基于改进YOLOv7 声光融合水下目标检测方法
2023-07-22葛慧林戴跃伟朱志宇
葛慧林,戴跃伟,朱志宇,王 彪
(江苏科技大学 海洋学院,江苏 镇江,212003)
0 引 言
基于光学传感器获得的图像具有较高的图像细节及颜色信息,适用于环境监测或地质勘探等应用场景。光学相机提供的高分辨率数据,在诸如珊瑚礁监测[1]、船体检查[2]、运动估计[3]和考古调查[4]等应用中具有重要意义。
然而,光学相机的成像范围有限,水下光的衰减、水的浊度或天气改变等因素都将进一步影响到光学传感器的范围和性能。照明系统可以在一定程度上缓解这些问题,但不均匀的照明也是光学图像的干扰因素之一,并且由于成本及功率的限制,高质量的照明系统并不适用于多数应用场景。此外,在水下环境中,潜艇会扬起淤泥,干扰光学传感器的性能。声呐可以适应昏暗的环境,拥有更大的感知范围,但是与光学相机相比,声呐的分辨率较低,而且不包含颜色。
结合光学和声呐数据,可实现各自优点的整合,提高水下目标检测的准确度[5]。目前相关研究多数集中于如何创建高效的整合模型。Moroni 等[6]利用光学数据建立一个三维纹理的场景,利用声呐数据的阴影形状产生一个三维水深轮廓,通过整合每一个表征并使用文献[7]中启发的方法,投影到多维状态空间图中的参考层。然而,算法没有对声光图像数据进行直接的融合。Negahdaripour 等[8]设计的模型在特征层面上明确地融合光学和声呐数据,不仅改进了运动估计,还克服了单眼视觉固有的模糊性。Babaee 等[9]提出一种利用前视声呐DIDSON 和光学相机图像从遮挡表面法线建立三维物体模型的方法,与单纯的光学传感器技术相比,可以在更高的浊度水平下生成更好的物体三维模型。
在目标检测任务中,执行光学图像和声呐图像的融合需要对影像进行校准。在使用深度学习的多模态输入中,根据声光图像信息被结合的时刻,一共分为3 种解决方案:早期融合、后期融合和中间融合。早期融合方法主要是在神经网络处理之前,在原始数据层面上结合光学和声呐图像。后期融合是指对来自光学和声呐图像进行独立处理后,融合处理结果。中期融合模型接受多种输入,在网络内部融合数据。
为了克服样本的不足,可利用零散的方法来增加样本数量[10-11]。对预训练的CNN 进行微调是声呐图像检测中一个有用的方法。Lee 等[12]采用StyleBankNet对人体的光学图像进行风格转移模拟,进一步提高了声呐物体检测的精度,但该样本由计算机辅助设计软件生成,需要大量的模拟工作来生成样本。Li 等[13]充分利用风格转移白化、着色变换方法和遥感图像模拟声呐图像进行目标风格转移。Yu 等[14]通过使用Transformer-YOLOv5,提高的准确率。Huang 等[15]结合三维模型、放大数据、设备噪声和图像机制,通过DCNN 和微调风格转换方法提取目标特征并模拟目标损伤和姿态。Song 等[16]提出了一种基于斑点噪声分析的高效声呐分割方法,该方法便于进行像素级分类,并采用具有多个侧向输出的单流深度神经网络来优化边缘分割。
为提升水下目标检测与识别的准确度,本文研究了实时神经网络检测器架构YOLOv7,并使其适用于多模态输入,实现声光数据融合。通过设计全新的融合模型YOLOv7-Fusion 以及引入CE-Fusion 模块,进一步提升融合效率和准确性。利用快速风格和图像处理算法转化的方法,生成人工数据集,丰富样本集数量。本文提出的算法可充分利用声、光图像的优势,显著提升水下目标检测识别的效率、准确性以及稳定性。
1 YOLOv7-Fusion 多模态网络设计
