一种基于计算资源度的星间路由协议
2023-07-21苏安刘乃金陈清霞向雪霜刘佳
苏安,刘乃金,*,陈清霞,向雪霜,刘佳
1.钱学森空间技术实验室,北京 100094 2.航天东方红卫星有限公司,北京 100094
1 引言
近年来,随着低轨卫星与5G(第五代移动通信,the fifth generation of mobile communications system)的火热发展,卫星互联网(IoSat,Internet of Satellite)逐渐成为空间网络的新范式,如图1所示[1,2]。卫星互联网中的一个重要因素是路由协议,由于卫星动态、链路中断和按需组网这类特殊行为的存在,传统的地面网络模型不能完全适用于卫星互联网[3-5]。
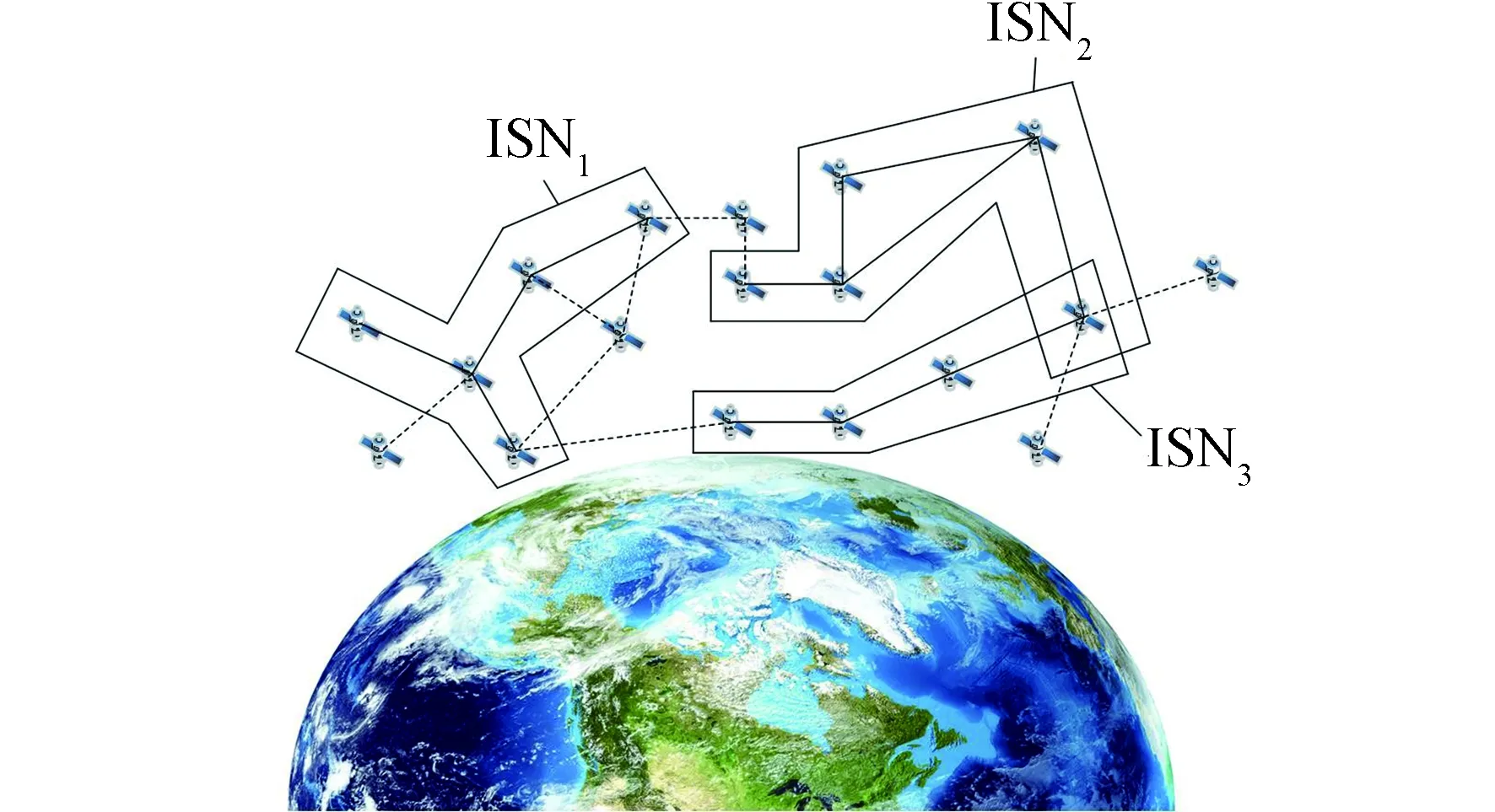
图1 卫星互联网示意
随着用户需求与任务复杂度的不断增加,单个卫星节点的能力和资源逐渐达到饱和态,已不能满足日益增长的任务要求。例如,遥感产品生产节点可提供的能力对任务调度有着重大影响,其中,服务能力的指标通常有:CPU计算能力、内存剩余容量、当前节点任务状态等。根据卫星中心报告,中国14颗中高分辨率光学卫星月产数据量将近PByte级别,即单星已达日产GByte级别,但中国目前要实现单星在轨实时图像处理难度较大[6]。目前,现有大多数卫星均采用弯管方式进行数据传输,大量遥感数据还需要被卸载到处理能力强的地面站中,由算力资源强的地面中心提供集中式计算服务。上述方法通信开销大、计算时延高,难以应对时延敏感类型业务。因此,面向未来海量数据的快速处理需求,星间协同计算不仅能显著提升计算时效性,而且能大大降低地面站计算模式带来的通信成本。
随着“东数西算”等国家战略部署的推进,计算和网络的融合成为趋势。在算力网络的初步探索中,形成了由算力服务层、算力资源层、算力路由层、网络资源层和算网编排管理层的新型算力感知架构。而算力路由是算力网络中的关键技术,依据对网络、计算、存储等多种资源和服务的感知,将算力信息加入到“计算+网络”这类范式的新型路由表中。最终实现感知业务请求,以及网络和计算的联合路由计算,按需实现业务调度策略[7-9]。在卫星互联网的发展中,星载计算资源作为提供服务的主要载体,具备数量大、分布广、异构等特点,面向当前日益繁多的空间计算资源,结合“计算+网络”的架构思维,实现星载算力资源的灵活调用、协同处理,满足卫星互联网应用的需求[10,11]。
