基于深度学习的化工企业财务数据信息异常分析方法
2023-07-17安世俊
安世俊
(兰州资源环境职业技术大学,甘肃 兰州 730022)
0 引言
随着现代化社会的飞速发展,互联网技术、数据挖掘技术在国内得到了快速发展与应用,我国许多化工企业均可实现快速、有效地对大规模异常数据进行检测与分析[1]。这些分析方法将统计的海量检测数据进行合理分析,及时检测出因网络设备问题或软件故障而生成的不同种类异常数据信息。实时检测与分析网络异常数据,根据信息获取和逻辑思考将时间序列数据分段,通过构建不同网络结构来对异常数据信息进行分析,使有标签数据集数量增加。同时其还加强了网络训练的能力,提升对网络结构和异常数据的检测实时性及准确性,使海量数据的异常识别效果更优,大幅提升分析的准确性。目前,由于分析过程的算法生成的序列缺少迭代,存在检测网络数据中混杂异常数据数量多、分析不明显等问题,导致企业的财务数据分析存在多种致命问题,如数据缺失、数据漂移等。异常数据的分布过于随机使检测结果在大数据中不好辨别,导致分析进程慢,更易产生虚假预警,严重影响异常数据分析的效果,进而造成网络诊断准确性大幅降低。因此,现阶段,为有效诊断与分析异常数据,该文以化工企业财务异常数据信息为试验对象,运用深度学习方法,结合具体情况进行试验与分析。
1 化工企业财务数据信息异常分析
1.1 PCA 法进行数据预处理
测量过程中的大量数据中均存在噪声,将这些噪声值设定为异常值。改进化工企业财务数据信息分析时要对数据的噪声问题进行处理,如果数据清洗不干净,则会影响其判断的准确率[2]。根据莱特检验的方法对每个网络中的信息点进行检测,对异常值进行发掘并剔除完成数据的预处理。进行异常信息检测时,通过T 检验得到网络中异常数据的相关性,如公式(1)所示。
式中:f为数据中的相关特征;为所有样本中的特征均值;n(f)为样本中的正常数据信息的特征均值。
然后运用深度学习中的PCA 算法识别数据中的主要成分并进行分类,获得大量数据集中的信息,再降低数据的维度。处理高维度数据时,通过正交变换得到新坐标系中的映射,形成新的正交变量集合。将获得的贡献率作为变量的重要性度量,设定r个变量的方差贡献率如公式(2)所示。
式中:γ为第r个变量中的样本总数计算得到的方差值。
变量中的方差贡献率值越大,线性集合中的变量收集到的原始数据信息就越多。引用PCA 算法得到高维度数据,并消除其中的数据冗余。根据其特征的提取完成总结,加强异常检测效率。定义一个财务数据序列为T=(t1,t2,...,tn),表示一组实数集合,设定空间W中的数据g和度量d,则平均数据中的最小化数据如公式(3)所示。
当映射在平均值的每个元素中时,通过运算权重之和获得合理权重P,以此得到新的数据样本。选择数据序列T中的相对距离进行赋值,在随机一个网络端内的数据样本Hi得到的权值pi如公式(4)所示。
式中:N为相邻样本之间的距离,其中距离最近的样本为最优。
随后将所有的序列样本赋予权重,进行归一化处理,将得到的结果作为数据序列的权重,任意选取一个c*初始化,生成新的数据序列,并不断对其进行迭代,合成新的数据[3]。对财务数字信号进行分解,信号中的最大值和最小值需要通过计算获得,设定分解过程的时间间隔为大、小值之间的时间间隔,计算均值并提取局部分量为h(t)=s(t)-imf(t),计算残留项目并得到公式(5)。
式中:imf(t)为本征的模态函数;r(t)为预留项。
根据信号分解,在对应尺度中形成表征,获得进一步分析的机会。为消除在模态中出现的混叠问题,在不同信号的筛选过程中加入白噪声,并进行多次分解,获得平均值后得到对应的给定信号s(t)的IMF,加入幅度相似的白噪声,如公式(6)所示。
式中:i为分解次数。
