基于LDA模型的专利文本主题分析
——以国内元宇宙领域为例
2023-08-01陆振昇
陆振昇, 马 超
(1.深圳信息职业技术学院 素质赋能中心,广东 深圳 518172;2.湘潭大学 公共管理学院,湖南 湘潭 411105)
2021年是元宇宙概念火爆全球的一年,被称为“元宇宙元年”。2021年3月10日,号称为元宇宙第一股的Roblox在美国纽约上市,当日暴涨50%以上;同年10月28日,国外社交媒体巨头Facebook更名为Meta,“meta”一词代表元宇宙的“元”;随后微软也宣布进军元宇宙。国内互联网头部公司诸如阿里巴巴、腾讯、字节跳动等也纷纷开始布局元宇宙,金融界开始大量注资拥有元宇宙概念的相关企业,产业界各团体展开了元宇宙这个新赛道的竞争[1]。2022年,南京信息工程大学、安徽大学和香港理工大学分别开设了元宇宙相关专业,元宇宙自此成为当前社会、政府、产业、学界等争相关注的焦点。
元宇宙是一个大的由虚拟世界和现实世界高度融合的数字空间,包括所有虚拟世界、增强现实和互联网的总和[2]。2021年底以来,北京、上海、武汉、合肥等多地政府出台了元宇宙和虚拟现实的相关政策文件。2021年底,上海市政府年度经济会议上便指出“引导企业 研究虚拟世界与现实世界相交互的平台”;2022年,北京市政府宣布要把通州区打造成元宇宙示范应用区;深圳市也提出在前海建立元宇宙应用试验区。2021年3月发布的《十四五规划和2035年远景目标纲要》中提出“加快建设数字经济、数字社会、数字政府,以数字化转型整体驱动生产方式、生活方式和治理方式变革”。2022年10月28日,国务院五部门(工业和信息化部、教育部、文化和旅游部、国家广电总局、国家体育总局)联合发布《虚拟现实与行业应用融合发展行动计划(2022—2026年)》强调应用场景落地[3]。应用落地需要相关的专利技术作为支撑。
1 专利分析相关研究
丁鹏斐[4]提出了一种基于LDA(latent dirichlet allocation)模型的中药专利内容热点领域分析方法,并以中药材三七为例,实现了中药专利领域主题细分和热点子领域判断。张世玉等[5]提出在传统技术层面专利组合分析方法的基础上,采用文本挖掘技术,通过技术领域标签抽取、专利文本特征表示、采用文本聚类等流程来对专利文本所属技术领域进行划分。张素娟等[6]使用LDA主题模型和聚类标签的方法实现了对西洋参领域专利的主题热度分析。艾楚涵等[7]提出了LDA模型与Kmeans聚类算法结合的方法,对我国转基因玉米育种领域的专利文本进行了分析。伊惠芳等[8]用了融合时间标签的LDA主题模型和战略坐标法相结合,将石墨烯领域专利分析以二维的形式展现出来。
2 LDA主题模型理论基础
2.1 LDA主题模型
