针对gem5 指令集实现及其功能测试的自动代码生成
2023-07-20赵紫微
赵紫微 涂 航 刘 芹 李 莉 余 涛
(武汉大学国家网络安全学院 武汉 430072)
计算机系统模拟器[1]是运行于宿主机上的软件,用于模拟目标机器的硬件和软件环境,便于使用者研究目标机器的架构与执行过程,减少硬件成本.嵌入式领域对于模拟器的需求量较大,并且在可扩展性和精确度方面有较多要求.因此,如何基于现有的模拟器快速开发原型并且在保证正确性的同时具有较好的执行效率是一个值得研究的问题.
目前的模拟器从精确度方面可以分为功能级、指令级、周期级.功能级保证其执行结果与目标机器相同,不考虑执行过程的精确性,在性能上表现最好,接近宿主机的执行速度,大多使用二进制翻译等技术提升性能,例如QEMU[2].指令级保证每条指令按顺序全部执行,不考虑指令周期和流水线的问题,大多使用即时编译(just-in-time compilation, JIT)等技术提升性能.周期级保证指令周期精确,可以仿真指令流水线,执行速度最慢,但提供更多执行细节信息,例如gem5[3].考虑到嵌入式开发中对周期精确的需求,本文选择基于gem5 进行研究.gem5 是一个开源的计算机架构模拟器,由密歇根大学的m5 项目和威斯康星大学的GEMS 项目合并而来,在学术界和工业界应用广泛.gem5 是模块化并以事件驱动的周期精确模拟器,可扩展性强.gem5 的CPU 模块采用解释执行技术,其译码模块和指令集实现独立于CPU 模块,可以与不同精确度的CPU 模型相结合.以不考虑访存延迟和流水线的AtomicSimpleCPU 模型为例,主要有3 个步骤:取指、译码和执行.其中,译码过程是由各个指令集架构中的译码模块负责.
gem5 中的指令集描述语言可以半自动地生成指令集功能代码,但需要开发者手动处理指令编码的判断并为指令编写模板替换函数.对于复杂的指令编码,手动处理指令编码的判断过于繁琐并且难以得到性能最优的实现.没有统一的指令模板替换函数导致逻辑复杂且存在冗余,总体开发效率较低.gem5 在取指过程后会由译码模块对指令编码进行预解析,之后再调用函数解析完整的指令编码,这2 个解析过程存在部分重复.此外,在实现指令集和译码模块后还需要对模拟器进行功能测试,但一些指令集没有提供公开的标准测试集,这种情况下开发者需要根据指令集文档自行编写测试程序.其中,测试用例的编写依赖于指令操作数的取值范围描述和指令的功能描述.因此,可以依据gem5 中所使用的指令集描述语言来生成功能测试中的部分数据,提高开发效率.
前人[4-5]提出了一些指令集描述方法和译码过程的优化算法,但不易与现有模拟器相结合,也没有针对gem5 进行优化.目前还没有一套为现有模拟器提供的从指令集描述到生成具体实现和测试用例的完整方案.这对于有自定义的指令需求的用户来说,在模拟器性能和项目开发效率方面有所欠缺.
本文的工作难点在于根据统一的指令集描述语言提供一个完整的开发与测试方案,并针对gem5 优化译码过程.用户可以根据指令集文档直观地描述出所有指令的信息,得到自动生成的指令集实现代码、译码模块代码和功能测试用例.
gem5 原本未支持Cortex-M3 指令集架构,本文实现了该指令集架构并引入了优化.主要工作包括指令集功能实现和内存管理单元的修改,难点在于优化译码决策树和译码模块,意义在于提供一种更高效的指令集实现方案以及增加gem5 对嵌入式芯片的仿真支持.
本文方案与gem5 原方案的流程比较如图1 所示.本文方案包括3 个阶段,首先是用词法和语法分析指令集描述文件,之后是根据指令的编码描述生成译码决策树,最后是使用统一的模板替换规则生成指令功能代码和译码模块代码.与原方案相比,本文方案重新设计了指令集描述文件格式,修改了模板替换的逻辑,增加了译码决策树生成功能并优化译码模块.此改进的作用在于简化指令定义,自动化生成译码决策树和译码模块代码,优化译码执行时间,提升开发效率.

Fig.1 Comparison of our scheme and original gem5 scheme图1 本文方案与gem5 原方案的比较
本文的主要贡献包括3 个方面:
1)设计了一种指令集描述语言和一个基于gem5的指令集代码生成方案.根据指令集的编码描述和功能描述,自动为模拟器生成指令集和译码模块代码,提升模拟器性能和开发效率.
2)提出了一个针对gem5 优化的译码决策树构建算法.该算法基于前人的算法进行扩展,并减少了gem5 中指令编码预解析阶段的重复判断,提升模拟器运行性能.
3)实现了一个指令集功能测试框架.根据指令的测试描述,使用框架中的模板为每条指令生成功能测试用例,在gem5 上运行测试程序并输出测试报告.
1 相关工作
前人的研究[4-5]提到很多针对处理器或系统仿真的描述语言的研究可以用于生成指令集功能的描述,例如Pydgin[6], LISA[7], nML[8],但这些不是针对译码过程和指令功能的描述,也不易结合到现有的模拟器实现中.本文方案主要基于gem5 的指令集描述语言进行扩展,部分指令描述的设计参考了上述描述语言.
目前一些研究提出了构造决策树来优化译码分支的方法[9-11],但在处理复杂指令结构时存在一些不能成功构建决策树的情况.Okuda 等人[12]基于前人工作提出了对于不规则指令编码的译码分支优化算法,解决了复杂指令结构处理中的问题,可以生成平均高度低且内存占用小的决策树,并在ARM 和MIPS指令集上取得了较好的结果.此算法可以用于自动化构建处理器仿真[13],此外还有研究分析了译码决策树的开销问题[14].本文基于此算法构造译码决策树,并针对gem5 译码模块做出优化,构建多个决策子树来配合gem5 的处理流程,提升译码模块性能.
指令集功能测试用于检测指令功能是否正确,例如检查单条指令执行前后的寄存器和内存的读写情况或者多条指令的处理器流水线情况[15]等.RISCV 提供了一套标准测试集[16],通过模板构建测试用例,能够测试单条指令的功能.本文搭建的指令功能测试框架中测试用例的设计参考了此测试集.