通过叠加白噪声抑制模态的混叠,减少数据处理的运算时间。
1.2 搭建UAE 数据关联模型
定义数据关联模型,将时间序列的窗口为s={s1,s2,...,sn},其中n为数据序列的长度,每个维度对应一种特征;s为获得对应财务数据信息的特征信息,即为数据大小、数量类型和数据说明等。将同一网络中的异常数据和正常数据进行归档记录,得到相应的发生时间间隔,通过异常关联性的分析得到参考序列之间的相似程度,判断数据之间的紧密性。设定参考序列为X,对应的关联系数计算如公式(7)所示。
式中:p为分析系数,一般状态下p=0.5;∆(min)为数据的两级差值;∆(k)为不同序列中的每点之间的差的绝对值。
关联度计算如公式(8)所示。
式中:r的值为1 则说明相关性强;反之为0 则说明相关性弱。
设财务数据中所有出现过的计量异常数据的种类为N类,表示为A(n=1,2,...,n),n为每种异常数据出现时的所有次数[4]。对异常数据进行统计,根据异常数据出现的顺序分别求出d<15 时异常出现的次数。再设适当的标准值为μ,当d<μ时,可以认为存在异常数据,且具有关联性。根据小概率出现原则,得到标准值设定的计算公式,如公式(9)所示。
式中:ni为An在网络中出现的所有次数。
在训练阶段,将正确的时间序列作为训练样本,输入数据关联模型中进行时间序列重构。在训练完成后,输入正确的时间序列,控制重构误差,并使误差的大小不超过3%。将含有异常数据的序列输入模型中时,重构误差值会变大。此时运用深度学习法完成重构序列的预处理,生成一个大小相同的状态向量并输出。在神经网络中训练对应的时间序列数据。当序列数据的长度超过实际规定大小时停止训练。如果所训练的数据梯度消失,说明只学习到一定间隔的时间序列信息,需要及时解决梯度消失问题。在神经网络中添加控制时间记忆长短的状态单元,通过存储当前时刻的数据延长记忆,使当前时刻的数据与之前的数据存在内部关联。在神经网络中设置3 个控制开关,运用forget gate 模块控制是否继续保存单元状态至当前时刻。其计算如公式(10)所示。
式中:wf为权重矩阵;b为偏置量;σ为控制函数。
再通过input gate 模块控制是否将当前时刻状态输入之前的状态单元。通过将当前记忆与之前的记忆相结合形成新的状态单元,并保存新的信息,最后将其输出。同时,为提高预测确度,运用注意力机制使数据能够在不同周期中具有实际数值。在不同的应用场景中,计算当前输入序列与输出向量的对应程度,集中点得分越高,计算得到的权重就越大。将每个隐藏状态设定一个权重,权重的不同决定了输出状态。对状态向量进行学习来重构序列。其中s1,s2,...,sn为输入序列,,,...,为重构序列,e为状态向量得到的具体的关联度值,以判断异常数据出现并实施检测。
1.3 HESS 法分析异常数据信息
对企业财务信息进行实时采集与记录,根据预处理的信息获得对应组元信息,并利用信息熵对异常信息数据进行初步检测。通过特定窗口对其求得信息熵值,将得到的数值与设定的标准值进行比较,以此来判断企业财务中存在异常数据信息的区间,同时进行第二次深度检测。其中,信息熵值的计算如公式(11)所示。
式中:d为样本数据,其中d=ni,i=1,2...,N;i为内部样本的数据;ni为变化的次数;D为样本取值的对应全部数目。
在样本信息熵的变化过程中,设定的变化区域范围为(0,logD),由于样本的分布相对统一,因此对应的信息熵值不变,样本值相等。为了减少网络防御的攻击,通过在网络结构中输入数据样本,并对正常样本进行标记,将输入层的数据在其中充分激活,完成解码与重构[5]。在数据信息编码的过程中,产生的隐藏部分的输出公式如公式(12)所示。
式中:E1为权重矩阵;B1为复合矩阵;σ为激活函数;g为输出层的对应输出。