2 相关工作
关于“在网络层构建算力信息感知的路由算法,实现利用多星提升协同计算效能”的早期研究中,为构建稳定的拓扑结构进行组网,相关学者基于卫星运行周期的路由算法本质上依靠卫星周期性运行的特点,将运行周期划分为离散时间片,并在时间片内建立静态拓扑结构,以达到网络层与卫星星座动态隔离的目的[12,13]。这类算法提供了解决卫星高动态性对网络拓扑影响的解决思路,但难以支持星上时延敏感型任务卸载与处理。针对卫星动态性问题,有学者提出基于网络中节点实时获取的拓扑信息构建分布式路由算法,这类算法虽然提高了链路利用率,但存在算法复杂度高,难以在星上实现等劣势[14-17]。针对算法复杂度问题,Jia Min等人将SDN思想与LEO单轨道卫星网络相结合,基于SDN的深度优先搜索和Dijkstra算法提升计算效率和计算结果可靠性,突破了传统卫星网络架构的性能限制[18]。Yang等人设计了具有收敛能力的路由协议和采用TDMA控制的链路层协议,通过仿真表明该方法适用于微纳卫星星座场景[19]。但上述研究依旧未对算力信息进行充分考量。
也有学者提出将卫星网络建模为移动自组织网络(MANET)来解决时延敏感型任务中低轨卫星高移动性的影响[20-21]。其中优化链路状态路由协议(optimized link state routing,OLSR)作为移动自组织网络中的一种典型主动式路由协议,该协议的主要优势在于网络中每个节点都可以利用MPR(multipoint relay)机制定期检索网络状态来估计当前拓扑(如图2所示)。此类研究的思路是根据不同的组网环境与要求,提出协议变体来满足组网需求。主要表现在针对能量、带宽、链路稳定性和QoS需求等不同指标来改进MPR选择算法和路由选择算法[22]。Yan等人从OLSR出发提出了基于链路稳定性的Sat-OLSR协议,通过在选举和路由算法中添加链路稳定度来适应卫星场景的高动态性[23]。其中,Huang等人在研究中从链路持续时间出发,利用节点的三维态势信息来预测链路存在的时长,从而在不增加节点数量的情况下提升了算法的分组投递率并且降低了时延[24]。Ali Moussaoui等人在研究中提出了两个新指标:节点稳定性和节点的保真度来选举稳定的MPR节点和拓扑,并且保证了相关QoS指标[25]。上述研究虽然解决了移动性问题,但针对卫星网络中邻近网络节点的算力信息利用率尚浅。