2 指令集描述
gem5 中已经实现了一个领域特定语言(domain specific language, DSL),用于描述指令集中各个指令的功能及其译码函数,文件后缀为.isa.在编译过程中,项目构建工具SCons[17]会调用Python 脚本对所编译的目标架构的*.isa 文件进行词法和语法分析,从而生成包含指令定义和译码函数的C++文件,最后SCons 将这些生成的文件添加到编译任务中.
在实际使用中,我们发现该指令集描述语言存在2 个问题:
1)译码函数主要由开发者手动编写.当指令数量较多且复杂时开发效率不高,并且手动编写的译码函数可能存在冗余,在执行效率方面有待优化.
2)用于生成C++代码的模板替换逻辑和待替换的数据没有分离.Python 脚本会使用函数exec()来处理这些字符串.然而这些模板替换逻辑非常类似,这种实现方式不仅增加了不必要的复杂性,而且不易维护.
本文参考了该指令集描述语言的实现,并提出了一种包含指令编码和指令功能信息的指令集描述语言,可以自动生成译码函数并自动完成指令功能代码与C++代码模板的替换.此外,对于不公开提供功能测试套件的指令集或是添加了自定义指令的情况,考虑到自行编写指令功能测试时很多所需的信息可以由指令集描述提供,本文方案允许标注操作数限制等指令测试所需的信息,支持生成指令的功能测试用例.
本文方案包括编码描述、功能描述和测试描述3 部分.这里以ARM Cortex-M3 的AND 指令为例来说明,如图2 所示.
2.1 编码描述
编码描述用于说明指令编码的结构与限制,用于构造译码决策树.本文方案将编码抽象为由固定位段和可变位段组成的结构,其中可变位段的取值可能存在一些限制.下面结合实例来说明其具体实现.
指令编码是一串由0、1 和小写字母组成的字符串.其中,0 和1 表示指令编码中取值确定的位,小写字母表示指令编码中取值可变的位.同一小写字母必须相连,表示一个可变的位段.例如,指令t1_and_reg的编码为0100000000mmmddd,说明第0 位和第2~9位为0,第1 位为1,第10~12 位为一个可变位段 {m},第13~15 位为另一个可变位段 {d}.
对于不符合要求的编码情况,使用EXCLUSION语句列出可变位段的所有例外表示,将其作为该指令编码的排除条件.例如,指令t1_and_imm 的编码排除了 {n}为13 到15 和 {d}为13 或15 的情况.
2.2 功能描述
功能描述用于说明指令功能的实现和标注信息,用于生成指令功能代码和提供仿真所需的控制信息和计数信息.本文方案将功能抽象为由特定功能代码和模板组成的结构.下面结合实例来说明其具体实现.
代码块由{{和}}来表示,在代码块中可变位段可以作为数值来使用,REPLACE_MAP 中定义替换词可以在前后加上@作为代码片段来使用.
指令构造函数代码以代码块形式定义在指令编码描述结束后,用于为指令基类定义的操作数变量根据实际编码来赋值.例如,指令t1_and_imm 的基类为DataImm,其中定义了操作数寄存器的序号、立即数、其他参数和功能函数等.
指令功能函数代码存放在一个字典结构中,代码块所对应的序号会作为参数传入FORMAT 语句.FORMAT 语句用于处理C++模板替换过程,定义在构造函数描述之后.例如,CODE { 0: {{ inta=0; }} }说明指令功能代码为inta=0,其对应序号为0.
FORMAT 语句会根据指令类型的格式从FORMAT_MAP 中得到对应的C++代码模板和参数格式,之后通过字符串替换生成相应的指令类.例如,指令类型AND 的格式为PredProcessOp,其C++代码模板为BasicDeclare, BasicConstructor, PredProcessExecute,分别用于指令类的声明、构造函数和功能函数的生成,其参数格式为['process_code'].指令t1_and_imm 将[0, 3]传入FORMAT 语句,即将序号为0 和3 的代码拼接后的值作为process_code.
2.3 测试描述
测试描述用于说明指令功能测试的参数要求,用于辅助生成指令功能测试.本文方案将功能测试抽象为由测试参数和测试模板组成的结构.下面结合实例来说明其具体实现.
指令测试的所需的信息由TEST 语句负责处理,用于生成该指令的功能测试用例.TEST 语句的参数对应于该指令的汇编表示,例如指令t1_and_imm 的汇编表示包括可选的标记S和条件cond,以及2 个寄存器类型Rx 和1 个立即数类型Constant.类型Rx 和类型Constant 定义于TEST_MAP 中,设置了其取值范围和函数名,在测试用例生成时会调用类型所对应的函数来生成数值.
3 译码决策树生成
本节说明了译码决策树生成过程中涉及的基本概念,并给出了译码决策树生成算法的具体描述.本文方案对前人所提出的算法[12]进行了改进,并结合gem5的特性实现了针对性优化.
3.1 基本概念
本节定义决策树的输入与输出形式,以表1 中的译码项来说明基本概念.令指令集中的1 条指令编码对应1 个译码项,算法的输入为1 个译码项集合,算法的输出为由该译码项集合生成的1 个译码决策树.