对应的重构误差如公式(13)所示。
式中:J(W,b)为分析重构存在的差异值;m为输入层的相应的节点数量;x为需要传递的数据;解压过程中的输出数据。
与传统样本集相比,在利用数据异常网络编码的过程中,为获得对应的样本特征,使神经元一直保持在抑制状态,需要对隐藏部分的神经元节点j完成激活,得到平均值的计算如公式(14)所示。
式中:m为数据的存在条数;aj(2)(x)为神经节点中的输出激活数据。
在对中间层的神经元节点进行分析的过程中,如果抑制状态产生,则需要规定其中间层的神经元节点j中。设置对应的抑制性参数为,按照设计条件,规定p的 取值范围为无限趋近于0 的小数。设定惩罚参数,利用不同抑制性参数之间的差异得到相应的惩罚,使激活参数之间的数据相等[6]。这种激活公式如公式(15)所示。
式中:K为隐藏部分的神经元数据。
式中:ε为对应的正则化因数;b为存在IDE 信息网络的层数;W为神经元的总数。
从第一个结构开始进行特征学习,训练后获得W和b的值,得到最终的训练样本[7]。
2 试验测试与分析
2.1 搭建试验环境
搭建财务数据信息异常检测方法的试验环境,根据IP地址段对全网进行划分,主要包括化工企业中的财务网段。设置一台P8 微处理机,操作系统为Windows 11,充分收集并详细记录对应的所有测量数据[8]。将Java 语言作为开发工具。运用的软件环境和参数见表1。
表1 软件环境及参数
运用Cisco 的NetFlow 从企业网络中的节点上依次采集样本数据信息,采样周期为12 个包。在初始数据包提供中,按每1440/86min 进行数据信息聚合,进行测量数据的采集的周期通常为一轮。处理采集到的财务数据信息,根据其信息熵计算网络数据在106×7 个数据段内的原IP 地址、目的IP 地址及端口的信息熵序列值,得到大小为600×4 的矩阵。各个属性的熵值序列对应600 个不同OF 数据段。根据对应边排布,将得到的对应元组矩阵变成2869×4 的矩阵P,将得到的结果按原IP、目的IP 以及端口分成不同序列,并将其作为K-means 的输入值进行异常分析[9]。
2.2 试验结果与分析
受公司规模、盈利范围等水平的影响,不同化工企业财务比率数据存在异常数据。设置5 个小组,运用该文方法的小组为试验组,1~4 对照组运用传统方法。试验选取的化工企业的财务数据信息样本数据为1000 类。先对试验数据进行标准化处理,将试验的数据样本带入运算得到样本的离差数据处理,即带入SOM 模型中,并对其中的异常信息进行分析,得到最优的聚类结果,见表2。
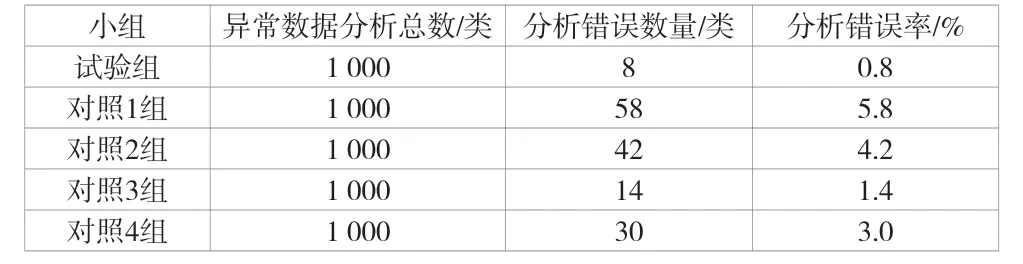
表2 SOM 信息异常分析表
由试验结果可知,1~4 对照组的分析错误率相对较高,聚类结果中存在的误差较大,造成化工企业的财务数据指标不符合标准,异常分析的准确程度下降。和对照组相比,试验组的分析错误率最低,为0.8%。这样就使聚类结果中的误差变小,准确率也有了显著提升,财务数据信息异常分析趋于准确,分析结果更具有说服力,可及时发现财务数据中的数据信息异常,使化工企业财务数据信息异常的分析更全面。
3 结语
该文从化工企业财务数据信息入手,运用深度学习技术,探究了基于深度学习的化工企业财务数据信息异常分析方法。通过检测与分析化工企业财务中的异常数据,对异常值进行查缺与填补,完成对化工企业财务数据清洗的过程。但是方法中也存在不足,例如算法中存在的阈值问题、对数据的空间特征的异常值检测问题及空缺值的问题。在以后的研究中应及时精细算法,对时间序列进行降维以改进异常值,提升异常分析的准确性。利用特性找出原有数据中的脏数据,对化工企业财务数据进行合理有效的清洗,构建优质数据库集群,从而使该方法的研究更完善。