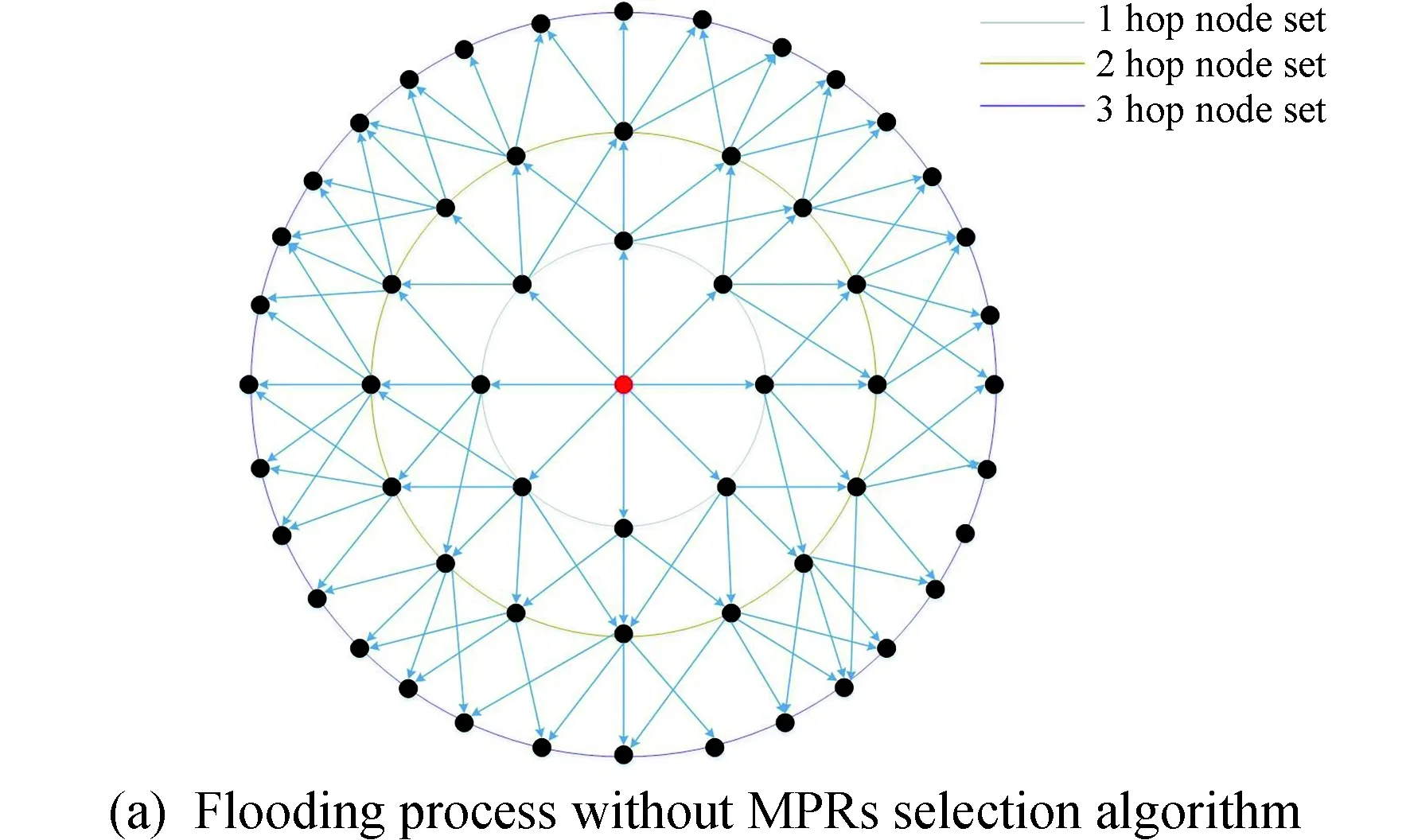
图2 有无MPRs选择泛洪对比
综上所述,现有文章对于计算资源与卫星动态性联合考虑的研究较少,本文基于移动自组织网络中OLSR协议,通过引入计算资源度和链路生存时间,提出了一种多资源度考量的星间路由协议。
3 系统模型
3.1 网络模型
在本节中将介绍所考虑的网络模型。单层LEO卫星网络由多个轨道高度相同,轨道倾角不同的Walker-Delta星座组成,卫星网络用有权无向图G(S,E)表示,其中S={s1,s2,…sN}表示卫星节点集合,E={lij|∀i∈S,∀j∈S}。每个卫星维护四条星间链路,分别为同轨道的两条,以及相邻轨道的两条。任务卸载模型如图3所示,在低轨卫星中存在不同计算资源度的卫星。卫星节点随机产生/获取空间任务,以产生任务的卫星节点为任务发起节点。计算任务请求从任务发起节点到地面站传输路径中,如果传输路径的中间卫星节点能满足计算需求,则直接在中间节点完成计算。
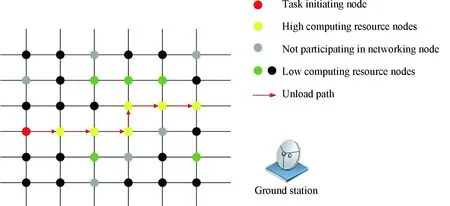
图3 任务卸载模型
文章提出的基于计算资源感知的星间路由协议,就是面向计算任务请求,寻找一条或多条高计算资源度的卸载路径,提升计算卸载的概率,从而降低任务完成时延,提升服务质量。
3.2 计算资源度评估模型
计算资源度考虑指标有:
1)CPU计算能力:可记为Capi单位为cycles/s,主要由CPU数量,CPU核心数以及CPU主频来评估。
2)内存容量:可记为Memi,单位为MByte。
3)节点负载状况:可由下式表征:
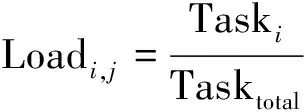
(1)
Taski,Tasktotal分别代表当前节点在规定时间j尚未完成的任务数量和需要完成的总任务数量。根据综合负载冗余率的计算方法,加入计算资源度后,量化节点计算能力的公式为:
Scomputing=α1×(0.95-OC)×Capi+
α2×(0.95-OM)×Memi-α3×Load
(2)
式中:OC、OM分别代表CPU和内存此时的占用率,并且设置95%为CPU和内存利用率的阈值。在获取CPU、内存占用率时,为避免出现瞬时高峰,此处占用率值取3s内的一个平均值。系数α1,α2,α3是根据CPU、内存和负载程度,对节点参加任务卸载以及对计算资源度的影响而在系统初始化时给定的权重值。其中α1+α2+α3=1。