本文网络主干选择为YOLOv7,YOLOv7 是一种单阶段的物体检测算法,其架构是在YOLOv4,Scaled YOLOv4 和YOLO-R 模型架构的基础上开发。YOLOv7采用了扩展的高效层聚合网络(E-ELAN)架构,通过实现输入的不同变化,如位置变换、扩展和合并,使网络的学习能力得到不断提高,进而网络在梯度路线改变时也能保持较高学习性能。YOLOv7 架构包括1 个骨干层、1 个瓶颈层和1 个头部。模型的输出位于头部,并包括主导头和辅助头,主导头负责预测结果,而辅助头支持中间层的训练。基于YOLOv7,将光学图像和声呐图像融合为6 通道的张量,其中3 个通道为RGB 图像数据,另3 个通道为声呐数据。使用2 个不同的特征提取网络进行独立处理,特征图在不同层级使用支系间连接进行组合,实现水下目标检测准确率的提升。所设计的YOLOv7-Fusion 如图1 所示,分别在骨干层的倒数第1、第2、第3 层提取特征图输入进CE-Fusion 模块,输出融合特征图,分别连接到瓶颈层的对应部分。

图1 YOLOv7 多模态网络结构Fig. 1 YOLOv7 multi-mode network architecture
为了在中间融合时,有效地结合来自不同模态的影像特征,提出一个新的CE-Fusion 模块,具体结构如图2 所示。模块包含自我注意力和多模态融合机,定义ti和gi代表第i层的光学特征图和声呐特征图。
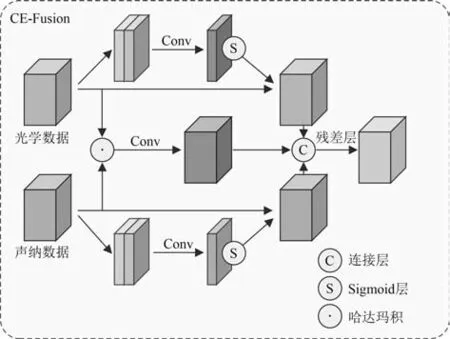
图2 CE-Fusion 模块Fig. 2 CE-Fusion module
由于低层CNN 特征可能包含噪声,为促进全局信息的表达、增强局部细节并抑制不相关区域,参照CBAM[24] 实现通道注意力和空间注意力方法。此外,利用哈达玛积对来自2 个分支特征之间的细粒度互动进行建模。最后,结合交叉特征和刺激特征,并通过一个残差块,产生特征fi,该特征可有效捕捉当前空间分辨率下的全局和局部环境。使用YOLOv7在COCO 的预训练权重初始化YOLOv7-Fusion,由于原版模型没有CE-Fusion 模块,在初始化后进行预热训练,在预热训练阶段,冻结转移的权重,专门训练CE-Fusion。
2 基于风格转移的人工资料集
目前,许多研究注重转移学习和数据增强,在声呐目标检测中,基于风格转移的模型性能有了明显的提高,并成为声呐目标检测的一个技术趋势。一般来说,风格转移主要包括2 个步骤:风格转移网络在风格图像和内容图像上训练,生成一个风格模型;将图像输入生成的模型中,并输出风格化图像。然而,直接使用风格转移方法,会失去声呐图像中目标的关键特征。为了增强特征,提出一系列增加特征的图像工学操作,通过使用3 个图像操作来增强目标的阴影和特征,具体表示如下:
式中:AutoLevel 为自动色阶;I为颜色反转;g为伽马值调整;γ为伽马函数的阈值;y为最终结果。该方法也可以应用于其他类型的声学图像。
在快速风格转移中,定义2 个Loss 函数,Lstyle和Lcontent。LStyle为f在风格方面与p更相似。Lcontent为f在内容方面与a更相似,则
式中:p为声呐图像的背景;a为光学图像;f为具有声学图像风格的转移图像。
在实际环境中, 由于水下环境多变,如低光照、失焦、抖动等,获取到的光学图像无法达到稳定的质量,而声呐可以获得相对稳定的数据。为了模拟应用中的不可控因素,对随机的光学图像进行高斯模糊,并改变其伽马值。最终通过融合光学及声学图像数据,实现检测及识别效果的提升。
