异构数据融合驱动的股市波动预测研究
2023-07-17叶慕戎鲁越谭楚婷
叶慕戎 鲁越 谭楚婷

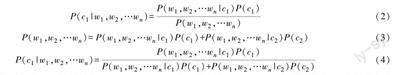
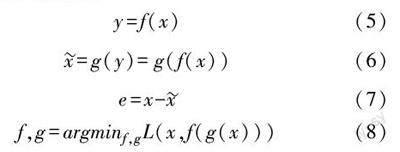
摘要:由于股票市场具有复杂性、动态性和混乱性等诸多特点,其波动易受各种信息源的影响,因此对其预测具有相当的挑战性,而机器学习方法的应用在目前取得了一定的成功。文章从深度学习方法出发,融合多种数据源,提出一种异构数据融合驱动的神经网络模型,探索股市舆情、量化指标与股价波动的内在联系,以及媒体信息对股市波动的影响机制。
关键词:多特征融合;舆情分析;股市预测;LDA;神经网络
中图法分类号:TP181 文献标识码:A
1 引言
由于金融时间序列数据存在复杂、非线性、难以预测的情况,因此股票市场的预测任务充满挑战[1] ,金融业界也一直在寻找能够系统地预测未来资产收益的方法,尝试预测资产的有效收益,然而股票市场处于极其动荡和嘈杂的环境中,这项任务无疑困难重重。传统股票预测方法往往仅依赖历史定量数据进行拟合分析,如价格、交易量、周转率等。作为定量数据的补充,文本信息也成为部分研究者关注的对象[2] 。使用计算机技术抽取海量舆情观点,对文本进行挖掘爬取处理,将特征进行整合,可以分析出股票市场发展动态的优劣,为每个投资者提供各自不同且具有针对性的建议和方法。随着文本情感分析的高速发展,简单文本极性判断已不能满足人们对互联网的需求,跨学科、跨平台的研究,将文本分析技术广泛应用在不同的领域。将引导机制、营销理论以及多元盈利模式融合,以提高模型性能。随着数据挖掘的深入,面向股票市场领域的细粒度情感分析技术的应用解决了隐式情感难提取、文本不规范等問题。学者正应用实践企图证实舆论与股票市场的相关性以及试图应用舆论预测市场的走向[3~5] 。
本文主要讨论了量化指标、股市舆情与股价波动间的潜在关联,为金融从业者、研究者提供了一种全新的视角,以行为金融学对行为人决策的研究成果为研究基础,寻求投资者在金融市场中可能会受到来自认知系统的各种偏差及对其信息处理和决策过程的影响,以期建立一个从投资者情绪到投资者行为,再到投资者行为对金融市场和实体经济影响的科学研究模式。
2 文献综述
多源数据融合技术是数据挖掘与机器学习领域中一种常见的特征处理手段,基于人工智能、模式识别、统计推断等,在医疗诊断、目标识别、自动驾驶等领域都有着良好的应用,通过融合不同数据源、不同粒度的信息,可以更好地捕捉数据之间的高阶特征交互。
在国内,陈晓美[6] 开展了对于Web2.0 的网络评论信息的分析研究,通过领域知识进行互补,构建了基于“观点?领域知识?主题”的新型知识搜索体系,以发现网络评论中的观点知识;郭光明[7] 设计了概率主题模型LUBD?CM,并将其应用于刻画用户信用属性,融合社交数据中用户信用画像的有效信息,以搭建用户信用画像预测系统;贺雅琪[8] 根据Dempster?Shafer证据理论,提出了一种数据融合框架,实现了对多源数据的决策级融合;邓烜堃构建了一种基于有限布尔兹曼机的深度自编码器,实现了对高位金融数据的特征降维并构建了回归模型预测股价,通过实证表明自编码器提取特征的效果优于传统主成分分析与因子分析等方法;王乾基于股票历史数据、财经新闻数据、股票社交舆情3 种信息源,使用LSTM 网络对个股涨跌趋势进行预测,通过实证证明了多源数据预测的合理性;黄洁云提出充分利用股市多源数据,并使用小波变换捕捉时间序列波动趋势,同时对文本数据使用BERT 模型提取其文本情感特征,融合量化特征与文本特征并预测股票波动;张露设计了一种SBV 多源信息融合模型,有效解决了财务预警问题中的有效样本不平衡问题,实现了对股市财务预警的精确预测;刘政昊从知识关联视角构建了一个金融领域知识图谱,尝试发现股票之间的关联性与隐含特征,为投资者提供指导建议;耿立校提出了一种基于多源异构数据的LSTM 模型,结合了历史交易数据、量化指标数据、文本评论数据3 类数据,对股票波动走势进行实时预测,并验证了其有效性和可行性。
3 模型设计
3.1 基于LDA 的情绪指数构建
LDA 是一种无监督学习主题模型,无需人工对训练集进行标注,仅利用文档集合就可以依概率分布显示出每篇文档的主题。对于文本的处理以及数据的挖掘,LDA 模型是一个常用的文本建模方法,可以有效地从文本中提取所需的重要信息。对于文本中隐含情绪的提取以及建模,LDA 模型克服了传统文本相似度的比较方法中的缺点,大幅提升了提取分析的效率。
作为经典主题模型之一,LDA 的核心思想是将文档表示为若干个潜在的主题,其中每个主题都通过一定量的单词来描述,具体而言,通过参数估计得到词汇概率分布,并结合各文档主题概率分布进行判断,从而将词项空间的全部词汇聚类转移到主题空间中,达到提取文本主题的目的。通过对每个词w 的主题z进行采样,基于其统计频次,计算得到文本主题k 中的词项概率分布φk 和第m 篇文档的主题概率分布θm ,其LDA 联合概率为:
在得到文本主题词汇后,本文使用开源情感分析工具Snownlp 得到其情感评分,其底层算法为朴素贝叶斯模型。其训练过程实质上是统计每一个特征出现的频次,通过对文本打上正、负极性的标签,将每一个词汇视作相互独立的特征,统计各个词汇特征出现的频次与训练样本中的词汇总数,就可以将情感极性分析任务转化为一个贝叶斯分类模型,具体公式为:
其中,c1, c2 为情感极性(积极或消极),w1,w2,…wn为每个词汇出现的频次,即特征n 为词汇数。
3.2 基于Auto?Encoder 的特征提取
由于股票市场指标种类繁多,需要接受大量输入信息,而且不同技术指标之间往往存在多重共线性的可能,为降低数据维度,提取出原数据中最具代表性的信息,压缩输入信息量,实现特征重构与特征提取。
本文建立了Auto?Encoder 自编码器模型,实现了由高维数据到低维数据的压缩编码。在处理统计特征的部分,依次完成差分处理、对数变换和标准化,提取时间序列的统计特征,以Auto?Encoder 模型提取重要因子,并加入模型。
自编码器(Auto?Encoder, AE)是一种经典神经网络模型,主要由编码器(Encoder)及解码器(Decoder)构成,其主要原理是将输入样本通过编码器映射至一个特征空间中,接着通过解码器将已完成编码的抽象特征映射回原始空间,以得到重构样本,然后对比输入和输出,使二者不断逼近,最终实现特征提取。通过学习到的新特征,Auto?Encoder 可以重构出原始输入数据,解码成更低维的数据。设输入样本为x,抽象特征为y,重构样本为x ,编码函数为f(x),解码函数为g(x),误差为e,则有:
3.3 基于LSTM 的股价波动预测
长短时记忆网络( Long Short?Term Memory,LSTM)是一种深度神经网络模型,在语音识别、股指预测等涉及序列数据的任务中具有相当广泛的应用。
LSTM 模型隶属于循环神经网络(Recurrent NeuralNetwork,RNN)的一种,由于其能够处理长时序列,比RNN 更适用于处理和预测时间序列数据。传统RNN模型试图通过循环来让信息连续传递,然而随着句子距离的增加,RNN 将难以连接相关信息,也就是俗称的远程依赖问题,该网络的设计本意正是希望克服远距离依赖问题, 并在各种任务中取得优异表现。
LSTM 模型由遗忘门、输入门、输出门3 部分组成,引入了单元状态的概念,其模型架构为:
其中,σ 为激活函数,W 为权重矩阵,b 为偏置项,ft ,it ,ot 和ct 分别为输入门、遗忘门、输出门和单元激活向量,ht 为输出激活函数。
近年来, LSTM 受到了很多科学家的青睐,其在舆情分析任务中的应用均取得了较好的效果,并在多个领域成为不可替代的一部分。通过LSTM 模型可以准确捕捉股市舆情间的高阶特征交互,并基于反复迭代训练学到记忆哪些信息和遗忘哪些信息。基于在LDA 主题模型中得到的关联关系,结合股票的发布时间、涨跌情况、股民评价、公司经营状况等轨迹,预测其未来的发展热度,使用神经循环网络,能够更好地拟合波动趋势,误差较小,预测精度较高,进而为广大投资者的投资决策提供了一定的辅助参考作用。
4 结束语
本文主要研究了基于多源异构数据的股指趋势预测,尝试将股市信息归纳为历史交易数据、量化指标数据、文本评论数据3 类数据源,通过设计不同的特征工程手段将不同种类数据融合至一处,然后输入AE?LSTM 模型实现对股票指数波动的预测,有效改进了模型效果。同时,通过与若干基线的对照实验,验证了模型的先进性与可行性。
随着互联网信息技术的高速发展,信息发布与传播速度愈发加快,数据量级呈现出井喷式的增长,导致社会投资者难以甄别其中的有效信息。然而由于股票市场的复杂性,历史交易数据、量化指标数据、文本评论数据均会影响投资者在股票市场中的决策行为,进而对股票收益率和流动性产生影响。因此本文基于前人基础,对股票的相关舆论信息进行数据挖掘,提出了量化数据与文本数据的融合方法,基于LDA 构建文本主题特征,基于AE?LSTM 模型预测股票价格走势,相信未来能够在股票投资领域发挥重要作用。
参考文献:
[1] 李尚昊,朝乐门.文本挖掘在中文信息分析中的应用研究述评[J].情报科学,2016,34(8):153?159.
[2] 王超.舆情热度对股市收益的影响[D].杭州:浙江大学,2020.
[3] 孙明璇,李莉莉.基于数据挖掘的投资者情绪对股市波动影响研究[J].燕山大学学报(哲学社会科学版),2020,21(1):68?77.
[4] 吕华揆,刘政昊,钱宇星,等.异质性财经新闻与股市关系研究[J].数据分析与知识发现,2021,5(1):99?111.
[5] 刘薇,姜青山,蒋泓毅,等.基于FinBERT?CNN 的股吧评论情感分析方法[J].集成技术,2022,11(1):27?39.
[6] 陳晓美.网络评论观点知识发现研究[D].长春:吉林大学,2014.
[7] 郭光明.基于社交大数据的用户信用画像方法研究[D].合肥:中国科学技术大学,2017.
[8] 贺雅琪.多源异构数据融合关键技术研究及其应用[D].成都:电子科技大学,2018.
作者简介:叶慕戎(2000—),本科,研究方向:金融数学。
