基于深度强化学习的海上编队防空任务分配*
2023-07-31彭鹏菲
卢 锐,彭鹏菲
(海军工程大学电子工程学院,武汉 430030)
0 引言
现代空袭目标技战术性能的快速提高给海上编队协同反导带来了巨大挑战,防空作战形势日趋严峻。编队间协同目标分配的快速确定和优化,是提高对空作战能力,保护编队生命力的关键。程明提出一种目标分配方法,基于受限时段资源对舰艇防空武器进行了合理的调度,得到多目标拦截武器分配方案[1]。周菁提出的目标分配算法为每个个体安排最佳的攻击目标,使集群的协同攻击效能最大[2]。白建保等提出了一种基于命中概率模型的反舰导弹目标分配方法,完善了相关数学模型[3]。曹璐提出了基于决策图贝叶斯优化算法的多无人艇协同目标分配方法,结合约束条件构建了多无人艇协同目标分配数学模型[4]。孙鹏等研究了基于突发事件的任务分配,将目标函数设为最小完成时间,通过贪婪算法进行可执行任务的动态分配,但此研究忽略了任务截止时间的约束[5]。
上述传统方法虽然快速有效但是理论性不强,且需要大量的专业知识和试错,无法被广泛使用,并且这些启发式算法只是针对某一特定环境求取最优解,面对环境变化时,往往需要重新求解,实时性差。而强化学习算法拥有自决策的特点,可以根据战场状态进行快速响应和调整,但其在解决大规模问题和维度较高时性能较差,深度强化学习的出现可以有效解决此难题。MNIH 等提出了DQN网络[6],其同时具有强化学习和深度学习的特点,其有效性在多个领域得到了证实,并不断被更新优化。朱建文等使用Q-Learning 算法对导弹的选取和分配方式进行智能决策[7]。代琪等提出了一种基于强化学习与深度神经网络的算法,在动态多无人机任务分配问题的求解中具有良好的性能[8]。黄亭飞等采用一种基于深度Q 网络(DQN)的模型对无人机动态任务分配问题进行了求解[9]。丁振林等提出一种基于强化学习与深度神经网络的动态目标分配算法,火力拦截成功率得到明显的提升[10]。龙腾等提出了一种基于神经网络的防空武器目标智能分配方法,能得到相对最优的分配方案[11]。相关研究虽然在一定程度上弥补了传统算法的不足,但缺乏对实际战场环境下的编队协同防空任务分配数学模型的适应性改进,综合效益值仍有上升空间。
本文在现有研究的基础上,建立和完善相关数学优化模型,提出了一种基于深度强化学习的海上编队协同防空任务分配方法,利用两种结构简单的深度强化学习算法对模型求解,进行任务分配的决策,可在时间成本较低的情况下实现较高的任务分配综合效益值。
1 问题描述和系统模型
在任务分配问题中,目标函数的合理选择,是较为重要的一个环节,是算法求解的对象,并且目标函数侧重的方面会根据研究者所关注的问题不同而有所区别,但一般来说都表述为一个极值问题[12]。如图1 所示,本文将编队内各火力平台看作一个整体,假设共有k 艘舰船,共m 个防空火力单元,空中来袭目标共有n 批,各个目标对编队的威胁度为ωj(j=1,2,…,n)。
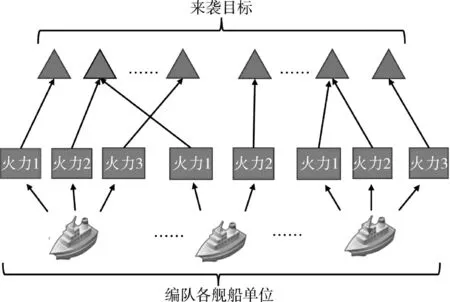
图1 任务分配示意图Fig.1 Schematic diagram of the task assignment
假设Pij为第i 个防空火力单元对第j 个空中目标的射击有利度(杀伤概率),每个空中目标被分配给火力单元的最大值为L。当空中目标被分配的所有火力射击有利度之和大于1 时即被移除出分配对象范畴。第Xi个防空火力单元打击第j 个空中目标表示为Xij,且有:
则基于毁伤效能指标的综合效益值目标函数可以表示为:
约束条件如下:
2 深度强化学习基本原理
强化学习是人工智能领域重要的分支,是无监督学习的代表算法,目前已在众多大规模决策问题中得到应用。强化学习主要包含智能体、环境、行动、奖励4 个要素,通过智能体采取行动与环境进行交互,获得相应奖励并不断调整策略的方式进行学习。深度强化学习则是深度神经网络与强化学习结合的产物,利用神经网络来解决传统强化学习状态过多无法存储的问题。本章主要介绍深度强化学习算法相关理论知识。
2.1 马尔可夫决策过程
当系统的下一个状态与之前状态无关,只由当前状态决定时,则称该系统具有马尔可夫性,可以根据当前状态和采取的动作来对未来状态和获取的奖励进行预测。马尔可夫决策过程则是序贯决策的数学模型,用于在系统状态具有马尔可夫性质的环境中模拟智能体可实现的随机性策略与回报,可用元组(S,A,P,r,γ)来表示。其中,S 表示有限数量的状态集合,A 为动作集合,P 为状态转移概率,r 为奖励函数,γ 为折扣因子。完整过程如图2 所示,在时刻t,智能体从环境中观测状态st∊S,根据策略π(a|s)选择动作at∊A,执行该动作并以概率转移到下一个状态,同时接收环境反馈的奖励r。

图2 马尔可夫决策过程框图Fig.2 The Markov decision-making process block diagram
2.2 DQN
强化学习中有一类基于值函数的算法,Qlearning 则是其中具有代表性的一种。它通过表格式存储各状态动作对Q 值的方式来记录探索过程中每个策略对应的价值,但当应用场景状态空间和动作空间维度较大时,表格式存储变得难以实现。受神经网络强大的拟合非线性函数能力启发,相关研究人员提出用神经网络替代表格式存储Q 值的方法,通过训练来对Q 价值函数进行拟合,即深度Q网络(DQN)。
DQN 使用参数化的神经网络来对Q 函数进行拟合逼近,找到最优的策略。训练的损失函数为:
3 基于深度强化学习的模型求解
3.1 问题转换
利用深度强化学习方法研究协同防空任务分配问题,需将协同防空任务分配问题转化为马尔可夫决策过程,便于问题的表示和解决,然后定义状态空间、动作空间与奖惩函数如下。
3.1.1 状态空间
本文将来袭目标和舰船的特征视为状态,并用3 个矩阵表示。第1 个为杀伤概率矩阵,第2 个为来袭各目标相对威胁度,第3 个为当前步长分配结果矩阵。例如3 艘舰船对3 个来袭目标进行火力打击,则状态矩阵表示如下:
3.1.2 动作空间
在海上编队协同防空场景下,对于编队火力单元来说,动作空间为在当前状态下各舰船可采取动作的集合,表示为C={a1,a2,…,ap}。假设可选动作:
1)攻击威胁度最大的来袭目标;
2)攻击火力单元杀伤概率最大的来袭目标;
3)攻击上级指定的目标;
4)攻击重点目标;
5)攻击射击有利的目标;
6)攻击先到达的目标。
3.1.3 奖励函数
奖励函数的选取深度强化学习的最终目的就是使累计奖励最大化,其效果与奖励函数的选取息息相关。累计奖励即每个动作产生的奖励总和,代表所有短期奖励产生的短期影响累积。
根据协同防空任务分配问题的数学描述,算法的最终目标是最大化综合效益值Z1:
每个动作的奖励设置如下:
3.2 算法流程