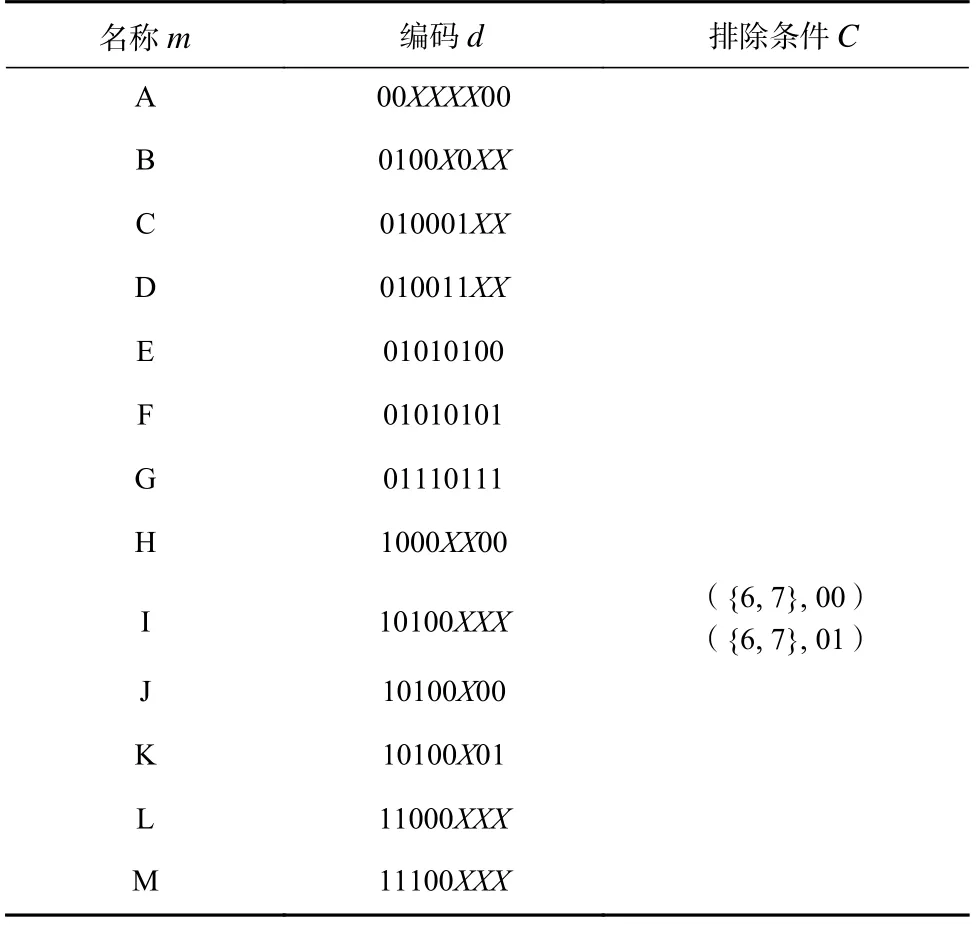
Table 1 An Example of Decoding Entries表1 译码项示例
3.1.1 译码项
译码项e包括名称m、编码d和排除条件集合C,记为e=(m,d,C).其中,译码项的名称和编码是唯一的,排除条件可以为0 或多个,译码项集合记为E,E={e}.
本文方案将编码定义为d∈{0,1,X}n.其中,X表示该位可以与0 或1 相匹配,用于表示可变位段,编码长度为n位.给定一个位串s∈{0,1}n,定义位串s与编码d的匹配规则为∀i∈{0,1,…,n-1},当且仅当s[i]=d[i]或d[i]=X时,位串s与编码d匹配,记为s∈d.若该编码所对应的译码项e无排除条件,则位串s与译码项e相匹配,记为s⇒e.例如,位串00001100匹配编码00XXXX00.
3.1.2 译码项中的排除条件
为了能够编码更多指令,在设计指令集时某些编码被添加了排除条件,即对编码中的可变位段设置了取值限制.若位串的某些可变位段等于特定常数时,则与该编码不匹配.
一个排除条件包括一个下标集合Iex和 一个排除项pex,记为(Iex,pex).其中,下标是从小到大排列,且与排除项的各位按序一一对应,即将应排除的值的第i位记为pex[i′].本文方案定义位串s使得排除条件(Iex,pex)成立的判定规则为:∀i∈Iex,当且仅当s[i]=pex[i′]时,位串s使得排除条件(Iex,pex)成立,记为exclude(s,(Iex,pex)).例如,译码项的排除条件({6,7},00)表示应排除第6 位和第7 位都为0的位串.
因此,本文方案定义位串s与具有排除条件的译码项ec=(mc,dc,Cc)的匹配规则为:当且仅当s∈dc且∀(Ic,pc)∈Cc,¬exclude(s,(Ic,pc))时,位串s与译码项ec相匹配,记为s⇒ec.例如,位串10100000虽然与名称为I 的译码项和名称为J 的译码项的编码匹配,但由于名称为I 的译码项的排除条件({6,7},00)成立,所以该位串是与名称为J 的译码项匹配.
3.1.3 译码决策树
译码过程是通过逐步查询位串中特定位段的值来获得该位串所匹配的译码项.本文将这个过程用译码决策树来表示,记为T=(VT,ET).其中,VT表示节点的集合,ET表示边的集合.每个节点有唯一标识符,记为nid.本文将节点分为内部节点和叶节点.内部节点表示译码选择分支,包含一个特定位的下标集合I和一个元组集合,每个元组由标签和子节点组成,记为(p,vchild).其中,下标集合中的元素从小到大排列,且与标签的各位按次序一一对应,l为下标集合的长度,标签p∈{0,1}l为叶节点,其表示译码查询所匹配的最终结果,包含一个译码项.
译码决策树示例如图3 所示.内部节点由包含其标识符nid和下标集合I的方框表示,边框为弧线表示该节点在优化过程中被修改过.叶节点由包含其标识符nid、译码项名称m和译码项编码d的方框表示.每条从内部节点所出的边的标签p和所指向的子节点vchild由该内部节点中的各个元组(p,vchild)得出.

Fig.3 An example of a decoding decision tree图3 译码决策树示例
3.2 算法描述
本节详细说明了构造译码决策树的算法.首先,分析了前人的工作[12]并提出了本文方案的译码决策树构造算法,扩展了前人对于内部节点的构造方法并增加了2 个优化策略.此外,本文方案还针对gem5的译码过程对译码决策树和生成的代码做了优化.最后,给出一个示例来说明每种优化策略所针对的情况和优化效果.
3.2.1 基础算法Okuda 等人[12]的算法主要包含3 个过程:1) 过程MakeTree根据给定的译码项集合E递归创建译码决策树的节点及其子节点.2) 过程MakeNode创建一个无排除条件的内部节点,并将译码项集合E划分为多个子译码项集合,为每个子译码项集合创建子译码决策树.3) 过程MakeConditionNode创建一个有排除条件的内部节点,并将译码项集合根据是否符合排除条件划分为2 个子译码项集合,分别为这2 个子译码项集合创建子译码决策树.此外,该算法是通过与指令长度相等的编码格式来划分子译码项集合.例如,使用以0 开头和以1 开头的4 位编码格式来划分包含编码为0101 和1 101 的译码项集合.
Okuda 等人[12]的算法存在2 个问题:
1)过程MakeConditionNode在划分子译码项集合时仅根据其是否符合排除条件分为2 类.对于不符合排除条件但也可被区分的子译码项来说,可能会再次处理该相同位段,导致译码决策树的高度增加.
2)算法根据与指令长度相等的编码格式来划分译码项集合,不便于添加额外的优化策略,例如处理个别位的合并或移除操作.
