步深度融合,通信各个领域对网络智能化的需求会大量增加[2]。
网络智能化需求的增加,为现有的IP网络优化算法研究拓宽了更多探索方向,同时也为数据驱动算法创造了更广阔的应用空间。近年来,随着机器学习与深度学习的发展,数据驱动算法已经在一些领域得到了广泛应用。其中深度学习是目前数据驱动算法中最重要的一个分支,它通过学习大量样本数据的内在规律,捕捉数据的重要特征,进而实现对数据的分类、回归或预测等,从而具备感知和分析的能力。图神经网络是深度学习的一个分支,对图结构数据具有更强的感知与分析能力,适用于IP网络的特征表示,因为IP网络本质可抽象成一张图。深度强化学习是深度学习与强化学习结合的产物,对大规模空间的最优化问题有较好的求解能力,且基于深度强化学习的算法在通信网络的业务场景中已经做了不少尝试[3]。
本文介绍了常用的深度学习和深度强化学习算法,总结了研究人员在几种场景下的设计思路,希望为在现网实施相关算法和模型提供参考。首先,介绍了深度学习和深度强化学习的基本模型,其中包括全连接神经网络(Fully Connected Neural Network,FCNN)、循环神经网络(Recurrent Neural Network,RNN)、图神经网络(Graph Neural Network,GNN)、深度Q-网络(Deep Q-Network,DQN)、深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG);其次,收集了深度学习与深度强化学习在IP网络不同场景(流量预测、网络规划和流量工程)的应用;最后,探讨了深度学习和深度强化学习的行业现状、存在的挑战和研究方向。
1 基于深度学习的IP网络优化算法
1.1 应用于IP网络优化的深度学习算法概述
深度学习是指机器学习中基于神经网络对输入数据进行表征学习的方法。“深度”指含多个隐藏层的学习模型,通过深度学习可以组合低维度特征形成高维度的属性、类别或特征。随着计算机算力的大幅度提升,深度学习将更为普及和实用。
全连接神经网络也称前馈神经网络或多层感知机,由输入层、全连接层和输出层3部分组成,每一层都由若干个神经元组成,其模型结构如图1所示。在前向传播中,下一层神经元的值是上一层所有神经元数值的加权叠加,数据经多层全连接层的传递被不断压缩和提炼,最终传递给输出层,因此在未添加激活函数的情况下,输出层神经元值可以表示为输入层神经元值的线性组合。输出层通过与实际结果对比得到损失函数,并以反向传播的形式逐层更新神经元加权权重,从而不断优化全连接网络的连接方式,得到从输入数据映射至输出数据的最佳网络参数。全连接网络在处理特征分布一致的数据时有着非常好的工作效率和准确率,但在实际应用中,需要进行预测的数据往往有着不完全一致的特征分布,全连接网络训练得到的分类器或回归器对于训练数据以外的样本鲁棒性较差,模型整体的新数据泛化能力较低。