3.3 任务计算时延模型
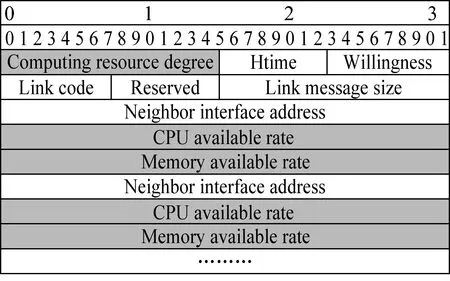
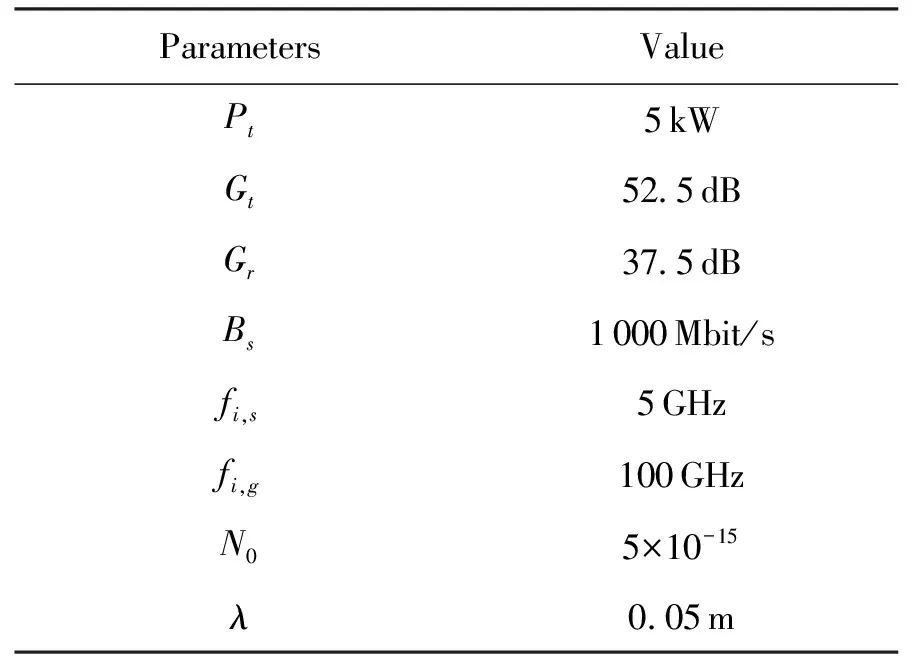
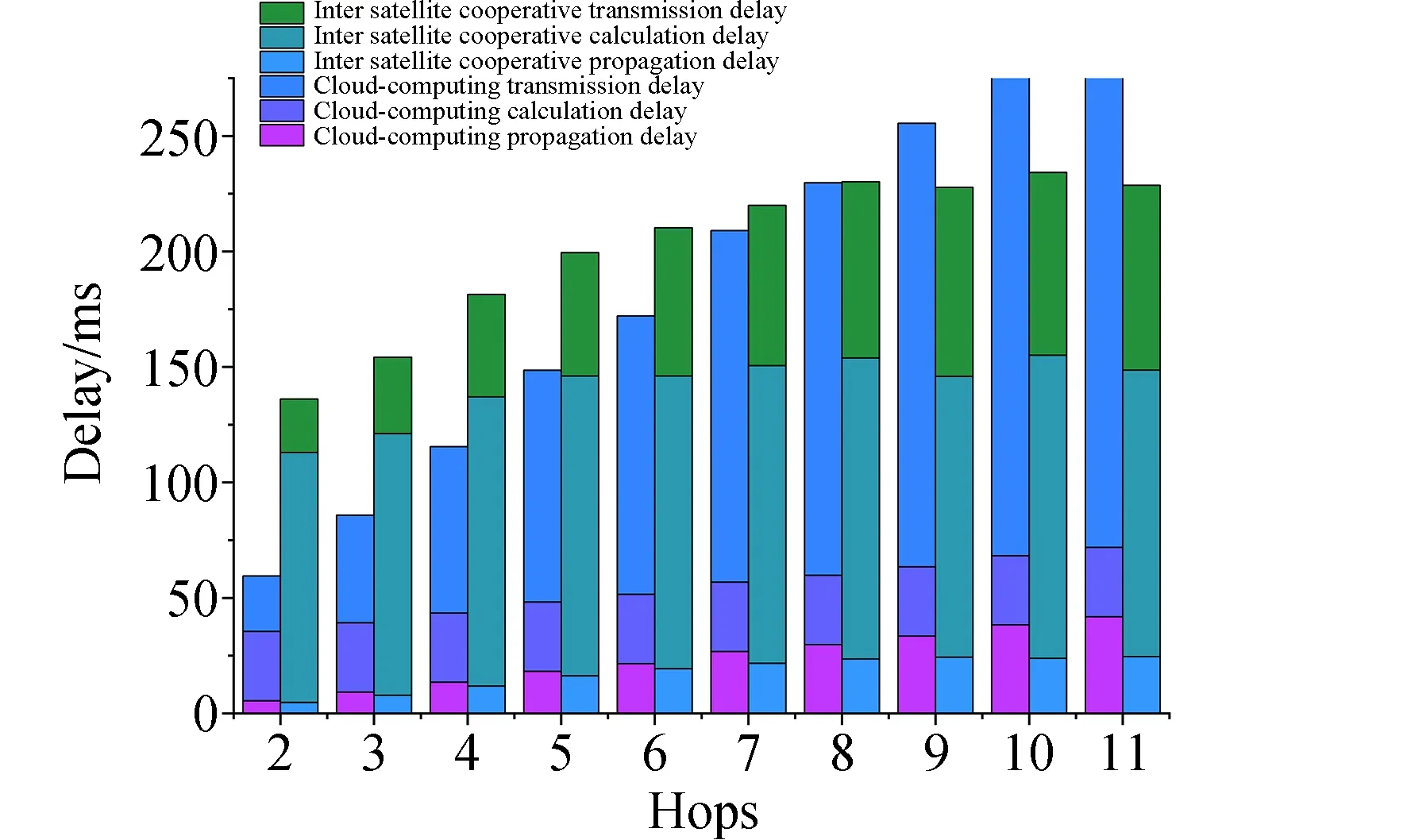
卫星si需要计算的子任务集群Ω={T1,T2,…Tj},式中Tj∈Ω(j (3) 式中:Bs代表星间信道可用带宽;N0代表背景高斯白噪声;Pr代表卸载任务时发射功率,并可由下式[26]表达。 (4) 式中:Pt,Gt,Gr代表信号发射功率、信号发射增益系数和信号接收增益系数;R为发射端和接收端距离;λ为载波波长。 所以,任务计算时延在一跳内可由下式[27]表示: (5) (6) 式中:n为从任务发起星到最终完成星间协同计算卸载所需的跳数。 为提高星间协同计算效能,提出了在OLSR协议的基础上,通过修改包格式、MPR选择算法和路由更新算法,设计基于计算资源感知的星间路由协议。通过该路由协议可为任务请求寻找一条或多条高计算资源度的卸载路径,从而降低任务完成时延,提升服务质量。 在OLSR协议中,HELLO包的Willingness字段用来表示节点参与MPR节点选取的意愿。Willingness字段的取值(记为wo)范围是从0到7的整数,其中wo= 0表示从不参选MPR,wo=7表示总是选为MPR。在原版协议中,大多数节点处于default状态,即wo= 3。TC包的ANSN字段代表通告的邻居序列号,每当节点检测到其通告的邻居集合中的变化时,该序列号递增。Advertised Neighbor Address字段包含邻居节点的主地址,始发节点的通告邻居的所有主地址都放在TC消息中。 OLSR基本工作流程如图4所示,节点会定期通过HELLO消息的泛洪感知周围节点信息,并且根据HELLO消息的更新而更新邻居表,并以此为基础进行MPR选择算法。节点在执行MPR选择算法后,根据TC消息定期更新拓扑表,通过节点拓扑表信息,逐步计算路由表。 图4 OLSR协议工作流程 文中提出的路由协议,首先基于标准化的HELLO包和TC包,分别在包头字段和包内字段中引入了计算资源度(computing resource degree),并在HELLO包的保留字段中加入了CPU可用率和内存可用率两个字段,因此节点的计算资源相关信息就会随着HELLO包泛洪至相邻节点,具体HELLO包修改字段具体如图5加深颜色部分所示。