本文方案的算法基于Okuda 等人[12]的算法做了扩展和优化.在构造内部节点时,本文方案使用下标集合I所确定的多个标签来划分译码项集合,每个译码项根据其编码在该下标集合I处的取值情况划分到不同的标签p下.本文方案为每个标签的译码项集合构造译码决策树,并将其作为该内部节点的子树.此外,本文方案修改了过程MakeConditionNode的实现,使其能够根据排除条件的下标集合Iex来区分多个子译码项集合.并且,本文方案以能够区分出最多子译码项集合的下标集合I来创建节点,这样可以避免重复判断相同位段的值并减少译码决策树的高度.
3.2.2 扩展算法
本文方案的算法对过程MakeNode和过程Make-ConditionNode做了扩展和优化,见算法1.
算法1.译码决策树构建算法.
过程MakeNode用于创建一个不使用排除条件的内部节点.首先,过程GetS igni ficantBits根据译码项集合E找出一个下标集合Isig,使得所有译码项可以用标签区分.过程S elOptBits根据下标集合划分各个标签对应的子译码项集合,将结果记为子节点信息In fo.之后检查是否可以通过扩增下标集合以减少译码决策树高度,如果可以优化,则更新下标集合Isig和子节点信息In fo.过程MakeChild会调用过程Make-Tree并根据子节点信息和尚未处理的下标集合来递归创建子节点译码决策树,将结果记为Tchild.如果创建的子节点译码决策树中存在已优化的节点,则需要通过过程ReselOptBits再次更新下标集合Isig、子节点信息In fo和子节点译码决策树Tchild.最后,过程CreateNode创建此内部节点,记录其下标集合Isig和子节点译码决策树Tchild,并设置节点类型是否为已优化节点.图4 展示了优化后的效果,将下标2 增加到根节点的判断中,减少了名称为G 的译码项和名称为M 的译码项所在的层数.
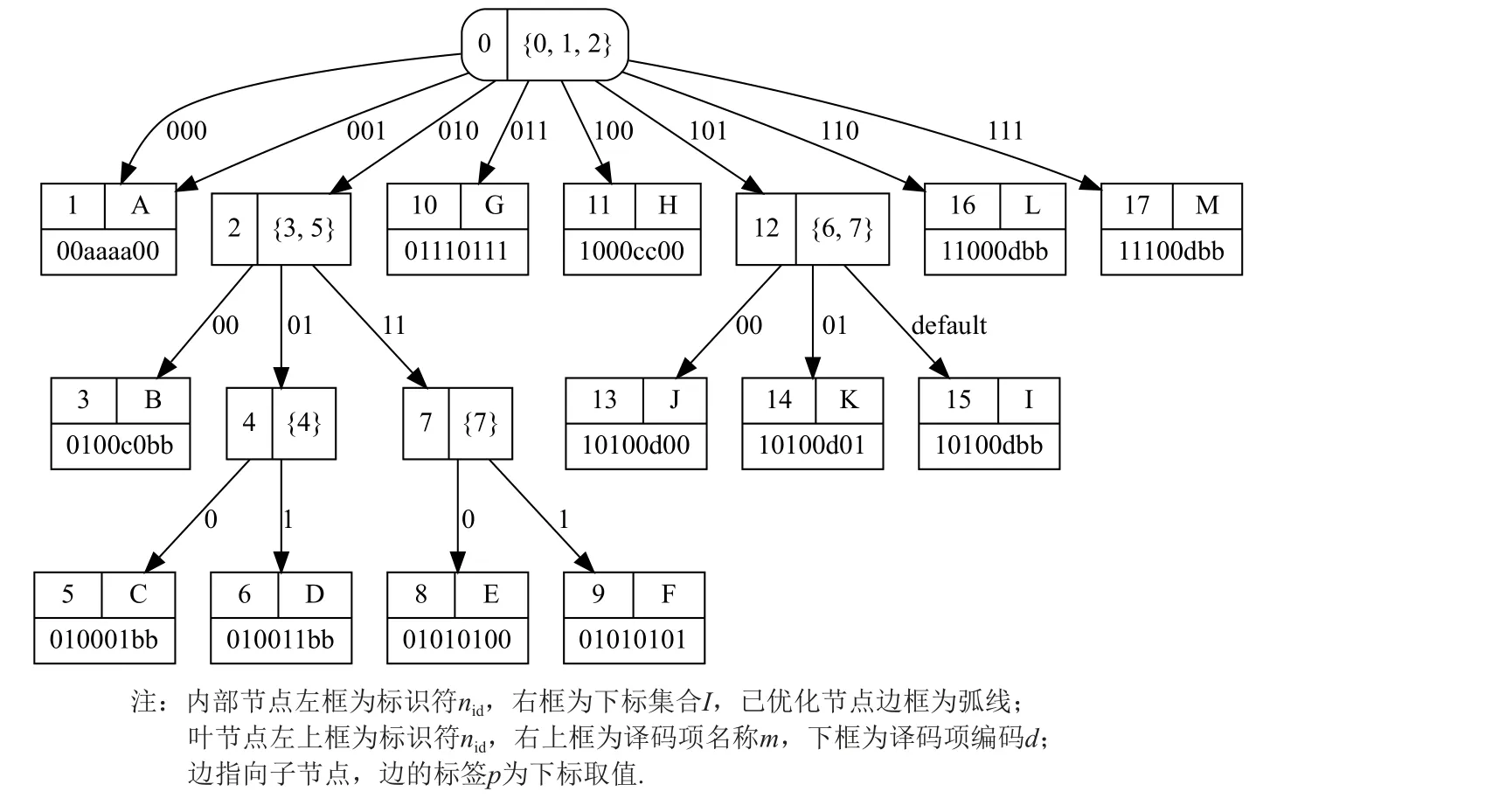
Fig.4 The decoding decision tree optimized by process MakeNode图4 使用过程MakeNode 优化的译码决策树
过程MakeConditionNode用于创建使用排除条件的内部节点.首先,过程S elConditionBits根据译码项集合E从各个译码项的排除条件中找出一个排除条件(Iex,pex),使得根据此下标集合Iex划分得到的标签数量最多,将结果记为子节点信息In fo.这里没有使用过程MakeNode中的优化方法是因为使用排除条件所得到的标签中一定包含default,之前的优化不适用于这种情况.之后执行过程MakeChild,将结果记为Tchild.最后,过程CreateConditionNode创建此内部节点,记录其下标集合Iex和子节点译码决策树Tchild,并设置节点类型是否为使用排除条件的节点.图5 说明了Okuda 等人[12]的算法对于条件节点的处理,仅判断是否满足排除条件,未考虑相同下标对应多个可区分编码的情况,导致冗余判断.本文使用下标集合来划分子译码项集合,因此在确定下标集合后,其划分方式与常规内部节点相同,如图3 所示.