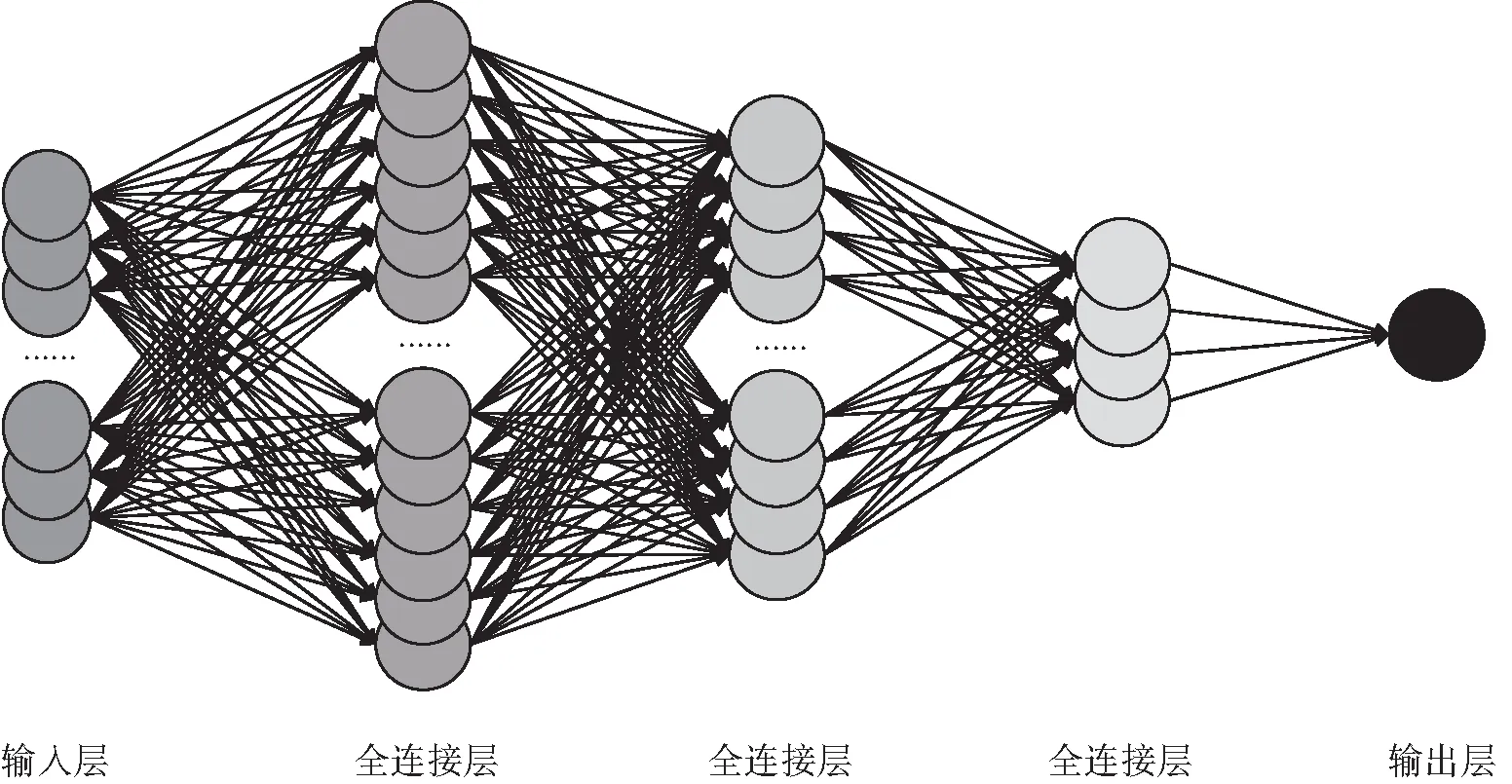
图1 全连接神经网络结构
循环神经网络是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。RNN引入了“记忆”的概念,其输出依赖于之前的输入序列,具体体现在RNN通过隐藏状态来存储之前时间步长的信息。
当时间步长较大时,循环神经网络的梯度计算容易出现梯度衰减或梯度爆炸,这导致循环神经网络在实际应用中难以捕捉时间序列中时间周期较大的变化趋势,而门控循环单元(Gated Recurrent Unit,GRU)和长短期记忆(Long Short-Term Memory,LSTM)可以解决这个难题。
GRU是一种常用的门控循环神经网络,它引入了重置门和更新门的概念。重置门和更新门的计算公式和RNN中隐藏状态的计算一样,选取Sigmoid函数作为激活函数,将重置门和更新门的参数值约束至[0,1]之间。两个门控的不同点在于:重置门的优化目标是控制上一时间步的隐藏状态以怎样的权重流入当前时间步的候选隐藏状态;更新门的优化目标是选择最佳的加权系数组合上一时间步的隐藏状态和当前时间步的候选隐藏状态。
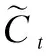
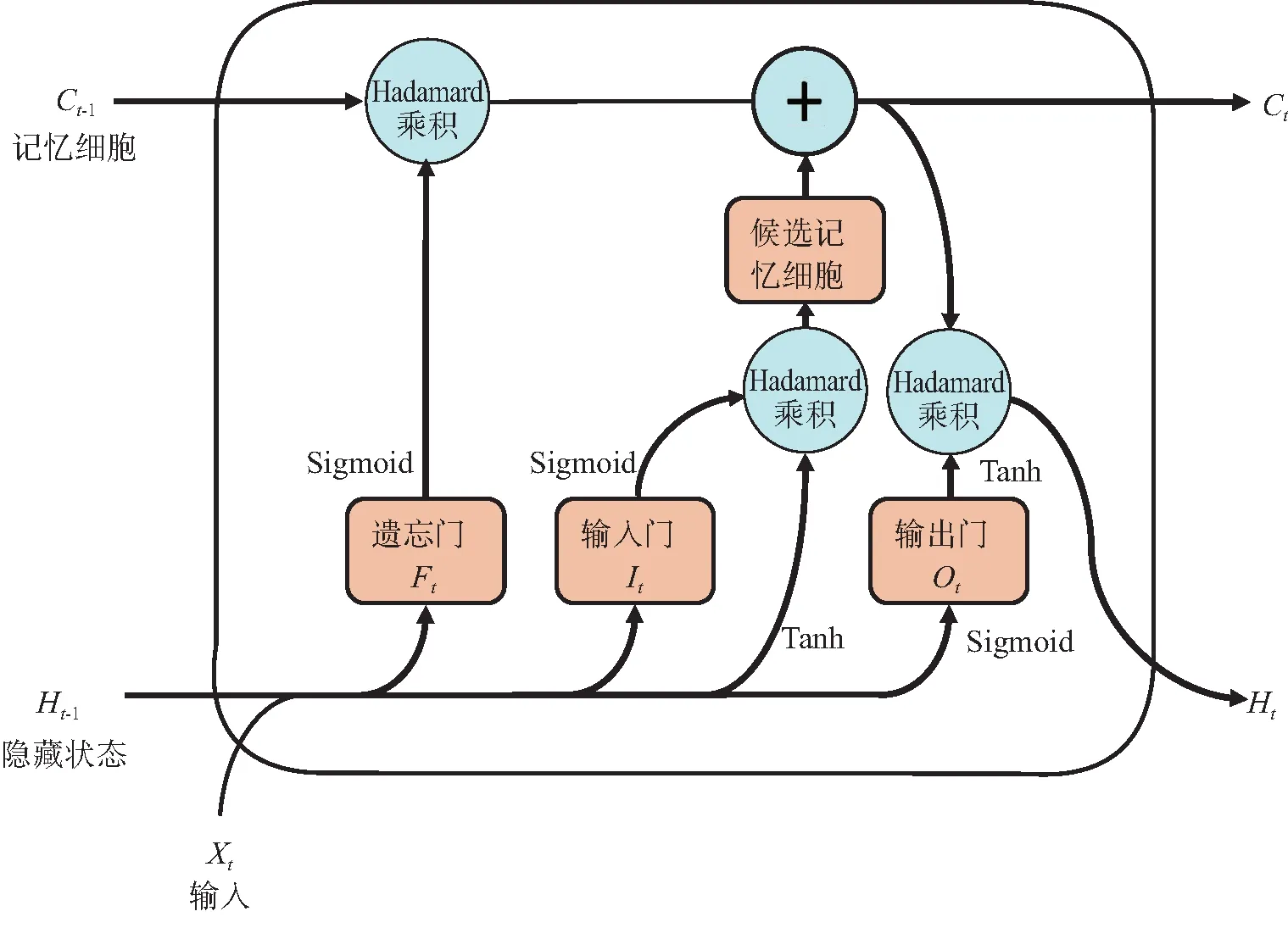
图2 LSTM内部结构
与GRU相比,LSTM由遗忘门和输入门产生新的状态,而GRU只有一种更新门;LSTM可以通过输出门调节新产生的状态,而GRU对输出无任何调节。因此,LSTM在模型结构上更加强大和灵活,有着更好的特征表达能力,但也引入了额外的计算开销。
图神经网络是指将神经网络技术运用在图数据的学习任务中的一大类方法。GNN的发展起源于对图卷积神经网络(Graph Convolutional Neural Network,GCN),其中GCN分为谱域和空域两类。谱域GCN的卷积操作通常作用于图拉普拉斯(Laplace)的特征值矩阵上,一般只能作用于一张图,限制了跨图学习能力和泛化能力;而空域GCN以压缩映射原理(Banach不动点理论)为基础,相对谱域GCN而言,空域GCN研究成果更为丰富。空域GCN本质上是一个迭代式的聚合邻居的过程,一方面大部分空域GCN的成果本质是对聚合操作的重新设计(基于GCN发展而来的模型统称为GNN),例如GraphSAGE(Graph SAmple and aggreGatE)、图注意力网络(Graph Attention Networks,GAT)、关系图卷积网络(Relational-GCN,R-GCN);另一方面,一些研究人员将具体的GNN设计解构,抽象为GNN设计范式,例如消息传播神经网络(Message Passing Neural Network,MPNN)、非局部神经网络(Non-Local Neural Network,NLNN)、图网络(Graph Network,GN)。