对于标准的TC包,包内字段原为邻居节点信息,现将邻居节点所对应的计算资源度加入包内字段,使得节点与节点所对应的计算资源度可以通过TC包的转发而使邻居节点得知,进而为之后的路由计算提供支撑。TC包修改字段具体如图6加深颜色部分所示。 图5 HELLO包格式 图6 TC包格式 文中提出的路由协议,基于原有的Willingness 字段,结合计算资源度参数,综合计算MPR 节点选择意愿值fcom[28]: (7) 式中:wo为Willingness字段值;ws为计算资源度Scomputing归一化为1至7后的整数。在MPR选择算法中,根据式(7)计算出各个节点的最终意愿值fcom后,优先选择fcom的节点作为MPR,其次选择两跳节点唯一可达的一跳节点作为MPR。具体步骤如算法1所示。 算法1.MPR选择算法 输入:N1(j),N2(j) 输出:MPR集合M(j) 1:计算N1(j)和N2(j)的连接度D(y); 2:计算N1(j)and N2(j)的计算资源度S(y); 3:首先将 N1(j)中意愿值fcom=7的一跳节点加入M(j)中; 4:while1 将N1(j)中唯一连接两跳节点的一跳节点加入M(j)中并将该两跳节点从N2(j)中删除; 5: while N2(j)非空Do 将剩余两跳节点所连接一跳节点中有最大 D(y)的节点加入M(j)中; 6: if多个一跳节点D(y)相同 将其中具有最大S(y)值的一跳节点加入 到M(j)中;并将该一跳节点所覆盖的两 跳节点从N2(j)中删除 7: end if 8: until N2(j)为空 9: end while 10:end while 算法1中,N1为任务发起节点的一跳邻居集合、N2为任务发起节点的两跳邻居集合、M代表MPR节点集合、D代表经一跳节点可到达两跳节点的数量(即连接度)、S代表上文定义的节点计算资源度。 路由表是根据邻居表(一跳和两跳邻居)和拓扑表的信息计算出来的。为了避免对已经接收和处理的消息重新处理,每个节点需要维护一个Duplicate Set(重复集),该集合由多个Duplicate Tuple(D_ADDR,D_SEQ_NUM,D_RETRANSMITTED,D_IFACE_LIST,D_TIME)组成,其中,D_ADDR是消息的发起者地址,D_SEQ_NUM是消息的消息序列号,D_RETRANSMITTED是指示消息是否已被重传的布尔值,D_IFACE_LIST是已在其上接收消息的接口的地址列表,D_TIME指定元组到期和必须被删除的时间。