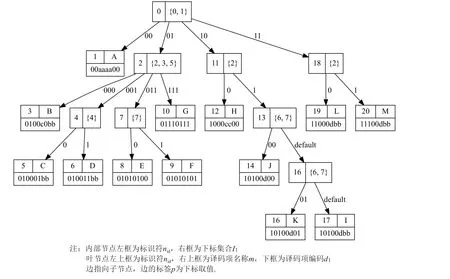
Fig.5 The condition node of Okuda et al’s algorithm图5 Okuda 等人所提算法的条件节点
此外,本文方案新增了过程OptimizeTree、过程OptimizeNode、过程FixNode和过程FixTree对译码决策树进行整体优化和调整,见算法2.
算法2.译码决策树优化算法.
过程OptimizeTree和过程OptimizeNode用 于前序遍历译码决策树中的节点并做优化.首先,过程Get-OptimizableBits检查节点N的内部子节点的下标集合Isig是否仅包含1 个元素,将满足条件的下标集合取并集作为待选下标集合.遍历待选下标集合,检查其他各个内部子节点下的所有译码项是否在该下标处取值相同.如果存在这样的下标,则将其加入到Iopt中.之后,对于节点N的每个叶子子节点Nleaf,使用过程GetLeaf Pattern修改指向此Nleaf的标签,将结果更新到Tchild中.遍历下标集合Iopt,对节点N的每个内部子节点Ninner用过程GetInnerPattern确认是否需要移除此内部节点,并修改指向此Ninner或其子节点的标签,将结果更新到Tchild中.最后过程UpdateOptimizableNode修改节点N的下标集合为Iopt,更新子节点译码决策树Tchild,并设置节点类型是否为已优化节点.图6 展示了优化后的效果,将下标4 增加到2 号节点的判断中,减少了名称为C 的译码项和名称为D 的译码项所在的层数.
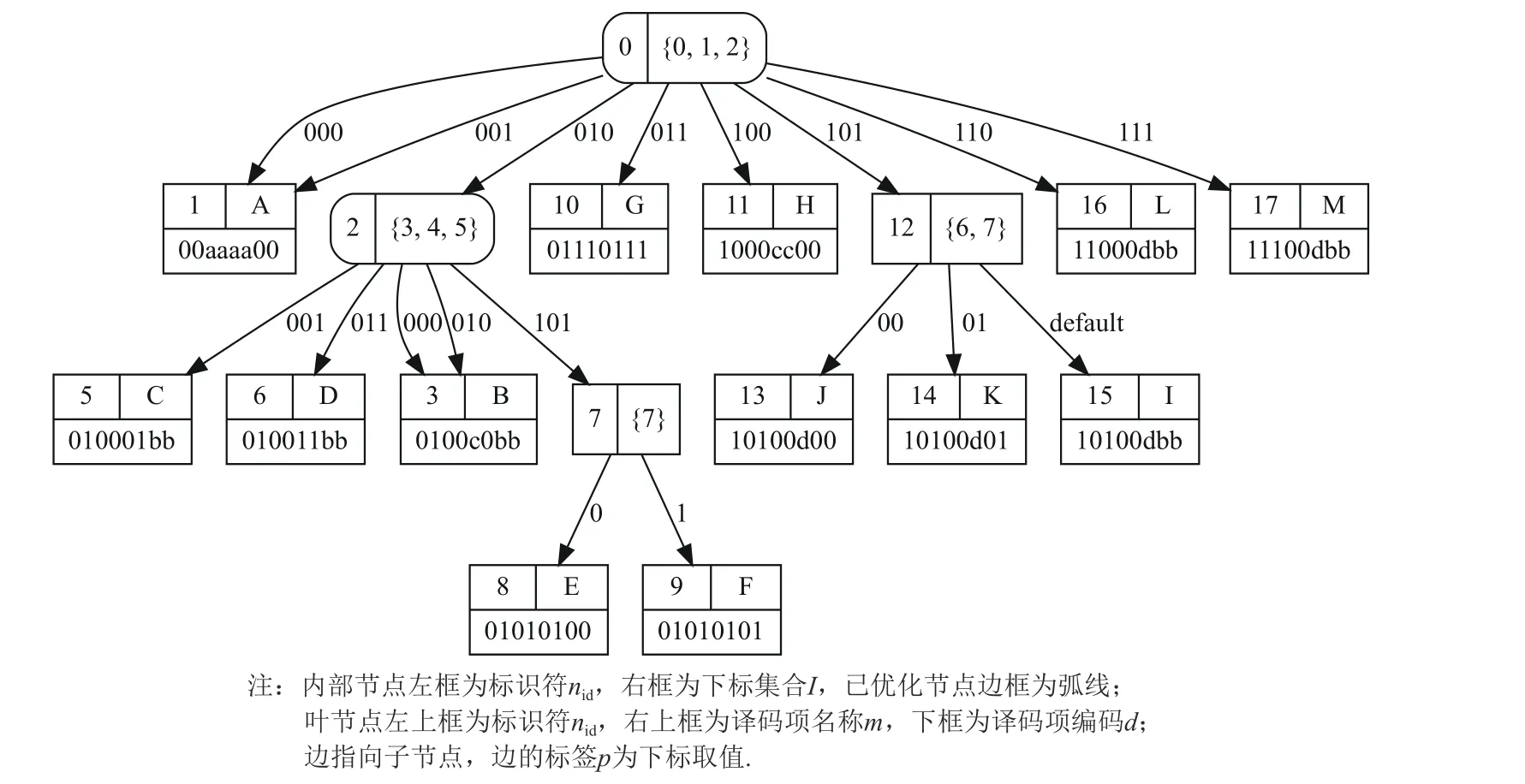
Fig.6 The decoding decision tree optimized by process OptimizeTree based on fig.4图6 在图4 的基础上使用过程OptimizeTree优化的译码决策树
过程FixTree和过程FixNode与前2 个过程类似,用于修正指向译码决策树中叶子节点的边,将重复分支的标签合并为default.图7 展示了优化后的效果,由于根节点下的分支数已达到最大且仅有名称为A的译码项对应多个标签,所以本文方案将这些标签合并为default.