本文使用在Evolving Reinforcement Learning Algorithms[13]一文中提到的两个算法,他们在众多环境测试中均优于传统DQN,网络结构简单,效率更高。两种表现较好的算法DQNReg 和DQNClipped具体如下:
设
3.2.1 DQNClipped
DQNClipped 是DQN 在3 种训练环境(Lunar Lander、Mini Grid-Dynamic-Obstacles-5,5Mini Grid Lava GapS5)中自举训练出来的。它在训练和未见环境中的表现都优于DQN 和Double DQN,Dueling DQN。其损失函数表明,如果Q 值过大(当Q(st,at)>δ2+ Yt),损失将作用于最小化Q(st,at)而不是传统的δ2。或者可认为当δ 足够小时,损失只是为了最小化Q(st,at)。具体损失函数如下:
3.2.2 DQNReg
DQNReg 是DQN 在3 种训练环境(Key Corridor S3R1,Dynamic-Obstacles-6x6,DoorKey-5x5)中通过自举训练出来的。与DQNClipped 相比,DQNReg 直接用一个始终有效的加权项来规范Q 值,但两个损失函数都为了将Q 值正则化为较低的值而修改了原始的DQN 损失函数。DQNReg 虽然相当简单,但它在众多公开训练和测试环境中,包括从经典控制和Minigrid 中,都与基线相匹配或超过了基线。在一些测试环境(Simple Crossing S9N1、Door Key-6x6和Unlock)中表现特别好,并在其他方法无法获得任何奖励时解决了这些任务。因此,它更稳定,种子之间的差异更小,在测试环境(Lava GapS5、Empty-6x6、Empty-Random-5x5)上的采样效率更高。损失函数如下:
神经网络的训练是一个最优化问题,最优化一个损失函数loss function,也就是标签和网络输出的偏差,目标是让损失函数最小化。为此,需要有样本,巨量的有标签数据,而Q-learning 利用Reward 和Q计算出来的目标Q 值即可作为标签,DQN 网络结构如图3 所示。第1 层为状态空间输入层,之后连接3个卷积层,在进行卷积操作后,将提取的特征通过全连接层输出Q 值,卷积层激活函数选用Relu。
然后通过反向传播使用梯度下降的方法来更新神经网络的参数。在DQN 中强化学习Q-Learning算法和深度学习的SGD 训练是同步进行的,通过Q-Learning 获取无限量的训练样本,然后对神经网络进行训练,流程如图4 所示。
综上,基于深度强化学习的海上编队协同防空任务分配算法核心步骤如下:
Step 1 初始化经验回放D,价值函数Q,折扣因子,Q 网络参数为θ;
Step 2 输入舰船的各特征值,来袭目标各特征值
Step 3 for i=1,M do;for t=1,T do
Step 4 初始化状态s;
Step 5 使用ε-贪婪算法进行动作选择,即以ε的概率随机选取动作空间内的可执行动作,以1-ε的概率选取当前时间步内Q 值最大的一个动作at;
Step 6 根据动作at 计算相应的奖励rt,并转入下一个状态st+1;
Step 7 将(st,at,rt,st+1)存储于D 中;
Step 8 随机从D 中选取适量的小批量样本(st',at',rt',st'+1);