1.2 基于深度学习的IP网络优化算法
网络流量预测通过捕捉流量数据的特征,依据历史流量数据规律推断未来的变化,是IP网络优化的基础。预测的准确度会直接影响网络规划和流量工程的最终结果,因此网络流量预测也是网络规划和流量工程的基础。基于循环神经网络的深度学习算法适合处理序列数据,是捕捉数据时间关联性的常用手段,广泛应用在时间序列预测的场景中。GRU,特别是LSTM的引入使得RNN捕捉短时时序特征的能力增强。
Vinayakumar[4]等将RNN框架应用在网络流量预测上,分别将LSTM与GRU、identity-RNN、RNN的预测结果进行比较。具体使用了泛欧学术网络的流量矩阵数据(采样间隔为15 min),将每个流量矩阵展平为流量矩阵向量,按时间顺序拼接成新流量矩阵,采用时间窗口的形式处理新流量矩阵以得到样本与标签。通过比较几种循环神经网络的预测结果与标签的均方误差(Mean Squared Error,MSE)得出以下结论:在网络流量预测的场景下,LSTM比其余基于RNN框架的算法表现更优异。
Ramakrishnan[5]等沿用Vinayakumar等人的处理方法,扩大了LSTM的比较范围并对算法的应用场景进行了拓展,包括网络协议预测和网络协议分布预测。具体而言,使用了Abilene数据集(采样间隔为5 min),将RNN、GRU、朴素预测(Naive Model,NM,即使用上一时刻的值作为预测值)、移动平均(Moving Average,MA)和自回归综合移动平均(Autoregressive Integrated Moving Average,ARIMA)算法与LSTM进行比较。在网络流量预测和网络协议分布预测的场景下,比较各个模型的预测结果与标签的MSE可知,LSTM的表现优于RNN和GRU,RNN框架的表现优于NM、MA和ARIMA。无论是回归任务还是分类任务,LSTM都有更优异的表现。
Hua[6]等就降低计算开销方向对LSTM进行了改进,提出了随机连接长短期记忆(Random Connectivity Long Short-Term Memory,RCLSTM)框架,有效降低了计算开销。通过比较RCLSTM、LSTM和其它常用算法模型分别在网络流量预测和用户位置预测场景中的预测效果,论证了在部分计算资源受限的条件下,RCLSTM比LSTM更具优势。RCLSTM的神经元之间是随机连接的,连接策略可以遵循任意分布规律,且允许调整临界值来控制神经元连接的数量。在网络流量预测场景中,研究人员使用泛欧学术网络公开数据集的流量矩阵数据,比较了各个算法模型的预测结果与标签的均方根误差(Root Mean Squared Error,RMSE),得出RCLSTM在这些场景下表现更优且计算开销更低的结论;在用户位置预测场景中,使用多个移动通信用户的位置数据,比较预测结果的准确率并得出RCLSTM的表现略差于LSTM但计算开销更低的结论。