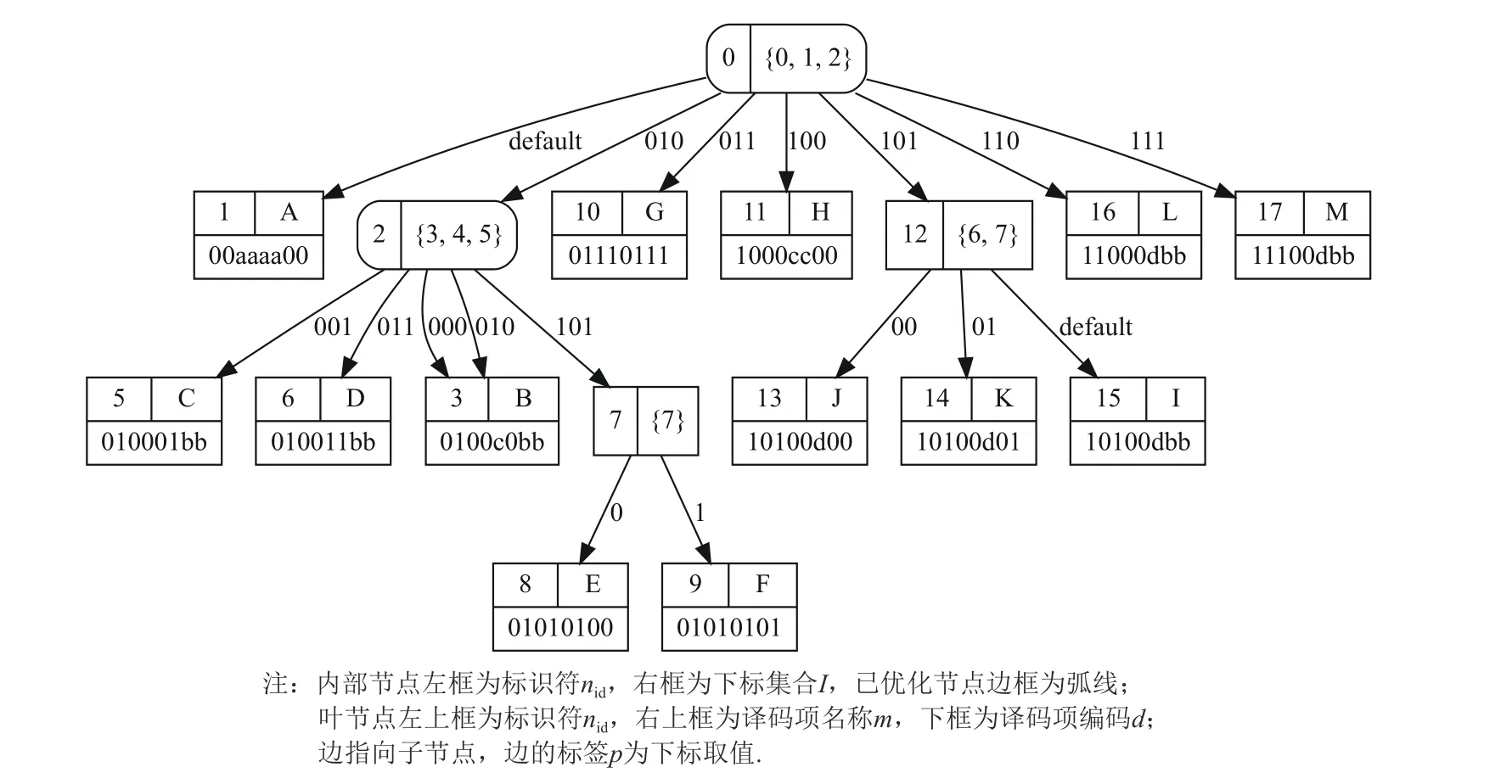
Fig.7 The decoding decision tree optimized by process FixTree based on fig.6图7 在图6 的基础上使用过程FixTree优化的译码决策树
3.2.3 gem5 中的译码过程
在gem5 的实现中,CPU 在译码阶段会先将取指阶段得到的数据传给译码模块,然后调用译码模块来解析指令并得到一个基类指针,在执行阶段会调用其所指向的具体指令对象的执行函数,具体处理流程如图8 所示.

Fig.8 The decode and execute processes in gem5图8 gem5 中的译码和执行流程
译码模块中的指令解析过程分为2 个阶段:预解析阶段(图8 ①)和译码阶段(图8 ②).首先,预解析阶段的函数moreBytes() 会根据大小端和指令长度对取指阶段得到的数据块进行处理,得到符合译码要求的具体指令位串.之后,译码阶段会调用译码函数对该指令位串进行解析.其中,译码函数的源文件是根据指令集描述语言在编译过程中生成的,其函数体为一个多层嵌套的switch-case 结构.
指令长度是根据位串中特定位的值来判断,这个过程与之后译码函数中的操作存在重复,即预解析阶段和译码阶段都会对同一段指令编码进行判断.以Cortex-M3 指令集为例,16 位Thumb 指令和32 位Arm 指令是由指令编码的前5 位来区分的,因此预解析阶段和译码阶段都会判断这前5 位.此外,条件指令IT 因为其条件执行功能涉及对译码模块的操作,所以会在预解析阶段中被完整解析,但在之后的译码阶段仍会被再次解析以获得一个指向该指令对象的指针.
为了解决上述问题,本文方案将原方案的译码函数拆分为多个译码函数,并使用函数指针优化调用过程.具体来说,本文方案的算法会根据指令集描述文件中设置的指令长度下标集合及其取值情况来构造多个译码决策树,从而生成多个译码函数.此外,本文方案的算法会自动生成预解析阶段所需的指令长度判断函数,以便根据判断结果选择对应的译码函数.
4 测试用例生成
本文方案搭建了一个对指令进行功能测试的框架,能够根据指令集描述为每条指令生成功能测试用例,并在gem5 上运行所生成的测试程序得到测试报告.该框架主要包括3 部分:操作数数据生成、期望值数据计算和测试程序模板.
以ARM Cortex-M3 的AND 指令为例,其操作数生成和期望值计算见算法3.该指令的汇编表示有2 种,即AND{S}{cond}Rn,#constant和AND{S}{cond}Rn,Rm,shi ft.其中,S表示是否更新状态位,cond表示执行的条件,Rn表示寄存器,#constant表示满足特定格式的立即数,Rm和shi ft表示寄存器及其移位信息.