生成人工资料集的具体操作如图3 所示,对于每一种光学图像,先进行一系列增强特征的图像工学操作,之后送进已经训练的风格转移模型,从而获得对应的声呐图像。光学图像本身则进行随机高斯模糊和伽马值调整,模拟昏暗水下环境,并与声呐图像成对输出。在训练集和测试集都进行人工资料集生成,最终获得了大量的声光融合资料集。
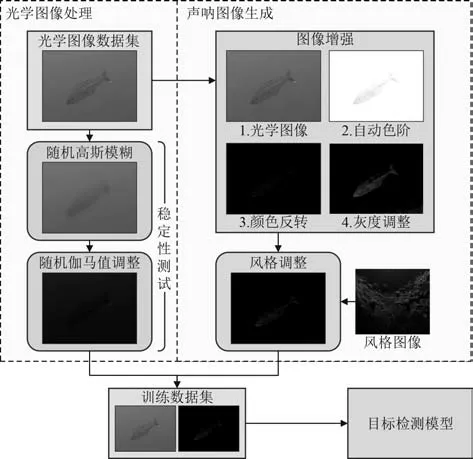
图3 基于快速风格转移的人工数据集生成Fig. 3 Manual data set generation based on fast style transfer
3 实验分析
3.1 性能指标
用来衡量模型准确性的指标是平均精度(AP)。计算平均精度需要了解其他3 个指标:交并比(IoU)、精确率(Precision)和召回率(Recall)。IoU 是预测区域和真实区域的交集区域和并集区域的比例,精确率是指正确识别预测的比例,召回率是指正确检测到的真实结果的比例。当一个预测对真实结果的“联合之上的交集”值,即IoU,高于一个特定的阈值时,则认为该预测正确。
式中:真阳性(TP)为指检测的方框中IoU 高于阈值的数量;假阳性(FP)为检测方框中IoU 低于阈值的数量;假阴性(FN)为未检测到的真实结果的数量。
定义mAP 是每个召回值的精度的平均值,换言之,mAP 代表精度-召回曲线下的面积。为了建立作为召回率函数的精度曲线,必须对整个测试集进行预测。建立一个按精度降序排序的每个方框的置信度表格,为每个预测的边界盒分配TP 和FP 的值。根据式(8)可知,通过创建一个累积的TP 和FP,可计算每个值的精度方程。根据式(9)可知,对于每个精度值,使用累积的TP 和FN 计算召回率。以TP 与FN 的和作为测试数据集中真实结果的数量。基于已设置的每个预测界线盒的精度和召回值的累积顺序,建立精度-召回曲线。最后,通过计算曲线下的面积得到mAP。mAP 指标决定了有多少预测结果是正确以及检测到的物体和地面真实位置之间的重叠程度如何,因此,可利用mAP 对于比不同检测算法的性能。此外,mAP 的值与预设的阈值密切相关,预设的阈值决定了预测方框和真实结果的重叠。本文采用了mAP0.5和mAP0.5-0.95两个指标。mAP0.5表示将IoU 的阈值设为0.5 时,所有类别的mAP,而mAP0.5-0.95则表示在0.5 到0.95,步长0.05 的所有阈值的平均mAP。
实验中的数据集为NorFisk,并以9:1 的比率划分训练集和测试集。在训练基于多模态的中期融合网络时,输入图像大小设置为640×640,初始学习率为0.01,权重衰减率为0.000 5。每次网络训练样本数为16,并使用动量为0.937 的亚当优化器进行梯度更新。模型在单张RTX 3 090 上训练。
3.2 实验结果分析
为证明本文理论分析的正确性及优越性,分别使用多种融合方法对目标数据集进行训练和测试,使用的方法如下:
1)早期融合YOLOv7-Early,如图4(a)所示。在YOLOv7 处理之前,在原始数据层面上结合光学和声呐图像,使用加权加法操作进行融合。在YOLO 的骨干中创建的潜在特征包含了来自第1 个计算阶段的2 个模态的信息。
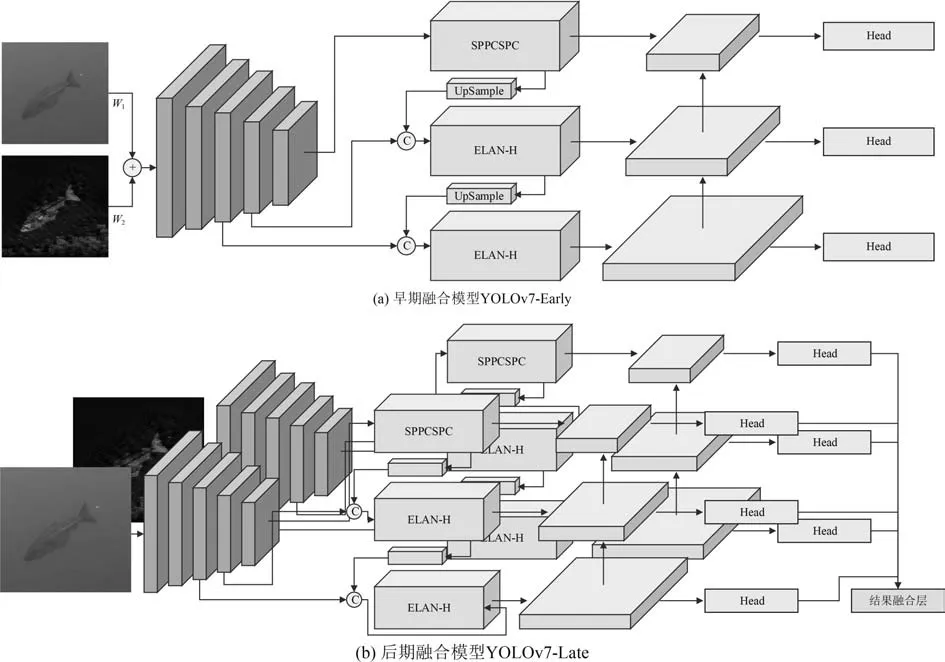
图4 早期融合模型和后期融合模型结构Fig. 4 Early fusion model and late fusion model structure