Theyazn[7]等从预处理环节提出了一个智能混合模型,将当前的时间序列预测模型与聚类模型相结合以提升网络流量预测的效果。该聚类模型使用模糊C-均值(Fuzzy-C-Means,FCM)作为聚类颗粒来分类流量数据,并使用加权指数平滑模型以提升预测结果稳定性。使用该聚类模型对网络流量数据进行预处理,可以提升LSTM的预测效果。此外,还使用4G基站网络流量(来自Kaggle数据集)和广域网流量(日本骨干网数据)作为输入,使用消融试验证明了该聚类模型可以提升预测效果。
与此同时,He[8]等基于图神经网络提出一种新的深度学习模型——图注意力时空网络(Graph Attention Spatial-Temporal Network,GASTN)。与之前的研究相比,该模型对数据的空间特征有更好的捕捉能力,能够同时捕捉局部空间特征和全局空间特征。GASTN通过构建空间关系图来建立空间关联性捕捉模型,并用递归神经网络为捕捉时间关联性进行建模。此外,为了提升GASTN的预测效果,研究人员提出了一种全局—局部协作学习策略,并充分利用全局模型和各区域的局部模型的知识,提高了GASTN模型的有效性。在流量数据预测中,他们使用大规模真实场景的移动流量数据,比较GASTN、历史均值(Historcal Average,HA)、ARIMA、多层感知机(Multiple Layer Perceptron,MLP)、LSTM、CNN-LSTM和STN(结合ConvLSTM和3D-ConvNet的深度时空网络)流量预测结果的RMSE、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、平均绝对误差(Mean Absolute Error,MAE)指标,证明了GASTN在流量数据预测任务上准确率更高。此外,他们使用消融试验验证了两层注意力网络的有效性,并在GASTN的基础上使用不同的学习策略来验证全局—局部协作学习策略的有效性。
2 基于强化学习的IP网络优化算法
2.1 应用于IP网络优化中的强化学习算法概述
强化学习(Reinforcement Learning,RL)是指环境中的智能体按照一定策略做出一系列决策以完成给定任务,求得最优策略使得回报最大化的过程。强化学习要重点考虑预测和控制两个问题,即策略评估和求解最优策略。强化学习本质上属于序列决策问题和优化问题,因此强化学习问题可以采用马尔科夫(Markov)模型表示,并基于此进行优化。
如果未来状态只与当前状态有关,则称该状态具有Markov性,特别地,如果St具有Markov性,用P表示条件概率,则上述定义如式(1)所示。