LDA主题模型由David Blei于2003年提出[9],是一种文档主题生成模型,它包含了三层结构,分别是主题、文档、词,是一个贝叶斯概率模型。LDA模型是一个无监督的机器学习方法,可以用来识别大规模文档集或语料集中的潜在主题信息[10]。同时,LDA采用了词袋模型,通过将每一篇文档视为一个词频向量,文档直接用这些向量集合来表示,并且这个词袋方法没有考虑词与词之间的顺序,降低了计算的复杂度。在LDA 模型中每一篇文档代表一些主题所构成的概率分布,在每一个主题中主题又代表了很多单词所构成的一个概率分布[11]。LDA模型的核心是Dirichlet分布,在贝叶斯概率理论中被称为共轭先验分布[12]。
LDA模型的大体思想为:运用先验分布的理念(即先设定一个猜想值去计算)通过不断迭代调整每个文档中每个词汇对应主题的概率分布和每个主题对应文档的概率分布,使最终结果符合实际的文档集中单词对应文档的分布。用数学公式表示为
P(w|d)=P(w|t)P(t|d)
(1)
式中:w为词汇;d为文档;t为主题。
2.2 主题困惑度
由于LDA模型在训练时需要事先设定好主题分类的个数,困惑度的概念是一种用于评价语言模型好坏的指标[13]。使用主题困惑度作为确定最佳主题数的指标,其在LDA模型中计算公式为
(2)
p(d)=Σlnp(w)
(3)
p(w)=[Σzp(z|d)]p(w|z)
(4)
式中:D为整个文档集;p(w)为测试集每一个词汇出现的概率;N为测试集所有词集合;z为训练过的主题;d为测试集的每篇文档。
最终计算出来的困惑度代表文档主题的不确定性,因此理论上来说困惑度越小模型性能越好,在困惑度曲线上显示为最低点或拐点处的主题数是最佳主题数[14]。
3 实验与分析
3.1 数据获取与处理
通过对CNKI中国知网的中国专利数据库中的关键词“元宇宙”进行检索,得到364条匹配结果,经过筛选,去除相似重复项和“多元宇宙算法”干扰项,选取其中234条专利的摘要构建文档集。数据获取截止时间为2022年12月19日。进行数据清洗,如“元宇宙”“专利”“申请”“发明”等词出现频率极高但对分析目标没有作用;使用jieba分词对文档集进行中文分词,并建立去停用词库。
3.2 实验结果
基于Python3.8软件的Sklearn库中LDA模型包对处理好的文档集进行主题划分,需要事先人为设置主题划分数,考虑到目前“元宇宙”专利数据集规模比较小,所以将主题数设置成3~5个。经对比发现,区分为3个主题时,主题区分度还不错,但细分技术领域和细分应用领域区分度不高;区分为4个主题时,出现极少数相似主题词分到相邻主题的情况;区分为5个主题时,出现较多相似主题词被分到不同主题的情况。主题数为3、4、5时的主题-主题词分布如表1~表3所示。

表1 主题数为3时的主题分布

表2 主题数为4时的主题分布

表3 主题数为5时的主题分布
将超参数α设置为0.1,β设置为0.01,最大迭代次数设置为50次,得出不同主题数下主题困惑度的变化曲线(图1)。