为建立拓扑表,MPR节点负责周期性广播拓扑控制(TC)包,在提出的路由协议更新算法中,TC包在遵循原生协议中的默认转发的前提下,会记录每条链路的计算资源度,如图7所示。 图7 TC包转发流程 在OLSR协议中,使用最短路径算法(Dijkstras算法)来寻找超过两跳的路径。为了在路径选择中引入计算资源度而不只是连接度,提出了Djikstras 算法的修改版本来在拓扑表的所有节点对(MPR 节点)之间找到可以满足“边传边算”的节点。具体步骤如算法2所示。 算法2.路由表计算 输入:一跳邻居表,两跳邻居表,拓扑表 输出:路由表 1:删除路由表中原有条目 2:以对称邻居(h=1)作为目标节点开始添加新的路由条目,目的地址和下一跳地址均为邻居地址地址。 3:查找路由表中跳数h最小且计算资源度权值最大的目的节点A,此时在拓扑表中查找通过A是否能到达其他节点B,一旦发现则建立新的路由表项,将新的路由表项中的目的节点设置为B,将下一跳地址设置为A,并将跳数距离设为h+1,并更新新的累计计算资源度。 4:重复步骤3,直到所有节点遍历完成,无新节点加入路由表项。 END 为了评估提出方案的效率,本节首先对提出的MPR改进算法与原生协议进行对比;然后,对星间协作计算和卸载到地面计算的业务处理时延进行对比;最后,对比在不同算力情况下对于业务的承载能力。仿真参数如表1所示。 表1 仿真参数表 fi,s,fi,g代表卫星与地面段的计算频率。 文中提出的路由协议,首先基于标准化的HELLO包和TC包,分别在包头字段和包内字段中引入了计算资源度(Computing Resource Degree),并在HELLO包的保留字段中加入了CPU可用率和内存可用率两个字段,因此节点的计算资源相关信息就会随着HELLO包泛洪至相邻节点,具体HELLO包修改字段如图6所示。 图8显示了标准MPR选择算法和所提出的MPR选择算法的性能对比。为了提升数据的可信性,在不同组网规模中都经过大量次数仿真,并对数据取均值。结果表明,在所提出的卫星模型下,文中提出的MPR选择改进算法比标准MPR选择算法和在减少泛洪节点数量上有一定的优势,这是因为其在选择作为泛洪的节点时引入了连接度的概念来减少冗余,而文中MPR选择算法过程在此基础上引入了评估计算资源度进一步根据需求去除冗余。