P[St+1|St]=P[St+1|S1,S2,…,St]
(1)
一个Markov决策过程,可以用四元组(S,A,P,R)表示,其中S表示状态集,A表示动作集,P表示转移概率,R表示奖赏。一般来说状态、动作和奖赏均为随机变量。强化学习的重要任务之一是策略评估,即需要定义状态值函数(每个状态的价值)及Q-值函数(指定状态下某个动作的价值)。
vπ(s)=Eπ[Gt|St=s]
(2)
qπ(s,a)=Eπ[Gt|St=s,at=a]
(3)
贝尔曼(Bellman)方程定义了状态值函数和Q-值函数的递推关系,在指定策略π下(π(a|s)表示在状态s下,执行动作a的概率),状态值函数vπ(s)和Q-值函数qπ(s,a)定义分别如下:
vπ(s)=Eπ[Rt+1+γGt+1|St=s]=∑aπ(a|s)
∑s′,rp(s′,r|s,a)[r+γvπ(s′)]
(4)
qπ(s,a)=Eπ[Rt+1+γGt+1|St=s,At=a]=∑s′,r
p(s′,r|s,a)[r+γ∑a′π(a′|s′)qπ(s′,a′)]
(5)
强化学习另外一个重要任务是求解最优策略。对于策略π和策略π′,如果对于任意状态有vπ(s)≥vπ′(s),则称策略π是优于策略π′的,记为π≥π′。如果至少存在一个策略比其他策略好,则这个策略为最优策略,记为π*。
深度强化学习(Deep Reinforcement Learning,DRL)将深度学习与强化学习结合起来,将强化学习的逼近任务用深度学习算法来完成。常见的DRL算法有DQN、DDPG等。DQN使用深度神经网络来逼近最优Q-值函数,即式(6):
(6)
即逼近一个最优策略π使得在给定的状态st下执行动作a能获取最大的期望汇报。DQN有两个特殊的机制,一种是随机抽样,从经验数据随机抽样,以消除观测序列的相关性并减缓数据分布的变动;另一种是目标量周期变动,使用迭代更新的方式让Q-值朝着目标量变动,而目标量设置为周期性变动,减少Q-值与目标量的相关性。基于这两个机制可以让非线性的神经网络在逼近Q-值函数时趋于稳定而避免发散。
除了DQN逼近Q-值函数的思路之外,另一个思路是逼近策略。策略梯度(Policy Gradient,PG)是早期逼近策略的强化学习方法,为了减少训练过程中参数的方差,通常采用演员-评论家(Actor-Critic,AC)框架。但PG输出的是一个概率分布函数,本质上是一个随机的策略。于是,2014年D.Silver[9]提出了确定性策略梯度(Deterministic Policy Gradient,DPG),将PG中的概率分布函数映射为一个确定的动作。随着DQN的成功,2016年Deepmind[10]受其启发基于DPG算法进行改进并提出了DDPG算法,采用深度神经网络作为策略函数μ和Q-函数的近似(即策略网络和Q-网络),最后用梯度优化的方法来训练这两个网络。