Step 9 使用随机梯度下降法训练网络结构;
Step 10 更新参数θ、θ-、Q(st,a;θ)、Qtarget(st,a;θ-);
Step 11 结束循环,保存Q 估计值网络结构,算法结束。
4 实例验证
为了验证上述两种新的深度强化学习算法,在海上编队协同防空任务分配场景中同样具有优良的性能,设置了一个仿真环境,假设海上编队共有4艘舰船,共20 个防空火力单元,空中来袭目标共有12 批(个),各个目标对编队的威胁度和部分武器对目标杀伤概率设置如表1 和表2 所示。

表1 来袭目标威胁度(目标数12)Table 1 The threat level of raid-goal(the number of goals is 12)

表2 武器杀伤概率(目标数12)Table 2 The weapon kill probabilit(the number of goals is 12)
深度强化学习算法的神经网络部分实现是基于TensorFlow 深度学习框架的,实验使用CPU 为intel(R)Core(TM)i7-8550U,内存为16GiB,GPU 为NVIDIA GeForce RTX 2080 的计算机。将算法训练1 000 个周期,其余相关参数设置如表3 所示。
由图5 累计奖励值可以看出,训练刚开始时,算法处于探索阶段,之后随着训练步数不断增长,累计奖励值也随之快速增加。在训练中期,算法定期更新参数会导致增长速度趋稳但略有变化。训练后期,累计奖励值逐渐趋定,并略微有上升,这说明此时已学习到了任务分配的策略。

图5 累计奖励值Fig.5 The Cumulative reward value
使用的两个新的算法DQNReg 和DQNClipped,在仿真环境中具有良好的性能。算法的Q-eval,cost,total training time 随训练时间步的变化如图6~图8 所示。
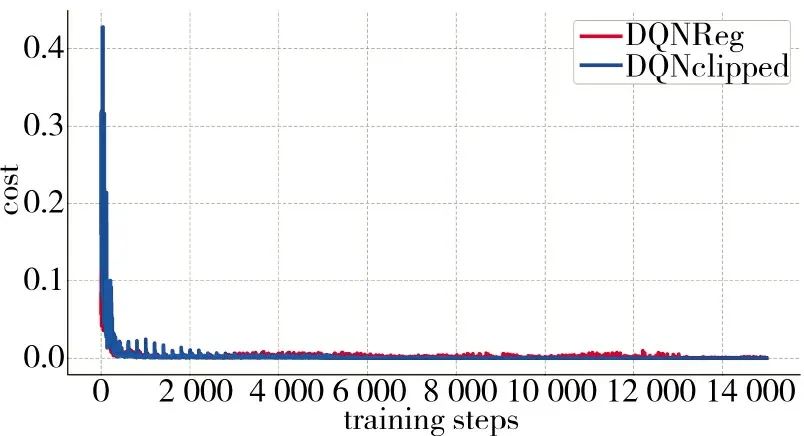
图6 损失值变化Fig.6 The change of loss value
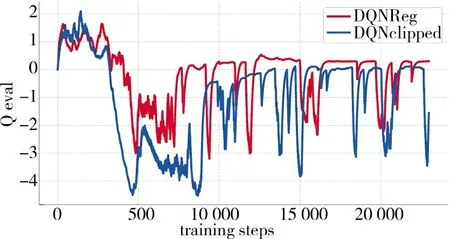
图7 Q-eval 变化Fig.7 The change of Q-eval
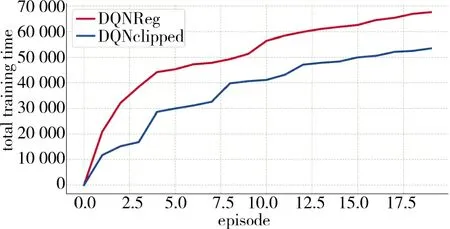
图8 总体训练时间Fig.8 The overall training time
图6~图8 展现了训练过程中两种算法的各种性能变化,说明了模型在训练的过程中,目标函数被不断地优化,求解模型的有效性得到证实。
本文利用现有的DQN 算法,遗传算法(GA),贪婪算法以及DQNReg 和DQNClipped 算法进行防空任务分配训练。实验设为两组,分别是来袭目标为12 批,20 批情况下综合效益值随训练时间步的对比实验。
图9 表示了来袭目标为12 批次情况下,各算法的综合效益值随时间步的变化情况。可以看出,训练得到的两种算法能实现较大综合效益值。在训练初期,两种训练得到的算法实现的综合效益值基本相同。在中后期,两种算法交叉获取最高效益值,这是因为两种算法有不同的损失函数和分配策略,但均高于其他算法。基于遗传算法的防空武器任务分配耗时平均约为5.6 s,贪婪随机选择算法平均为10.3 s,而基于深度强化学习的防空武器任务分配耗时均小于1 s,具体分配方案如表4 所示。从结果可以看出,在当前仿真环境下,对于来袭目标威胁度较大的目标,分配了多个对该目标杀伤概率大的武器进行打击,以提高防空综合效益值,说明了任务分配方法的有效性。

