水资源取用水数据畸变智能处理技术研究
2023-08-03王铭铭
王铭铭,贾 飞
(1.安徽省(水利部淮河水利委员会)水利科学研究院(安徽省水利工程质量检测中心站),安徽 合肥 230094;2.安徽省大禹水利工程科技有限公司,安徽 蚌埠 233060)
1 引言
我国淡水资源总量为28000 亿立方米,人均水资源量仅为世界平均水平的1/4,属于全球人均水资源最贫乏的国家之一。工业的快速发展伴随着水资源的粗犷式开采和高耗式利用,我国万元GDP 耗水量是世界平均水平的4 倍。长期的粗犷式发展导致可持续发展战略与水资源的矛盾日益凸显,严重制约社会经济发展。围绕国家水资源监控能力项目建设需求,开展水资源监管领域技术研究,是实行最严格的水资源管理制度最重要的技术保障措施之一。
随着水资源取水监测系统的持续建设,安徽省已率先完成3000 余处取水监测点的在线监测,在系统运行维护管理中,取水监测数据归零及畸变问题,已成为影响取水数据统计及应用的重难点。据研究,由于仪表显示的位数有限,一些取水大户计量设备满量程后,常出现归零问题。此外,在取水数据采集、传输过程中由于信号干扰等因素的影响,易造成数据错位或畸变现象,严重影响取水户水量的统计和系统的正常应用。
目前,尚无针对取水计量数据归零及畸变问题的专题研究,国家水资源取水监控数据均采用人工巡查与处理的方式进行管理,其时效性与准确性均难以达到要求,已严重制约国家水资源监控能力建设项目的效益发挥。随着水资源取水监测站的持续建设,站点数据进一步增加,仅依靠人工进行数据巡查及后期处理已不现实,也难以满足水资源取水数据精细化管理需求。本文基于安徽省水资源取水计量监控项目,为提高取水数据质量、降低取水数据巡查与管理难度及减轻取水数据管理的压力,课题长期对取水数据归零及畸变数据特征进行跟踪研究,最终通过大数据挖掘技术,以对归零及畸变数据自动甄别、及时处理为目的,研究出取水数据归零与畸变的智能甄别处理系统,以保障取水数据的精确采集、统计及应用。
2 数据畸变原因分析
基于对已建安徽省水资源取水监控数据的长期跟踪研究,归零数据常出现在大型取水监测点,作为计量仪表满量程后出现的累积流量自动归零的现象,影响取水点流量的正常计算。而畸变数据是在数据传输过程中受到信号干扰因素而产生的。当监测设备安装点有电子类工程施工、电焊施工、变频干扰或设备本身故障等一些干扰因素存在时,计量数据传输易受影响,常导致数据丢包、小数点错位等畸变现象。
通过对安徽省的3000 余处水资源取用水样本点开展了调研,发现省内各取用水户选用的计量设备各不相同,其计量设备显示方式、计量量程、设备安装环境等各不相同,现场存在的干扰因素亦各有特点,甚至部分企业本身的生产工作亦存在对计量监测设备的数据传输造成干扰。经研究,取水数据的归零和畸变的诱因甚多,难以对现场环境的监测进行甄别与诊断,故课题采用水资源取水大数据分析方法,开展基于数据挖掘等技术手段的取水归零及畸变数据纠错研究。
3 算法设计与软件实现
3.1 研究基础
数据畸变智能分析需要建立在取水户、行业取水的多年监测数据基础上进行,需要具备海量的取水原始数据及大量的畸变数据处理样本。安徽省水资源取水监控经过5 年的建设,已实现对3000 余处水资源取水点的监测,系统已积累约20GB 的原始取水计量数据,为取水数据的研究提供原始数据基础。此外,安徽省水资源取水监控系统多年的运行管理经验和积累的13000 余条人工处理数据归零及畸变数据,提供了充足的研究样本。
3.2 研究思路
课题研究以取水监控系统中原始采集数据为基础,经对26000 余组畸变数据处理特点的归纳和分析,采用寻找取水数据期望的方法,对取水历史数据进行聚类,由正常数据和异常数据形成多个聚簇,通过确定最新数据的水量累计值、小时用水量、日用水量是否命中相对应的聚簇内,以甄别该数据是否为归零或畸变数据,最终根据对数据的甄别结果,对数据进行入库、纠错或抛弃等处理。