2.2 基于强化学习的IP网络优化算法概述
强化学习应用于IP网络优化问题的主要场景有网络规划和流量工程。网络规划是一类NP-难(Non-deterministic Polynomial hard,NP-hard)的组合优化问题。一般来说,可以将其建模为整数线性规划(Integer Linear Programming,ILP)问题,约束条件可以基于一系列相关的QoS和SLA要求进行设置,目标函数可以设置为相关的成本。但是ILP本身也是NP-难的组合优化问题,经典方法是通过分支定界法、割平面法等指数时间算法求得精确解,对复杂大规模网络规划问题的求解存在困难。流量工程是通过控制网络的路由策略来改变网络流量分布,优化网络资源的分配和提升网络的性能,要求算法有更低的时间复杂度以及更少的资源调度。
Zhu[11]等结合GNN、DRL与ILP提出了网络规划框架——NeuroPlan。首先使用GNN对节点和连接进行动态编码,目的是应对规划过程中网络拓扑的动态性质;其次,使用两阶段混合方法,先用DRL修剪搜索空间,然后使用ILP求解器找到最优解。与手动调整的启发式算法相比,它可以降低约17%的目标函数值;与ILP相比,则能求解更大规模的网络规划问题。
胡道允[12]等基于SDN提出了一种基于深度学习的流量工程算法(DL-TEA)。在仿真场景下,将该算法与模拟退火和贪婪算法进行比较发现,在平均时延、请求平均占用带宽和网络阻塞率上DL-TEA略差于模拟退火,但优于贪婪算法;在耗时上DL-TEA远优于模拟退火,略优于贪婪算法。这表明DL-TEA不仅能够实时地为业务计算一条高效的路径,同时还能够提升业务的QoS、网络资源利用率,降低网络阻塞率。
兰巨龙[13]等为解决SDN场景中QoS优化方案常因参数与网络场景不匹配出现性能下降的问题,提出了R-DRL算法。该算法基于LSTM和DDPG,首先统一网络资源和状态信息,然后通过LSTM获取流量的时序特征,最后使用DDPG生成满足QoS目标的动态流量调度策略。试验结果表明,相较于现有算法,R-DRL算法不但保证了端到端传输时延和分组丢失率,而且提高了22.7%的网络负载均衡程度和8.2%的网络吞吐率。
Zhang[14]等提出将关键流重新路由强化学习(Critical Flow Rerouting-Reinforcement Learning,CFR-RL)方法应用于路由规划。只对关键流进行重新路由可以缩小对网络流的调度规模,减轻大规模网络流调度产生的负面影响。由于关键流的搜索空间巨大,且无法使用基于规则的启发式算法应对动态拓扑场景,所以选择强化学习作为算法框架。主要使用CFR-RL自动在流量矩阵中选取关键流,之后通过求解简单的线性规划来重新路由这些关键流以平衡链路的利用率。试验结果显示,CFR-RL可以在仅重新路由10%~21.3%全局流量的情况下达到近似最优解。