2)后期融合YOLOv7-Late,如图4(b)所示,对来自光学和声呐图像进行独立处理,同时融合处理结果。深度神经网络由2 个完整独立的分支组成,从这2 个分支得到的检测结果由一个预测合并模块处理。检测方框根据从2 个处理分支获得的结果的平均提供一个单一的检测输出,目标种类预测采用声学图像的结果,从而融合2 个网络的结果。
3)中间融合YOLOv7-Fusion,是本文主要提出的方法。开始时,使用2 个不同的特征提取网络进行独立处理,特征图在不同层级使用支系间连接进行组合,最终可以实现更高的水下目标检测准确率。
4)原始模型YOLOv7,不进行融合,只使用单独一个模态进行训练和检测。标记使用光学图像训练的YOLOv7 为YOLOv7-Opti,而使用人工声呐图像训练的为YOLOv7 -Acou。
通过比较不同网络mAP 值,实现不同网络性能的对比。根据表1 可知,YOLOv7-Fusion 检测器达到了最高的指标分数,因为模型结合了从不同处理水平的2 个来源提取的信息。YOLO4-Late 检测器的检测结果稍差,模块平均了光学和声呐图像数据的并行处理模块的检测结果。在目标分类任务上,YOLOv7-Fusion 的召回率比YOLOv7-Acou 略低,产生此种现象的原因可能是由于选择的模型拥有简单的背景和良好的光照条件,使得普通的单模态模型也能达到非常高的准确率,并且YOLOv7 本身也是强大的目标检测模型。

表1 不同网络对数据集的检测准确率Tab. 1 Detection accuracy of different networks of the data set
为了模拟应用中的不可控因素,通过改变数据集,实施了稳定性测试。对光学图像的处理有改变伽马值和进行高斯模糊,将改变后的数据集输入融合网络进行测试,实验的结果如表2 所示,通过对比mAP指标可知,YOLOv7-Fusion 各项性能均最佳,它在处理后的图像数据集上的表现明显优于其他方法,尤其与YOLOv7-Early 和YOLOv7-Opti 等单源方法相比,这种性能差异更为明显,根据表2 所呈现的数据可知,YOLOv7-Fusion 比YOLOv7-Early 和YOLOv7-Opti 在mAP0.5的改进超过0.066。对于融合时机来说,YOLOv7-Fusion 比YOLOv7-Late 的表现好0.328,比YOLOv7-Early 好0.009,这证明了中间数据融合能够最有效地吸收各个模态地信息。值得注意的是,YOLOv7-Late探测器在模糊图像分类准确度低,因为模块参考光学图像分类。

表2 在稳定性测试中不同网络的检测准确率Tab. 2 Detection accuracy of different networks in stability testing
当使用数据采集装置时,系统只有有限的时间预算来进行有效的检测和决定。表3 列出了所分析的融合模型的处理Fps 值,即每秒可以处理的张数,推理时间的计算均是假设每个图像都是独立处理。Fps 越大,网络检测性能越好。由上述实验可知,不同的光照条件下,YOLOv7-Fusion 有关目标检测准确性均最佳,且效率比拥有2 个独立模型的YOLOv7-Late 效率高,与YOLOv7 以及YOLOv7 基本持平。此外,由于YOLOv7-Fusion 在RTX3090 GPU 上实现了43.4 fps 的速度,因此本文所提出的YOLOv7-Fusion 在保持高检测准确率以及稳定性的同时,还满足了对瞬时处理的要求。

表3 不同网络对数据集的检测性能Tab. 3 Detection performance of different networks of data sets