算法3.功能测试用例生成算法.
输入:指令测试描述info、测试范围range和测试用例数量num;
输出:测试用例列表G.
过程GenData(info,range,num)
过程GenData用于生成操作数数据,根据指令测试描述info、测试范围range和测试用例数量num来随机生成操作数,并在边界附近多生成一些值,之后调用过程GenExpAND生成期望值expects,最后返回测试用例列表G.
过程GenExpAND用于生成期望值数据,根据指令测试描述info和操作数ops来计算期望值expects,最后返回结果.
此外,本文方案准备了一系列测试程序模板,以宏的方式组织汇编指令,能够为每条指令生成相应的汇编文件作为测试程序.每个用例以宏的方式呈现,例如TEST_AND_R_OP2C(testnum,inst,expExec,expRes,expApsr,Apsr,Rn,Constant)是用于AND 指令的第1 种汇编表示的宏,参数包括用例编号、被测指令、期望值和操作数.
5 实验结果
本文实验环境的CPU 为Intel Core i5-10400 @2.90 GHz,内存为32 GB,系统为Linux Mint 20.1 Kernel 5.4.0-89-generic.本文的gem5 配置为系统调用仿真(system call emulation, SE)模式,CPU 模型为Atomic-SimpleCPU,编译版本为fast.本文方案中的指令集描述语言使用SLY[18]作为词法和语法分析工具①gem5 原词法和语法分析工具为PLY(Python Lex-Yacc), SLY(Sly Lex-Yacc)是其新版本.,并且修改了gem5 的编译脚本,将本文方案整合到项目的构建过程中.
实验选择Cortex-M3 指令集作为待描述的指令集,该指令集在gem5 项目中未做实现.实验分别使用gem5 原方案与本文方案实现该指令集,并比较这2 种方案的性能以及所生成的代码的运行性能.此外,在实验前使用第4 节的功能测试框架为其生成了指令功能测试用例并确保其能正确执行,即保证所实现的Cortex-M3 指令集的译码和执行过程是功能正确的.
5.1 方案性能比较
指令集中每条指令编码的查找路径的长度是在译码决策树中根节点到其所对应叶节点的边数,即叶节点v在译码决策树T中的高度,记为HT(v).将各译码决策树中叶节点高度的平均值记为,将译码决策树集合中所有叶节点高度的平均值记为.
比较gem5 原方案与本文方案所生成的译码决策树高度,结果如表2 所示.Cortex-M3 指令集共有226 个指令编码.原方案生成的译码决策树中叶节点的最大高度为10,最小高度为3,总平均高度为5.52.本文方案共生成4 个译码决策树和1 个IT 指令的译码函数,总平均高度为2.87.其译码范围是根据预解析阶段所处理的指令前5 位取值以及是否为IT 指令来划分的,表2 中标明了各个译码决策树负责处理的译码范围.其中,16 位指令的译码决策树包含指令编码数量最多,32 位指令(以11101 开头)的译码决策树的平均高度最大.与依赖开发者手动构造译码函数的原方案相比,本文方案在译码决策树高度方面的优化效果较好,并且很大程度上提升了开发效率.
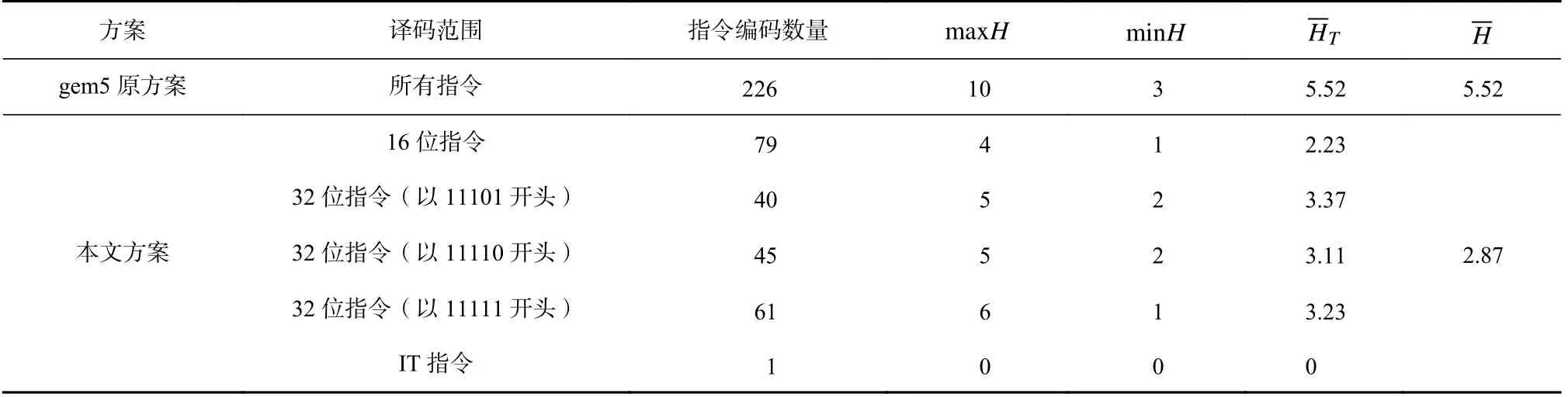
Table 2 Comparison of the Height of the Generated Decoding Decision Tree Between Two Methods Under Cortex-M3表2 在Cortex-M3 指令集下2 种方案所生成的译码决策树高度的比较
此外,统计这2 种方案生成译码决策树及其C++源文件的时间和编译后的可执行文件gem5.fast 的代码大小,结果如表3 所示.原方案需要开发者手动编写译码决策树,并且需要将模板替换逻辑与指令定义写在同一指令集描述文件中,在解析的同时处理替换过程,耦合度较高.本文方案仅将指令定义写在指令集描述文件中,之后根据编码信息自动生成译码决策树和C++源文件,所用的总时间比原方案减少了约64%,代码大小减少了约407 KB.