可以看到,随着组网规模的增大 图8 MPR改进算法效果图 图9 任务处理时延与跳数变化关系 仿真结果如下,本节针对传输跳数对任务处理时延的影响作出分析。随着任务在星间传输跳数的增长,地面云计算和星间协同计算的任务处理时延总体呈上升趋势。由于地面云计算需要将任务卸载至地面,因此随着跳数的增长,星间链路的传输时延与传播时延是影响地面云计算方案的主要因素。当从任务发起星卸载到地面所需要的传输跳数为2~8跳时,地面云计算性能要优于星间协同计算。首先,在将任务下行至地面的跳数小于完成星间协同计算的跳数的情况下,地面云计算有更小的传输时延,且在地面云服务器高算力支持下,任务计算时延更小;其次,星间协同计算需要根据周边卫星节点所能提供的服务情况,决定卸载任务所需的跳数,通常,周边卫星节点所能提供更高的算力支撑时,所需的跳数越小。 当卸载任务所需跳数进一步加大时(意味着任务发起星距离目的地面站更远时),星间协同计算开始体现优势。随着跳数的增加,星间协同计算可以在任务尚未卸载至地面时,完成任务的计算。如图所示,在给定条件下,星间协同计算的传输时延和计算时延分别稳定在80ms和120ms左右。但此时,随着传播跳数的增大,地面云计算所需的传输时延以接近每跳增加20ms的速率增大。因此,在任务发起星有足够的跳数来发现周围可完成任务卸载的节点时,星间协同计算方案更优。 仿真结果如图10所示,星间协同计算的任务处理时延性能优于地面云计算。一方面,随着任务数据量的增大,由于星间多跳传输和星地长距离链路的传输,地面云计算传输时延显著增加,并且占据任务处理时延中88%的时间;另一方面,在低任务数据量时,地面云计算的高算力性能可以弥补数据传输带来的时延差距,但随着数据量的增大,这种差距逐渐增大,具体体现在计算时延的增速在26ms/MByte,而传输时延增速在66ms/MByte。由图可知,当数据量从0MByte增至5MByte时,星间协同计算任务处理性能提升效果从31.541%逐渐降低至15%左右,这是因为在设计的网络中,单个卫星节点所能提供最大的算力仅能完成任务的20%,即单个卫星承担卸载任务的能力会影响星间协同计算的性能。综上,星间协同计算相比于地面云计算更容易满足低时延需求的业务。 