3.3 取水数据纠错算法设计
3.3.1 K-Means 算法
K-Means 算法是一种基于样本间相似性度量的间接聚类方法,其中心思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的类聚内紧凑,类间独立。由于其对样例数据量的要求不高,在小规模数据中仍能够较为准确地计算出聚类结果,因此具有简单、快速等特点,在处理大数据集时效率较高,特别当结果聚类密集,且聚类与聚类之间区别明显时,该算法应用效果明显。
水资源取水监测数据站点较多,对数据计算时效性要求较高。此外,畸变或归零数据簇与聚类簇之间具有明显的区别,因此文章选择K-Means 算法作为水资源取水畸变数据甄别算法的理论基础。
3.3.2 取水数据纠错算法实现
在K-Means 算法中唯一需要去确认的值为K值,在K 值确定后需通过中心的迭代,以实现中心点收敛。为实现水资源取水畸变数据甄别,课题研究随机选取k 个聚类中心点(clustercentroids)μ1,……,μk,重复下面过程直到收敛。
对于每一个样例i,计算其应该属于的聚类:
对于每一个聚类j,重新计算该聚类的质心:
基于以上两步的不断进行数据收敛,通过程序递归,最终得到唯一的收敛值,以确定最终收敛的k 个中心。当得到收敛中心时即与之前的中心进行比较,从而诊断其是否为畸变数据。在程序的不断应用及完善中,我们通过程序经验和结果分析得到,当k 值选取在3 个收敛点时,得到的数据较为精准,且数据识别度较高。
由于归零数据为畸变数据的一种,当确定数据畸变后,还需开展归零数据的判断,若为归零数据则根据归零数据、计量设备量基础程值及归零前计量数值进行测算与修复,并将恢复后的数据入库;若非归零数据,则判定数据为畸变,对其进行抛弃处理。算法实现的详细流程见图1 所示。
3.4 算法应用验证
通过选取在近5 年内的正常数据样本,并分区间计算样本数据的区间中心数据,形成样例数据的中心点数据样本,此次选择宁国市众益水务有限公司的样本数据进行结果验证。
提供的样例中心点数据如下:
同过K-Means 算法对样例数据寻找中心点,经过计算得到收敛的三个中心点数据:[2965,472,5888]。通过对最新的上行的累计数据与前两日的最后一条上行的数据计算得到用水差值,并将该差值与三个中心点数据进行比对,对与大于中心点之和的数据进行畸变判断。程序通过判断将超出中心点数据的上行累计数据归纳为畸变数据。图2 为对宁国市众益水务有限公司取水数据聚类及畸变数据的分析示意图。

图2 宁国市众益水务有限公司取水数据聚类及畸变数据分析图
对于分析出来的正常数据和畸变数据分别进行数据存放,并不断扩充畸变数据和正常数据样本库,程序通过持续的数据学习,实现数据评价逐步靠近真实。
4 应用效果
通过数据归零和畸变的智能处理方法的应用,在实际应用过程中对异常频率较高的取水点进行数据跟踪,选取其中部分取水点在2022 年年取水量汇总计算的数据样本,得到数据纠错后的正确性达到100%,部分难以处理的数据通过处理告警的方式,提示运维管理人员进行人工处理。详见表1
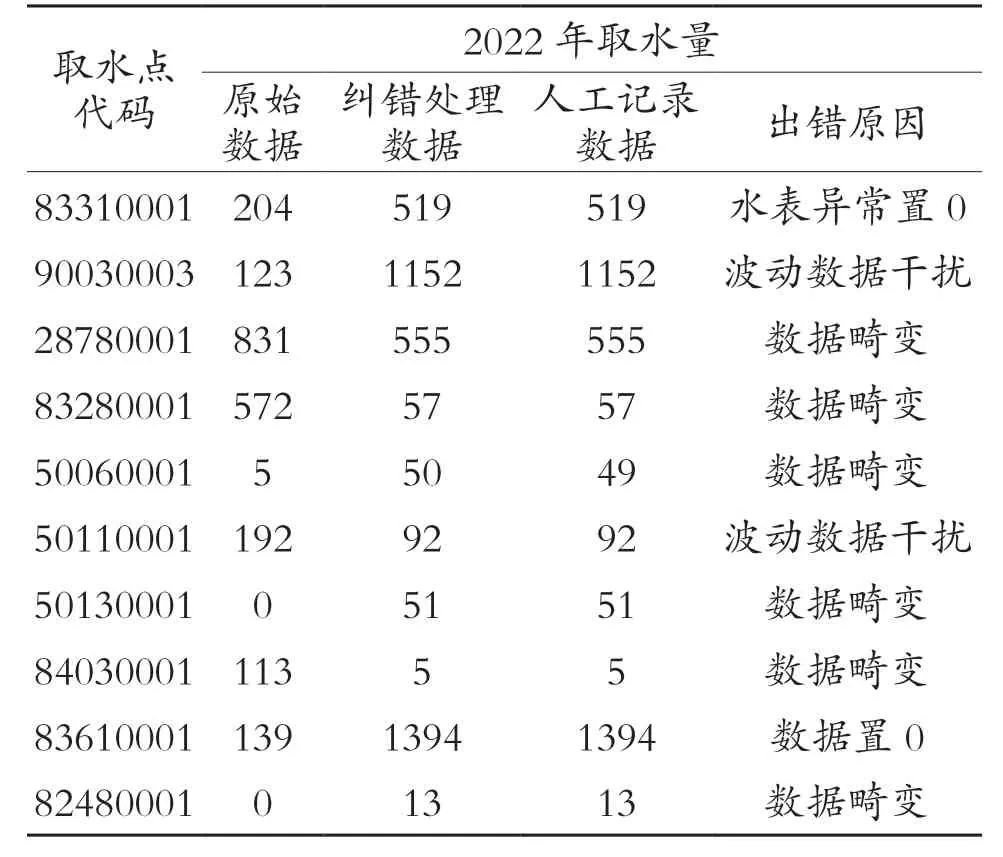
表1 水资源取水数据纠错数据列表(节选) (单位:万方)
5 小结
水资源取水计量监测管理是用水总量红线控制的基础,是最严格水资源管理制度的重要支撑平台。本文深入研究行业技术特点,与实际情况有效结合起来,解决了计量仪表数据归零及畸变处理的问题,保证了监测数据可用性、可信性,对水资源取水监控项目建设与管理的水平提升具有促进作用