表4 分配结果(目标数12)Table 4 The assignment results(when the number of goals is 12)
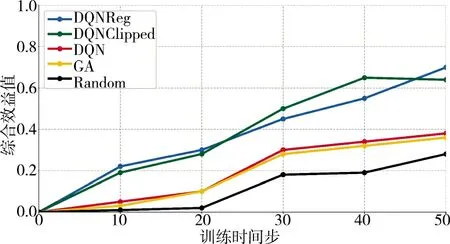
图9 来袭目标为12 批次时Fig.9 When the target is 12
图10 表示了来袭目标为20 批次情况下,各算法的综合效益值随训练时间步的变化情况,各个目标对编队的威胁度和部分杀伤概率设置如表5、表6 所示。当来袭目标增多时,训练所得的算法实现的综合效益值还是明显高于DQN,GA 和贪婪算法。与之前交叉上升不同的是,在训练后期DQNReg 明显超过了DQNClipped,这是因为当来袭目标增多时,各种时间约束则更多,说明训练所得的DQNReg 算法更适应这种情况。同时也说明了本文训练的算法在任务量增大时依然能实现最大综合效益值。基于遗传算法的防空任务分配耗时平均约为6.7 s,贪婪随机选择算法平均为13.5 s,而基于深度强化学习的防空任务分配耗时均小于1 s,具体分配方案如表7 所示。从具体分配结果可以看出,在来袭目标数量更多的情况下,对于威胁度高的来袭目标,分配了杀伤概率高的火力单元对其进行攻击,证实了任务分配方法的合理性。
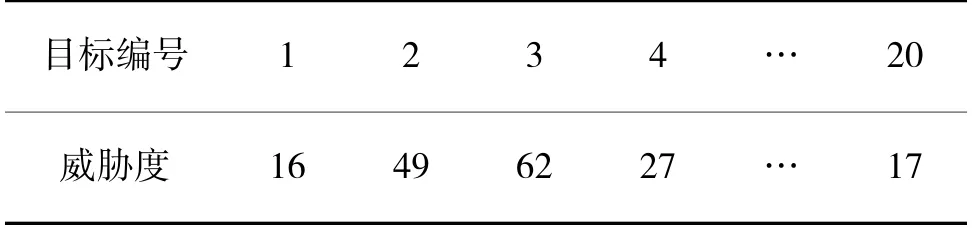
表5 来袭目标威胁度(目标数20)Table 5 The threat level of raid-goa(when the number of goals is 20)

表6 武器杀伤概率(目标数20)Table 6 The weapon kill probability(when the number of goals is 20)
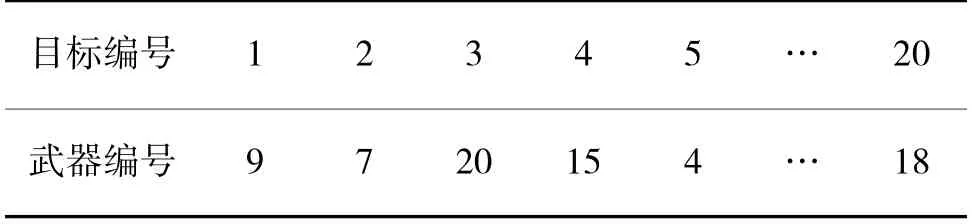
表7 分配结果(目标数20)Fig.7 The assignment result(when the number of goals is 20)
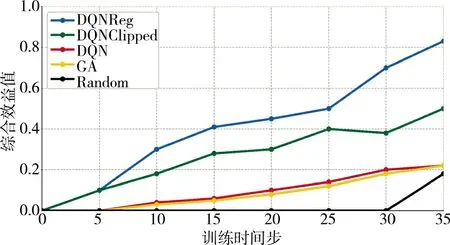
图10 来袭目标为20 时Fig.10 When the number of raid-goals is 20
综上,由各情况下实验结果可以看出,使用的两个新算法在不同情况下的任务分配效果都要明显好于之前的任务分配算法,能实现最大综合效益值。其中,对于不同的防空任务,两种算法在不同时期分别具有最好的表现,这说明在训练前期和中期,算法拥有不同的分配策略,但总体而言均高于之前已提出的算法,证实了算法的有效性。
5 结论
本文研究了海上编队协同防空任务分配问题,提出了一种基于深度强化学习的分配方法。创新性地将问题建模成马尔可夫决策过程,并使用两种最新的深度强化学习算法对问题优化求解,进行任务分配的决策,实现综合效益值的最大化。仿真结果表明,相较传统任务分配方法,本文方法在实现防空综合效益最大化方面有一定优势,且计算效率更高,更能满足实时性决策的需要,对相关领域的研究具有一定意义。