图10 星间协同计算和地面云计算任务处理时延对比 本小节比较本文所提出基于计算资源度的星间卸载算法(ISOA-CRD,inter satellite offloading algorithm based on computing resource degree)与加权轮转算法(WRR)和随机动态算法(Pick-KX)的时延性能,仿真结果如图11所示。 图11 多种算法时延性能对比 如图可知:当任务数据量小于1.5MByte时,各算法差异并不明显;当任务数据量大于2MByte时,随着任务数据量的增加,本文提出的算法的时延明显低于其他3种算法。例如:在仿真中当数据量达到5MByte时,本文所提出的算法时延为380ms,相较于WRR 算法(754.08ms)降低了49.6%、Pick-KX算法(670.72ms)降低了43.3%。 这是因为WRR算法根据卫星的计算性能强弱来进行映射,但由于不考虑网络中拓扑关系,因此对高并发的任务响应性能较差;Pick-KX虽然随机地将任务卸载至邻近卫星,但由于其并不考虑邻近卫星计算性能,所以也有一定的局限。本文所提出的基于计算资源度的卸载策略综合考虑了节点计算能力与网络拓扑关系,因此可以有效的降低任务处理时延。 传统组网协议存在无法感知邻居节点算力资源情况的问题,难以做到高效、系统性和快速地完成卸载任务。文中提出了一种基于计算资源度的星间路由协议,通过引入节点计算资源度来感知周边组网节点的算力、CPU、内存和负载等情况,并且根据该参数修改MPR选择算法与路由表更新算法。通过仿真评估,所提算法在组网节点泛洪和任务计算时延方面有一定优势。后续的研究工作将进一步丰富卫星组网场景,考虑高动态链路对于协议的影响。

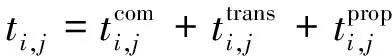
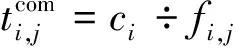
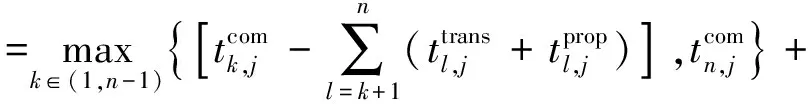
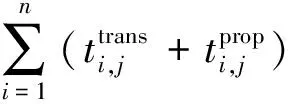
4 基于计算资源度的路由协议

4.1 包格式修改

4.2 MPR节点选择算法
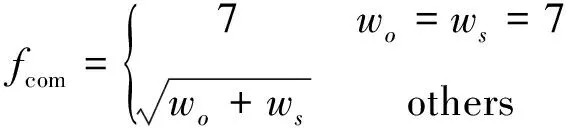
4.3 路由表更新算法

5 仿真结果
5.1 MPR选择算法改进效果

5.2 任务处理时延与跳数变化关系
5.3 星间协同计算与地面云计算任务处理时延性能对比分析

5.4 多种卸载策略算法试验性能比较

6 结论