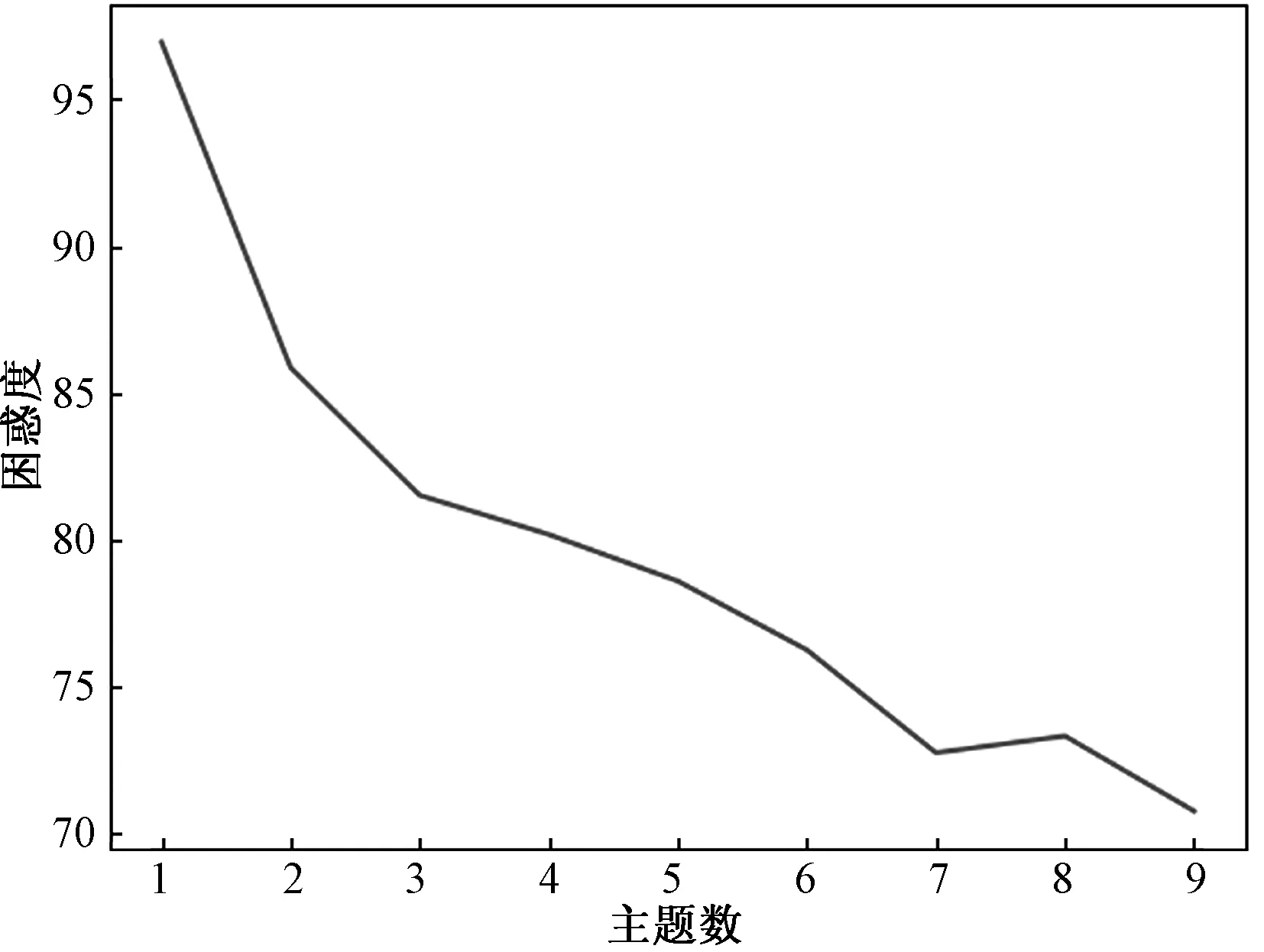
图1 不同主题数下主题困惑度变化曲线
由图1可知困惑度在主题数为7时出现拐点,最终确定最佳主题数为7。
将主题数设置为7后,得到的主题-主题词的分布情况如表4所示。可以将这7类分别对应其所在的技术领域,分别是“人工智能技术”“区块链技术”“物联网技术”“人机交互技术”“3D建模技术”“扩展现实技术”“云计算技术”。
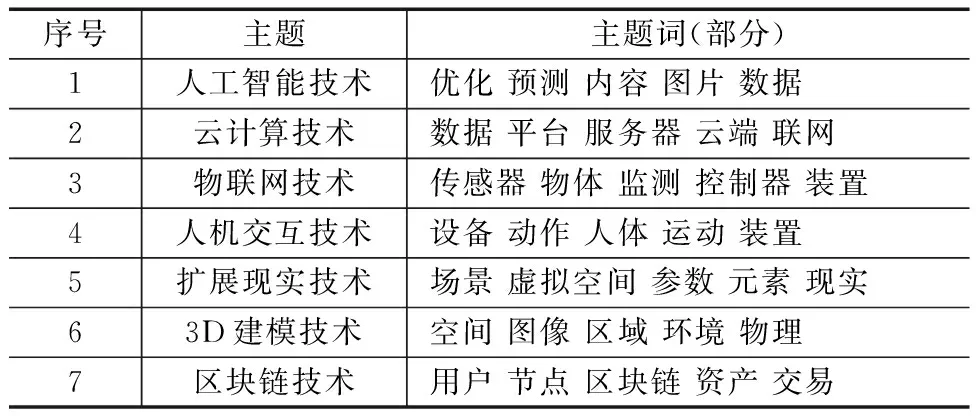
表4 主题数为7时的主题分布
3.3 实验结果分析
结合LDA主题模型训练输出最后的主题分类结果,使用Excel软件进行专利主题分类数据统计分析,得到图2所示结果。

图2 专利数量分类统计柱状图
由图2可得,目前基于区块链技术在元宇宙环境中开发的专利数量占比最大,云计算技术次之。而在2022年国务院五部门联合发布的有关促进加强虚拟现实技术与行业产业界融合应用发展计划中重点关注的虚拟现实技术方面的专利数量排名靠后。通过分析可以发现这七类关键技术在元宇宙产业应用中存在发展不平衡的现象,在《“十四五”规划和2035远景规划》中“加强数字化发展 建设数字中国”篇章里明确提到了人工智能和扩展现实这两个数字经济重点产业技术,有关部门应当在元宇宙产业的布局上着重发展这两项技术的创新开发和落地应用。截至2022年7月20日,根据全球专利数据供应商IFI CLAIMS的情报,过去5年拥有元宇宙相关专利的前10位公司有微软158件、三星122件、Magic Leap 109件、IBM71件、迪士尼40件、Facebook 38件、Adobe 31件、Verizon 30件、英特尔 27件、Snap 27件[15]。这些公司的元宇宙相关专利数量总和是国内专利数据库中元宇宙专利的两倍以上,国内的元宇宙产业尚处于起步阶段,在未来的数字化进程中,国内元宇宙产业的应用专利和技术专利具有相当大的发展空间。
4 结语
LDA主题模型可以应用到元宇宙专利文本数据的主题分类中,实现对元宇宙专利主题领域、技术领域的现状的分析和判断,揭示了热门技术领域和热门产业发展的紧密关联性,为后续元宇宙产业的研究提供了参考意见。经过实证环节总结出以下结论:通过实验分析基于LDA主题模型得出专利-主题的具体分布,将中国元宇宙领域相关专利细分成七大技术类别,填补了当前国内元宇宙领域内专利文本分析的空白。
1)通过对当前中国专利数据库中元宇宙相关专利的分析研究,发现以下局限:获取的专利文本数据规模小,无法更深层次地、更广维度地对国内元宇宙专利数据进行挖掘。
2)国内目前在元宇宙产业还处于初期发展阶段,产业界和高校已经陆续着手扩大元宇宙方向的布局,相信在不久的将来,随着生成式AI(artificial intelligence)技术的蓬勃发展,在此项技术的加持下,中国元宇宙相关专利会在虚拟现实技术领域出现井喷式的增长。