5.2 在gem5 中的运行情况
在gem5 中运行一些测试程序并比较2 种方案的运行性能.实验使用的测试程序来自Embench[19],这是一个面向嵌入式设备的开源测试集,它包含22 个测试程序,支持对真实机器和模拟器的测试.该测试集原本是通过远程调试器来获取测试函数前后的指令周期数来评估处理器速度,而本文所研究的译码模块优化不影响模拟器中的周期数,所以我们改为获取测试函数前后的实际时间来评估模拟器译码模块的性能,即通过shell 命令获取宿主机时间.为减少额外操作对时间的影响,我们将默认的测试循环次数由1 改为10,
每个用例用时大约在10 s 左右.此外,gem5 原本使用了一个译码表来缓存相同地址或相同指令编码的译码结果.由于实验所用的测试程序都依赖于循环,并且在开始计时前会先运行几轮来预热缓存,导致gem5 实际运行时2 种方案几乎没有区别.这与本文实验目的不符,因此我们在测试时关闭了译码缓存功能.
测试结果如图9 所示,原方案平均用时10.24 s,本文方案平均用时8.91 s,比原方案减少了大约13%.
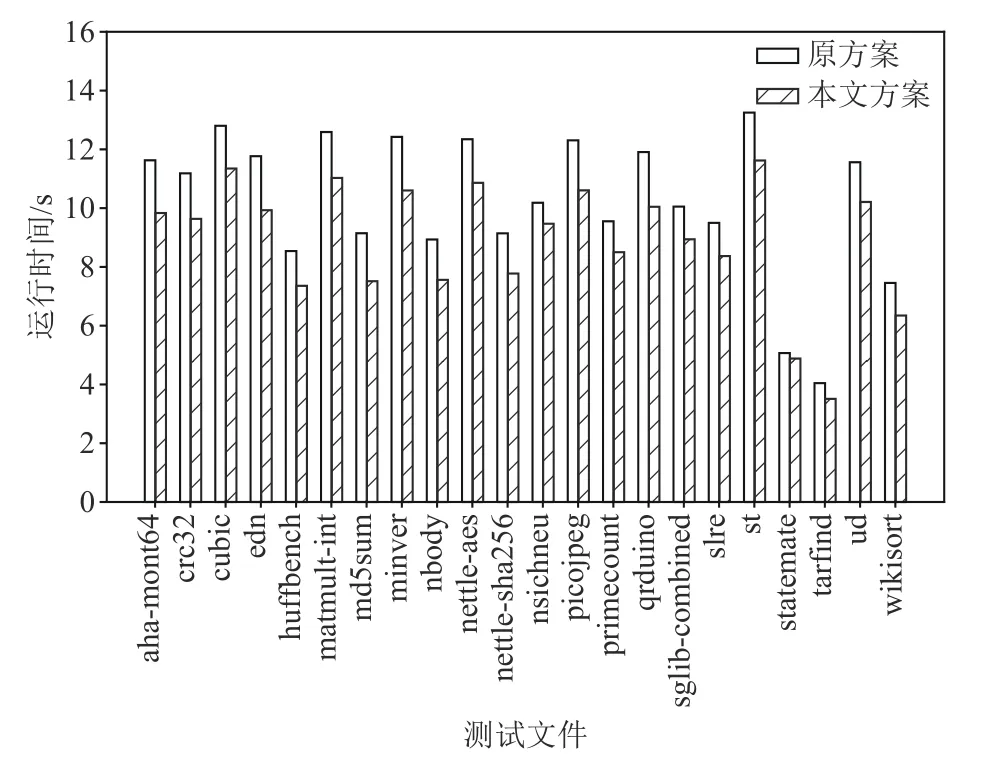
Fig.9 Execution performance of two methods in gem5 Under Cortex-M3图9 在Cortex-M3 指令集下2 种方案在gem5 中运行性能
5.3 方案效果分析
本文方案的译码决策树生成算法采用划分编码位段的方式,通过计算位段的匹配情况和使用多个优化策略来构建树的节点,从而减少译码过程的时间开销.
译码过程的搜索时间开销与译码决策树的高度呈正相关.树的每个内部节点所处理的位数n决定了该节点的子节点数量上限 2n.对于相同的指令数量,树中内部节点指向新子节点的分支数量越多,树的高度越低.因此在树的构造过程中需要充分考虑指令长度和编码限制条件,处理节点之间的合并优化.
为进一步说明改进效果,我们使用本文方案为RV64GC 指令集生成了译码决策树并与gem5 原方案已实现的译码函数做比较,结果如表4 所示.RV64GC指令集的编码设计较为规整,较少使用编码的排除条件,因此其译码决策树的高度整体较为平均.RV64GC 实验结果与Cortex-M3 类似,本文方案有效降低了译码决策树的最大高度并且优化了平均高度.

Table 4 Comparison of the Height of the Generated Decoding Decision Tree Between Two Methods Under RV64GC表4 在RV64GC 指令集下2 种方案对于所生成的译码决策树高度的比较
6 讨 论
本文方案支持使用gem5 中提供的接口函数和类型定义(如向量操作),可以用于实现其他指令集架构,例如MIPS 和Cortex-A 等.从RV64GC 的实验结果可以看出,自动化生成和优化的预解析阶段的辅助函数和译码决策树可以在一定程度上降低译码决策树的平均高度,提升执行效率.此外,本文方案的指令集描述文件更易被编写与修改,开发效率较高.
本文方案的编码描述和译码决策树生成算法具有通用性,能够应用于指令译码过程,而功能描述和代码生成阶段则与模拟器的具体实现关系紧密.若要将本文方案推广到其他模拟器,则还需从实现角度考虑模拟器是否可以采用这种译码和执行流程,以及这种模板替换策略能否与模拟器其他模块适配.
7 结 论
本文方案解决了模拟器的指令集实现及其功能测试的开发效率问题并提升了gem5 译码模块的性能,为添加新指令集或自定义扩展指令的开发与测试提供了一套完整方案.本文方案设计的指令集描述中定义了指令集的编码描述、功能描述和测试描述,用于生成模拟器的译码模块代码、指令集实现代码和指令功能测试用例.本文提出了一个针对gem5优化的译码决策树构造算法和一个指令功能测试框架.该算法使用指令的特定位和排除条件位来判断指令编码,并且允许根据gem5 指令预解析阶段的条件划分各个决策树的范围,从而降低译码决策树的平均高度并且减少了原方案中的重复判断,提升执行性能.此外,该指令功能测试框架可以根据指令集描述生成指令功能测试用例,提升开发效率.
作者贡献声明:赵紫微为论文工作的主要完成人,负责实验设计与实施、论文撰写;涂航和刘芹审阅论文的内容并提出意见;余涛协助论文功能测试的软件实现;李莉对论文提出修改意见,完善论文思路和实验设计,负责论文审校.