Sun[15]等提出使用多智能体元强化学习(Multi-Agent Meta Reinforcement Learning,MAMRL)解决路由优化问题,使用同为分布式无模型路由算法的深度策略梯度算法与MAMRL进行比较。MAMRL得益于与模型无关的元学习,能够迅速适应拓扑改变的场景。为验证MAMRL的性能,使用多个广域网拓扑进行模拟,其在数据包级的模拟场景下的结果显示:与传统最短路径算法和传统强化学习方法相比,即使在需求激增的情况下MAMRL也能显著降低数据包的平均传输时间;与非元深度策略梯度方法相比,在链路故障的情况下MAMRL能在较少的迭代次数内可观地减少数据包的丢失数量,从而降低数据包的平均传输时间。
3 IP网络优化算法面临的挑战
数据的质量和规模是深度学习的基础。但是在实践过程中,受成本和采集技术所限,用于深度学习的数据往往不能达到预计的质量和规模,从而使得深度学习模型难以直接适用于现网场景。以流量预测为例,流量预测是大部分网络规划和流量工程算法的关键输入,其准确度直接影响到其他任务的结果。对于流量预测而言,数据的采样间隙越小,预测误差越小,采集成本也会越高。流量采样需要消耗一定的带宽和存储资源,深度学习也要消耗相应的算力资源,而在现网中需要实时预测时,需要尽可能降低算法和模型的复杂度。如何在低成本和低资源消耗下保持合理的预测精度,是现网实际应用中需要考虑的问题。此外,还需考虑相关的数字孪生技术,通过模拟环境得到一些数据,也可能通过数据增强等扩充数据,如依靠生成对抗网络来产生一些数据。
另外,深度学习类似于“黑盒”,缺乏一定的解释性,在现网应用中会引入一系列问题,无法了解算法做出相应决策的逻辑。若出现某些应用场景失效而造成网络故障,不仅会导致相关SLA的违背,还可能引发其他严重后果。此外,网络往往是动态变化的,也要求相关算法和模型具有一定的泛化性。深度学习和深度强化学习的模型中存在大量的超参数,一个良好的模型通常需要依赖恰当的调参才能得到。如何选取合适的算法模型进行调参,是相当复杂的过程,虽然已有一些自动化调参方法,但尚处于初期阶段。因此,如何设计出成本较低、具备可解释性和较好泛化效果的算法和模型,是目前研究的难点。
与此同时,深度学习模型在云网边端的部署和协同问题需要深入分析;如何融合相关行业知识、结合传统优化算法使得求解问题更高效,也值得从业人员进行探索。
4 结束语
本文总结了深度学习和深度强化学习目前在IP网络优化中的相关算法、模型和应用方向,并分析了其主要存在的问题。目前来看,深度学习和深度强化学习方法在IP网络优化相关场景下的应用具备一定优势,并取得了一些积极效应,但同时也面临着数据采集难、训练成本高、缺乏可解释性和泛化能力、真实场景部署难等问题,需要相关从业人员进一步的研究和攻克,从而推动网络智能化的发展。
